【论文阅读】Deep Session Interest Network for Click-Through Rate Prediction
2019年,继DIN,DIEN之后,DSIN问世。论文点击这里,代码点击这里。
一句话总结:从用户行为发现,在每个会话中的行为是相近的,而在不同会话之间差别是很大的,阿里提出了深度会话兴趣网络Deep Session Interest Network,来建模用户这种跟会话密切相关的行为。session划分,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。
1.论文阅读
为什么提出DSIN?
经过观察,发现每个会话内的行为比较相近,不同会话之间差别较大。【说明数据分析的重要性,结合对业务的认知,对session进行建模,提出DSIN】
Base Model
Base Model就是一个全连接神经网络,其输入的特征的主要分为三部分,用户特征,待推荐物品特征,用户历史行为序列特征。用户特征如性别、城市、用户ID等等,待推荐物品特征包含商家ID、品牌ID等等,用户历史行为序列特征主要是用户最近点击的物品ID序列。
这些特征会通过Embedding层转换为对应的embedding,拼接后输入到多层全连接中,并使用logloss指导模型的训练。
DISN Model
整体网络结构:
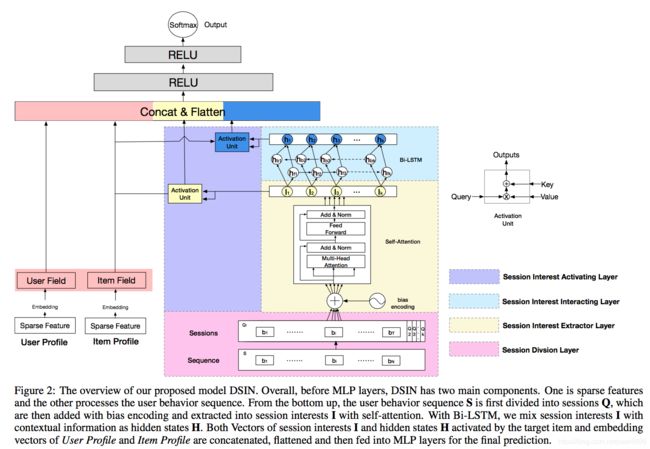
DSIN在全连接层之前,分成了两部分,左边的那一部分,将用户特征和物品特征转换对应的向量表示,这部分主要是一个embedding层,就不再过多的描述。右边的那一部分主要是对用户行为序列进行处理,从下到上分为四层:
1)序列切分层session division layer
2)会话兴趣抽取层session interest extractor layer
3)会话间兴趣交互层session interest interacting layer
4)会话兴趣激活层session interest acti- vating layer
1)序列切分层session division layer
这一层将用户的行文进行切分,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。
切分后,我们可以将用户的行为序列S转换成会话序列Q。第k个会话Qk=[b1;b2;...;bi;...;bT],其中,T是会话的长度,bi是会话中第i个行为,是一个d维的embedding向量。所以Qk是T * d的。而Q,则是K * T * d的。
2)会话兴趣抽取层session interest extractor layer
这里对每个session,使用transformer对每个会话的行为进行处理。
在Transformer中,对输入的序列会进行Positional Encoding。Positional Encoding对序列中每个物品,以及每个物品对应的Embedding的每个位置,进行了处理,如下:

但在我们这里不一样了,我们同时会输入多个会话序列,所以还需要对每个会话添加一个Positional Encoding。在DSIN中,这种对位置的处理,称为Bias Encoding,它分为三块:

BE是K * T * d的,和Q的形状一样。BE(k,t,c)是第k个session中,第t个物品的嵌入向量的第c个位置的偏置项,也就是说,每个会话、会话中的每个物品有偏置项外,每个物品对应的embedding的每个位置,都加入了偏置项。所以加入偏置项后,Q变为:
Q = Q + BE
随后,是对每个会话中的序列通过Transformer进行处理:
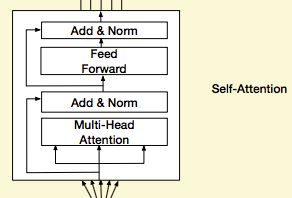
这里的过程和Transformer的Encoding的block处理是一样的,不再赘述。感兴趣的同学可以看一下这篇文章。
这样,经过Transformer处理之后,每个Session是得到的结果仍然是T * d,随后,我们经过一个avg pooling操作,将每个session兴趣转换成一个d维向量。
3)会话间兴趣交互层session interest interacting layer
用户的会话兴趣,是有序列关系在里面的,这种关系,我们通过一个双向LSTM(bi-LSTM)来处理:
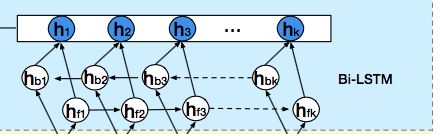
每个时刻的hidden state计算如下

相加的两项分别是前向传播和反向传播对应的t时刻的hidden state。这里得到的隐藏层状态Ht,我们可以认为是混合了上下文信息的会话兴趣。
4)会话兴趣激活层session interest acti- vating layer
用户的会话兴趣与目标物品越相近,那么应该赋予更大的权重,这里使用注意力机制来刻画这种相关性:
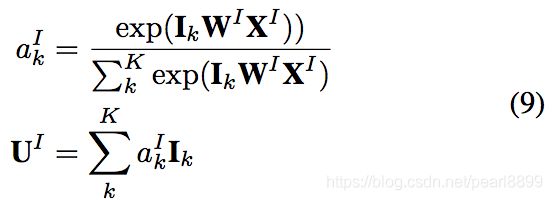
这里XI是带推荐物品向量。
同样,混合了上下文信息的会话兴趣,也进行同样的处理:

后面的话,就是把四部分的向量:用户特征向量、待推荐物品向量、会话兴趣加权向量UI、带上下文信息的会话兴趣加权向量UH进行横向拼接,输入到全连接层中,得到输出。
结论:
1 Effect of Multiple Sessions
从实验结果来看,DIN-RNN的效果差于DIN,而DSIN-BE的效果好于DSIN-BE-No-SIIL。两组的差别均是有没有使用序列建模。文章里提到,对于序列建模来说,如果用户的行为时十分跳跃的,同时是突然结束的,会使得用户的行为看上进去具有很大的噪声。这样就使得DIN-RNN的效果反而不如DIN,但在DSIN中,我们对用户的行为序列按照会话进行了分组,由于以下两点原因,使得DSIN中使用序列建模效果反而更好。
2.Effect of Session Interest Interacting Layer
DSIN-BE的效果好于DSIN-BE-No-SIIL,说明通过 Effect of Session Interest Interacting Layer得到混合上下文信息的用户兴趣,可以进一步提升模型的效果。
3.Effect of Bias Encoding
DSIN-BE的效果好于DSIN-PE,说明对不同的session添加偏置项,效果还是十分不错的。
2.代码
1.数据处理
2.网络结构
参考:
1.论文:https://arxiv.org/abs/1905.06482
2.代码数据处理:https://github.com/shenweichen/DSIN,网络结构核心源码:DeepCTR
3.https://www.jianshu.com/p/82ccb10f9ede
4.Transformer:https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w