归并排序教学——你学会了吗?
1.概念煮栗子
前面我们讲解了堆排序,因为它用到了完全二叉树,充分利用了完全二叉树的深度是的特性,所以效率比较高。不过堆这种结构设计是比较复杂的,老实说,能想出这么一种结构就不容易了,有没有更直接简单的办法利用完全二叉树来排序呢?答案当然是有的。
比如我们要知道班里人的成绩排名情况,我们要比较两个同学的成绩高低是很容易的,比如甲比乙分数低,丙比丁分数低。那么我们就可以很容易得到甲乙丙丁并后的成绩排名,同样的往后面推,由于他们两组分别有序,把八个同学成绩合并有序也是很容易做到的,继续下去...最终完成全班同学的成绩排名,第一名也就出来了。
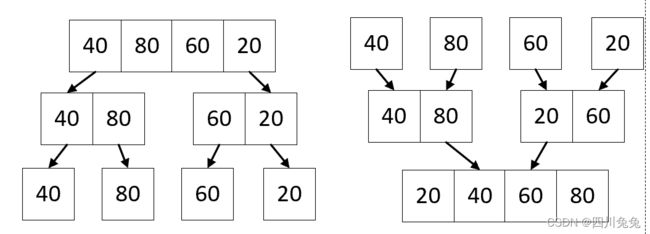
为了理解更加清晰,大家看下面这张图,我们将本是无序的序列{16,7,13,10,9,15,3,2,5,8,12,1,11,4,6,14},通过两两合并,排序后再合并,最终获得了一个有序数组。注意仔细观察它的形状,你会发现,它像极了一棵倒置的完全二叉树,通常涉及到完全二叉树结构的排序算法,效率一般都不低的,这就是我们要讲的归并排序。
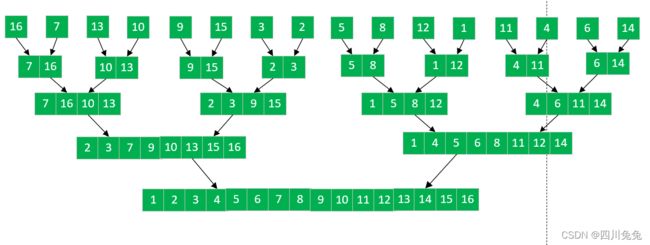
2.归并排序算法
归并排序(Merging Sort)就是利用归并的思想实现排序方法。它的原理是:假设初始序列含有 n 个记录,则可以看成 n 个有序的子序列,每个子序列的长度为1,然后两两归并得到 ( 表示不小于x的最小整数)个长度为 2 或 1 的有序子序列;再两两归并,如此重复,直到得到一个长度为 n 的有序序列为止,这种排序方法称作为 2 路归并排序。
好了,有了对归并排序的认识,我们来看看代码:
void MergeSort(SqList *L)
{
MergeSort(L->r,L->r,L->length);
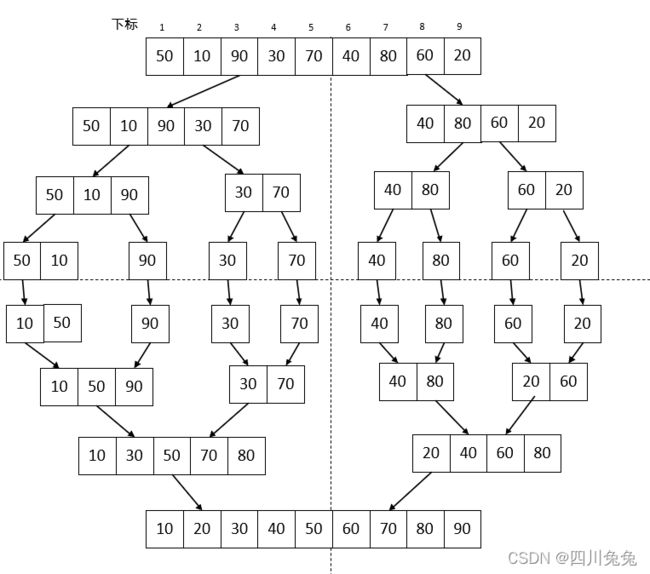
}这串代码我们只是调用了另外一个函数而已,由于我们要讲解的归并排序实现需要用到递归调用,因此我们外封装了一个函数。假设现在要对数组{50,10,90,30,70,40,80,60,20}进行排序,L.length = 9,我们来看看MSort的实现。
void Msort(int SR[],int TR1[],int s,int t)
{
int m;
int TR2[MAXSIZE+1];
if (s==t)
TR1[s]=SR[s];
else
{
m = (s+t) / 2; // 将SR[s...t]平分为SR[s...m]和SR[m+1...t]
Msort(SR, TR2, s, m); // 递归将SR[s...m]归并为有序的TR2[s...m]
Msort(SR, TR2, m+1, t); // 递归将SR[m+1...t]归并为有序TR2[m+1...t]
Merge(SR, TR2, s, m,t); // 将TR2[s...m]和TR2[m+1...t]归并到TR1[s...t]
}
}1.Msort被调用时,SR与TR1都是{50,10,90,30,70,40,80,60,20},s = 1, t = 9,最终我们的目的就是要将TR1中的数组排好顺序。
2.第 5 行,显然 s 不等于 t,执行第 8 - 13 行 else 语句。
3.第 9 行,m = (1+9)/ 2 = 5.m就是序列的正中间下标。
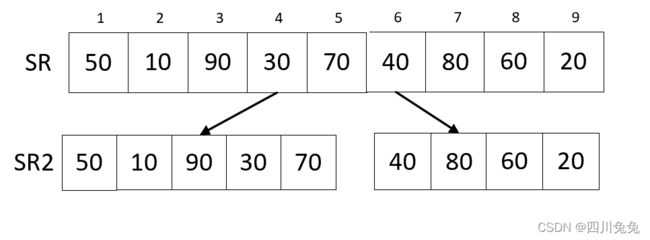
4.此时第 10 行,调用“MSort(SR,TR2,1,5)”的目标就是将数组 SR 中的第 1-5 的关键字归并到有序的 TR2。也就是说,在调用这两句代码前,代码已经准备将数组分成了两个数组了,如图:
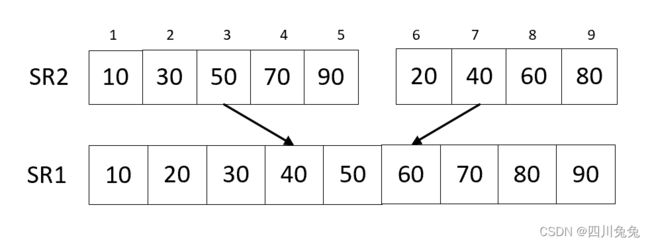
5.第 12 行,函数 Merge 的代码的细节一会儿将,调用“Merge(TR2,TR1,1,5,9)” 的目的就是将 第 10 和 11 行代码获得的数组 TR2 (注意它是下标为 1-5 和 6-10的关键字分别有序)归并为TR1,此时相当于整个排序就已经完成了,如图。
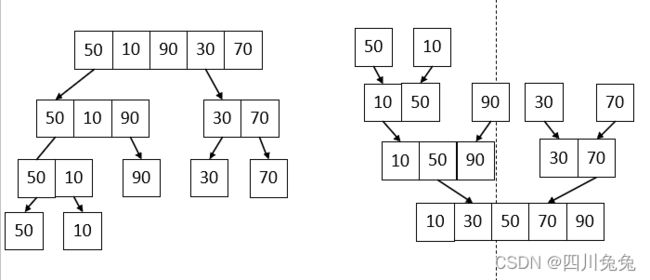
6.再来看第 10 行递归调用进去后,s = 1, t = 5, m = (1+5) / 2 = 3.此时相当于将 5 个记录拆分为三个和两个。继续递归进去,直到细分为一个记录填入 TR2,此时 s 和 t 相等,返回递归。如左图。每次递归都会返回后执行第 12 行,将 TR2 归并到 TR1 中,右图所示,最终使得当前序列有序。
7.同样的第 11 行业也是这样,如图:
8.此时也就是刚才所讲的最后一次执行第 12 行代码,将{10,30,50,70,90}与{20,40,60,80}归并为最终有序的序列。
可以说,如果对递归函数运行方式理解比较透彻的话,MSort 函数还是很好理解的。我们来看看整个数据变换示意图。
现在我们来看看Merge函数的代码如何实现的。
void Merge(int SR[],int TR[],int i,int m,int n)
{
int j,k,l;
for(j = m + 1, k = i; i < = m && j < = m; k++) // 将 SR 中记录由小到大归并入 TR
{
if (SR[i] < SR[j])
TR[k] = SR[i++];
else
TR[k] = SR[j++];
}
if(i <= m)
{
for(l = 0; l <= m-i;l++)
TR[K+1] = SR[i+1]; // 将剩余的SR[i..m]复制到TR
}
if( j <= n)
{
for(l = 0; l <=i n-j; l++)
TR[k+1] = SR[j+1]; //将剩余的SR[j..n]复制到TR
}
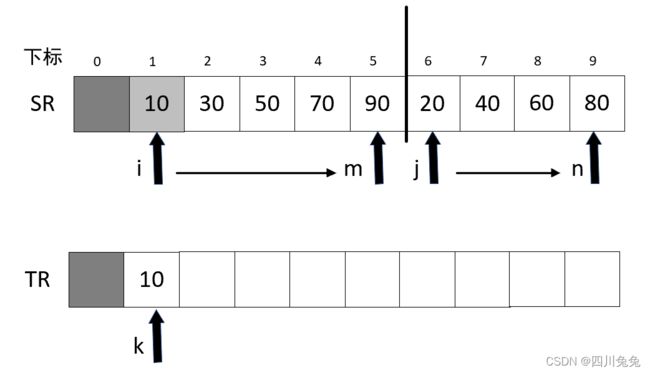
}1.假设我们此时调用的 Merge 就是将{10,30,50,70,90}与{20,40,60,80}归并为最终有序的序列,因此数组 SR 为{10,30,50,70,90,20,40,60,80}, i = 1,m = 5, n = 9.
2.第 4 行,for 循环,j = m+1 = 6开始到 9, i 由 1 开始到 5,k 由 1 开始每次加一,k 值用于目标数组TR的下标。
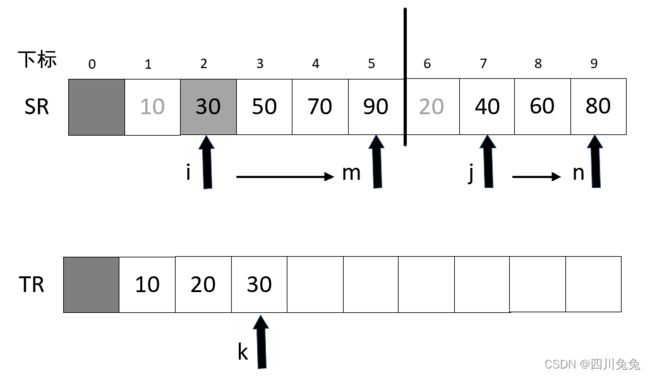
3.第 6 行,SR[i] = SR[1] = 10,SR[j] = SR[6] = 20,SR[i] < SR[j],执行第七行,TR[k] = TR[1] = 10,并且 i++.如图:
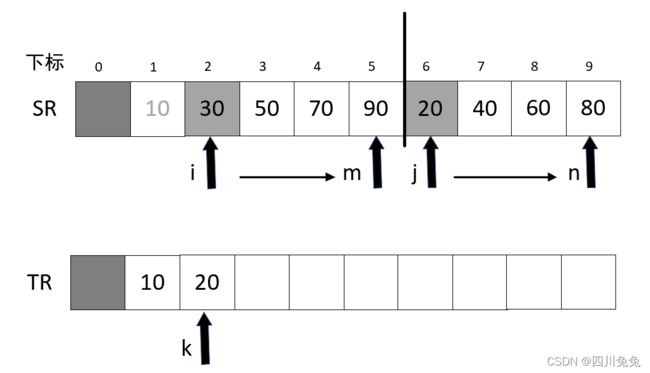
4.再次循环,k++ 得到 2 ,SR[i] = SR[2] = 30,SR[j] = SR[6] = 20, SR[i] > SR[j],执行第 9 行,TR[k] = TR[2] = 20,并且 j++,如图所示:
5.再次循环,k++得到 k = 3,SR[i] = SR[2] = 30,SR[j] = SR[7] = 40,SR[i] < SR[j],执行第 7 行,TR[k] = TR[3] = 30,并且 i++,如图。
6.接下来完全相同的操作,一直到 j++后,j = 10,大于 9 结束循环,如图。
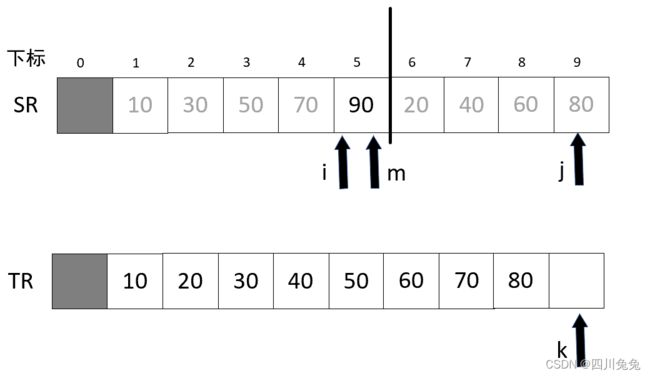
7.第 11-12 行的代码,其实就是将归并剩下的数组数据,移动到 TR 的后面。当前 k = 9,i = m =5,执行第 13 -20 行代码, for 循环 l = 0,TR[K+1] = SR[i+1] = 90,大功告成。
就这样,我们的归并排序算法就是完成了一次排序工作,怎么样,是不是比堆排序简单一点呢?你学废了吗?评论区扣 9 别扣 6。
3.归并算法复杂度分析
我们来分析一下归并排序的时间复杂度,一趟归并需要将 SR[1]~SR[n] 中相邻的长度为 h 的有序序列进行两两归并。并将结果放到 TR1[1]~TR1[n]中,这需要将待排序序列中的所有记录扫描一遍,因此耗费 O(n)的时间,而由完全二叉树的深度可知,整个归并排序需要进行 次,因此,总的时间复杂度为 O(nlogn),而且这是归并排序算法中最好最坏,平均的时间性能。
由于归并排序在归并过程中需要与原始记录序列同样数量的存储空间存放归并结果以及递归时深度为 的栈空间,因此空间复杂度为 O(n + logn).
另外,对代码进行仔细研究,发现 Merge 函数中有 if(SR[i] < SR[j]) 语句,这就是说明他需要两两比较,不存在跳跃,因此归并排序是一种稳定的排序算法。
也就是说,归并排序是一种比较占用内存,但却效率高,稳定的算法。