计算机主要由CPU、总线、I/O设备、内存、硬盘等组成,见下图:

- cpu由控制器(CU)和运算器(ALU)组成,相当于计算机大脑。用来解释计算机指令和处理计算数据。
- 总线:相当于传递信息的高速公路,计算机各大部件之间的信息交流都会通过总线。
- io设备: 计算机与外界的信息交互的载体。鼠标,键盘,磁盘,声卡,网卡等都属于io设备
- 内存:即图中的主存储器,运行速度比磁盘快得多。主要用来解决磁盘和cpu之间处理速度差距过大的问题。所有cpu运算所需的数据都是从内存获得。但是内存中的数据在断电时会丢失。
- 硬盘:用于持久化存储计算机运行所需数据。但是由于它的机械结构,运行速度慢,所以必须通过运行速度快的内存将数据传递给cpu。磁盘具有容量大,速度慢,断电数据不丢失。
我们在评估一个服务端系统瓶颈的时候,通常把服务分为io密集型和计算密集型。
- 计算密集型是指cpu的计算单元处理速度达到瓶颈,可以通过增加cpu核心,提高cpu主频来增大计算能力。目前cpu主频已经超过3GHZ,服务器核心也从2核心,4核增大到32核,64核甚至128核。
-
io密集型是指磁盘处理io操作的速度达到瓶颈。上面介绍过,为了解决cpu处理速度和硬盘处理速度的巨大差异,我们引入了内存作为数据中转站,好让cpu不致于等待硬盘而浪费宝贵的cpu资源。以下是cpu-内存-磁盘的示意图,不完全准确,但是能清晰表达这里的意思:
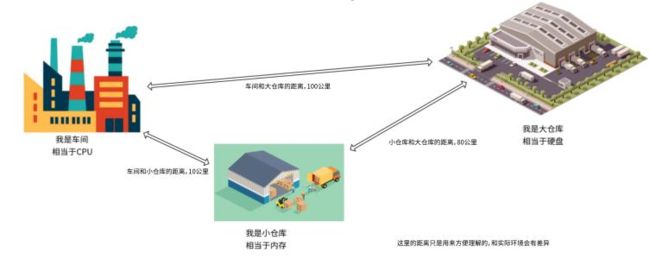 cpu-内存-磁盘关系示意图.png
cpu-内存-磁盘关系示意图.png系统表现为io密集型的意思就是:cpu工厂产出的数据虽然能很快的放到内存这个小仓库,但是硬盘这个大仓库的处理速度实在太慢,导致内存小仓库收到cpu工厂运过来的数据太多而装满,cpu工厂和内存小仓库不得不停下工作,等待硬盘大仓库从内存小仓库运出部分数据。
那么硬盘io速度为什么这么慢?操作系统有没有做对应的优化?应用程序有没有做对应的优化?
一,硬盘io的物理过程
磁盘由一些旋转着的金属碟片和一个装在步进马达上的读写头组成。

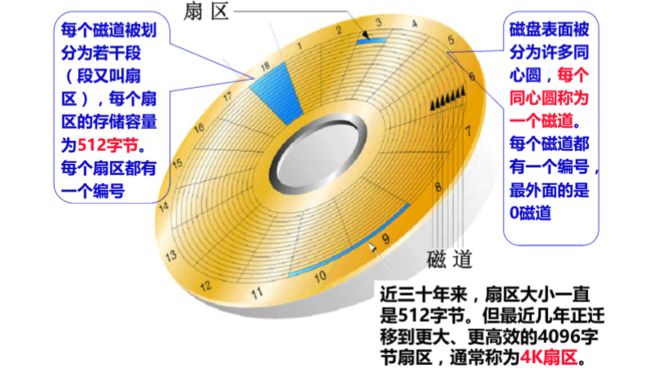
磁盘完成一个io过程所花费的时间,由寻道时间,旋转延迟和数据传输三部分时间组成:
1,寻道时间
Tseek是指将读写磁头移动至正确的磁道上所需要的时间,目前磁盘的平均寻道时间一般在3-15ms
2,旋转延迟
Trotation是指盘片旋转将请求数据所在的扇区移动到读写磁盘下方所需要的时间。旋转延迟取决于磁盘转速,通常用磁盘旋转一周所需时间的1/2表示。比如:7200rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms,而转速为15000rpm的磁盘其平均旋转延迟为2ms。
机械硬盘的连续读写性能很好,但随机读写性能很差。这主要是因为随机读写的寻道时间和旋转延迟比较高,磁头需要不停的移动来寻找正确的磁道,然后磁片也需要旋转来找到正确的分区,所以性能不高。
3,数据传输
Ttransfer是指完成传输所请求的数据所需要的时间,它取决于数据传输率,其值等于数据大小除以数据传输率。目前IDE/ATA能达到133MB/s,SATA II可达到300MB/s的接口数据传输率,数据传输时间通常远小于前两部分消耗时间。
二,操作系统对硬盘io的封装优化
类似于网络的分层结构,下图显示了Linux系统中对于磁盘的一次读请求在核心空间中所要经历的层次模型:
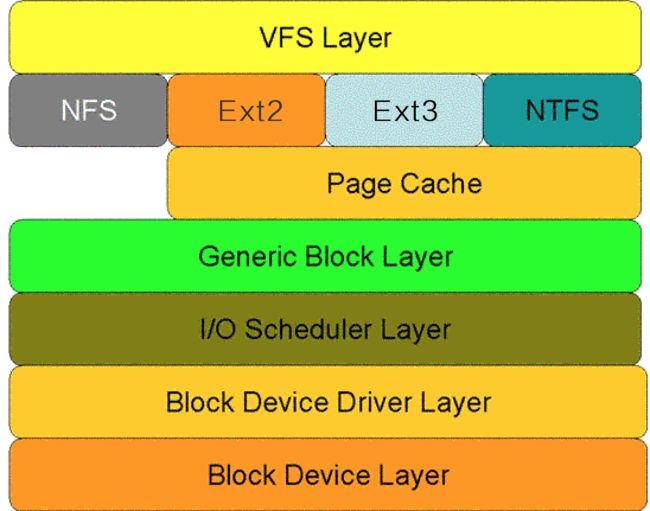
对于磁盘的一次读请求,首先经过虚拟文件系统层(VFS Layer),其次是具体的文件系统层(例如Ext2),接下来是Cache层(Page Cache Layer)、通用块层(Generic Block Layer)、I/O调度层(I/O Scheduler Layer)、块设备驱动层(Block Device Driver Layer),最后是物理块设备层(Block Device Layer)。
1,虚拟文件系统层(VFS Layer)
VFS(Virtual File System)虚拟文件系统是一种软件机制,更确切的说扮演着文件系统管理者的角色,与它相关的数据结构只存在于物理内存当中。它的作用是:屏蔽下层具体文件系统操作的差异,为上层的操作提供一个统一的接口。正是因为有了这个层次,Linux中允许众多不同的文件系统共存并且对文件的操作可以跨文件系统而执行。
VFS中包含着向物理文件系统转换的一系列数据结构,如VFS超级块、VFS的Inode、各种操作函数的转换入口等。Linux中VFS依靠四个主要的数据结构来描述其结构信息,分别为超级块、索引结点、目录项和文件对象。
- 超级块(Super Block):超级块对象表示一个文件系统。它存储一个已安装的文件系统的控制信息,包括文件系统名称(比如Ext2)、文件系统的大小和状态、块设备的引用和元数据信息(比如空闲列表等等)。VFS超级块存在于内存中,它在文件系统安装时建立,并且在文件系统卸载时自动删除。同时需要注意的是对于每个具体的文件系统来说,也有各自的超级块,它们存放于磁盘。
- 索引结点(Inode):索引结点对象存储了文件的相关元数据信息,例如:文件大小、设备标识符、用户标识符、用户组标识符等等。Inode分为两种:一种是VFS的Inode,一种是具体文件系统的Inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的Inode调进填充内存中的Inode,这样才是算使用了磁盘文件Inode。当创建一个文件的时候,就给文件分配了一个Inode。一个Inode只对应一个实际文件,一个文件也会只有一个Inode。
- 目录项(Dentry):引入目录项对象的概念主要是出于方便查找文件的目的。不同于前面的两个对象,目录项对象没有对应的磁盘数据结构,只存在于内存中。一个路径的各个组成部分,不管是目录还是普通的文件,都是一个目录项对象。如,在路径/home/source/test.java中,目录 /, home, source和文件 test.java都对应一个目录项对象。VFS在查找的时候,根据一层一层的目录项找到对应的每个目录项的Inode,那么沿着目录项进行操作就可以找到最终的文件。
- 文件对象(File):文件对象描述的是进程已经打开的文件。因为一个文件可以被多个进程打开,所以一个文件可以存在多个文件对象。一个文件对应的文件对象可能不是惟一的,但是其对应的索引节点和目录项对象肯定是惟一的。
2, Ext2文件系统
具体的文件系统,linux常用的有Ext2, Ext3, NFS, NTFS等文件系统,对用户透明,不介绍。
3,Page Cache层
引入Cache层的目的是为了提高Linux操作系统对磁盘访问的性能。层在内存中缓存了磁盘上的部分数据。当数据的请求到达时,如果在Cache中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。磁盘Cache有两大功能:预读和回写。
预读
预读其实就是利用了局部性原理,有同步和异步两种情况。具体过程是:
- 对于每个文件的第一个次请求,系统读入所请求的页面并读入紧随其后的少数几个页面(通常是三个页面),这时的预读称为同步预读。
- 对于第二次读请求,
- 如果所读页面不在Cache中,即不在前次预读的页中,则表明文件访问不是顺序访问,系统继续采用同步预读;
- 如果所读页面在Cache中,则表明前次预读命中,操作系统把预读页的大小扩大一倍,此时预读过程是异步的,应用程序可以不等预读完成即可返回,只要后台慢慢读页面即可,这时的预读称为异步预读。
- 任何接下来的读请求都会处于两种情况之一:第一种情况是所请求的页面处于预读的页面中,这时继续进行异步预读;第二种情况是所请求的页面处于预读页面之外,这时系统就要进行同步预读。
回写
回写是通过暂时将数据存在Cache里,然后统一异步写到磁盘中。
之前还有疑问:如果进程不断的对一个文件频繁的每次写一点数据,那系统不断的做用户态和内核态数据交换,效率岂不是非常低。原来操作系统考虑到了这个问题,在这里做了page cache优化。
通过这种异步的数据I/O模式解决了程序中的计算速度和数据存储速度不匹配的鸿沟,减少了访问底层存储介质的次数,使存储系统的性能大大提高。
回写机制存在的问题是回写不及时引发数据丢失(可由sync|fsync解决),回写期间读I/O性能很差。
4,通用块层
不太了解,不介绍。
5,io调度层
I/O调度层的功能是管理块设备的请求队列。即接收通用块层发出的I/O请求,缓存请求并试图合并相邻的请求。并根据设置好的调度算法,回调驱动层提供的请求处理函数,以处理具体的I/O请求。
如果简单地以内核产生请求的次序直接将请求发给块设备的话,那么块设备性能肯定让人难以接受,因为磁盘寻址是整个计算机中最慢的操作之一。为了优化寻址操作,内核不会一旦接收到I/O请求后,就按照请求的次序发起块I/O请求。为此Linux实现了几种I/O调度算法,算法基本思想就是通过合并和排序I/O请求队列中的请求,以此大大降低所需的磁盘寻道时间和旋转延迟,从而一定程度上克服随机io的缺点,来提高整体I/O性能。
6,块设备驱动层
驱动层中的驱动程序对应具体的物理块设备。它从上层中取出I/O请求,并根据该I/O请求中指定的信息,通过向具体块设备的设备控制器发送命令的方式,来操纵设备传输数据
三,开源软件利用操作系统io特性的设计技巧
下面以开源系统阐述一些基于磁盘I/O特性的设计技巧。
1,追加写
kafka就是采用了追加写,最直接的证明就是Kafka源码中只调用了FileChannel.write(ByteBuffer),而没有调用过带offset参数的write方法,说明它不会执行随机写操作。顺序读写就减少了寻道和旋转的时间,从而提高了kafka的整体读写tps。还有另外一种声音,就是kafka的整体读写tps决定因素,除了顺序读写外,还包括基于mmap的零拷贝技术,pagecache,利用java NIO技术等的综合因素。
2,小文件合并
- 首先减少了大量元数据,提高了元数据的检索和查询效率,降低了文件读写的I/O操作延时。
- 其次将可能连续访问的小文件一同合并存储,增加了文件之间的局部性,将原本小文件间的随机访问变为了顺序访问,大大提高了性能。
- 合并存储能够有效的减少小文件存储时所产生的磁盘碎片问题,提高了磁盘的利用率。
- 合并之后小文件的访问流程也有了很大的变化,由原来许多的open操作转变为了seek操作,定位到大文件具体的位置即可。如何寻址这个大文件中的小文件呢?其实就是利用一个旁路数据库来记录每个小文件在这个大文件中的偏移量和长度等信息。其实
小文件合并的策略本质上就是通过分层的思想来存储元数据。中控节点存储一级元数据,也就是大文件与底层块的对应关系;数据节点存放二级元数据,也就是最终的用户文件在这些一级大块中的存储位置对应关系,经过两级寻址来读写数据。
淘宝的TFS就采用了小文件合并存储的策略。TFS中默认Block大小为64M,每个块中会存储许多不同的小文件,但是这个块只占用一个Inode。假设一个Block为64M,数量级为1PB。那么NameServer上会有 1 * 1024 * 1024 * 1024 / 64 = 16.7M个Block。假设每个Block的元数据大小为0.1K,则占用内存不到2G。在TFS中,文件名中包含了Block ID和File ID,通过Block ID定位到具体的DataServer上,然后DataServer会根据本地记录的信息来得到File ID所在Block的偏移量,从而读取到正确的文件内容。
3,元数据管理优化
元数据信息包括名称、文件大小、设备标识符、用户标识符、用户组标识符等等。
- 在小文件系统中可以对元数据信息进行精简,仅保存足够的信息即可。元数据精简可以减少元数据通信延时,同时相同容量的Cache能存储更多的元数据,从而提高元数据使用效率。
- 可以在文件名中就包含元数据信息,从而减少一个元数据的查询操作。TFS中文件命名就隐含了位置信息等部分元数据。
- 针对特别小的一些文件,可以采取元数据和数据并存的策略,将数据直接存储在元数据之中,通过减少一次寻址操作从而大大提高性能。在Rerserfs中,对于小于1KB的小文件,Rerserfs可以将数据直接存储在Inode中。
参考
1,磁盘io那些事
2,kafka的顺序读写到底是什么