Redis原理(1) 内存全面详解
一. 我们怎么观察线上Redis内存
我们如果在我们的redis.conf配置文件里面配置:
# 最大内存设置,100M
maxmemory 104857600
查看redis内存信息 (info Memory)
172.29.2.11:7002> info Memory
# Memory
used_memory:2598042
used_memory_human:2.48M
used_memory_rss:3002368
used_memory_rss_human:2.86M
maxmemory:104857600
maxmemory_human:100.00M
mem_fragmentation_ratio:1.16
....
先大致看下几个字段的概念:
- 1. maxmemory
用户配置的(maxmemory )最大内存量, maxmemory_human 人能看懂的单位。
- 2. used_memory
Redis使用的内存总量,它包含了实际缓存占用的内存(包含虚拟内存)和Redis自身运行所占用的内存(如元数据、lua)。它是由Redis使用内存分配器分配的内存,所以这个数据并没有把内存碎片的内存给统计进去。
- 3. used_memory_rss
从操作系统角度看redis进程占用的内存量。包括进程运行本身需要的内存、内存碎片等,但是不包括虚拟内存。
- 4. mem_fragmentation_ratio
used_memory_rss/used_memory的值,可以代表碎片化。
mem_fragmentation_ratio越大,used_memory_rss就越大,内存碎片就越大。
mem_fragmentation_ratio小于1时,代表使用了过多的虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。
那问题来了,内存碎片是什么?怎么产生的? 虚拟内存又是什么?如何能产生?
带着这些问题,我又薅掉了些自己仅存的几根头发,又欣喜的瞄了下对面老大的光头,并发誓我一定不会变成这样!就是带着这伟大的理想,我做了下面的事情。
二. Redis内存碎片实战
首先我配置maxmemory为100M ,然后写程序一直set key value 到 内存爆满后(注意是不同的key),直到程序抛出OOM异常:

然后我查看了下此时内存信息

used_memory_rss和used_memory 都达到了100M,证明内存已经打满了。
但是我们的mem_fragmentation_ratio 还很正常,于是我执行了下flushdb,删除当前数据库所有key。
172.29.2.10:7000> flushdb
OK
172.29.2.10:7000> info Memory
# Memory
used_memory:2617096
used_memory_human:2.50M
used_memory_rss:112009216
used_memory_rss_human:106.82M
...
mem_fragmentation_ratio:42.80
然后惊奇的发现: used_memory被释放了,但是used_memory_rss 还是雷打不动。mem_fragmentation_ratio内存碎片比达到了42.8之多,碎片化很严重。如果此时不清理掉碎片, 会导致redis重新设置大key时没法存放,这很严重。
Redis为什么这么做?
Redis有自己的内存分配器(jemalloc),当数据删除后,释放的内存空间由Redis自己的内存分配器管理,并没有立即将内存返回给操作系统,所以对于操作系统而言,仍然认为Redis占用了内存。这样的好处是,减少Redis向系统申请内存分配的次数,提升Redis自身性能。
jemalloc简单介绍
Redis在编译时便会指定内存分配器;内存分配器可以是 libc 、jemalloc或者tcmalloc, 默认是jemalloc。
jemalloc 内存分配方式为 按照一系列固定大小分配内存空间,jemalloc 按照申请的内存大小分配最接近的内存空间;
比如申请220字节,jemalloc 会分配256字节,如果还要继续写入20字节,Redis则不会继续向系统申请内存空间,直接写。
总而言之 : 按页分配内存,而不是按实际数据大小来分配,碎片产生的原因就是页内部分数据回收了,这个页还是占着空间。
三. Redis使用虚拟内存实战
首先我们在redis.conf配置文件配置虚拟内存:
# #开启虚拟内存
vm-enabled yes
# #交换出来的value保存的文件路径
vm-swap-file /usr/local/app/redis-cluster/7002/redis.swap
# #redis使用的最大内存上限
vm-max-memory 134857600然后启动居然报错了:
*** FATAL CONFIG FILE ERROR ***
Reading the configuration file, at line 26
>>> 'vm-enabled yes'
Bad directive or wrong number of arguments最后发现,据说redis2.6后面的版本已经把虚拟内存配置去掉了。~~~
此时,仿佛看到了一位不负责的男一号,疯狂的肆虐着女一号,女二号,女三号.... 为啥后面版本去掉了,我也不清除,我就简单介绍下虚拟内存思想吧:
redis 发现大部分数据都是冷数据(不常访问的数据),于是搞出虚拟内存来专门存放这些冷数据,这样就可以大大节省实际内存空间。 但是redis虚拟内存只是存储value,而不存储key。
好了我就知道这么多,即使你用虎头铡 我也只能言尽了~
四. Redis OOM
在上面有个环节,redis报了oom,原因就是使用的内存已经超过了配置的maxmemory。
## 客户端报错
OOM command not allowed when used memory > ‘maxmemory’
此时redis进程还是在的,并没有崩溃。如果在设置值也可能会设置进去,取决与下面这个配置:
maxmemory-policy volatile-lru
maxmemory-policy 为 内存达到峰值后,淘汰现有key,以便接受新数据 的策略,有下面几个可选参数:
- noeviction: 不淘汰现有key,直接返回异常,不再接受set key了。
- allkeys-lru: 优先删除掉最近最不经常使用的key,用以保存新数据。
- volatile-lru: 删除 最近不常使用的 且 设置了过期时间的key 。
- allkeys-random: 随机从all-keys中选择一些key进行删除。
- volatile-random: 只从设置失效(expire set)的key中,选择一些key进行删除。
- volatile-ttl: 只从设置失效(expire set)的key中,选出存活时间(TTL)最短的key进行删除,用以保存新数据。
毫无疑问,线上配置 volatile-lru 就可以了。
那么问题来了,我们怎么去排查是哪些key有问题呢?肯定是有大量key占着茅坑不拉屎的。
五. Redis OOM后,大key的排查
首先我们不要慌~ 要先观察老大的微表情,必要的时候扇下风,这什么鬼Redis机器,内存这么小! 然后老大就对你刮目了,小伙子这么快就知道原因了,于是马上通知运维,升级,搞定~~~
不过我们是一个负责的程序员,于是我们先执行下命令:
127.0.0.1:7001> info Keyspace
# Keyspace
db0:keys=37801,expires=22759,avg_ttl=35832230364
- keys 总key数:37801
- expires 带过期的key : 22759
- avg_ttl 平均过期时间
在使用 bigkeys 查看下内存占用最多的key
[root@localhost redis-cluster]# redis-cli -p 7001 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '127.1761.661.1021' with 3931 bytes
[00.03%] Biggest string found so far '127.661.651.971' with 4372 bytes
[00.03%] Biggest string found so far '127.311.2361.61' with 4428 bytes
[00.03%] Biggest string found so far '127.801.2211.111' with 4676 bytes
[00.08%] Biggest string found so far '127.2471.801.2511' with 4918 bytes
[00.41%] Biggest string found so far '127.121.501.901' with 4945 bytes
[00.63%] Biggest string found so far '127.291.1181.2461' with 4980 bytes
[00.90%] Biggest string found so far '127.441.1481.2311' with 4998 bytes
[14.36%] Biggest string found so far '127.1251.1911.1921' with 4999 bytes
-------- summary -------
Sampled 37801 keys in the keyspace!
Total key length in bytes is 631318 (avg len 16.70)
Biggest string found '127.1251.1911.1921' has 4999 bytes
37801 strings with 94531257 bytes (100.00% of keys, avg size 2500.76)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
127.1761.661.1021 , 127.661.651.971 ... 这些就是我们的大key ,我们看下是什么
############先查看key 的类型 ,然后在取值
127.0.0.1:7001> type 127.1761.661.1021
string
127.0.0.1:7001> get 127.1761.661.1021
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
接下来如果觉得key不重要就批量删除吧: 可以用scan命令配合某个脚本语言删。不过我们还要通过一个python写的工具rdbtools。
rdbtools的使用
rdbtools工具是一款redis rdb数据文件分析工具,相比redis自带的info命令来说,rdbtools可以非常方便的将key的数量、大小等信息进行分析统计。
安装rdbtools (python2.7环境)
[root@localhost local]# wget https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz
[root@localhost local]# tar -zxvf pip-1.5.4.tar.gz
[root@localhost local]# cd pip-1.5.4
[root@localhost local]# python setup.py install
[root@localhost local]# pip install rdbtools进入Redis 的rdb文件目录,然后执行导出csv文件
[root@localhost redis-cluster]# rdb -c memory dump.rdb > redis.csv打开csv
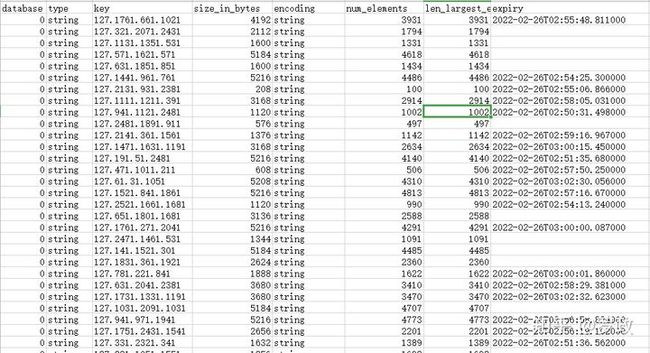
生成报表字段有:
- database(key在redis的db)
- type(key类型)
- key(key值)
- size_in_bytes(key的内存大小)
- encoding(value的存储编码形式)
- num_elements(key中的value的个数)
- len_largest_element(key中的value的长度)
- expiry (过期时间)
到此redis里面所有的key都已经导出来了,尽情的去分析把~
六. Redis 内存的一些理论
(1)redis数据结构概述
redis最底层数据结构是一个redisDb结构体
/* Redis数据库结构体 */
typedef struct redisDb {
// 数据库键空间,存放着所有的键值对(键为key,值为相应的类型对象)
dict *dict;
// 键的过期时间
dict *expires;
// 处于阻塞状态的键和相应的client(主要用于List类型的阻塞操作)
dict *blocking_keys;
// 准备好数据可以解除阻塞状态的键和相应的client
dict *ready_keys;
// 被watch命令监控的key和相应client
dict *watched_keys;
// 数据库ID标识
int id;
// 数据库内所有键的平均TTL(生存时间)
long long avg_ttl;
} redisDb;
dict : dict是一种用于维护key和value映射关系的数据结构(类似Map),里面存储着该数据库中所有的键值对数据,该字段又称为键空间key space。
dict的结构图:
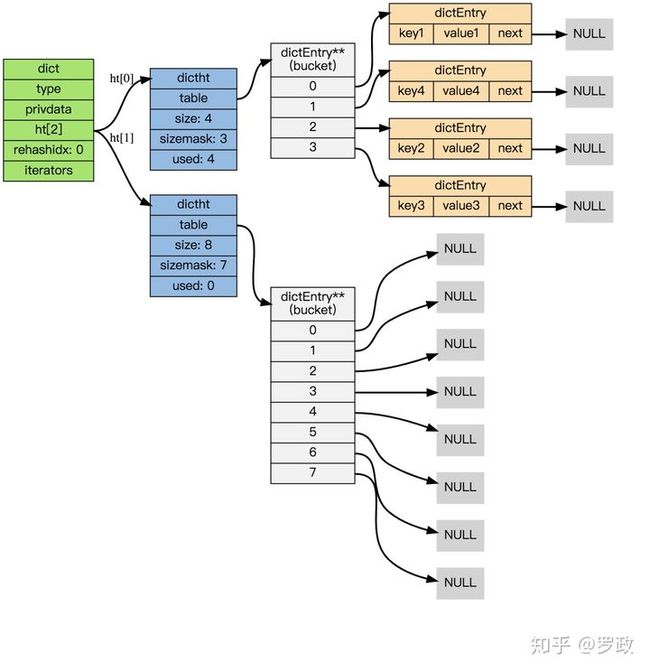
dict 结构体
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录 rehash 进度的标志,值为 -1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict;
我们重点关注下2个哈希表 dictht ht[2]:
只有在 rehash 的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
当redis有数据要set ,通过redisDb 0 对象拿到dict ,然后从dict里面找到ht[0] , 然后根据key结合hash算法算出table数组(bucket)的位置,然后看bucket位置是否有数据,有的话就拉成链表,这其实就是跟java的HashMap类似。【实际并没这么简单,这里只是大概思想】
就像下图一样:
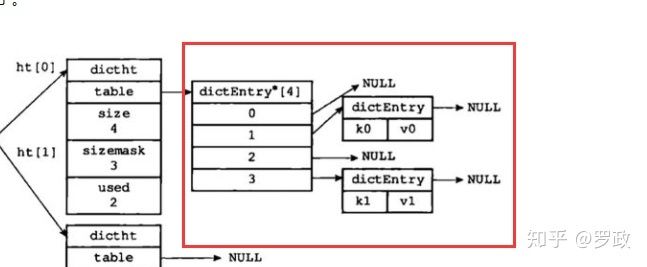
图解释: 两张哈希表(ht[0] ,ht[1] ),其中一个的值为 null, 另外一个哈希表的 size=4, 其中两个位置上已经存放了具体的键值对,而且没有发生 hash 冲突。
dictEntry对象 暂且认为里面就是存了真实的key和value的对象。下面会详解。
扩容与缩容
当哈希表过于拥挤,查找效率就会下降,当 hash 表过于稀疏,对内存就有点太浪费了,此时就需要进行相应的扩容与缩容操作(大量key过期了,就要缩容)。
负载因子
负载因子是用来描述哈希表当前被填充的程度。计算公式是:负载因子=哈希表以保存节点数量 / 哈希表的大小.
在 Redis 的实现里,扩容缩容有三条规则:
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,且
负载因子>1的时候进行扩容。 - 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,
负载因子>5的时候,强行进行扩容。 - 当
负载因子<0.1的时候,进行缩容。
扩容时的rehash
我们回顾下java 的HashMap的扩容,是重新构造entry数组,然后全部数据rehash,都是一次性操作完成的。
但是对于redis大字典操作是很好耗时的,于是采用 渐进式hash。过程如下:
- 假如当前数据在 ht[0] 中,那么首先为 ht[1] 分配足够的空间。
- 在字典中维护一个变量,rehashindex = 0. 用来指示当前 rehash 的进度。
- 在 rehash 期间,每次对 字典进行 增删改查操作,在完成实际操作之后,都会进行 一次 rehash 操作,将 ht[0] 在
rehashindex位置上的值 rehash 到 ht[1] 上。将 rehashindex 递增一位。 - 随着不断的执行,原来的 ht[0] 上的数值总会全部 rehash 完成,此时结束 rehash 过程。 将 rehashindex 置为-1。
在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
渐进式rehash带来的问题
渐进式rehash避免了redis阻塞,可以说非常完美,但是由于在rehash时,需要分配一个新的hash表,在rehash期间,同时有两个hash表在使用,会使得redis内存使用量瞬间突增,在Redis 满容状态下由于Rehash会导致大量Key驱逐(淘汰)。
下面是哈希表大小和内存申请大小的对应关系图:

rehash内存不足淘汰key的实践案例:
https://luoming1224.github.io/2018/11/14/[redis%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0]redis%20rehash%E6%9C%BA%E5%88%B6%E5%AF%BC%E8%87%B4%E6%95%B0%E6%8D%AE%E6%B7%98%E6%B1%B0%E5%88%86%E6%9E%90/luoming1224.github.io
(2)dictEntry 数据存储细节
当我们执行redis命令
127.0.0.1:7000> set hello world
-> Redirected to slot [8175] located at 172.29.2.11:7000
OK 会出现以下数据模型
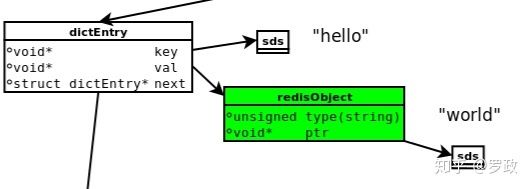
dictEntry(32bits)
每个redis key value 都对应成 dictEntry 结构体,里面有 指向key和value 的指针。next 是指向下一个dictEntry 。总共有3个指针组成,在64位机器下占24个字节,jemalloc会为它分配32字节大小的内存单元。
key指针
注意 key指针指向一个sds结构的字符串存储,并不是一个简单的char*。sds字符串后面讲。
val指针
val指针指向一个redisObject结构体,代表redis的value存储。
(2)redisObject详解
redisObject实际上是下面结构:
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; // 编码
unsigned lru:REDIS_LRU_BITS; // 对象最后一次被访问的时间
int refcount; // 引用计数
void *ptr; // 指向实际值的指针
} robj;
type(4bits)
redis对象的类型,REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
encoding(4bits)
对象的内部编码。也就是说对象使用了什么数据结构作为底层实现,有下面几种编码实现:
| 编码常量 | 编码所对应的底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典 |
每种类型的对象提供了至少2种不同的编码实现:
| 类型 | 编码 | 对象 |
|---|---|---|
| REDIS_STRING | REDIS_ENCODING_INT | 整数值实现的字符串对象 |
| REDIS_ENCODING_EMBSTR | embstr编码实现的简单动态字符串实现的字符串对象 | |
| REDIS_ENCODING_RAW | 简单动态字符串实现的字符串对象 | |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 压缩列表实现的列表对象 |
| REDIS_ENCODING_LINKEDLIST | 双端链表实现的列表对象 | |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 压缩列表实现的哈希对象 |
| REDIS_ENCODING_HT | 字典实现的哈希对象 | |
| REDIS_SET | REDIS_ENCODING_INTSET | 整数集合实现的集合对象 |
| REDIS_ENCODING_HT | 字典实现的集合对象 | |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 压缩列表实现的有序集合对象 |
| REDIS_ENCODING_SKIPLIST | 跳表实现的有序集合对象 |
以上面列表对象(REDIS_LIST)为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
OBJECT ENCODING 查看编码方式
172.29.2.11:7000> OBJECT ENCODING OnePiece
embstr
172.29.2.11:7000>
lru(24bits)
记录对象最后一次被命令程序访问的时间。可以用来判断key 多久没有被程序使用过了,比如 object idletime命令 :查看key多少秒没有被访问过了。
172.29.2.11:7000> OBJECT idletime OnePiece
852
172.29.2.11:7000> OBJECT idletime OnePiece
853
172.29.2.11:7000> OBJECT idletime OnePiece
854
172.29.2.11:7000> OBJECT idletime OnePiece
855
172.29.2.11:7000> OBJECT idletime OnePiecerefcount (4byte)
refcount记录的是该对象被引用的次数。Redis在自己的对象系统中构建了一个引用计数技术实现的内存回收技术。创建一个新对象时,refcount会被初始化为1,当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
refcount 还用于redis共享对象的查看,如果 执行 set a 10 和 set b 10 这两条命令,redis不会开辟两个redisObject空间, 而是让两个key共享,如果有一个key共享了,那么redisObject的refcount就加1 。
ptr(8byte)
ptr指针指向具体的数据,是一个sds字符串。
我们可以算出一个redisObject的大小 16字节
4bit+4bit+24bit+4byte+8byte=16byte (8bit=1byte)
(3)SDS字符串
sds (Simple Dynamic String,简单动态字符串)是 Redis 底层所使用的字符串表示, 几乎所有的 Redis 模块中都用了 sds。
为什么redis不用简单的char * 而是用sds?我们来看下sds结构体:
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
当redis存储hello world 字符串时,sds是这样的:
struct sdshdr {
len = 11;
free = 0;
buf = "hello world\0"; // buf 的实际长度为 len + 1
};
通过 len 属性, sdshdr 可以实现复杂度为 θ(1) 的长度计算操作。
当我们使用append命令追加字符串 abcdef时:
struct sdshdr {
len = 18;
free = 18;
buf = "hello world abcdef\0 "; // 空白的地方为预分配空间,共 18 + 18 + 1 个字节
}
注意, 当调用 SET 命令创建 sdshdr 时, sdshdr 的 free 属性为 0 , Redis 也没有为 buf 创建额外的空间 —— 而在执行 APPEND 之后, Redis 为 buf 创建了多于所需空间一倍的大小。这样以后在append 当小于18时,就不会在额外分配空间。
当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。(字符串最大长度为512M)
总结 sds 的好处
- 计算长度len,复杂度是θ(1)。
- 高效的追加,通过预分配,降低内存分配。
讲了些浅显的知识给大家,望海涵。而且有些redis版本可能与文章知识稍稍不一致。下章讲下有了这些知识,怎么去极致优化redis内存。
强烈推荐一个 进阶 JAVA架构师 的博客
Java架构师修炼githubs.xyz