本场 Chat 和《NLP 中文短文本分类项目实践(上)》可以看做姊妹篇,在上一篇的基础上,本篇主要讲一下文本分类在集成学习和深度学习方面的应用,由于内容比较多,笔者不可能面面俱到。下面我们先从集成学习说起。
一、数据科学比赛大杀器 XGBoost 实战文本分类
在说 XGBoost 之前,我们先简单从树模型说起,典型的决策树模型。决策树的学习过程主要包括:
特征选择: 从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法,如根据信息增益、信息增益率和gini等)。
决策树生成: 根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树生长。
剪枝: 决策树容易过拟合,需通过剪枝来预防过拟合(包括预剪枝和后剪枝)。
常见的决策树算法有 ID3、C4.5、CART 等。
在 sklearn 中决策树分类模型如下,可以看到默认通过 gini 计算实现。
sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
尽管决策树分类算法模型在应用中能够得到很好的结果,并通过剪枝操作提高模型泛化能力,但一棵树的生成肯定不如多棵树,因此就有了随机森林,并成功解决了决策树泛化能力弱的缺点,随机森林就是集成学习的一种方式。
在西瓜书中对集成学习的描述:集成学习通过将多个学习器进行结合,可获得比单一学习器显著优越的泛化性能,对“弱学习器” 尤为明显。弱学习器常指泛化性能略优于随机猜测的学习器。集成学习的结果通过投票法产生,即“少数服从多数”。个体学习不能太坏,并且要有“多样性”,即学习器间具有差异,即集成个体应“好而不同”。
假设基分类器的错误率相互独立,则由 Hoeffding 不等式可知,随着集成中个体分类器数目 T 的增大,集成的错误率将指数级下降,最终趋向于零。
但是这里有一个关键假设:基学习器的误差相互独立,而现实中个体学习器是为解决同一个问题训练出来的,所以不可能相互独立。因此,如何产生并结合“好而不同”的个体学习器是集成学习研究的核心。
集成学习大致分为两大类:
Boosting:个体学习器间存在强依赖关系,必须串行生成的序列化方法。代表:AdaBoost、GBDT、XGBoost
Bagging:个体学习器间不存在强依赖关系,可同时生成的并行化方法。代表:随机森林(Random Forest)
在 sklearn 中,对于 Random Forest、AdaBoost、GBDT 都有实现,下面我们重点说说在 kaggle、阿里天池等数据科学比赛经常会用到的大杀器 XGBoost,来实战文本分类 。
关于分类数据,还是延用《NLP 中文短文本分类项目实践(上)》中朴素贝叶斯算法的数据,这里对数据的标签做个修改,标签由 str 换成 int 类型,并从 0 开始,0、1、2、3 代表四类,所以是一个多分类问题:
preprocess_text(laogong, sentences,0) #laogong 分类0
preprocess_text(laopo, sentences, 1) #laopo 分类1
preprocess_text(erzi, sentences, 2) #erzi 分类2
preprocess_text(nver, sentences,3) #nver 分类3
接着我们引入 XGBoost 的库(默认你已经安装好 XGBoost),整个代码加了注释,可以当做模板来用,每次使用只需微调即可使用。
import xgboost as xgb
from sklearn.model_selection import StratifiedKFold
import numpy as np
# xgb矩阵赋值
xgb_train = xgb.DMatrix(vec.transform(x_train), label=y_train)
xgb_test = xgb.DMatrix(vec.transform(x_test))
上面在引入库和构建完 DMatrix 矩阵之后,下面主要是调参指标,可以根据参数进行调参:
params = {
'booster': 'gbtree', #使用gbtree
'objective': 'multi:softmax', # 多分类的问题、
# 'objective': 'multi:softprob', # 多分类概率
#'objective': 'binary:logistic', #二分类
'eval_metric': 'merror', #logloss
'num_class': 4, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 8, # 构建树的深度,越大越容易过拟合
'alpha': 0, # L1正则化系数
'lambda': 10, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.5, # 生成树时进行的列采样
'min_child_weight': 3,
# 这个参数默认是 1,是每个叶子里面 h 的和至少是多少,对正负样本不均衡时的 0-1 分类而言
# 假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
# 这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。
'silent': 0, # 设置成1则没有运行信息输出,最好是设置为0\.
'eta': 0.03, # 如同学习率
'seed': 1000,
'nthread': -1, # cpu 线程数
'missing': 1
#'scale_pos_weight': (np.sum(y==0)/np.sum(y==1)) # 用来处理正负样本不均衡的问题,通常取:sum(negative cases) / sum(positive cases)
}
这里进行迭代次数设置和 k 折交叉验证,训练模型,并进行模型保存和预测结果。
plst = list(params.items())
num_rounds = 200 # 迭代次数
watchlist = [(xgb_train, 'train')]
# 交叉验证
result = xgb.cv(plst, xgb_train, num_boost_round=200, nfold=4, early_stopping_rounds=200, verbose_eval=True, folds=StratifiedKFold(n_splits=4).split(vec.transform(x_train), y_train))
# 训练模型并保存
# early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练
model = xgb.train(plst, xgb_train, num_rounds, watchlist, early_stopping_rounds=200)
#model.save_model('../data/model/xgb.model') # 用于存储训练出的模型
#predicts = model.predict(xgb_test) #预测
二、词向量 Word2Vec 和 FastText 实战
深度学习带给自然语言处理最令人兴奋的突破是词向量(Word Embedding)技术。词向量技术是将词语转化成为稠密向量。在自然语言处理应用中,词向量作为机器学习、深度学习模型的特征进行输入。因此,最终模型的效果很大程度上取决于词向量的效果。
1. Word2Vec 词向量
在 Word2Vec 出现之前,自然语言处理经常把字词进行独热编码,也就是 One-Hot Encoder。
大数据 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
云计算[0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
机器学习[0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
人工智能[0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
比如上面的例子中,大数据 、云计算、机器学习和人工智能各对应一个向量,向量中只有一个值为 1,其余都为 0。所以使用 One-Hot Encoder 有以下问题:第一,词语编码是随机的,向量之间相互独立,看不出词语之间可能存在的关联关系。第二,向量维度的大小取决于语料库中词语的多少,如果语料包含的所有词语对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。
而解决这个问题的手段,就是使用向量表示(Vector Representations)。
Word2Vec 是 Google 团队 2013 年推出的,自提出后被广泛应用在自然语言处理任务中,并且受到它的启发,后续出现了更多形式的词向量模型。Word2Vec 主要包含两种模型:Skip-Gram 和 CBOW,值得一提的是,Word2Vec 词向量可以较好地表达不同词之间的相似和类比关系。
下面我们通过代码实战来体验一下 Word2Vec,pip install gensim 安装好库后,即可导入使用:
训练模型定义
from gensim.models import Word2Vec
model = Word2Vec(sentences, sg=1, size=100, window=5, min_count=5, negative=3, sample=0.001, hs=1, workers=4)
参数解释:
- sg=1 是 skip-gram 算法,对低频词敏感;默认 sg=0 为 CBOW 算法。
- size 是输出词向量的维数,值太小会导致词映射因为冲突而影响结果,值太大则会耗内存并使算法计算变慢,一般值取为 100 到 200 之间。
- window 是句子中当前词与目标词之间的最大距离,3 表示在目标词前看 3-b 个词,后面看 b 个词(b 在 0-3 之间随机)。
- min_count 是对词进行过滤,频率小于 min-count 的单词则会被忽视,默认值为 5。
- negative 和 sample 可根据训练结果进行微调,sample 表示更高频率的词被随机下采样到所设置的阈值,默认值为 1e-3。
- hs=1 表示层级 softmax 将会被使用,默认 hs=0 且 negative 不为 0,则负采样将会被选择使用。
- 详细参数说明可查看 Word2Vec 源代码。
训练后的模型保存与加载,可以用来计算相似性,最大匹配程度等。
model.save(model) #保存模型
model = Word2Vec.load(model) #加载模型
model.most_similar(positive=['女人', '女王'], negative=['男人'])
#输出[('女王', 0.50882536), ...]
model.similarity('女人', '男人')
#输出0.73723527
2.FastText词向量
FastText 是 facebook 开源的一个词向量与文本分类工具,模型简单,训练速度非常快。FastText 做的事情,就是把文档中所有词通过 lookup table 变成向量,取平均后直接用线性分类器得到分类结果。
FastText python 包的安装:
pip install fasttext
FastText 做文本分类要求文本是如下的存储形式:
__label__1 ,内容。
__label__2,内容。
__label__3 ,内容。
__label__4,内容。
其中前面的 __label__ 是前缀,也可以自己定义,__label__ 后接的为类别,之后接的就是我是我们的文本内容。
调用 fastText 训练生成模型,对模型效果进行评估。
import fasttext
classifier = fasttext.supervised('train_data.txt', 'classifier.model', label_prefix='__label__')
result = classifier.test('train_data.txt')
print(result.precision)
print(result.recall)
实际预测过程:
label_to_cate = {1:'科技', 2:'财经', 3:'体育', 4:'生活', 5:'美食'}
texts = ['现如今 机器 学习 和 深度 学习 带动 人工智能 飞速 的 发展 并 在 图片 处理 语音 识别 领域 取得 巨大成功']
labels = classifier.predict(texts)
print(labels)
print(label_to_cate[int(labels[0][0])])
[[u'1']]
科技
三、文本分类之神经网络 CNN 和 LSTM 实战
1. CNN 做文本分类实战
CNN 在图像上的巨大成功,使得大家都有在文本上试一把的冲动。CNN 的原理这里就不赘述了,关键看看怎样用于文本分类的,下图是一个 TextCNN 的结构(来源:网络):
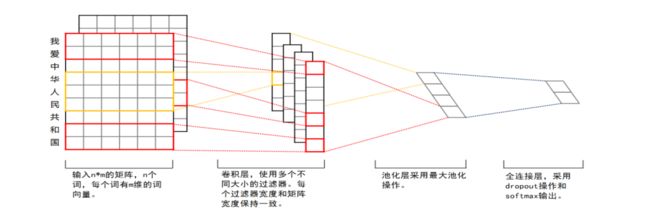
具体结构介绍:
(1)输入层
可以把输入层理解成把一句话转化成了一个二维的图像:每一排是一个词的 Word2Vec 向量,纵向是这句话的每个词按序排列。输入数据的 size,也就是图像的 size,n×k,n 代表训练数据中最长的句子的词个数,k 是 embbeding 的维度。从输入层还可以看出 kernel 的 size。很明显 kernel 的高 (h) 会有不同的值,有的是 2,有的是 3。这很容易理解,不同的 kernel 想获取不同范围内词的关系;和图像不同的是,NLP 中的 CNN 的 kernel 的宽 (w) 一般都是图像的宽,也就是 Word2Vec 的维度,这也可以理解,因为我们需要获得的是纵向的差异信息,也就是不同范围的词出现会带来什么信息。
(2)卷积层
由于 kernel 的特殊形状,因此卷积后的 feature map 是一个宽度是 1 的长条。
(3)池化层
这里使用 MaxPooling,并且一个 feature map 只选一个最大值留下。这被认为是按照这个 kernel 卷积后的最重要的特征。
(4)全连接层
这里的全连接层是带 dropout 的全连接层和 softmax。
下面我们看看自己用 Tensorflow 如何实现一个文本分类器:
超参数定义:
#文档最长长度
MAX_DOCUMENT_LENGTH = 100
#最小词频数
MIN_WORD_FREQUENCE = 2
#词嵌入的维度
EMBEDDING_SIZE = 20
#filter个数
N_FILTERS = 10
#感知野大小
WINDOW_SIZE = 20
#filter的形状
FILTER_SHAPE1 = [WINDOW_SIZE, EMBEDDING_SIZE]
FILTER_SHAPE2 = [WINDOW_SIZE, N_FILTERS]
#池化
POOLING_WINDOW = 4
POOLING_STRIDE = 2
n_words = 0
网络结构定义,2 层的卷积神经网络,用于短文本分类:
def cnn_model(features, target):
# 先把词转成词嵌入
# 我们得到一个形状为[n_words, EMBEDDING_SIZE]的词表映射矩阵
# 接着我们可以把一批文本映射成[batch_size, sequence_length, EMBEDDING_SIZE]的矩阵形式
target = tf.one_hot(target, 15, 1, 0)
word_vectors = tf.contrib.layers.embed_sequence(
features, vocab_size=n_words, embed_dim=EMBEDDING_SIZE, scope='words')
word_vectors = tf.expand_dims(word_vectors, 3)
with tf.variable_scope('CNN_Layer1'):
# 添加卷积层做滤波
conv1 = tf.contrib.layers.convolution2d(
word_vectors, N_FILTERS, FILTER_SHAPE1, padding='VALID')
# 添加RELU非线性
conv1 = tf.nn.relu(conv1)
# 最大池化
pool1 = tf.nn.max_pool(
conv1,
ksize=[1, POOLING_WINDOW, 1, 1],
strides=[1, POOLING_STRIDE, 1, 1],
padding='SAME')
# 对矩阵进行转置,以满足形状
pool1 = tf.transpose(pool1, [0, 1, 3, 2])
with tf.variable_scope('CNN_Layer2'):
# 第2个卷积层
conv2 = tf.contrib.layers.convolution2d(
pool1, N_FILTERS, FILTER_SHAPE2, padding='VALID')
# 抽取特征
pool2 = tf.squeeze(tf.reduce_max(conv2, 1), squeeze_dims=[1])
# 全连接层
logits = tf.contrib.layers.fully_connected(pool2, 15, activation_fn=None)
loss = tf.losses.softmax_cross_entropy(target, logits)
train_op = tf.contrib.layers.optimize_loss(
loss,
tf.contrib.framework.get_global_step(),
optimizer='Adam',
learning_rate=0.01)
return ({
'class': tf.argmax(logits, 1),
'prob': tf.nn.softmax(logits)
}, loss, train_op)
2. LSTM 做文本分类实战
上面实现了基于 CNN 的文本分类器之后,再来做一个基于 LSTM 分类器,会觉得非常容易,因为变化的部分只偶遇中间把 CNN 换成了 LSTM 模型。关于 RNN 和 LSTM 的理论知识,请自行解决,这里主要给出思路和代码实现。
具体结构,参照下面这幅图(来源:网络):
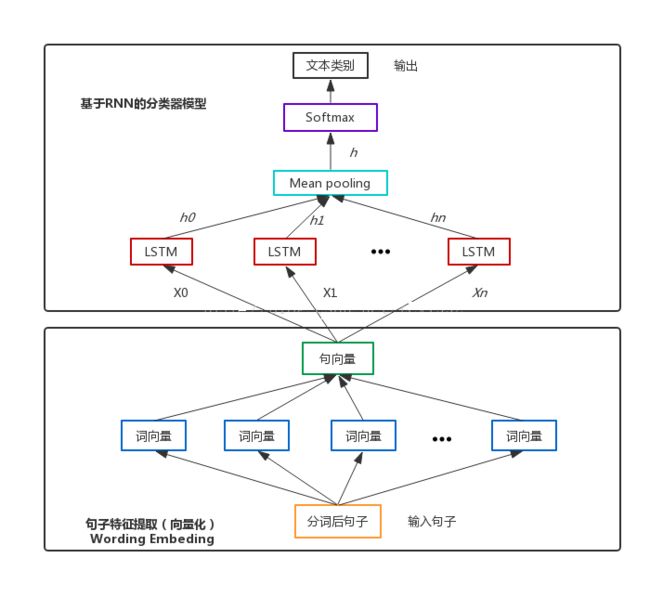
上面我们用的 Tensorflow 实现的,这次我们用 Keras 更简单方便的实现其核心代码:
#超参数定义
MAX_SEQUENCE_LENGTH = 100
EMBEDDING_DIM = 200
VALIDATION_SPLIT = 0.16
TEST_SPLIT = 0.2
epochs = 10
batch_size = 128
#模型网络定义
model = Sequential()
model.add(Embedding(len(word_index) + 1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH))
model.add(LSTM(200, dropout=0.2, recurrent_dropout=0.2))
model.add(Dropout(0.2))
model.add(Dense(labels.shape[1], activation='softmax'))
model.summary()
可见,基于 Keras 实现神经网络比 Tensorflow 要简单和容易很多,Keras 搭建神经网络俗称“堆积木”,这里有所体现。所以笔者也推荐,如果想快速实现一个神经网络,建议先用 Keras 快速搭建验证,之后再尝试用 Tensorflow 去实现。
总结,本次 Chat 就将分享到这里,从 XGBoost 到词向量以及神经网络,内容非常多也非常重要,笔者并没有过多的讲述理论并不代表不重要,相反理论很重要,但笔者希望能够先通过代码实战进行体验,然后静下心来完成理论部分的学习,最后代码和理论相结合,效率更高。
如有侵权请联系QQ:758230255删除