前言
学习Oracle的过程中,我们势必会接触到游标、存储过程、存储函数、触发器等概念,那么这些名词具体是什么含义呢?我们在实际工作中又可以怎么样来使用这些功能呢?本篇文章将针对上述概念进行讲解,并结合具体的代码案例来展示他们所使用的场景,希望能够给对这些概念不清楚的读者一个参考。
一、游标(Cursor)
游标是处理数据的一种方法,为了查看或者处理结果集中的数据,游标提供了在结果集中一次一行或者多行前进或向后浏览数据的能力。简单来说的话,可以把游标理解为是一个执行了某一段sql代码后得到的结果集。每次调用游标的fetch方法时相当于有一根指针逐行扫过结果集提取出一条结果。
(一)普通游标
1、普通游标的定义
一个完整的游标定义一共需要四个步骤:
1. 声明游标:也就是为自定义的游标定义一个名字
2. 打开游标:打开游标后才可以正式从里面读取数据
3. 取得游标数据:这一步写的是具体要对游标数据执行的操作内容
4. 关闭游标:当提取和处理完游标结果集合数据后,应及时关闭游标,以释放该游标所占用的系统资源,并使该游标的工作区变成无效,不能再使用FETCH 语句取其中数据。关闭后的游标可以使用OPEN 语句重新打开。
这里需要注意的是,游标提供了%found和%notfound两个属性来让我们判断当前游标fetch后的结果是否为空,我们一般会使用这个属性来作为我们循环取数据的结束条件。
游标的语法格式:
-- define cursor
CURSOR cursor_name[(parameter[, parameter]…)]
[RETURN datatype]
IS
select_statement;
-- open cursor
OPEN cursor_name[([parameter =>] value[, [parameter =>] value]…)];
-- fetch cursor
FETCH cursor_name INTO {variable_list | record_variable };
--close cursor
CLOSE cursor_name;
举一个例子:输出员工表中所有的员工姓名和工资(游标不使用参数)
declare
-- 声明游标
cursor v_emprows is select * from emp;
v_emprow emp%rowtype;
begin
-- 打开游标
open v_emprows;
-- 从游标中取出数据
fetch v_emprows into v_emprow;
while v_emprows%found loop
dbms_output.put_line('员工姓名是: '||v_emprow.ename||' 工资是: '||v_emprow.sal);
fetch v_emprows into v_emprow;
end loop;
-- 关闭游标
close v_emprows;
end;


游标还支持传入参数来调用,我们这里再举一个例子:我们查询指定部门的员工姓名和工资。
declare
-- 声明有参游标
cursor v_emprows(v_depno number) is select * from emp where emp.deptno=v_depno;
v_emprow emp%rowtype;
begin
-- 打开游标
open v_emprows(10);
-- 操作游标
loop
fetch v_emprows into v_emprow;
dbms_output.put_line('员工姓名为: '||v_emprow.ename||' 员工工资为: '||v_emprow.sal);
exit when v_emprows%notfound;
end loop;
-- 关闭游标
close v_emprows;
end;

个人认为,有参游标可以让我们解决某类场景的问题,不过如果这个游标不需要被多次复用的话,我们一般使用无参的游标就行。
可能有些读者对于为什么要使用游标还不是很清楚,毕竟类似的需求本身我们写一个sql就可以实现了,个人认为使用游标的好处有以下两点:
1、存储数据集,调用数据快
2、单纯的游标作用不大,可是游标配合其他工具可以便捷的实现对结果集数据的操作
(二)系统引用游标
系统引用游标的作用和普通游标差不多,主要的区别是在于游标具体定义的阶段不同。系统引用游标可以在打开游标的时候才指定具体的sql 语句。因为在某些场景中,我们无法在游标声明的时候就确定游标的查询语句,需要根据业务逻辑过程确定查询,此时引用游标就可以灵活地帮我们解决这个问题。
我们来使用系统引用游标来做一个小案例:查询所有员工的姓名和工资,需要注意的是,打开系统引用游标时,指定sql使用的关键词是for不是is。
declare
-- 声明游标和变量
v_emprow emp%rowtype;
v_emprows sys_refcursor;
begin
-- 打开游标
open v_emprows for select * from emp ;
-- 操作游标
loop
fetch v_emprows into v_emprow;
exit when v_emprows%notfound;
dbms_output.put_line('员工姓名为: '||v_emprow.ename||' 员工工资为: '||v_emprow.sal);
end loop;
-- 关闭游标
close v_emprows;
end;
经过上面的介绍,想必大家应该清楚游标的使用了,现在让我们来使用游标实现一个综合案例:
按照员工的工作给各位员工涨薪,总裁800,经理500,其他职位400;
declare
-- 声明游标
cursor v_emprows is select * from emp FOR UPDATE NOWAIT;
begin
--操作游标
for v_emprow in v_emprows loop
if v_emprow.job = 'PRESIDENT' then
update emp set emp.sal = emp.sal + 800 where emp.empno = v_emprow.empno;
elsif v_emprow.job = 'MANAGER' then
update emp set emp.sal = emp.sal + 500 where emp.empno = v_emprow.empno;
else
update emp set emp.sal = emp.sal + 400 where emp.empno = v_emprow.empno;
end if;
end loop;
commit;
end;
各位读者可能已经注意到,在这里案例中,我并没有进行游标的open、close和fetch,同时在for循环中我使用了for...in...这种写法来进行迭代,这是针对游标特有的一种for循环写法。具体细节可以参考下面的拓展。
拓展:游标For循环
游标FOR循环语句,自动执行游标的OPEN、FETCH、CLOSE语句和循环语句的功能;当进入循环时,游标FOR循环语句自动打开游标,并提取第一行游标数据,当程序处理完当前所提取的数据而进入下一次循环时,游标FOR循环语句自动提取下一行数据供程序处理,当提取完结果集合中的所有数据行后结束循环,并自动关闭游标。
FOR index_variable IN cursor_name[(value[, value]…)] LOOP
-- 游标数据处理代码
END LOOP;
二、存储过程
存储过程可以理解为是一组为完成特定功能的SQL 语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。简单理解的话,可以把它当做是java中的一个定义好入参出参的方法。
(一)存储过程的定义
CREATE [OR REPLACE] PROCEDURE procedure_name
([arg1 [ IN | OUT | IN OUT ]] type1 [DEFAULT value1],
[arg2 [ IN | OUT | IN OUT ]] type2 [DEFAULT value1]],
......
[argn [ IN | OUT | IN OUT ]] typen [DEFAULT valuen])
[ AUTHID DEFINER | CURRENT_USER ]
{ IS | AS }
<声明部分>
BEGIN
<执行部分>
EXCEPTION
<可选的异常错误处理程序>
END procedure_name;
我们已经知道了存储过程的语法,现在就让我们来实现一个小功能吧:
创建一个存储过程,要求可以传入员工号和工资,实现员工的工资更新,并打印涨薪前后的工资。
create or replace procedure update_emp_sal(v_empno in number,v_mount in number)
is
v_empsal emp.sal%type;
begin
select sal into v_empsal from emp where emp.empno = v_empno;
dbms_output.put_line('涨薪前的工资为: '||v_empsal);
update emp set sal = sal + v_mount where empno = v_empno;
dbms_output.put_line('涨薪后的工资为: '||(v_empsal+v_mount));
commit;
end update_emp_sal;
我们可以在PL/SQL Developer中查看我们刚刚创建的存储过程

(二)存储过程的调用方式
创建了存储过程之后,下一步自然是调用我们的存储过程验证一下是否正确。存储过程的调用一共有三种方式。
- command命令下,基本语法为:exec sp_name [参数名];
- SQL环境下,基本语法为:call sp_name [参数名];
- PL/SQL环境下,基本语法为:begin sp_name [参数名] end;
下面我们来演示一下最后两种方式:
在PL/SQL Developer中执行:
begin
update_emp_sal(7369,300);
end;
---
call update_emp_sal(7369,300);

三、存储函数
存储函数和存储过程并没有本质上的区别,二者统称为PL/SQL子程序,他们是被命名的PL/SQL块,均存储在数据库中,并通过输入、输出参数或输入/输出参数与其调用者交换信息。过程和函数的唯一区别是函数总向调用者返回数据,而过程则不返回数据。一般来说,会由存储过程来调用存储函数。
(一)存储函数的定义
CREATE [OR REPLACE] FUNCTION function_name
(arg1 [ { IN | OUT | IN OUT }] type1 [DEFAULT value1],
[arg2 [ { IN | OUT | IN OUT }] type2 [DEFAULT value1]],
......
[argn [ { IN | OUT | IN OUT }] typen [DEFAULT valuen]])
[ AUTHID DEFINER | CURRENT_USER ]
RETURN return_type
IS | AS
<类型.变量的声明部分>
BEGIN
执行部分
RETURN expression
EXCEPTION
异常处理部分
END function_name;
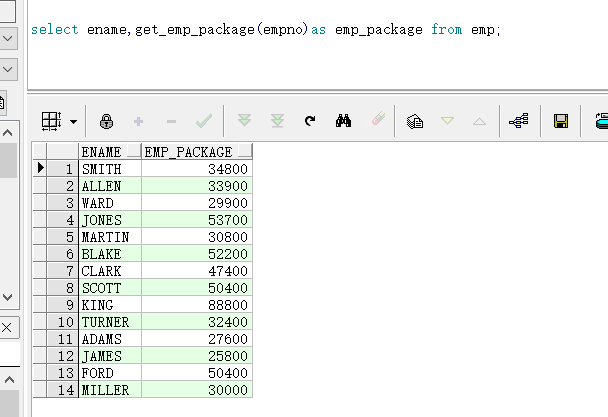
小案例:创建一个查询指定员工年薪的函数(使用return返回)
create or replace function get_emp_package(v_empno in number) return number
is
v_package number;
begin
select sal*12 + nvl(comm,0) into v_package from emp where emp.empno = v_empno;
return v_package ;
end;
同时,存储函数和存储过程有一个不同之处在于,存储函数可以直接由select语句调用执行
四、触发器
触发器在数据库里以独立的对象存储,它与存储过程和函数不同的是,存储过程与函数需要用户显示调用才执行,而触发器是由一个事件来启动运行。即触发器是当某个事件发生时自动地隐式运行。也可以将触发器理解为是,对表数据进行增、删、改操作的之前和之后的时机中,隐式地执行某些函数。
(一)触发器的定义
触发器的定义语法如下:
CREATE [OR REPLACE] TRIGGER trigger_name
{BEFORE | AFTER }
{INSERT | DELETE | UPDATE [OF column [, column …]]}
[OR {INSERT | DELETE | UPDATE [OF column [, column …]]}...]
ON [schema.]table_name | [schema.]view_name
[REFERENCING {OLD [AS] old | NEW [AS] new| PARENT as parent}]
[FOR EACH ROW ]
[WHEN condition]
PL/SQL_BLOCK | CALL procedure_name;
触发器的定义格式我们已经知道,现在我们就来创建一个简单的触发器来实现一个小功能吧:
每次更新EMP表时,都打印一句“已经更新了”
create trigger print_after_update
after
update
on emp
declare
begin
dbms_output.put_line('已经更新了数据');
end;
(二)触发器的分类
根据触发的颗粒度不同,触发器可以分为行触发器和语句触发器。比如说,现在已有某张表上已有一个触发器,对该表执行一条更新语句,结果会修改多行记录的内容,如果表上的触发器属于行级触发器,那么触发器只会执行一次函数,如果是语句触发器,那么被更新的每一条记录都会触发一次触发器函数。这就是二者最大的不同。
触发器类型的定义一般是由是否配置FOR EACH ROW来判断的


(三):old和:new属性的使用
当触发器被触发时,要使用被插入、更新或删除的记录中的列值,有时要使用操作前、操作后列的值
:NEW 修饰符访问操作完成后列的值,:OLD 修饰符访问操作完成前列的值。需要注意的是,这两个属性只在行级触发器中才可以使用。
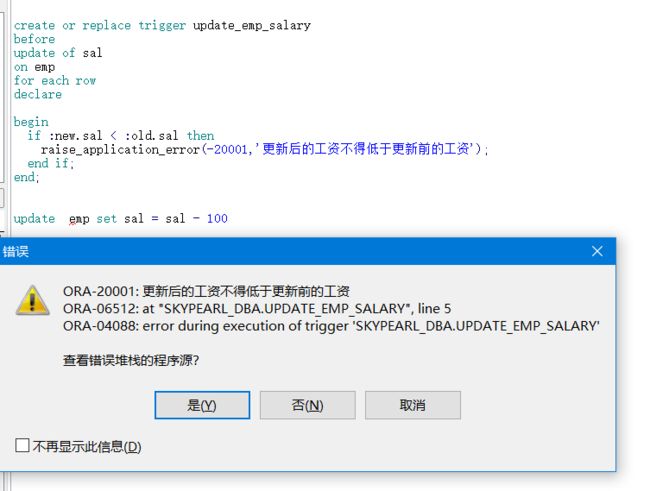
用一个小案例来演示一下这两个属性的作用:要求在每次更新员工表工资的时候,新工资不得低于旧工资
create or replace trigger update_emp_salary
before
update of sal
on emp
for each row
declare
begin
if :new.sal < :old.sal then
raise_application_error(-20001,'更新后的工资不得低于更新前的工资');
end if;
end;
触发器的综合小案例
我们知道对于Oracle数据库而言,是没有实现表ID字段自增的功能的。在实际工作中,我们常常会使用触发器结合序列来实现这个功能。
-- 创建序列
CREATE SEQUENCE update_sequence
INCREMENT BY 1
START WITH 1
MAXVALUE 5000 CYCLE;
-- 创建触发器
CREATE OR REPLACE TRIGGER dept_cascade1
BEFORE INSERT ON dept
FOR EACH ROW
BEGIN
SELECT update_sequence.NEXTVAL INTO :new.id FROM dual;
END;
有关于游标、存储过程、存储函数、触发器的概念和使用就介绍到这里了,想要了解更多使用的细节的话,各位读者可以看一下参考资料的文章,里面写的还是比较详细的。
参考资料:
PLSQL编程详解 https://www.jianshu.com/p/3d5acb46936e