分布式消息队列RocketMQ
一、RocketMQ简介
RocketMQ(火箭MQ) 出自于阿里,后开源给apache成为apache的顶级开源项目之一,顶住了淘宝10年的 双11压力 是电商产品的不二选择 (略微有点夸张)
1、MQ概述
Message Queue,是一种提供消息队列服务的中间件,也成为消息中间件,是一套提供了消息生产、存储、消费全过程API的软件系统
2、MQ用途
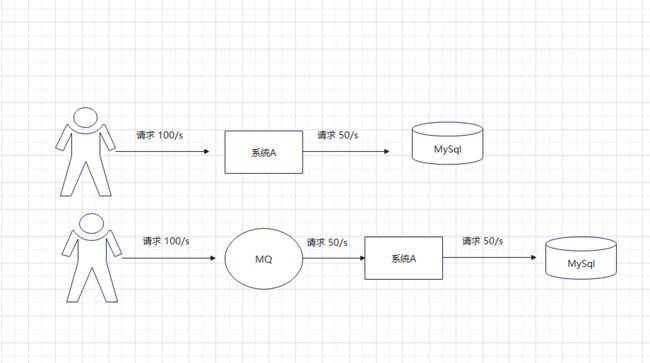
(1)、限流削峰
系统A每秒只能处理50请求 一般来讲如过收到请求大于处理请求,则多余请求会舍去。如果加入MQ 多出来的请求就会存储在MQ中,每秒向系统A发送50请求
(2)、异步解耦
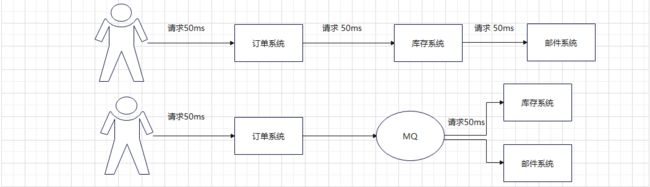
用户请求上游系统模块,上游再去调用下游,在下游做出回应之前,一直处于等待状态,这也是同步调用。
加入MQ后则不用等待一条下单链结束后才返回结果给用户,让库存系统和邮件系统可以同时执行。
可以看出原本需要 50+50+50 = 150ms的下单链 现在只需要 50+50 = 100ms就可以解决
(3)、数据收集
分布式系统会产生海量级数据流,如:业务日志、监控数据、用户行为(用户点了哪里,看了什么。。)等。针对这些数据流进行实时或批量采集汇总,然后对这些数据流进行大数据分析,这是当前互联网平台必备的计数。通过MQ完成此类数据收集是最好的选择
3、常见的MQ

(1)、ActiveMQ
使用java开发的一款MQ产品。早些年公司项目都在使用,现在社区活跃度低。现在的项目中已经很少使用了
(2)、RabbitMQ
使用Erlang开发的一款MQ产品。吞吐量较kafka和RocketMQ较低,由于不是使用java语言开发。因此对其定制化开发较难
(3)、kafaka
使用Erlang/java开发的一款MQ产品。其最大的特点就是吞吐率高,常用于大数据领域实时计算、日志采集等场景。没有遵循任何的MQ协议,而是使用自研协议
(4)、RocketMQ
使用java开发的一款MQ产品。是阿里基于kafka开发而来。经过数年阿里双11考研,性能与稳定性非常高,没有遵循任何常见MQ协议(与基于kafka开发有关系),而是使用自研协议
4、常见MQ协议
因主要学习的 kafaka/RocketMQ 并不遵循常见的MQ协议 因此先放一放。
二、RocketMQ安装
1、基本概念
(1)、消息(Message)
消息是指消息系统所传输信息的无力再提,生产和消费数据的最小单位,每条消息必须属于一个主题
(2)、主题(Topic)
Topic(主题)可以看做消息的规类,它是消息的第一级类型。比如一个电商系统可以分为:交易消息、物流消息等,一条消息必须有一个 Topic 。
Topic 与生产者和消费者的关系非常松散,一个 Topic 可以有0个、1个、多个生产者向其发送消息,一个生产者也可以同时向不同的 Topic 发送消息。
一个 Topic 也可以被 0个、1个、多个消费者订阅。

(3)、标签(Tag)
Tag(标签)可以看作子主题,它是消息的第二级类型,用于为用户提供额外的灵活性。使用标签,同一业务模块不同目的的消息就可以用相同 Topic 而不同的 Tag 来标识。比如交易消息又可以分为:交易创建消息、交易完成消息等,一条消息可以没有 Tag 。
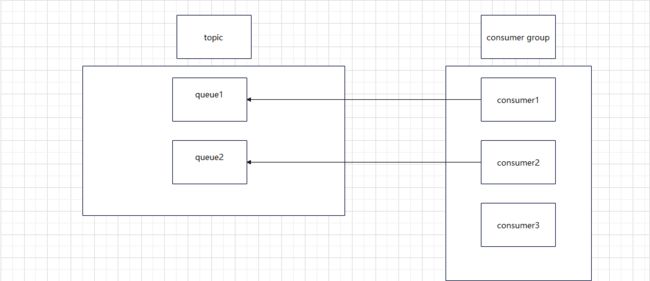
(4)、队列(Queue)
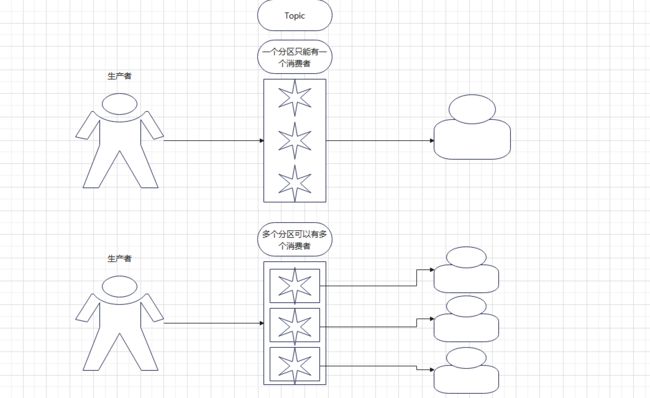
存储消息的物理实体。一个 Topic可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一个Topic的Queue也被称为一个Topic中消息的分区
一个 Topic 中 一个 Queue 的消息只能被一个 消费者组 中的消费者消费
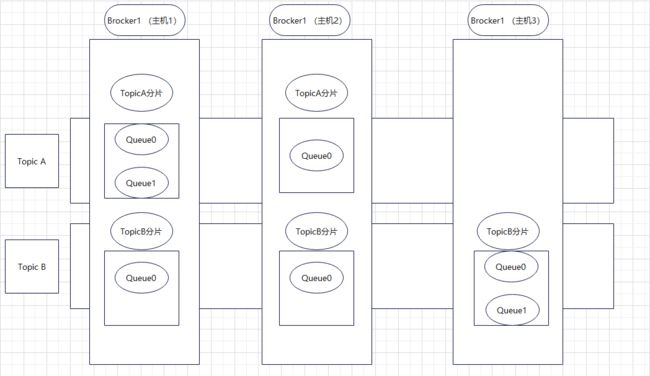
分片(Sharding)不同于分区。在RocketMQ中,分片指的是存放相应 Topic 的 Broker(主机)。每个分片中会创建出相应数量的分区,即 Queue,每个Queue的大小都是相同的
(5)、消息标识(MessageID/Key)
RocketMQ中每个消息拥有MessageID,且可以携带具有业务标识的Key,以便对消息的查询。MessageID有两个:在生产者 send() 消息时会自动生成一个MessageID(msgID),当消息到达Broker后,Broker也会自动生成一个MessageID(offsetMsgID)。msgID、offsetMsgID与key都成为消息标识
msgID:由producer生成,规则为:
producerIP + 进程pid + MessageClientIdSetter类的ClassLoder的hashcode + 当前时间 + AutomicInteger自增计数器
offsetMsgID:由Broker端生成,规则为:
brokerIP + 物理分区的offset
key:由用户指定的业务相关的唯一标识
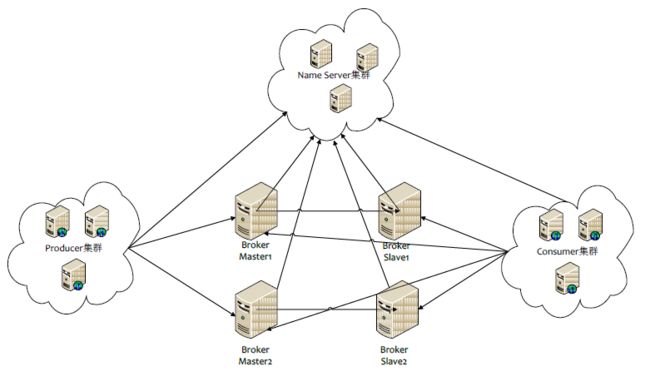
2、系统架构

(1)、Producer
消息生产者,负责产生消息,一般由业务系统负责产生消息。
- Producer由用户进行分布式部署,消息由Producer通过多种负载均衡模式发送到Broker集群,发送低延时,支持快速失败。
- RocketMQ 提供了三种方式发送消息:同步、异步和单向
- 同步发送:同步发送指消息发送方发出数据后会在收到接收方发回响应之后才发下一个数据包。一般用于重要通知消息,例如重要通知邮件、营销短信。
- 异步发送:异步发送指发送方发出数据后,不等接收方发回响应,接着发送下个数据包,一般用于可能链路耗时较长而对响应时间敏感的业务场景,例如用户视频上传后通知启动转码服务。
- 单向发送:单向发送是指只负责发送消息而不等待服务器回应且没有回调函数触发,适用于某些耗时非常短但对可靠性要求并不高的场景,例如日志收集。
(2)、Consumer
消息消费者,负责消费消息,一般是后台系统负责异步消费。消费时会均分。
- Consumer也由用户部署,支持PUSH和PULL两种消费模式,支持集群消费和广播消息,提供实时的消息订阅机制。
- Pull:拉取型消费者(Pull Consumer)主动从消息服务器拉取信息,只要批量拉取到消息,用户应用就会启动消费过程,所以 Pull 称为主动消费型。
- Push:推送型消费者(Push Consumer)封装了消息的拉取、消费进度和其他的内部维护工作,将消息到达时执行的回调接口留给用户应用程序来实现。所以 Push 称为被动消费类型,但从实现上看还是从消息服务器中拉取消息,不同于 Pull 的是 Push 首先要注册消费监听器,当监听器处触发后才开始消费消息。
- 消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的Consumer将不能消费消息。反之,一个Topic类型的消息可以被多个消费者组消费。
(3)、Name Server
①、功能介绍
NameServer是一个Broker与Topic路由的注册中心,支持Broker动态注册与发现。
②、路由注册
NameServer是无状态的。在Broker节点启动时,轮询NameServer列表,与每个NameServer节点建立长连接,发起注册请求。在NameServer内部维护着一个Broker列表,用来动态存储Broker的信息。以此保证节点中的数据同步。(zk等与之相反,通知一个让其内部自己同步。麻烦,注册是简单了,如果扩容NameServer需要修改Broker指定新加的NameServer)
Broker节点会每30s发送一次心跳,将最新的的信息以心跳包的方式上报NameServer。心跳包含BrokerID、Broker地址(Ip+Port)、Broker名称、Broker所属集群名称......,NameServer接受心跳包后,会更新心跳时间戳,记录Broker最新存活时间
③、路由剔除
如果NameServer没有收到Broker的心跳,NameServer可能会将其从Broker中剔除
NameServer中有一个定时任务,每隔10s会扫描Broker表,查看每一个Broker最新心跳时间距离当前是否超过120s,如果超过,则会判定Broker失效,然后将其从Broker列表中剔除。(RocketMQ没有自我保护机制)
若要停掉Broker工作,需将Broker读写权限禁用,Client等向Broker发送请求会受到NO_PERMISSION响应,然后Client会进行对其他Broker重试。
④、路由发现
RocketMQ采用的是Pull模型。当Topic路由信息发生变化时,NameServer不会主动推送给客户端,而是客户端定时拉去主题最新的路由。默认科幻段每30s拉取一次最新的路由。
1、push模型:实时性好,是一个发布订阅模型,需要维护一个长连接。耗费资源。
2、pull模型:实时性较差
3、Long Polling模型:长轮询模型。整合pull和push,维护一个长连接指定时间再去释放长连接
⑤、客户端NameServer选择策略
客户端首先生成一个随机数,在与NameServer节点数量取模,此时得到就是所要连接的节点索引,然后就会进行连接。如果连接失败,则会采用round-robin,逐个尝试去连接其他节点。首先采用随即策略,失败后采用轮询
(4)、Broker
①、功能介绍
消息中转角色,负责存储消息,转发消息。
- Broker是具体提供业务的服务器,单个Broker节点与所有的NameServer节点保持长连接及心跳,并会定时将Topic信息注册到NameServer,顺带一提底层的通信和连接都是基于Netty实现的。
- Broker负责消息存储,以Topic为纬度支持轻量级的队列,单机可以支撑上万队列规模,支持消息推拉模型。
- 官网上有数据显示:具有上亿级消息堆积能力,同时可严格保证消息的有序性。
②、模块构成

Remoting Module:整个Broker的尸体,负责处理来自Clients端的请求。而这个Broker实体则由以下模块构成。
Client Manager:客户端管理器。负责接受、解析客户端(Producer/Consumer)请求,管理客户端。例如:维护Consumer的Topuc订阅信息
Store Service:存储服务。提供方便简单的API接口,处理消息存储到物理硬盘 和 消息查询 功能
HA Service:高可用服务,提供Master Broker 和 Slave Broker之间的数据同步功能
Index Service:索引服务。根据特定的Message key,投递到Broker的消息进行索引服务,同时也提供根据Message Key对消息进行快速查询的功能
③、集群部署
主备集群,Master挂掉后会启动Slave。Master与Slave的对应关系是通过指定相同的BrokerName、不同的BrokerId来确定。BrokerId为0表示Master,非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有的NameServer。

(5)、工作流程
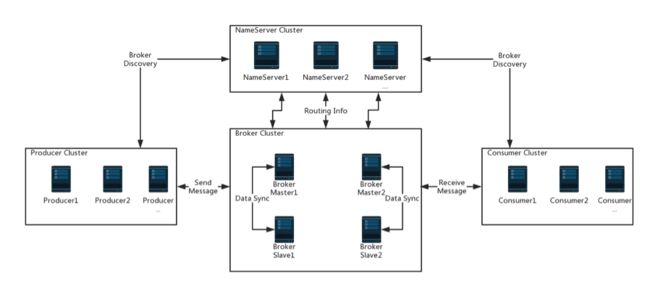
1、启动NameServer,启动后开始监听端口,等待Broker,Producer,Consumer连接
2、启动Broker时,Broker会与所有的NameServer建立并保持长连接,然后每隔30s向NameServer发送心跳包
3、收发消息前,可先创Topic,创建时需要指定该Topic要存储在那些Broker上,在次高压部分华北Topic时也会将Topic与Broker的关系写到NameServer中。 此步骤时可选的,也可以在发送消息时自动创建Topic
4、Producer发送消息,启动时先跟NameServer集群中其中一台建立长连接,并从NameServer中获取路由信息,即当前发送的Topic的Queue与Broker地址(Ip+Port)的映射关系。然后根据算法策略从队列选择一个Queue,与队列所在的Broker建立长连接从而向Broker发消息。在获取到路由信息后,Producer会首先将路由信息缓存到本地,再每30s从NamesServer更新一次路由信息。
5、Consumer与Producer类似,跟其中一台NameServer建立长连接,获取其所订阅Topic的路由信息,然后根据算法策略从路由信息中获取其所要消费的Queue,然后直接跟Broker建立长连接,开始消费其中的消息。Consumer再获取到路由信息后,同样也会每30s从NameServer更新一次路由信息。不同于Producer的是,Consumer还会向Broker发送心跳,以确保Broker的存活状态。
Topic创建模式
Topic手动创建模式有两种
集群模式:该模式下创建的Topic在该集群中,所有Broker中的Queue数量相同。
Broker模式:该模式下创建的Topic在该集群中,每个Broker中的Queue数量可以不同。
Topic自动创建模式有一种
默认采用的是Broker模式:会为每个Broker默认创建4个Queue(配置文件中取的4)

读写队列
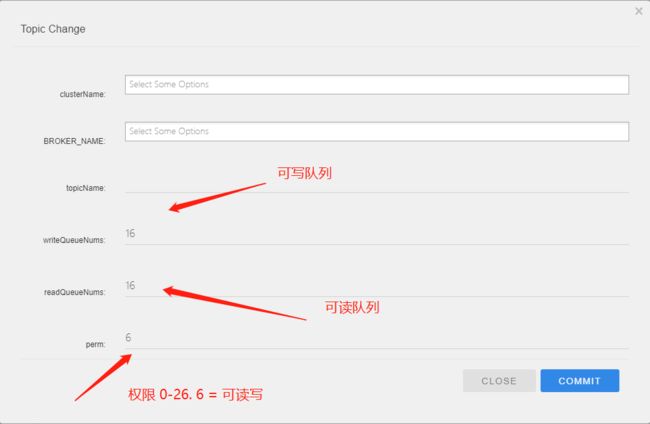
读写队列可以不同,例:可写队列设置为16,可读队列写为14,那么生产者可以把消息卸载0-15的队列中,而消费者只能消费0-14中队列的消息。
为何如此设计?
因为这么搞可以方便缩容,例:可写可读队列都为16,现在只保存8个队列,可以先改可写队列为8,待消费者消费完可读队列中8-15的消息后在调整可读队列为8,这样一来整个缩容过程没有任何消息丢失。
三、单机的安装与启动
1、安装RocketMQ
在官网下载安装RocketMQ和JDK并解压
注:RocketMQ是zip 需要安装unzip才能解压。
官网
2、修改配置
注:RocketMQ适配于J8,J8以上需要修改配置文件
例如:RocketMQ4.9.2(2021-1)
修改RocketMQ的bin目录下的 runserver.sh、runbroker.sh、tools.sh
(1)、runserver.sh
删除:
- -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy
- JAVA_OPT="${JAVA_OPT} -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m"
- JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${JAVA_HOME}/jre/lib/ext:${BASE_DIR}/lib"(删除带有Djava哪一行就行不同版本不一样)
更改
- CLASSPATH为:${BASE_DIR}/lib/rocketmq-broker-4.5.1.jar:${BASE_DIR}/lib/*{BASE_DIR}/conf:${CLASSPATH} rocketmq-broker-版本号.jar
4.9.2改好的
#!/bin/sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#===========================================================================================
# Java Environment Setting
#===========================================================================================
error_exit ()
{
echo "ERROR: $1 !!"
exit 1
}
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=$HOME/jdk/java
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=/usr/java
[ ! -e "$JAVA_HOME/bin/java" ] && error_exit "Please set the JAVA_HOME variable in your environment, We need java(x64)!"
export JAVA_HOME
export JAVA="$JAVA_HOME/bin/java"
export BASE_DIR=$(dirname $0)/..
export CLASSPATH=${BASE_DIR}/lib/rocketmq-broker-4.9.2.jar:${BASE_DIR}/lib/*:${BASE_DIR}/conf:${CLASSPATH}
#===========================================================================================
# JVM Configuration
#===========================================================================================
# The RAMDisk initializing size in MB on Darwin OS for gc-log
DIR_SIZE_IN_MB=600
choose_gc_log_directory()
{
case "`uname`" in
Darwin)
if [ ! -d "/Volumes/RAMDisk" ]; then
# create ram disk on Darwin systems as gc-log directory
DEV=`hdiutil attach -nomount ram://$((2 * 1024 * DIR_SIZE_IN_MB))` > /dev/null
diskutil eraseVolume HFS+ RAMDisk ${DEV} > /dev/null
echo "Create RAMDisk /Volumes/RAMDisk for gc logging on Darwin OS."
fi
GC_LOG_DIR="/Volumes/RAMDisk"
;;
*)
# check if /dev/shm exists on other systems
if [ -d "/dev/shm" ]; then
GC_LOG_DIR="/dev/shm"
else
GC_LOG_DIR=${BASE_DIR}
fi
;;
esac
}
choose_gc_options()
{
# Example of JAVA_MAJOR_VERSION value : '1', '9', '10', '11', ...
# '1' means releases befor Java 9
JAVA_MAJOR_VERSION=$("$JAVA" -version 2>&1 | sed -r -n 's/.* version "([0-9]*).*$/\1/p')
if [ -z "$JAVA_MAJOR_VERSION" ] || [ "$JAVA_MAJOR_VERSION" -lt "9" ] ; then
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
JAVA_OPT="${JAVA_OPT} -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:SurvivorRatio=8"
JAVA_OPT="${JAVA_OPT} -verbose:gc -Xlog:gc:${GC_LOG_DIR}/rmq_srv_gc_%p_%t.log -XX:+PrintGCDateStamps"
JAVA_OPT="${JAVA_OPT} -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m"
else
JAVA_OPT="${JAVA_OPT} -server -Xms4g -Xmx4g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0"
JAVA_OPT="${JAVA_OPT} -Xlog:gc*:file=${GC_LOG_DIR}/rmq_srv_gc_%p_%t.log:time,tags:filecount=5,filesize=30M"
fi
}
choose_gc_log_directory
choose_gc_options
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"
JAVA_OPT="${JAVA_OPT} -XX:-UseLargePages"
#JAVA_OPT="${JAVA_OPT} -Xdebug -Xrunjdwp:transport=dt_socket,address=9555,server=y,suspend=n"
JAVA_OPT="${JAVA_OPT} ${JAVA_OPT_EXT}"
JAVA_OPT="${JAVA_OPT} -cp ${CLASSPATH}"
$JAVA ${JAVA_OPT} $@
(2)、runbroker.sh
删除
- -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy
- JAVA_OPT="${JAVA_OPT} -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m"
- JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${JAVA_HOME}/jre/lib/ext:${BASE_DIR}/lib"(删除带有Djava哪一行就行不同版本不一样)
修改
- CLASSPATH为:${BASE_DIR}/lib/rocketmq-broker-4.5.1.jar:${BASE_DIR}/lib/*{BASE_DIR}/conf:${CLASSPATH} rocketmq-broker-版本号.jar
-Xloggc:改成-Xlog:gc
4.9.2改好的
#!/bin/sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#===========================================================================================
# Java Environment Setting
#===========================================================================================
error_exit ()
{
echo "ERROR: $1 !!"
exit 1
}
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=$HOME/jdk/java
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=/usr/java
[ ! -e "$JAVA_HOME/bin/java" ] && error_exit "Please set the JAVA_HOME variable in your environment, We need java(x64)!"
export JAVA_HOME
export JAVA="$JAVA_HOME/bin/java"
export BASE_DIR=$(dirname $0)/..
export CLASSPATH=${BASE_DIR}/lib/rocketmq-broker-4.9.2.jar:${BASE_DIR}/lib/*:${BASE_DIR}/conf:${CLASSPATH}
#===========================================================================================
# JVM Configuration
#===========================================================================================
# The RAMDisk initializing size in MB on Darwin OS for gc-log
DIR_SIZE_IN_MB=600
choose_gc_log_directory()
{
case "`uname`" in
Darwin)
if [ ! -d "/Volumes/RAMDisk" ]; then
# create ram disk on Darwin systems as gc-log directory
DEV=`hdiutil attach -nomount ram://$((2 * 1024 * DIR_SIZE_IN_MB))` > /dev/null
diskutil eraseVolume HFS+ RAMDisk ${DEV} > /dev/null
echo "Create RAMDisk /Volumes/RAMDisk for gc logging on Darwin OS."
fi
GC_LOG_DIR="/Volumes/RAMDisk"
;;
*)
# check if /dev/shm exists on other systems
if [ -d "/dev/shm" ]; then
GC_LOG_DIR="/dev/shm"
else
GC_LOG_DIR=${BASE_DIR}
fi
;;
esac
}
choose_gc_log_directory
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m"
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0"
JAVA_OPT="${JAVA_OPT} -verbose:gc -Xloggc:${GC_LOG_DIR}/rmq_broker_gc_%p_%t.log"
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"
JAVA_OPT="${JAVA_OPT} -XX:+AlwaysPreTouch"
JAVA_OPT="${JAVA_OPT} -XX:MaxDirectMemorySize=15g"
JAVA_OPT="${JAVA_OPT} -XX:-UseLargePages -XX:-UseBiasedLocking"
#JAVA_OPT="${JAVA_OPT} -Xdebug -Xrunjdwp:transport=dt_socket,address=9555,server=y,suspend=n"
JAVA_OPT="${JAVA_OPT} ${JAVA_OPT_EXT}"
JAVA_OPT="${JAVA_OPT} -cp ${CLASSPATH}"
numactl --interleave=all pwd > /dev/null 2>&1
if [ $? -eq 0 ]
then
if [ -z "$RMQ_NUMA_NODE" ] ; then
numactl --interleave=all $JAVA ${JAVA_OPT} $@
else
numactl --cpunodebind=$RMQ_NUMA_NODE --membind=$RMQ_NUMA_NODE $JAVA ${JAVA_OPT} $@
fi
else
$JAVA ${JAVA_OPT} $@
fi
(3)、tool.sh
删除
- JAVA_OPT="${JAVA_OPT} -Djava.ext.dirs=${BASE_DIR}/lib:${JAVA_HOME}/jre/lib/ext"(删除带有Djava哪一行就行不同版本不一样)
修改
- 更改
CLASSPATH的值为export CLASSPATH=${BASE_DIR}/lib/*{BASE_DIR}/conf:.{CLASSPATH}
4.9.2改好的
#!/bin/sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#===========================================================================================
# Java Environment Setting
#===========================================================================================
error_exit ()
{
echo "ERROR: $1 !!"
exit 1
}
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=$HOME/jdk/java
[ ! -e "$JAVA_HOME/bin/java" ] && JAVA_HOME=/usr/java
[ ! -e "$JAVA_HOME/bin/java" ] && error_exit "Please set the JAVA_HOME variable in your environment, We need java(x64)!"
export JAVA_HOME
export JAVA="$JAVA_HOME/bin/java"
export BASE_DIR=$(dirname $0)/..
export CLASSPATH=export CLASSPATH=${BASE_DIR}/lib/*:${BASE_DIR}/conf:.:${CLASSPATH}
#===========================================================================================
# JVM Configuration
#===========================================================================================
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m"
JAVA_OPT="${JAVA_OPT} -cp ${CLASSPATH}"
$JAVA ${JAVA_OPT} "$@"
3、启动RocketMQ

方便复制
> nohup sh bin/mqnamesrv &
> tail -f ~/logs/rocketmqlogs/namesrv.log
The Name Server boot success...
> nohup sh bin/mqbroker -n localhost:9876 &
> tail -f ~/logs/rocketmqlogs/broker.log
The broker[%s, 172.30.30.233:10911] boot success...
4、关闭RocketMQ
方便复制
> sh bin/mqshutdown broker
The mqbroker(36695) is running...
Send shutdown request to mqbroker(36695) OK
> sh bin/mqshutdown namesrv
The mqnamesrv(36664) is running...
Send shutdown request to mqnamesrv(36664) OK
四、控制台的安装与启动
1、下载
可视化下载地址(GitHub)
下载下来是个SpringBoot工程
2、修改配置
修改application的 rocketmq.config.namesrvAddr= 你服务器的地址:broker启动的端口号
3、添加依赖
在解压目录rocketmq-console的pom.xml中添加如下JAXB依赖。
JAXB,Java Architechture for Xml Binding,用于XML绑定的Java技术,是一个业界标准,是一
项可以根据XML Schema生成Java类的技术。
javax.xml.bind
jaxb-api
2.3.0
com.sun.xml.bind
jaxb-impl
2.3.0
com.sun.xml.bind
jaxb-core
2.3.0
javax.activation
activation
1.1.1
4、打包
确保已经安装过Maven
进入该项目目录执行打开cmd执行以下命令:mvn clean package -Dmaven.test.skip=true
5、运行
java -jar 运行该jar包即可,然后就可在浏览器访问到该项目
当然 这个项目最好是挂在服务器上
五、集群搭建理论
1、数据复制与刷盘策略

(1)、复制策略
复制策略是Broker的Master与Slave间的数据同步方式。分为同步复制与异步复制:
同步复制:消息写入master后,master会等待slave同步数据成功后才向producer返回成功ACK
异步复制:消息写入master后,master立即向producer返回成功ACK,无需等待slave同步数据成功
异步复制策略会降低系统的写入延迟,RT变小,提高了系统的吞吐量
(2)、刷盘策略
刷盘策略指的是broker中消息的落盘方式,即消息发送到broker内存后消息持久化到磁盘的方式。分为同步刷盘与异步刷盘:
同步刷盘:当消息持久化到broker的磁盘后才算是消息写入成功。
异步刷盘:当消息写入到broker的内存后即表示消息写入成功,无需等待消息持久化到磁盘。
-
异步刷盘策略会降低系统的写入延迟,RT变小,提高了系统的吞吐量
-
消息写入到Broker的内存,一般是写入到了PageCache
-
对于异步 刷盘策略,消息会写入到PageCache后立即返回成功ACK。但并不会立即做落盘操作,而是当PageCache到达一定量时会自动进行落盘。
2、Broker集群模式
根据Broker集群中各个节点间关系的不同,Broker集群可以分为以下几类:
(1)、- 单Master
只有一个broker(其本质上就不能称为集群)。这种方式也只能是在测试时使用,生产环境下不能使用,因为存在单点问题。
(2)、多Master
broker集群仅由多个master构成,不存在Slave。同一Topic的各个Queue会平均分布在各个master节点上。
-
优点:配置简单,单个Master宕机或重启维护对应用无影响,在 磁盘配置为RAID10 时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
-
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅(不可消费),消息实时性会受到影响以上优点的前提是,这些Master都配置了RAID磁盘阵列。如果没有配置,一旦出现某Master宕机,则会发生大量消息丢失的情况。
以上优点的前提是,这些Master都配置了RAID磁盘阵列。如果没有配置,一旦出现某Master宕机,则会发生大量消息丢失的情况。
(3)、多Master多Slave模式-异步复制
-
broker集群由多个master构成,每个master又配置了多个slave(在配置了RAID磁盘阵列的情况下,一个master一般配置一个slave即可)。master与slave的关系是主备关系,即master负责处理消息的读写请求,而slave仅负责消息的备份与master宕机后的角色切换。
-
异步复制即前面所讲的复制策略中的异步复制策略,即消息写入master成功后,master立即向producer返回成功ACK,无需等待slave同步数据成功。
-
该模式的最大特点之一是,当master宕机后slave能够 自动切换 为master。不过由于slave从master的同步具有短暂的延迟(毫秒级),所以当master宕机后,这种异步复制方式可能会存在少量消息的丢失问题。
Slave从Master同步的延迟越短,其可能丢失的消息就越少,对于Master的RAID磁盘阵列;若使用的也是异步复制策略,同样也存在延迟问题,同样也可能会丢失消息。但RAID阵列的秘诀是微秒级的(因为是由硬盘支持的,但是成本过高),所以其丢失的数据量会更少。
(4)、多Master多Slave模式-同步双写
-
该模式是多Master多Slave模式的同步复制实现。所谓同步双写,指的是消息写入master成功后,master会等待slave同步数据成功后才向producer返回成功ACK,即master与slave都要写入成功后才会返回成功ACK,也即双写。
-
该模式与异步复制模式相比,优点是消息的安全性更高,不存在消息丢失的情况。但单个消息的RT(响应时间)略高,从而导致性能要略低(大约低10%)。
-
该模式存在一个大的问题:对于目前的版本,Master宕机后,Slave不会自动切换到Master(致命问题)。
(5)、最佳实践
- 一般会为Master配置RAID10磁盘阵列,然后再为其配置一个Slave。即利用了RAID10磁盘阵列的高
效、安全性,又解决了可能会影响订阅的问题。-------多M多S+RAID10阵列-
RAID磁盘阵列的效率要高于Master-Slave集群。因为RAID是硬件支持的。也正因为如此,所以RAID阵列
的搭建成本较高。 -
多Master+RAID阵列,与多Master多Slave集群的区别是什么?
-
多Master+RAID阵列,其仅仅可以保证数据不丢失,即不影响消息写入,但其可能会影响到
消息的订阅。但其执行效率要远高于多Master多Slave集群 -
多Master多Slave集群,其不仅可以保证数据不丢失,也不会影响消息写入。其运行效率要低
于多Master+RAID阵列
-
-
六、磁盘阵列RAID
1、RAID历史
1988 年美国加州大学伯克利分校的 D. A. Patterson 教授等首次在论文 “A Case of Redundant Array ofInexpensive Disks” 中提出了 RAID 概念 ,即廉价冗余磁盘阵列( Redundant Array of InexpensiveDisks )。
由于当时大容量磁盘比较昂贵, RAID 的基本思想是将多个容量较小、相对廉价的磁盘进行有机组合,从而以较低的成本获得与昂贵大容量磁盘相当的容量、性能、可靠性。随着磁盘成本和价格的不断降低, “廉价” 已经毫无意义。因此, RAID 咨询委员会( RAID Advisory Board, RAB )决定用“ 独立 ” 替代 “ 廉价 ” ,于时 RAID 变成了独立磁盘冗余阵列( Redundant Array of IndependentDisks )。但这仅仅是名称的变化,实质内容没有改变。
2、RAID等级
RAID 这种设计思想很快被业界接纳, RAID 技术作为高性能、高可靠的存储技术,得到了非常广泛的应用。 RAID 主要利用镜像、数据条带和数据校验三种技术来获取高性能、可靠性、容错能力和扩展性,根据对这三种技术的使用策略和组合架构,可以把 RAID 分为不同的等级,以满足不同数据应用的需求。
D. A. Patterson 等的论文中定义了 RAID0 ~ RAID6 原始 RAID 等级。随后存储厂商又不断推出 RAID7、 RAID10、RAID01 、 RAID50 、 RAID53 、 RAID100 等 RAID 等级,但这些并无统一的标准。目前业界与学术界公认的标准是 RAID0 ~ RAID6 ,而在实际应用领域中使用最多的 RAID 等级是 RAID0 、RAID1 、 RAID3 、 RAID5 、 RAID6 和 RAID10。
RAID 每一个等级代表一种实现方法和技术,等级之间并无高低之分。在实际应用中,应当根据用户的数据应用特点,综合考虑可用性、性能和成本来选择合适的 RAID 等级,以及具体的实现方式。
3、关键技术
(1)、镜像技术
- 镜像技术是一种冗余技术,为磁盘提供数据备份功能,防止磁盘发生故障而造成数据丢失。对于 RAID而言,采用镜像技术最典型地的用法就是,同时在磁盘阵列中产生两个完全相同的数据副本,并且分布在两个不同的磁盘上。镜像提供了完全的数据冗余能力,当一个数据副本失效不可用时,外部系统仍可正常访问另一副本,不会对应用系统运行和性能产生影响。而且,镜像不需要额外的计算和校验,故障修复非常快,直接复制即可。镜像技术可以从多个副本进行并发读取数据,提供更高的读 I/O 性能,但不能并行写数据,写多个副本通常会导致一定的 I/O 性能下降。
镜像技术提供了非常高的数据安全性,其代价也是非常昂贵的,需要至少双倍的存储空间。高成本限制了镜像的广泛应用,主要应用于至关重要的数据保护,这种场合下的数据丢失可能会造成非常巨大的损失。(硬盘不值钱没多大成本)
(2)、数据条带技术
- 将一个数据拆开,并行写给多个磁盘中;数据条带化技术是一种自动将 I/O操作负载均衡到多个物理磁盘上的技术。更具体地说就是,将一块连续的数据分成很多小部分并把它们分别存储到不同磁盘上。这就能使多个进程可以并发访问数据的多个不同部分,从而获得最大程度上的 I/O 并行能力,极大地提升性能。
(3)、数据校验技术
- 数据校验技术是指, RAID 要在写入数据的同时进行校验计算,并将得到的校验数据存储在 RAID 成员磁盘中。校验数据可以集中保存在某个磁盘或分散存储在多个不同磁盘中。当其中一部分数据出错时,就可以对剩余数据和校验数据进行反校验计算重建丢失的数据。(硬盘比CPU便宜,所以这个不咋地)
数据校验技术相对于镜像技术的优势在于节省大量开销,但由于每次数据读写都要进行大量的校验运算,对计算机的运算速度要求很高,且必须使用硬件 RAID 控制器。在数据重建恢复方面,检验技术比镜像技术复杂得多且慢得多。(并不实用)
4、RAID分类
从实现角度看, RAID 主要分为软 RAID、硬 RAID 以及混合 RAID 三种。对于项目而言,都是用 硬RAID ,成本毛毛雨~,其他两个了解就好
(1)、软 RAID
- 所有功能均有操作系统和 CPU 来完成,没有独立的 RAID 控制处理芯片和 I/O 处理芯片,效率自然最低。软件完成
(2)、硬 RAID
- 配备了专门的 RAID 控制处理芯片和 I/O 处理芯片以及阵列缓冲,不占用 CPU 资源。效率很高,但成本也很高。硬件完成
(3)、混合 RAID
- 具备 RAID 控制处理芯片,但没有专门的I/O 处理芯片,需要 CPU 和驱动程序来完成。性能和成本在软RAID 和硬 RAID 之间。软硬完成
5、常见RAID等级详解
(1)、JBOD
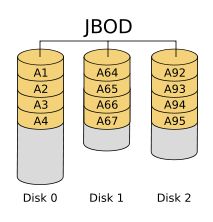
-
JBOD ,Just a Bunch of Disks,磁盘簇。表示一个没有控制软件提供协调控制的磁盘集合,这是 RAID区别与 JBOD 的主要因素。 JBOD 将多个物理磁盘串联起来,提供一个巨大的逻辑磁盘·。
-
JBOD 的数据存放机制是由第一块磁盘开始按顺序往后存储,当前磁盘存储空间用完后,再依次往后面的磁盘存储数据。 JBOD 存储性能完全等同于单块磁盘,而且也不提供数据安全保护。
多块磁盘组成的逻辑磁盘;
其只是简单提供一种扩展存储空间的机制,JBOD可用存储容量等于所有成员磁盘的存储空间之和
JBOD 常指磁盘柜,而不论其是否提供 RAID 功能。不过,JBOD并非官方术语,官方称为Spanning。
(2)、RAID0
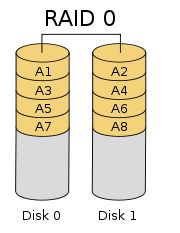
-
RAID0 是 一种简单的、无数据校验的数据条带化技术。实际上不是一种真正的 RAID ,因为它并不提供任何形式的冗余策略 。 RAID0 将所在磁盘条带化后组成大容量的存储空间,将数据分散存储在所有磁盘中,以独立访问方式实现多块磁盘的并读访问。
-
理论上讲,一个由 n 块磁盘组成的 RAID0 ,它的读写性能是单个磁盘性能的 n 倍,但由于总线带宽等多种因素的限制,实际的性能提升低于理论值。由于可以并发执行 I/O 操作,总线带宽得到充分利用。再加上不需要进行数据校验,RAID0 的性能在所有 RAID 等级中是最高的。
-
RAID0 具有低成本、高读写性能、 100% 的高存储空间利用率等优点,但是它不提供数据冗余保护,一旦数据损坏,将无法恢复。
应用场景:
对数据的顺序读写要求不高,对数据的安全性和可靠性要求不高,但对系统性能要求很高的场景。
和JBOD的区别:
1、存储容量:都是成员磁盘容量总和
2、磁盘利用率,都是100%,即都没有做任何的数据冗余备份
3、JBOD:数据是顺序存放的,一个磁盘存满后才会开始存放到下一个磁盘
4、RAID:各个磁盘中的数据写入是并行的,是通过数据条带技术写入的。其读写性能是JBOD的n倍
(3)、RAID1
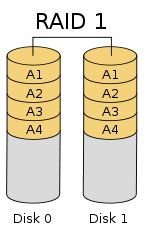
-
RAID1 就是一种镜像技术,它将数据完全一致地分别写到工作磁盘和镜像磁盘,它的磁盘空间利用率为 50% 。 RAID1 在数据写入时,响应时间会有所影响,但是读数据的时候没有影响。 RAID1 提供了最佳的数据保护,一旦工作磁盘发生故障,系统将自动切换到镜像磁盘,不会影响使用。
-
RAID1是为了增强数据安全性使两块磁盘数据呈现完全镜像,从而达到安全性好、技术简单、管理方便。 RAID1 拥有完全容错的能力,但实现成本高。
应用场景:
对顺序读写性能要求较高,或对数据安全性要求较高的场景。
(4)、RAID10
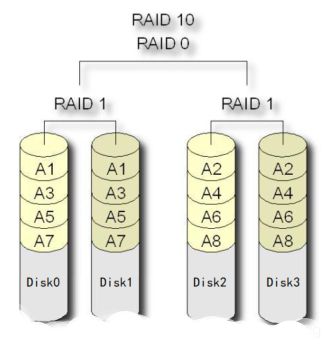
-
RAID10是一个RAID1与RAID0的组合体,所以
它继承了RAID0的快速和RAID1的安全。 -
简单来说就是,
先做条带,再做镜像。先把进来的数据先分散到不同的磁盘,再将磁盘中的数据做镜像。
(5)、RAID01
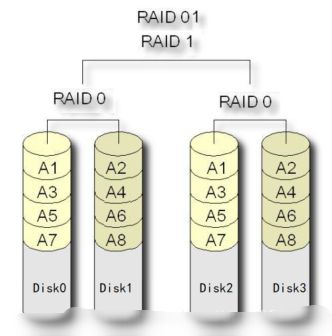
-
RAID01是一个RAID0与RAID1的组合体,所以
它继承了RAID0的快速和RAID1的安全。 -
简单来说就是,
先做镜像,再做条带。先把进来的数据先做镜像,再将镜像数据写入到与之前数据不同的磁盘,即再做条带。
对比RAID10容错率会高,生产环境一般选择RAID10