Hive基本操作
Hive产生背景:
mapreduce编程的不便性
HDFS上文件缺少Schema (Schema:关系型数据库里面创建一张表,需要创建表名、列的名称、列的类型,每个字段的分隔符),如果没有Schema,就无法对分布式文件上的数据进行相应的查询。
hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
Hive:
(1)facebook开源,用于解决海量结构化的日志数据统计问题
(2)构建在Hadoop之上的数据仓库
(3)Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同)
(4)通常用于进行离线数据处理(刚刚开始时是采用MapReduce)
(5)目前底层支持多种不同的执行引擎
Hive底层的执行引擎有:MapReduce、Tez、Spark
Hive on MapReduce
Hive on Tez
Hive on Spark
(6)支持多种不同的压缩格式、存储格式以及自定义函数
压缩:GZIP、LZ0、Snappy、BZIP2……
存储:TextFile、SequenceFile、RCFile、ORC、Parquet。默认是TextFile,一般可选用RCFile,也可以选择ORC。
UDF:自定义函数
java写一个自定义udf函数
//删除原有的函数
drop function default.w2v_vector;
//创建新函数,读取jar包中的类,jar包需要上传到hdfs或s3。
create function w2v_vector as 'xxx.udf.W2VVector' using jar 's3://mildom/hive/jar/xxx-udf-1.0.0-jar-with-dependencies.jar';
然后这个函数可以在写hive sql时直接使用。
Hive体系架构及部署架构
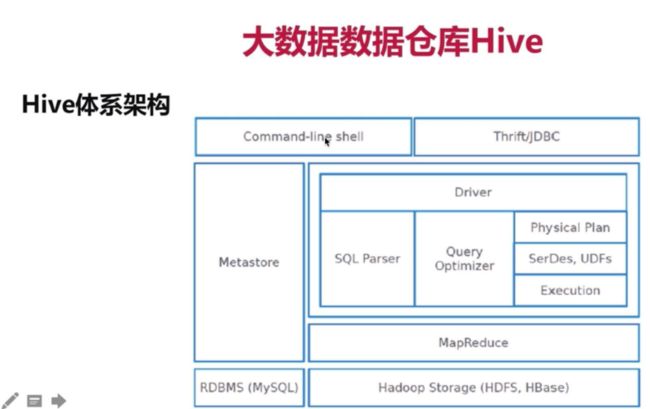
通过hive脚本和JDBC来访问hive
Hive环境搭建
Hive环境搭建
1)Hive下载:http://archive.cloudera.com/cdh5/cdh/5/
wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
2)解压
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/
3)配置
系统环境变量(~/.bash_profile)
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
实现安装一个mysql, yum install xxx
hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/sparksql?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
root
4)拷贝mysql驱动到$HIVE_HOME/lib/
5)启动hive: $HIVE_HOME/bin/hive
Hive基本使用
启动hive前要先启动HDFS和mysql,否则无法启动。
./start-dfs.sh hadoop启动HDFS
启动hive:在sbin目录下执行: ./start-dfs.sh
创建表
CREATE TABLE table_name
[(col_name data_type [COMMENT col_comment])]
CREATE TABLE IF NOT EXISTS TableName
CREATE EXTERNAL TABLE IF NOT EXISTS TableName
PARTITIONED BY (day bigint)
STORED AS ORC
LOCATION 's3://mildom/hive/${DATA_BASE}.db/${DATA_TABLE}
COMMENT关键字为字段注释(comment = 表注释内容)
CREATE EXTERNAL TABLE table_name
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table)
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
虽然说,建立外部表会使用LOCATION指定位置,而建立内部表不使用LOCATION,会默认保存在/hive/warehouse/下,自动生成一个目录,目录名为表名。
但是通过一系列对比,我们可以发现,这两个参数之间是没有关系的。
我们可以建立外部表,不使用LOCATION;也可以建立内部表,使用LOCATION。
所以我们是否会在HDFS上看到生成新的目录,取决于是否使用LOCATION,而不是外部表、内部表的关系。
删除表
DROP TABLE IF EXISTS TableName
加载数据到hive表
LOAD DATA LOCAL INPATH 'filepath' INTO TABLE tablename
load data local inpath '/home/hadoop/data/hello.txt' into table hive_wordcount;
为单词计数
select word, count(1) from hive_wordcount lateral view explode(split(context,'\t')) wc as word group by word;
拆分列为行:
lateral view explode(): 是把每行记录按照指定分隔符进行拆解
where是在表中查询,作用于表中的列,所以where不能放在group by的后面,而having是作用于查询结果中的列,group by 之后可以用having来过滤。
例如:
select s_id,avg(s_score) as avgScore from score
group by s_id
having avgScore > 60;
拆分列为多列
select split("116:151:1", '\\:')[0] as gid
, split("116:151:1", '\\:')[1] as sid
, split("116:151:1", '\\:')[2] as rid
from table
hiveql提交执行以后会生成mr作业,并在yarn上运行
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
create table dept(
deptno int,
dname string,
location string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/home/hadoop/data/emp.txt' into table emp;
load data local inpath '/home/hadoop/data/dept.txt' into table dept;
求每个部门的人数
select deptno, count(1) from emp group by deptno;
Hive下查看数据表信息的方法
方法1:查看表的字段信息,describe该表
desc table_name;
方法2:查看表的字段信息及元数据存储路径
desc extended table_name;
方法3:查看表的字段信息及元数据存储路径
desc formatted table_name;
当日期精确到小时的时候例如2019121206,用substring切取前面八位。字段内容过滤用in和括号。
SELECT app
from table_name
where substring(stat_date,0,8) = 20180913 and app in ('com.taobao.taobao', 'com.xunmeng.pinduoduo', 'com.jingdong.app.mall', 'com.achievo.vipshop', 'com.xingin.xhs', 'com.tmall.wireless')
删除分区(例如分区为日期)
ALTER TABLE table_name DROP IF EXISTS PARTITION (stat_date = "20180625")
alter table table_name drop if exists partition (stat_date>='20181102',stat_date<='20181104')
删除date&hour两个分区(删除昨天的分区数据,hour_1ago为‘date_1ago’+‘23’,设置了两个分区)
ALTER TABLE table_name DROP IF EXISTS PARTITION(day=${date_1ago},hour=${hour_1ago});
添加分区
ALTER TABLE table_name IF NOT EXISTS ADD PARTITION (p_hour='2017113003', p_city='573', p_loctype='MHA');
转换数据格式(类型)
select umid,cast(cnt_active_day_7 as double) from tablename
查看制表信息(可以查看在hdfs/s3中的location)
show create table tablename
表重命名
alter table old_table_name rename to new_table_name
添加字段(添加列)
添加hour字段
alter table table_name add columns(hour bigint)
alter table table_name change hour HOUR string after user_name
需要调整位置和注释可以如下:
ALTER TABLE table_name CHANGE col_old_name col_new_name column_type AFTER column_name
改变列名/类型/位置/注释
ALTER TABLE table_name CHANGE
[CLOUMN] col_old_name col_new_name column_type
[CONMMENT col_conmment]
[FIRST|AFTER column_name];
这个命令可以修改表的列名,数据类型,列注释和列所在的位置顺序,FIRST将列放在第一列,AFTER col_name将列放在col_name后面一列,
只改列名:
ALTER TABLE name CHANGE column_name new_name new_type
删除字段
建表语句,如果已经建过表了则可以忽略该语句
create table table_name (
column_1 string,
column_2 int);
删除column_2
alter table table_name replace columns(
column_1 string); --column_2不写,即删除column_2,保留column_1
类型转换 cast(value AS TYPE)
SELECT name, salary FROM employees WHERE cast(salary AS FLOAT) < 100000.0;
这里把整数转化为浮点数再比较
如果需要把浮点数转化为整数,推荐round()或floor()函数,不推荐使用cast
If函数:if和case类似,都是处理单个列的查询结果
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值: T
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
举例:if(条件表达式,结果1,结果2)相当于java中的三目运算符,只是if后面的表达式类型可以不一样。
if中的等于条件用“=”或“==”均可
hive> select if(a=a,’bbbb’,111) from dual;
bbbb
hive> select if(1<2,100,200) from dual;
200
可以和其他函数和字段组合使用,例如计算30天内的观看时长:
hive>select sum(if(CreateTime>"2020-10-10 00:00:00"),WatchTime,0) as recent_watch_time from dual;
CASE WHEN THEN语句和if条件语句类似,用于处理单个列的查询结果:
SELECT name,salary,
CASE
WHEN salary < 50000.0 THEN 'low'
WHEN salary >= 50000.0 AND salary < 70000.0 THEN 'middle'
WHEN salary > 70000.0 AND salary<100000.0 THEN 'high'
ELSE 'very high'
END AS bracket FROM employees;
|name|salary|bracket|
|KEVIN|100000|high|
NVL函数
NVL(expr1, expr2):空值转换函数
备注:
1、如果expr1为NULL,返回值为 expr2,否则返回expr1。
2、适用于数字型、字符型和日期型,但是 expr1和expr2的数据类型必须为同类型。
decode(binary bin, string charset)返回string
使用默认编码类型且只能指定一个编码类型,将第一个参数解码为字符串,如果任何一个参数为null,返回null。可选编码类型为: 'US_ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16'
unbase64(string str)返回binary
将base64字符串转换为二进制
对某一个需要提取特征的文本列,可以如此转码。
select decode(unbase64(col_name), 'utf-8') from table_name
distinct 取唯一
select distinct name, id from table
获取最新分区,按照日期stat_date字段分区的数据,有时候会出现数据阻塞,
规定时间内数据没有跑出来,那么为了不影响业务使用,到规定时间内当天数据没有出来则取最近的日期数据上报
select t2.*
from (select max(stat_date) as latest_op_day from algo.wallpaper_user_recommend) t1
join algo.wallpaper_user_recommend t2
on t1.latest_op_day = t2.stat_date
常用join的用法,查看两次表里面性别不一致的人:
select a.flymeid,a.sex,b.flyme_id,b.sex from (select flymeid,case when q1 = 'A' THEN '1' when q1 = 'B' THEN '2' ELSE 'unknown' END as sex from algo.wy_questionnaire_data_new) a join (select flyme_id,sex from user_profile.ods_question_answer_by_flyme) b on a.flymeid=b.flyme_id where a.sex != b.sex
全连阶FULL OUTER,合并key
SELECT
COALESCE(a.ID, b.ID, c.ID) AS ID
,COALESCE(a.Attr, b.Attr, c.Attr) AS Attr
FROM TA a
FULL OUTER JOIN TB b ON (a.ID = b.ID)
FULL OUTER JOIN TC c ON (a.ID = c.ID OR b.ID = c.ID)
hive交集
left semi join: 并不拼接两张表,两个表对 on 的条件字段做交集,返回前面表的记录,相较于其他的方法,这样子 hive 处理速度比较快。
排序
SELECT cast(substring(value_str,14,13) AS bigint) AS key FROM src SORT BY key ASC
SELECT cast(substring(value_str,14,13) AS bigint) AS key FROM src SORT BY key DESC
hive中在不需要全局排序的情况下,写排序语句时,最好用distribute by 表中字段名 sort by 表中字段名 asc | desc 的形式,尽量不用order by形式。
distribute by通常用来缓解数据倾斜的问题,在sql结尾加上distribute by rand(),
可以控制map数据的结果,保证每个分区的数据量基本一致。
distribute by关键字控制map输出结果的分发,相同字段的map输出会发到一个reduce节点去处理。sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序,每一个reducer产生一个排序文件,所以不是全局排序。使用sort by可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
#相同的col_name会倒序排在一起
select * from table_name distribute by col_name sort by col_name desc;
#更常见的用法,全局排序,distribute by用在ID列上控制map,然后、后sort by把想要排序的字段放到一个reducer中全局排序。
select * from table_name distribute by ID_col_name sort by col_name desc;
#另一种用法,distribute by用在ID列上控制map,然后sort by把想要排序的多个字段放到一个reducer中全局排序。
select * from table_name distribute by ID_col_name sort by ID_col_name asc,col_name desc;
#结果是所有相同的ID_col_name组合在一起并升序排排列,col_name列为降序。
ID_name col_name
1 3
1 1
2 8
3 5
3 4
3 1
Distribute by和sort by的使用场景
1.Map输出的文件大小不均。
2.Reduce输出文件大小不均。
3.小文件过多。
4.文件超大。
cluster by相当于distribute by组合sort by用法,但是只能升序
collect_list和collect_set函数
这两个函数是用来做聚合,区别是collect_set会去重。
网上的例子:
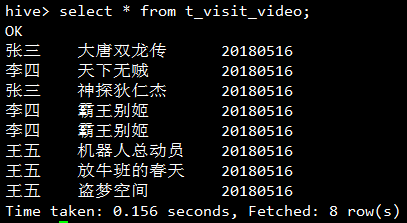
按用户分组,取出每个用户每天看过的所有视频的名字:
select username, collect_list(video_name) from t_visit_video group by username ;

去重的结果
select username, collect_set(video_name) from t_visit_video group by username;

collect_set很多时候和concat_ws搭配使用。
select user_id,concat_ws(',',collect_set(follow_user_id)) as follow_user_ids
group by user_id
COALESCE函数:
COALESCE是一个函数, (expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。
比如我们要登记用户的电话,数据库中包含他的person_tel,home_tel,office_tel,我们只要取一个非空的就可以,则我们可以写查询语句
select COALESCE(person_tel,home_tel,office_tel) as contact_number from Contact;
使用实例:
这个参数使用的场合为:假如某个字段默认是null,你想其返回的不是null,而是比如0或其他值,可以使用这个函数
SELECT COALESCE(field_name,0) as value from table;
select coalesce(a,b,c);
参数说明:如果a==null,则选择b;
如果b==null,则选择c;
如果a!=null,则选择a;
如果a b c 都为null ,则返回为null。
切分字符串
//当日期精确到小时的时候例如2019121206,用substring切取第二个元素后面的前面八位。
SELECT imei,search,app,match_kw as keyword
from mzreader.ods_stream_search_action_overall
where substring(stat_date,2,8) = 20180913 and app in ('com.taobao.taobao', 'com.xunmeng.pinduoduo', 'com.jingdong.app.mall')
时间戳和json格式处理
时间戳转化成普通日期格式使用hive自带的udf:from_unixtime,后面可以转换得出的格式,比如只要年月日可以写成:'yyyyMMdd'。
get_json_object用来解析json
这里是取了一个json格式的字段里的timestamp
select from_unixtime(cast(get_json_object(字段名字,'$.timestamp') as bigint),'yyyyMMdd HH:mm:ss') from hive表名
日期偏移
--返回当前日期:current_date() 使用这个方法的时候要注意,服务区的区时不一定是北京时间,比如使用的是世界区时GMT,就要用这个代替要在GMT加上8小时:substring(from_utc_timestamp(current_timestamp(),'GMT+8'),1,10)
--自定义日期操作函数(返回带横线的日期):get_date
select get_date();--返回当前日期,返回 2020-02-09
select get_date(-2);--返回当前日期往前偏移2天的日期 ,返回 2020-02-07
--自定义日期操作函数(返回不带横线的日期):get_dt_date
select get_dt_date();--获取当前日期,返回 20200209
select get_dt_date(get_date(-2));--获取当前日期偏移,转为不带横杆的格式
select get_dt_date('2020-02-02',-2);--20200131
#####日期函数(比较,往后推,往前推),通常需要用from_unixtime转化成对应格式再比较
datediff(string enddate,string startdate)
select datediff('2000-01-30','2000-01-29') //比较相差几天,这里是一天
date_add(string startdate, intdays)
select date_add('2000-01-01',10)//开始日期往后推10天
date_sub (string startdate,int days)
select date_sub('2000-01-01',10)//开始日期往前推10天
所以去当前前10天的数据就可以写成
select * from table where datediff(current_timestamp,stat_date)<=10
其中stat_date是表里的当前的时间,current_timestamp直接返回当前时间
或者
date是当前取到的日期
select * from table where stat_date<='date' and stat_date>date_sub('date',10)
这种更好理解一些。
有的时候时间不是这个格式,那就需要用from_unixtime处理一下,再用replace把"-"删除
select replace(date_sub(from_unixtime(unix_timestamp('20181224','yyyyMMdd'),'yyyy-MM-dd'),60),'-','')
有时候把不同格式的数据进行比较会报错,比如比较日期,一个是bigint(20191111),一个是string('20191212'),日志会报错会有sethive.strict.checks.type.safety to false的字样
在代码前加上set hive.strict.checks.type.safety = false;
关闭严格类型安全模式,就可以比较了。
以下有几种,节选自网络:
启用严格模式:hive.mapred.mode = strict // Deprecated
hive.strict.checks.large.query = true
该设置会禁用:
- 不指定分页的order by
- 对分区表不指定分区进行查询
- 和数据量无关,只是一个查询模式
hive.strict.checks.type.safety = true
严格类型安全,该属性不允许以下操作:
- bigint和string之间的比较
- bigint和double之间的比较
hive.strict.checks.cartesian.product = true
该属性不允许笛卡尔积操作
具体例子:
select gid,
uid,
DAY,
watch_time,
first_watch_date
from(
SELECT gid,
user_id AS uid,
host_id,
DAY,
sum(watch_time) AS watch_time,
min(hour(tm)) as first_watch_hour,
min(to_date(tm)) as first_watch_date
FROM dwd.dwd_room_watch_time
WHERE gid IS NOT NULL
AND host_id IS NOT NULL
AND watch_time is not null
AND DAY <= 20201012
AND DAY >= 20201005
GROUP BY gid, user_id,DAY,game_key,host_id,platform
) as t0_watch_time
where first_watch_date >= date_add("2020-10-12",-7) and first_watch_date <="2020-10-12"
排序加索引
scala中,ml或milib中的模型特征需要topK排序加索引,我通常使用data.sortBy().zipWithIndex()组合来生存排序和索引。
hive中则需要用到row_number、rank、dense_rank
RANK():返回数据项在分组中的排名,在排名相等时会在名次中留下空位,造成排名不连续。
DENSE_RANK():同样返回数据项在分组中排名,不过在排名相等时不会留下名位空位。
ROW_NUMBER():为每一条分组记录返回一个数字,注意不同于rownum伪列。
partition by相当于group by,按照第一个字段分组按照category_3字段降序排列。
select *,DENSE_RANK() OVER(order by 字段) as 字段新名称 from table_name
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。
select *,dense_rank() over (order by category_3 desc) as label_3 --Level3
from table_name where title like '%戴森%'
select * --多个字段标号
,dense_rank() over (order by category_1 desc) as label_1 --Level1
,dense_rank() over (partition by category_1 order by category_2 desc) as label_2 --Level2
,dense_rank() over (partition by category_1,category_2 order by category_3 desc) as label_3 --Level3
from table_name
网上的例子看row_number、rank、dense_rank的区别:
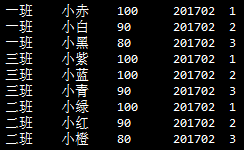
查看班级排名情况,rn为排名次序字段
select *, rank() over (partition by class order by score desc) rn from t_score where term="201702";
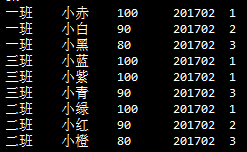
三班的排名出现了两个并列第一,然后紧接着就是第三名,没有第二名了。想要把第三名更正为第二名则需要用dense_rank
select *, dense_rank() over (partition by class order by score desc) from t_score where term="201702";
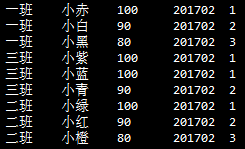
假使不想出现并列的情况,只打算排序,序号要唯一。
1. 首先按照成绩排序
2. 成绩相同的不要并列,而是再按照姓名排序,姓氏靠后的认倒霉吧
3. 对于成绩和姓名都完全相同的情况,没有指定就假装不存在这种情况好啦
select *, row_number() over (partition by class order by score desc, name) from t_score where term="201702";
结果大概是这样:
hive中的复合数据结构
hive中的复合数据结构有如下几种
map
(key1, value1, key2, value2, ...) Creates a map with the given key/value pairs
struct
(val1, val2, val3, ...) Creates a struct with the given field values. Struct field names will be col1, col2, ...
named_struct
(name1, val1, name2, val2, ...) Creates a struct with the given field names and values. (as of Hive 0.8.0)
array
(val1, val2, ...) Creates an array with the given elements
create_union
(tag, val1, val2, ...) Creates a union type with the value that is being pointed to by the tag parameter
常用的三种为array map struct
array的用法
hive中array可以通过索引来取出制定位置的元素
array[0],array[5]
判断array是否含有某个元素
array_contains
用法示例:
SELECT array_CONTAINS(ARRAY(0,1),0) returns true
SELECT array_CONTAINS(split(‘0=1’,’=’),’0’) returns true
array大小
size(array)
有时候需要对array切片,比如需要取array中前top50的元素
网上通常是使用udf解决,hive使用udf比spark中的udf麻烦,个人不喜欢用,可以把array转成字符串曲线救国。
字符串中有substring_index函数,这个函数的作用是,拿出某个字符串前面/后面的内容substring_index(str,1)取str前面的内容,(array_str,array[51],-1)取str后面的内容。
如果数组中的元素是不重复的,那么可以利用这个函数来切片再转化为数组。
比如某表数组需要取50个元素切片,不够50全取,超过50取前50个:
可以在后面加上array_size的数组元素个数字段,再加上数组转字符串的字段array_str。
例子:select
if (array_size<=50,concat(array_str,','),substring_index(array_str,array[51],1)) as array_string
from table
这样就取出了前五十个元素+“,”,后面删去最后一个逗号在用split切割成数组,就达到了目的。
map的用法
struct的用法
创建表,写入表
RCFILE格式
创建表
create table if not exists table_name (col1 string, col2 int,col3 bigint,col4 string,col5 boolean,col6 double,col7 array,col8 MAP)
partitioned by (stat_date bigint) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe' STORED AS RCFILE
把temp表写入到创建的表
insert overwrite table table_name partition(stat_date = "20180811" ) select * from temp
OCFILE格式
ORC三种创建/使用方式:
1, STORED AS ORC;
2, ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' with serdeproperties('serialization.null.format' = '') STORED AS ORC;
3, ROW FORMAT DELIMITED NULL DEFINED AS '' STORED AS ORC;
创建表
create table if not exists table_name (col1 string, col2 int,col3 bigint,col4 string,col5 boolean,col6 double,col7 array,col8 MAP)
partitioned by (stat_date bigint) STORED AS ORC
把temp表写入到创建的表
insert overwrite table table_name partition(stat_date = "20180811" ) select * from temp
Hive 文件格式
hive文件存储格式包括以下几类:
1、TEXTFILE
2、SEQUENCEFILE
3、RCFILE
4、ORCFILE(0.11以后出现)
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入SequenceFile,RCFile,ORCFile表中。
一、TEXTFILE
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,
从而无法对数据进行并行操作。
二、SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
三、RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
四、ORCFILE
然后是 ORC File(Optimized Row Columnar file),对RCFile做了一些优化,克服 RCFile 的一些限制,主要参考这篇文档。 和RCFile格式相比,ORC File格式有以下优点:
- 每个task只输出单个文件,这样可以减少NameNode的负载;
- 支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
- 在文件中存储了一些轻量级的索引数据;
- 基于数据类型的块模式压缩:
- integer类型的列用行程长度编码(run-length encoding)
- String类型的列用字典编码(dictionary encoding);
- 用多个互相独立的RecordReaders并行读相同的文件;
- 无需扫描markers就可以分割文件;
- 绑定读写所需要的内存;
- metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
总结:
相比TEXTFILE和SEQUENCEFILE,RCFILE由于是列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
hive常见错误
FAILED: ParseException line 1:56 cannot recognize input near 'xxxx' in constant (state=42000,code=40000)
遇见这种错误主要是几种情况,
1.某个hive字段名使用了end这样的hive保留字段
2.某些地方不小心加了空格没有发现
3.通shell脚本往sql中传参数,参数没有上传成功
HDFS基本操作
HDFS的设计目标
巨大的分布式文件系统
运行在普通廉价的硬件上
易扩展、为用户提供性能不错的文件存储服务
HDFS架构
1个Master(NameNode/简称NN)带 N个Slaves(DataNode/简称DN)
1个文件会被拆分成多个Block
如果设定blocksize: 128M
130M ==> 2个Block: 128M 和 2M
NN
(1)负责客户端请求的响应
(2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN
(1)存储用户文件对应的数据块(Block)
(2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况。
一个典型的部署架构是一台机器上面运行一个NameNode,每个其他机器上面都运行一个DataNodes
NameNode + N个DataNode
建议: NN和DN是部署在不同的节点上
replication factor :副本系数、副本因子
一个文件里所有的block除了最后一个可能大小不一样,其他的都是一样的size。
软件存放目录
hadoop/hadoop
/home/hadoop
software:存放的是安装的软件包
app: 存放的是所有软件的安装目录
data: 存放的是课程中的所有使用的测试数据目录
source:存放的是软件源码目录,spark
HDFS环境搭建
使用版本:hadoop-2.6.0-cdh5.7.0
(1)下载Hadoop
http://archive.cloudera.com/cdh5/cdh/5/2.6.0-cdh5.7.0
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
(2)安装JDK
安装的版本:
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)
下载
解压到app目录:tar -zxvf jdk-7u51-linux-x64.tar.gz -C ~/app/
验证安装是否成功:~/app/jdk1.7.0_51/bin 执行 ./java -version
建议把bin目录配置到系统环境变量(~/.bash_profile)中
vi .bash_profile 编辑系统环境变量
添加两行:
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51
export PATH=$JAVA_HOME/BIN:$PATH
保存以后:
source .bash_profile 让系统环境变量立刻生效
echo $JAVA_HOME 输出JAVA_HOME在哪里
(3)机器参数设置
hostname:hadoop001
修改机器名 vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop001
设置ip和hostname的映射关系:/etc/hosts
输入 cat /etc/hosts 然后copy本机的ip地址
192.168.199.200 hadoop001
127.0.0.1 localhost
ssh 免密码登录(本步骤可以省略,但是后面重启hadoop进场时需要手工输入密码)
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
(4)Hadoop配置文件修改: ~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
hadoop-env.sh
export JAVA_HOME= /home/hadoop/app/jdk1.7.0_51
core-site.xml
hdfs-site.xml
(5)格式化HDFS
注意:这一步操作,只是在第一次执行,每次如果都格式化的话,那么HDFS上的数据会被清空
在bin目录下执行:./hdfs namenode -format
(6)启停HDFS:
启动HDFS
在sbin目录下执行: ./start-dfs.sh
验证是否启动成功:
输入: jps
SecondaryNameNode
DataNode
NameNode
停止HDFS
在sbin目录下执行: ./stop-dfs.sh
(7)HDFS,Hadoop shell常用命令和shell常用命令类似,很多只需要在常用shell命令前面加上"hadoop fs -"
即可,下面给一些例子:
ls get mkdir rm put等等
hadoop fs 帮助命令,可以查看所有可用命令
#ls
hadoop fs -ls 查看文件夹下的文件
hadoop fs -ls test 查看test文件夹下的文件
hadoop fs -ls -R 加上-R代表需要递归的执行
hadoop fs -lsr 同上
#mkdir
hadoop fs -mkdir /user/root/dir 创建文件夹
hadoop fs -mkdir /user/root/dir1 /user/root/dir2 一次性创建多个文件夹
hadoop fs -mkdir -p a/b 创建多层文件夹
#put 把本地一个或多个文件上传到hdfs中
hadoop fs -put ...
hadoop fs -put Desktop/testfile.txt /user/root/dir1/
hadoop fs -put [文件] /[文件夹]/ 把文件放入文件夹中
hadoop fs -put 1.tar /test 把当前目录的1.tar上传到hdfs的test目录,若test目录中存在相同的文件,则会报错
hadoop fs -put -f 1.tar /test 把当前目录的1.tar上传到hdfs的test目录,若存在相同文件,会覆盖该文件。
#copy
hadoop fs -copy [文件] /[文件夹]/ 把文件放入文件夹中
hadoop fs -copy 1.tar /test 也能实现把本地文件传到HDFS,和put一样。
#rm
hadoop fs -rm [文件名] 删除一个文件
hadoop fs -rm /test/1.tar
hadoop fs -rm -r [文件夹] 删除文件夹需要递归的删除文件 或者 hadoop fs -rmr(这是老版本代码 )
hadoop fs -rmdir 删除空目录
#查看文件内容
hadoop fs -text
hadoop fs -text [文件] 将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
hadoop fs -cat
hadoop fs -cat [文件] 这两个都可以查看文件内容
也可以用-text把文本文件保存,-text查看文件内容以后再重定向到文件保存路径中去
hadoop fs -text [文件,例如:/apps/recommend/models/*] > [保存路径:$data_save_dir/tmp]
hadoop fs -cat [文件,例如:/apps/recommend/models/*] > [保存路径:$data_save_dir/tmp]
hadoop fs -text /user/wangyao/data/* > $data_save_dir/tmp
#chmod
hadoop fs -chmod -R 777 [文件夹]
hadoop fs -chmod 777 [文件]
#get 从hadoop上下载文件到本地
hadoop fs -get
hadoop fs -get [文件路径] [保存的文件路径] 把文件下载到本地
hadoop fs -get /user/hadoop/file localfile
hadoop fs -get
hadoop fs -get hdfs://host:port/user/hadoop/file localfile
例如: hadoop fs -get /test/hdfs.java code_java
#cp 复制文件
在Hadoop文件系统中将文件从一个地方复制到另一个地方与unix shell中的cp命令语法相同。
hadoop fs -cp ...
示例:
hadoop fs -cp /user/root/dir1/testfile.txt /user/root/dir2
#mv 将文件从源移动到目标
以下是在Hadoop文件系统中将文件从一个目录移动到另一个目录的语法和示例。
hadoop fs -mv
示例:
hadoop fs -mv /user/root/dir1/testfile.txt /user/root/dir2
##count
hadoop fs -count < hdfs path >
统计hdfs对应路径下的目录个数,文件个数,文件总计大小
显示为目录个数,文件个数,文件总计大小,输入路径
#du 显示特定文件的总长度
为了检查文件中内容的总长度,我们可以使用-du。 命令如下。 如果路径是文件的路径,则显示文件的长度,如果它是目录的路径,则显示的内容的聚合大小显示为包括所有文件和目录。
hadoop fs -du
示例:
hadoop fs -du /user/root/dir1/testfile.txt
#df 文件系统中的空间的详细信息
要获取Hadoop文件系统的所有空间相关详细信息,我们可以使用df命令。 它提供有关当前安装的文件系统使用的空间量和可用空间量的信息
用法:
hadoop fs -df
命令可以在没有路径URI或路径URI的情况下使用,当不使用路径URI时,它提供关于整个文件系统的信息。 当提供路径URI id时,它提供特定于路径的信息。
示例:
hadoop fs -df
hadoop fs -df /user/root
更多命令可以查阅 hadoop FS Shell使用指南
(8)HDFS的优缺点
优点:
高容错
适合批处理
适合大数据处理
构建在廉价的机器上
缺点:
低延迟的数据访问
小文件存储
(9)把训练好的机器学习模型持久化到HDFS中(scala)
import org.apache.hadoop.fs.{FileSystem, Path}
// 保存模型到hdfs
def save_model(sparkSession: SparkSession, model: LogisticRegressionModel, save_dir: String) = {
// 客户端要构造FileSystem对象可以使用FileSystem.get()方法,使用FileSystem.get()方法获取FileSystem对象
val fs = FileSystem.get(new org.apache.hadoop.conf.Configuration())
val p = new Path(save_dir)
if (fs.exists(p)) {
printf("\n====>>>> model file is already exists! delete it! %s", p.toString)
fs.delete(p, true)
}
printf("\n====>>>> save model to %s", p.toString)
// 保存模型
model.save(sparkSession.sparkContext, p.toString)
}
// 从hdfs中读取模型
def load_model(sparkSession: SparkSession, model_path: String, job_date: String): LogisticRegressionModel = {
LogisticRegressionModel.load(sparkSession.sparkContext, model_path)
}
}
HDFS常见错误:
Exception in thread "main" org.json4s.package$MappingException: Did not find value which can be converted into java.lang.String
本人遇见的情况是在HDFS上读取保存好的文件时报错,原因是保存的模型文件是mllib格式,而读取的方式是ml格式,二者不兼容。
Hbase基本操作
HBase常用操作
建表
create 'Wordcount','result'
create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
查看表结构
describe 'Wordcount'
查看所有数据
scan 'Wordcount',{LIMIT=>10}
删除指定rowkey
deleteall 'Wordcount','hello'
删除所有数据
truncate 'Wordcount'
删除表
disable 'Wordcount'
drop 'Wordcount'
加入数据
put 'Wordcount','test','result:count','2'
获取数据
get 'Wordcount','hello','result:count'
get 'Wordcount','hello'获取hello下所有的数据
删除数据
delete 'Wordcount','hello','result:count'
查看表中的记录总数
count 'table_name'
修改压缩算法
disable 'table'
alter 'table',{NAME=>'info',COMPRESSION=>'snappy'}
enable 'table'
删除列族
disable 'table'
alter 'table',{NAME=>'info',METHOD=>'delete'}
enable 'table'
disable_all 和drop_all支持正则表达式,并列出当前匹配的表
disable_all 'toplist.*'
……
并给出确认提示
Disable the above 25 tables (y/n)?
分配权限
权限用五个字母表示: “RWXCA”.
READ(‘R’), WRITE(‘W’), EXEC(‘X’), CREATE(‘C’), ADMIN(‘A’)
grant 参数间用逗号分隔
grant 'test','RW','t1'
查看权限
user_permission 't1'
收回权限
revoke 'test','t1'
移动region
encodeRegionName指的regioName后面的编码,ServerName指的是master-status的Region Servers列表
move 'encodeRegionName', 'ServerName'
开启/关闭region
balance_switch true|false
手动split
split 'regionName', 'splitKey'
手动触发major compaction
Compact all regions in a table:
hbase> major_compact 't1'
Compact an entire region:
hbase> major_compact 'r1'
Compact a single column family within a region:
hbase> major_compact 'r1', 'c1'
Compact a single column family within a table:
hbase> major_compact 't1', 'c1'
关于compaction
作用:
合并文件
清除删除、过期、多余版本的数据
提高读写数据的效率
Minor Compaction
做部分文件的合并操作,将几个较小的相邻StoreFiles重写为一个,会做minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作(major可以)
Major Compaction
将Region下的HStore下的所有StoreFile合并,Major Compaction之后每个HStore只有一个File
行转列:
1)多行转多列
假设数据表
row2col:
col1 col2 col3
a c 1
a d 2
a e 3
b c 4
b d 5
b e 6
现在要将其转化为:
col1 c d e
a 1 2 3
b 4 5 6
此时需要使用到max(case … when … then … else 0 end),仅限于转化的字段为数值类型,且为正值的情况。
HQL语句为:
select col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'e' then col3 else 0 end) as e
from row2col
group by col1;
列转行:
References
http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.0.0.2/ds_Hive/orcfile.html
https://blog.csdn.net/Nougats/article/details/72722503
你可能感兴趣的:(Hive&HDFS&Hbase基本操作)