Scrapy爬虫快速入门
Scrapy学了就忘怎么办? 先来点真实的:
把大象塞进冰箱里需要几步,学习Scrapy就需要几步:
1、下载 2、学 3、得瑟
1. 下载Scrapy
现在是2022年,下载Scrapy直接打开终端pip install Scrapy就可以了,不需要通过wheel。
pip install Scrapy下载到的东西包括你以前安装的模块或包都在你的python->Lib->site-package里,所以随便下载不用担心出错,anaconda也同理。
输入 scrapy version 验证即可
![]()
2. 学习Scrapy的基本使用
2.1. Scrapy的基本操作
1. 首先创建一个工程
我们打开pycharm,随便在一个目录下面即可,打开Terminal,按照如下输入:
scrapy startproject firstBlood其中 firstBlood 为本次工程的名称。

此时我们的目录下多了这样一组文件:
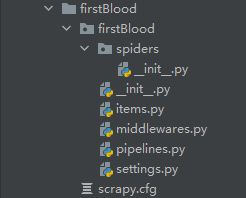
我们先看这两个:
spiders文件夹:里面我们要放置爬虫源文件(自己添加自己写)
settings:本次要用的被指文件
其他会在后面介绍。
2 . 在spiders子目录下创建一个爬虫源文件。
在上步操作中,系统已经提示我们:

因此,我们首先进入到工程目录,然后再执行命令创建一个爬虫文件:
cd firstBlood
scrapy genspider first www.baidu.com
这里我给爬虫文件起名为first至于网站随便打一个就行,不满意的话还可以改。
于是我们的spiders文件夹下多了一个名为first的文件:

3. 了解一下first.py各部分含义:
认真看一下
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称:就是爬虫源文件的一个唯一标识
name = 'first'
# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
allowed_domains = ['www.baidu.com']
# 起始的url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.baidu.com/', 'https://www.sogou.com']
# 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
pass
可见,对于允许请求的地址,会被scrapy自动进行请求的发送。如上我们手动添加了一个新的地址‘https://www.sougou.com’,那么scrapy便会发送两次请求(我们先把allowed_domains注释掉,学得灵活一点)。
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称:就是爬虫源文件的一个唯一标识
name = 'first'
# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
#allowed_domains = ['www.baidu.com']
# 起始的url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.baidu.com/', 'https://www.sogou.com']
# 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
print(response)
pass
像我们以前 requests.get(http://www.xxxx.com)一样,response为返回的响应对象,所以如果我们print打印出response,应该得到两个响应对象:
运行文件需要终端继续输入:
scrapy crawl first不出意外,你应该获得了一大堆的日志信息,这里面你并没有找到预期的两个response对象,在这里,我们看到从我们第一天学爬虫就的知的robots协议,它在settings.py中,很明显我们默认是遵从了robots协议,因此没有获得响应数据。
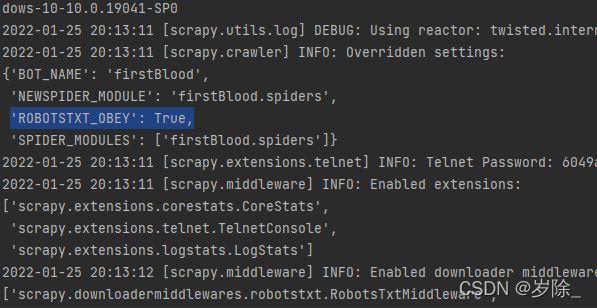
诶我们不遵从,就是玩儿。

此时再次运行文件 scrapy crawl first:
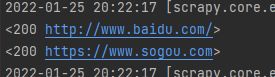
我们得到了想要的响应对象
此时依旧由很多日志信息,会干扰到我们阅读,因此可以在运行文件的时候加上一句--nolog
scrapy crawl first --nolog舒服多了

但若以后我们的程序一不小心出错,这样执行我们并不会发现问题,因此最好的办法是:
在settings.py中加上一句
LOG_LEVEL = 'ERROR'
意思是以后我们的日志只会打印出错误信息。

这里没有出错因此没有打印出错误信息。
2.2. Scrapy数据解析
我们曾类比JavaScript寻找标签学过一些基本的东西,bs4,xpath,selenium,数据解析无非就是寻找我们所需要爬取内容的地方。
首先我们创建一个工程文件,随便在网上找点简单的东西练一下:
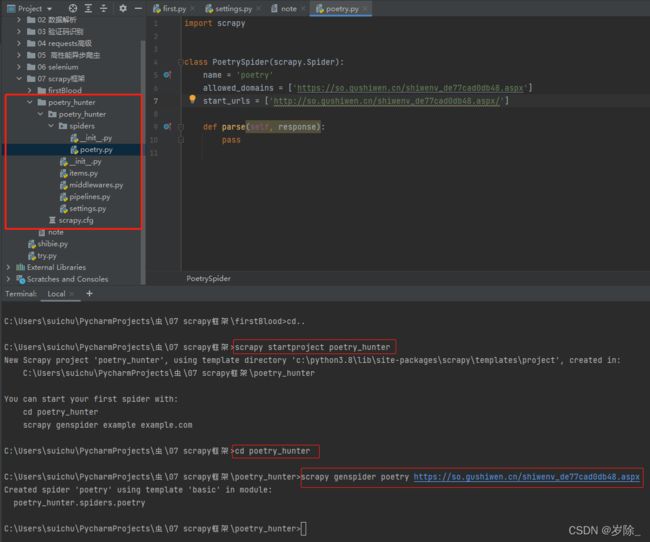
settings.py记得改一下,UA伪装记得把自己浏览器的UA复制粘贴进去:

这是我们要爬取的内容:
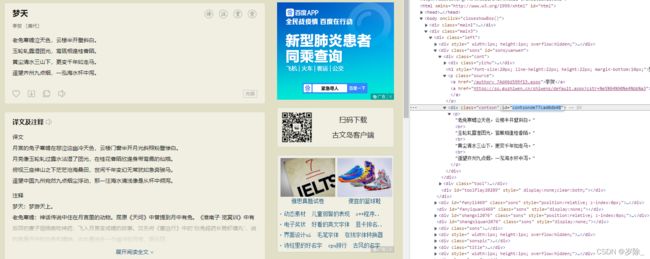
poetry.py (01)
import scrapy
class PoetrySpider(scrapy.Spider):
name = 'poetry'
allowed_domains = ['https://so.gushiwen.cn/shiwenv_de77cad0db48.aspx']
start_urls = ['http://so.gushiwen.cn/shiwenv_de77cad0db48.aspx/']
def parse(self, response):
# 获取诗名
title = response.xpath("//div[@class='cont']/h1/text()")
# 获取诗内容
poetry_content = response.xpath("//div[@id='contsonde77cad0db48']/p//text()")
print(title)
print(poetry_content)
执行 scrapy crawl poetry运行文件

可以看到我们scrapy有自带的xpath方法,用法与lxml导入etree的xpath用法基本相同,不过我们观察它的返回对象,虽然依然是列表,但列表内的元素变成了Seleter对象。此时我们只需后面加上
.extract()
即可提出成字符串返回:
poetry.py (02)
import scrapy
class PoetrySpider(scrapy.Spider):
name = 'poetry'
allowed_domains = ['https://so.gushiwen.cn/shiwenv_de77cad0db48.aspx']
start_urls = ['http://so.gushiwen.cn/shiwenv_de77cad0db48.aspx/']
def parse(self, response):
# 获取诗名
title = response.xpath("//div[@class='cont']/h1/text()").extract()
# 获取诗内容
poetry_content = response.xpath("//div[@id='contsonde77cad0db48']/p//text()").extract()
print(title)
print(poetry_content)
# print(''.join(poetry_content))
# ['梦天']
# ['老兔寒蟾泣天色,云楼半开壁斜白。', '玉轮轧露湿团光,鸾珮相逢桂香陌。', '黄尘清水三山下,更变千年如走马。', '遥望齐州九点烟,一泓海水杯中泻。']
其他:若我们想获取返回列表的第一条数据,除了可以加索引[0]还可以写成:.extract_first()
2.3. 持久化存储
我们还要像以前一样with open(‘xxx’) as f 这样存储吗? no no no
- 基于终端指令:
- 要求:只可以将parse方法的返回值存储到本地的文本文件中
- 注意:持久化存储对应的文本文件的类型只可以为:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle
- 指令:scrapy crawl xxx -o filePath
- 好处:简介高效便捷
- 缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
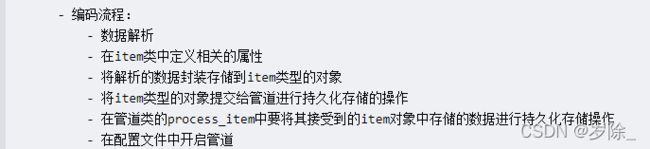
- 基于管道:
- 编码流程:
- 数据解析
- 在item类中定义相关的属性
- 将解析的数据封装存储到item类型的对象
- 将item类型的对象提交给管道进行持久化存储的操作
- 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 在配置文件中开启管道
- 好处:
- 通用性强。如可以存到数据库、文件。
- 面试题:将爬取到的数据一份存储到本地一份存储到数据库,如何实现?
- 管道文件中一个管道类对应的是将数据存储到一种平台
- 爬虫文件提交的item只会给管道文件中第一个被执行的管道类接受
- process_item中的return item表示将item传递给下一个即将被执行的管道类
2.3.1 基于终端指令存储
看一下我们上面写的
import scrapy
class PoetrySpider(scrapy.Spider):
name = 'poetry'
allowed_domains = ['https://so.gushiwen.cn/shiwenv_de77cad0db48.aspx']
start_urls = ['http://so.gushiwen.cn/shiwenv_de77cad0db48.aspx/']
def parse(self, response):
# 获取诗名
title = response.xpath("//div[@class='cont']/h1/text()").extract()
# 获取诗内容
poetry_content = response.xpath("//div[@id='contsonde77cad0db48']/p//text()").extract()
title = ''.join(title)
poetry_content = ''.join(poetry_content)
dct = {title: poetry_content}
return dct
这里我把这首诗的标题和内容以字符串的形式装进了字典了,你可以想象一下我们for循环爬取了很多数据都放到了这个字典里,最后return这个字典。
想要保存这组返回值,只需在Terminal输入:
scrapy crawl xxx -o filePath
scrapy crawl poetry -o poetry.csv注意:该方法只可以将parse方法的返回值存储到本地的文本文件中
Set a supported one (('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle'))
2.3.2 基于管道持久化存储
这是我在上面罗列的步骤
第一步:数据解析
很明显我们已经完成了
import scrapy
class PoetrySpider(scrapy.Spider):
name = 'poetry'
allowed_domains = ['https://so.gushiwen.cn/shiwenv_de77cad0db48.aspx']
start_urls = ['http://so.gushiwen.cn/shiwenv_de77cad0db48.aspx/']
def parse(self, response):
# 获取诗名
title = response.xpath("//div[@class='cont']/h1/text()").extract()
# 获取诗内容
poetry_content = response.xpath("//div[@id='contsonde77cad0db48']/p//text()").extract()
title = ''.join(title)
poetry_content = ''.join(poetry_content)第二、三步和第四步:
首先第二、三步,什么是Item类呢?上面我们只介绍了一个项目文件中的两个部分(spiders文件夹和settings.py),这里我们来看一下另一个文件:items.py

我们要执行的步骤就是:
1、按照绿色的提示给Item这个类创建属性用来存储临时数据
2、在poetry.py里导入这个类并且实例化传入我们解析到值。
items.py
import scrapy
class PoetryHunterItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()poetry.py
(这里我把07 scrapy框架文件名改为了scrapyKJ,以便导入文件。这句话可忽略。)
这里要注意一下,你在Terminal所处的位置,因为我最后执行文件的时候所处的位置是
C:\Users\suichu\PycharmProjects\虫\scrapyKJ\poetry_hunter>scrapy crawl poetry
所以虽然文件内部飘红,结果依然正常。结果在最后。
import scrapy
from poetry_hunter.items import PoetryHunterItem
class PoetrySpider(scrapy.Spider):
name = 'poetry'
allowed_domains = ['https://so.gushiwen.cn/shiwenv_de77cad0db48.aspx']
start_urls = ['http://so.gushiwen.cn/shiwenv_de77cad0db48.aspx/']
def parse(self, response):
# 获取诗名
title = response.xpath("//div[@class='cont']/h1/text()").extract()
# 获取诗内容
poetry_content = response.xpath("//div[@id='contsonde77cad0db48']/p//text()").extract()
title = ''.join(title)
poetry_content = ''.join(poetry_content)
item = PoetryHunterItem()
item['title'] = title
item['content'] = poetry_content
yield item # 将item提交给了管道注意看后四行代码,这里最后我们通过yield将item交给管道,此时完成第四步。
那么交给管道后干了什么呢?管道是什么呢?
第五步:管道存储
再来介绍一个文件:pipelines.py
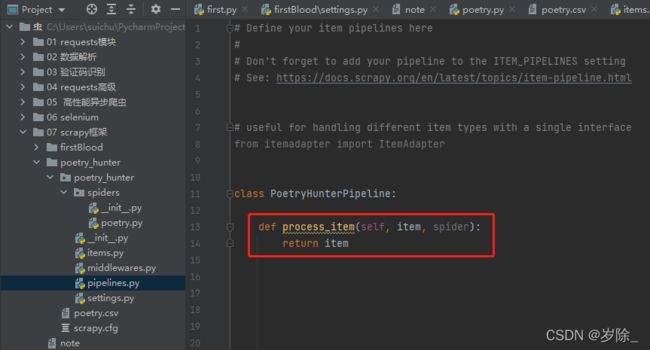
这里给我们定义了一个方法:process_item,它是专门处理Item对象的方法(因为我们在上面Item已经封装好了,所以管道这里可以进行处理)。
class PoetryHunterPipeline:
# 专门处理Item对象的方法
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一次item就会被调用一次
def process_item(self, item, spider):
return item我们由于接收到了item,因此就可以从item对象中获取想要的数据。然后再进行持久化存储。
class PoetryHunterPipeline:
# 专门处理Item对象的方法
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一次item就会被调用一次
def process_item(self, item, spider):
title = item['title']
content = item['content']
# with open('xxx','w') as f:
return item试想一下,如果我们上面poetry.py的写的是个for循环不停地实例化item传递给管道(也就是这个类), 我们也知道了这个类的方法每接收到一次item就会被调用一次,那么若我们在这个process_item里不停地打开文件、写入、保存,岂不是很麻烦?因此我们要想办法让文件只打开一次我们不停地往里面去写,写完再关闭就可以了。
这里,我们重写父类方法,该父类方法只会在爬虫开始时被调用一次:
class PoetryHunterPipeline:
fp = None
# 重写父类的方法,该方法只会在开始爬虫的时候被调用一次
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('poetry1.txt', 'w', encoding='utf-8')
# 专门处理Item对象的方法
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一次item就会被调用一次
def process_item(self, item, spider):
title = item['title']
content = item['content']
self.fp.write(title + '\n' + content + '\n')
return item
def close_spider(self, spider):
self.fp.close()
print('爬虫结束')
第六步:设置settings.py
找到ITEM_PIPELINES解除注释状态

这里的PoetryHunterPipeline指的就是我们pipelines.py里的PoetryHunterPipeline这个类,300指的是类的优先级,数字越小优先级越高,即会被先执行。(这句话我们也可以看出文件中的类可以不止写一个,它们都会有各自的用途。)
最后,我们来运行一下爬虫文件:

终端结果: 
txt文件:
补充:
我们了解了管道存储的操作流程以后,可以随便试试不执行哪部哪步,自己看看结果以便加深一下理解。
比如我们将内容实例化后不提交给管道,或者不实例化item,我们的项目文件里都会多出一个名为poetry1.txt的文件,因为我们在pipelines.py中重写了一组父类方法,那组父类方法一个在爬虫开始执行的时候执行一次,一个结束时执行一次,执行了文件的创建或者开关。
拓展:
假如我们要求将爬到的数据同时保存在文件中和数据库中:
我们上面也说了,可以有多个类,无非就是在pipelines.py中再模仿写一个类,执行数据库操作就可以了。(数据库、pymysql还不会的话自己反思一下)
pipelines.py
import pymysql
class PoetryHunterPipeline:
fp = None
# 重写父类的方法,该方法只会在开始爬虫的时候被调用一次
def open_spider(self, spider):
print('开始爬虫1')
self.fp = open('poetry1.txt', 'w', encoding='utf-8')
# 专门处理Item对象的方法
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一次item就会被调用一次
def process_item(self, item, spider):
title = item['title']
content = item['content']
self.fp.write(title + '\n' + content + '\n')
return item
def close_spider(self, spider):
self.fp.close()
print('爬虫结束1')
class MysqlPoetryHunterPipeline:
conn = None
cursor = None
def open_spider(self, spider):
print('开始爬虫2')
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='', db='poetryDB')
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
title = item['title']
content = item['content']
try:
self.cursor.execute("insert into poetry_table(title,content) values (%s,%s)", [title, content])
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
print('爬虫结束2')
seetings.py

在执行爬虫之前我们先思考一个问题:
poetry.py里的item提交给pipelines.py时只会提交给一个类,那么是的哪一个类呢?
答案是优先级更高的类(如上面的299),但我们的这个类中的process_item方法有着这样一句:return item ,这句话的作用是把传递过来的item送给下一个要被执行的类。
结果如下:


思考: 我们这在存储时只用到了process_item中的item参数,后面的内容是否会有关于spider参数的呢,它是否更便捷呢?
2.4. 全站数据爬取
在我初学python的时候,那时我曾凭借着仅有的一点点爬虫知识加上百度的帮助,爬取过盗版笔趣阁上的一本小说,因为那本小说很好看,但是有一点不健康,我担心将来被封掉于是爬了下来。
它与我们常见的url大同小异,也是每一张都对应着一个url数字,我for循环拼接字符串完成了爬取。本次的案例也一样。
巧了啊,我所用的案例都是现去找的,包括上面的那个古诗文网的案例。我刚刚找那种含有下一页的网站的时候发现古诗文网还是符合我的要求。
经过分析,古诗文网主页地址’http:so.gushiwen.cn/shiwens‘,当我点击下一页并去掉没用的参数它的地址是这样的’http:so.gushiwen.cn/shiwens/?page=2‘ 我们不妨就以古诗文网为例爬取古诗文网全站(假装只有3页)数据(我们为方便只爬诗名)。
新建一个项目title_hunter,记得修改settings.py。
我们要把每一个链接放到start_urls里吗? 不不不那太low了。
这里直接上代码:
import scrapy
class TitleSpider(scrapy.Spider):
name = 'title'
# allowed_domains = ['https://so.gushiwen.cn/shiwens/?page=1']
# 网站主页 其实内容与http://https://so.gushiwen.cn/shiwens/?page=1 是一样的 灵活点都无所谓的
start_urls = ['https://so.gushiwen.cn/shiwens/']
# 定义一个通用模板
urls = r'https://so.gushiwen.cn/shiwens/?page=%d'
count = 2
def parse(self, response):
# 每一页的标题列表
title_lst = response.xpath("//*[@id='leftZhankai']/div[@class='sons']//a/b/text()").extract()
print(title_lst)
if self.count <= 4:
new_url = format(self.urls % self.count)
self.count += 1
# 手动发送请求:callback回调函数是专门用作数据解析
yield scrapy.Request(url=new_url, callback=self.parse)可以看到我们返回了四个页面的标题列表

2.5. Scrapy框架五大组件
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
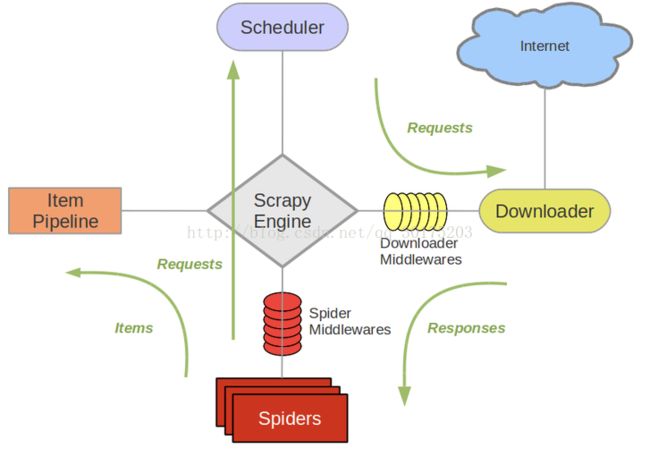
Scrapy运行流程大概如下:
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
然后,爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。
若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline
我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
2.6. Scrapy请求传参
上面我们爬取古诗文网‘全站’的诗名时应对的是一些相似url变化的查找。然而我们爬取的过程中少不了一些深度查找,比如我们点击那首古诗的时候会进入一个新的详情页面,若我们所需要爬取的数据在类似于详情页面的页面中,那便是深度查找。
所以其实我们还可以以古诗文网为例,但这次我们换个口味.
爬取Boss直聘中米哈游公司前三页的招聘岗位。
创建一个新项目:
scrapy startproject miHoYo
cd miHoYo
scrapy genspider mhy https://www.zhipin.com/c100010000/?query=%米哈游
这个网站其实有个障眼法,爬取的详情感兴趣的话可以看下这个链接,这里我直接逃课爬取,过程不重要。目的是为了介绍Scrapy的请求传参这个主题。
(别看了被禁了,不让发。)
先测试一下能否爬到岗位名称:
(这里我重写了一下父级请求,记得settings.py里cookies_enable = true)
import scrapy
class MhySpider(scrapy.Spider):
name = 'mhy'
# allowed_domains = ['https://www.zhipin.com/c100010000/?query=%E7%B1%B3%E5%93%88%E6%B8%B8']
start_urls = ['https://www.zhipin.com/c100010000/?query=%E7%B1%B3%E5%93%88%E6%B8%B8']
urls = r'https://www.zhipin.com/c100010000/?query=米哈游&page=%d'
page = 2
cookies = {'__zp_stoken__': '重要cookie'}
def start_requests(self):
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies=self.cookies
)
def parse(self, response):
position_lst = response.xpath("//div[@class='job-list']//li//span[@class='job-name']/a/text()").extract()
print(position_lst)
if self.page <= 3:
new_url = format(self.urls % self.page)
self.page += 1
yield scrapy.Request(url=new_url, callback=self.parse, cookies=self.cookies)

ok接下来就是请求参数的传递,其实不算是什么新知识,我们上面学了
![]()
只需在需要跳转搜索详情页的时候,把新的请求交给一个新的函数去做就可以。
如下:
mhy.py
import scrapy
from miHoYo.items import MihoyoItem
class MhySpider(scrapy.Spider):
name = 'mhy'
# allowed_domains = ['https://www.zhipin.com/c100010000/?query=%E7%B1%B3%E5%93%88%E6%B8%B8']
start_urls = ['https://www.zhipin.com/c100010000/?query=%E7%B1%B3%E5%93%88%E6%B8%B8']
urls = r'https://www.zhipin.com/c100010000/?query=米哈游&page=%d'
page = 2
cookies = {'__zp_stoken__': '重要cookie'}
def start_requests(self):
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies=self.cookies,
meta= {'proxy':'代理ip'}
)
def find_detail(self, response):
mhy_item = response.meta['mhy_item']
detail = response.xpath("//*[@id='main']/div[3]/div/div[2]/div[2]/div[1]/div//text()").extract()
detail = ''.join(detail)[:12] # 我们这里只取前12个字吧
print(detail)
mhy_item['position_detail'] = detail
yield mhy_item
def parse(self, response):
position_lst = response.xpath("//div[@class='job-list']//li//span[@class='job-name']/a/text()").extract()
position_href = response.xpath("//div[@class='job-list']//li//span[@class='job-name']/a/@href").extract()
print(position_lst[:3])
for i in range(len(position_href)):
mhy_item = MihoyoItem()
mhy_item['position_title'] = position_lst[i]
yield scrapy.Request(url=position_href[i], callback=self.find_detail, cookies=self.cookies,
meta={'mhy_item': mhy_item,'proxy':'代理ip'})
if self.page <= 3:
new_url = format(self.urls % self.page)
self.page += 1
yield scrapy.Request(url=new_url, callback=self.parse, cookies=self.cookies,meta={'proxy':'代理ip'})
items.py
import scrapy
class MihoyoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
position_title = scrapy.Field()
position_detail = scrapy.Field()pipelines.py
class MihoyoPipeline:
fp = None
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('miHoYo.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
title = item['position_title']
detail = item['position_detail']
self.fp.write(title + '\n' + detail + '\n')
return item
def close_spider(self, spider):
self.fp.close()
print('爬虫结束')插入补充:Scrapy设置cookie的三种方式:
1.在settings中设置
settings文件中给cookies_enabled=False解除注释
settings的headers配置的cookie就可以用了
2.DownloadMiddleware
settings中给downloadmiddleware解除去注释
去中间件文件中找downloadmiddleware这个类,修改process_request,添加request.cookies={}即可。
3.爬虫主文件中重写start_request
(如上面的示例)记得cookies_enabled=True
注:
方法1的cookie可以直接粘贴浏览器的。
方法2、3添加的cookie是字典格式的而且需要设置settings中的cookies_enabled=True
2.7.Scrapy中间件
没错又是中间件,middlewares.py
新建一个项目,本次案例爬取网易新闻。
settings.py

经观察发现其内部信息为动态加载出来的数据,本次我们不强行找,用selenium。
netease.py
(当然也可以进一步提取再写个函数,这里只用作示例)
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from Netease.items import NeteaseItem
class NeteaseSpider(scrapy.Spider):
name = 'netease'
# allowed_domains = ['https://news.163.com/']
start_urls = ['https://news.163.com/']
# parse被执行多次但这个类只实例化一次
def __init__(self):
self.s = Service('../../chromedriver.exe')
self.bro = webdriver.Chrome(service=self.s)
def find_detail(self, response):
item = response.meta['item']
contant = ','.join(response.xpath('//div[@class="ndi_main"]//div[@class="news_title"]/h3/a/text()').extract())
item['contant'] = contant
yield item
def parse(self, response):
# 标题 我们只取几部分 下同
title = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li/a/text()').extract()[2:4]
# 列表栏链接地址
lst = response.xpath('//*[@id="index2016_wrap"]/div[2]/div[2]/div[2]/div[2]/div/ul/li/a/@href').extract()[2:4]
for i in range(len(lst)):
item = NeteaseItem()
item['title'] = title[i]
yield scrapy.Request(url=lst[i], callback=self.find_detail, meta={'item': item})
middlewares.py
(这里我们只先看NeteaseDownloaderMiddleware)
class NeteaseDownloaderMiddleware:
# ua伪装池
user_agent_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 Edg/97.0.1072.69'
]
# ip伪装池
PROXY_http = [
'1.14.122.251:1080',
'140.246.37.11:8888',
]
PROXY_https = [
'58.253.153.28:9999',
'182.116.232.154:9999',
]
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# UA伪装
request.headers['User-Agent'] = random.choice(self.user_agent_list)
# request.headers['cooikes']
return None
# 拦截所有的响应
def process_response(self, request, response, spider):
bro = spider.bro # 获取了在爬虫类中定义的浏览器对象
bro.get(request.url) # 五个板块对应的url进行请求
sleep(3)
page_text = bro.page_source # 包含了动态加载的新闻数据
new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)
return new_response
# 拦截发生异常的请求
def process_exception(self, request, exception, spider):
if request.url.split(':')[0] == 'http':
# 代理
request.meta['proxy'] = 'http://' + random.choice(self.PROXY_http)
else:
request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)
return request # 将修正之后的请求对象进行重新的请求发送
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)2.8. Scrapy的图片爬取
- 图片数据爬取之ImagesPipeline
- 基于scrapy爬取字符串类型的数据和爬取图片类型的数据区别?
- 字符串:只需要基于xpath进行解析且提交管道进行持久化存储
- 图片:xpath解析出图片src的属性值。单独的对图片地址发起请求获取图片二进制类型的数据
- ImagesPipeline:
- 只需要将img的src的属性值进行解析,提交到管道,管道就会对图片的src进行请求发送获取图片的二进制类型的数据,且还会帮我们进行持久化存储。
- 需求:爬取站长素材中的高清图片
- 使用流程:
- 数据解析(图片的地址)
- 将存储图片地址的item提交到制定的管道类
- 在管道文件中自定制一个基于ImagesPipeLine的一个管道类
- get_media_request
- file_path
- item_completed
- 在配置文件中:
- 指定图片存储的目录:IMAGES_STORE = './imgs_xx'
- 指定开启的管道:自定制的管道类
这次我们随便爬点图片
hunter.py
import scrapy
from imgs_hunter.items import ImgsHunterItem
class HunterSpider(scrapy.Spider):
name = 'hunter'
# allowed_domains = ['https://zhuanlan.zhihu.com/p/111568154']
start_urls = ['https://zhuanlan.zhihu.com/p/111568154/']
def parse(self, response):
srcs = response.xpath('//*[@id="root"]/div/main/div/article/div[1]/div/div/figure//img/@src').extract()
for i in srcs:
item = ImgsHunterItem()
item['src'] = i
yield item
pipelines.py
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class ImgsHunterPipeline(ImagesPipeline):
# 就是可以根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
# 指定图片存储的路径
def file_path(self, request, response=None, info=None):
imgName = request.url.split('/')[-1]
return imgName
def item_completed(self, results, item, info):
return item # 返回给下一个即将被执行的管道类items.py
import scrapy
class ImgsHunterItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
2.9. CrawlSpider
crawlspider是spider的子类,我们之前写的爬虫文件中用到了spider,这次我们使用crawlspider。
CrawlSpider主要用于全站数据的爬取,我们以后爬取全站数据除了像之前那样另写一个函数处理请求传参等,还可以用CrawlSpider。
新建一个项目:
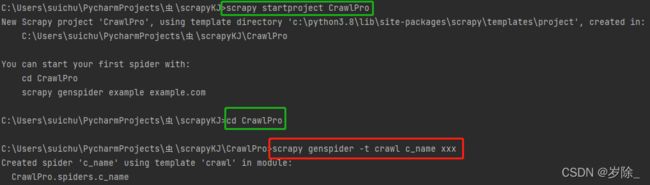 注意本次 scrapy genspider -t crawl example example.com
注意本次 scrapy genspider -t crawl example example.com
生成如下:

- 链接提取器 LinkExtractor:
- 作用:根据指定的规则(allow=正则)进行指定链接的提取
- 规则解析器 Rule:
- 作用:将链接提取器提取到的链接进行指定规则(callback)的解析
即假如我们爬取这个start_url里那个网站的选能显示页码的数据,连接提取器里面的正则匹配到这个页面的url,规则解释器回调函数就调用3次。
注意
1.rules内规定了对响应中url的爬取规则,爬取得到的url会被再次进行请求,并根据callback函数和follow属性的设置进行解析或跟进。
这里强调两点:一是会对所有返回的response进行url提取,包括首次url请求得来的response;二是rules列表中规定的所有Rule都会被执行。
2.allow参数没有必要写出要提取的url完整的正则表达式,部分即可,只要能够区别开来。且最重要的是,即使原网页中写的是相对url,通过LinkExtractor这个类也可以提取中绝对的url。
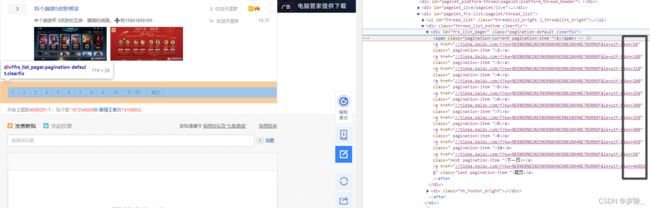
如以百度贴吧英雄联盟吧为例:
内容也是动态加载出来的 我们在中间件中加上selenium(略)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
class CNameSpider(CrawlSpider):
name = 'c_name'
# allowed_domains = ['xxx']
start_urls = ['https://tieba.baidu.com/f?ie=utf-8&kw=%E8%8B%B1%E9%9B%84%E8%81%94%E7%9B%9F']
rules = (
Rule(LinkExtractor(allow=r'pn=\d+'), callback='parse_item', follow=True),
# follow=True:可以将链接提取器 继续作用到 连接提取器提取到的链接 所对应的页面中 (调度器中又过滤器,会对重复的请求过滤掉)
)
def __init__(self):
self.s = Service('../../chromedriver.exe')
self.bro = webdriver.Chrome(service=self.s)
super().__init__()
def parse_item(self, response):
print(response)
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
return item(用__init__初始化时记得super().继承父类。)

假如follow=False 由于我们访问的页面是英雄联盟板块的第一页,因此我们只会获得

这些页的响应。
而当我们把Rule里的follow改为True时,它会跟进查找直到所有页码返回。
# follow=True:可以将链接提取器 继续作用到 连接提取器提取到的链接 所对应的页面中 (调度器中又过滤器,会对重复的请求过滤掉)
LinkExtractor的参数:
LinkExtractor(allow=(), deny=(), allow_domains=(),
deny_domains=(), deny_extensions=None,
restrict_xpaths=(), restrict_css=(),
tags=('a', 'area'), attrs=('href', ),
canonicalize=True, unique=True,
process_value=None)- allow(正则表达式(或的列表)) - 一个单一的正则表达式(或正则表达式列表),(绝对)urls必须匹配才能提取。如果没有给出(或为空),它将匹配所有链接。
- deny(正则表达式或正则表达式列表) - 一个正则表达式(或正则表达式列表),(绝对)urls必须匹配才能排除(即不提取)。它优先于allow参数。如果没有给出(或为空),它不会排除任何链接。
- allow_domains(str或list) - 单个值或包含将被考虑用于提取链接的域的字符串列表
- deny_domains(str或list) - 单个值或包含不会被考虑用于提取链接的域的字符串列表
- deny_extensions(list) - 包含在提取链接时应该忽略的扩展的单个值或字符串列表。如果没有给出,它将默认为IGNORED_EXTENSIONS在scrapy.linkextractors包中定义的 列表 。
- restrict_xpaths(str或list) - 是一个XPath(或XPath的列表),它定义响应中应从中提取链接的区域。如果给出,只有那些XPath选择的文本将被扫描链接。参见下面的例子。
- restrict_css(str或list) - 一个CSS选择器(或选择器列表),用于定义响应中应提取链接的区域。有相同的行为restrict_xpaths。
标签(str或list) - 标签或在提取链接时要考虑的标签列表。默认为。('a', 'area') - attrs(list) - 在查找要提取的链接时应该考虑的属性或属性列表(仅适用于参数中指定的那些标签tags )。默认为('href',)
- canonicalize(boolean) - 规范化每个提取的url(使用w3lib.url.canonicalize_url)。默认为True。
- unique(boolean) - 是否应对提取的链接应用重复过滤。
- process_value(callable) -
接收从标签提取的每个值和扫描的属性并且可以修改值并返回新值的函数,或者返回None以完全忽略链接。如果没有给出,process_value默认为。lambda x: x
当然也可以写多个Rule(LinkExtractor(),xx,xx)用于对页面内的详情部分发起请求,另写一个回调函数处理。
因为两个函数之间无法传递参数,所以可以在items中定义两个类如:
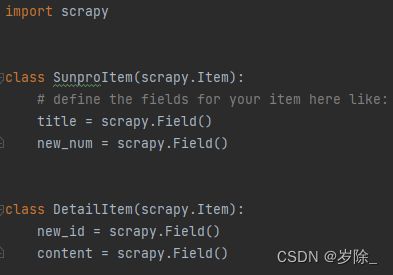
在pipelines.py中则要进行验证

写入数据时,由new_id与new_num相等的原理进行匹配,这里不做演示。
2.10. 分布式爬虫和增量式爬虫
分布式爬虫
笔记:
- 分布式爬虫
- 概念:我们需要搭建一个分布式的机群,让其对一组资源进行分布联合爬取。
- 作用:提升爬取数据的效率
- 如何实现分布式?
- 安装一个scrapy-redis的组件
- 原生的scarapy是不可以实现分布式爬虫(管道不共享),必须要让scrapy结合着scrapy-redis组件一起实现分布式爬虫。
- 为什么原生的scrapy不可以实现分布式?
- 调度器不可以被分布式机群共享
- 管道不可以被分布式机群共享
- scrapy-redis组件作用:
- 可以给原生的scrapy框架提供可以被共享的管道和调度器
- 实现流程
- 创建一个工程
- 创建一个基于CrawlSpider的爬虫文件
- 修改当前的爬虫文件:
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 将start_urls和allowed_domains进行注释
- 添加一个新属性:redis_key = 'sun' 可以被共享的调度器队列的名称
- 编写数据解析相关的操作
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 修改配置文件settings
- 指定使用可以被共享的管道:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 指定调度器:
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定redis服务器:
- redis相关操作配置:
- 配置redis的配置文件:
- linux或者mac:redis.conf
- windows:redis.windows.conf
- 代开配置文件修改:
- 将bind 127.0.0.1进行删除
- 关闭保护模式:protected-mode yes改为no
- 结合着配置文件开启redis服务
- redis-server 配置文件
- 启动客户端:
- redis-cli
- 执行工程:
- scrapy runspider xxx.py
- 向调度器的队列中放入一个起始的url:
- 调度器的队列在redis的客户端中
- lpush xxx www.xxx.com
- 爬取到的数据存储在了redis的proName:items这个数据结构中
增量式爬虫
笔记:
增量式爬虫
- 概念:监测网站数据更新的情况,只会爬取网站最新更新出来的数据。
- 分析:
- 指定一个起始url
- 基于CrawlSpider获取其他页码链接
- 基于Rule将其他页码链接进行请求
- 从每一个页码对应的页面源码中解析出每一个电影详情页的URL
- 核心:检测电影详情页的url之前有没有请求过
- 将爬取过的电影详情页的url存储
- 存储到redis的set数据结构
- 对详情页的url发起请求,然后解析出电影的名称和简介
- 进行持久化存储