首先放上项目地址,喜欢的话就star一个吧
GitHub: markdown365-parser
预览地址: Demo
react的发布让前端摆脱了使用jQuery一点一点修改DOM的历史。对于后来的很多框架都产生非常重要的影响。其中最为重要的概念就是Virtual DOM了,在后面vue也借鉴了这一概念,不过这两个框架对Virtual DOM的实现是不一样的。
作为一个搬砖的,肯定是离不开markdwon的,markdwon能够用很简洁的语法表现出很好的排版样式。所以也就关注了一些markdwon的解析器,闲来无事,就有了自己造一个轮子的想法。在GitHub上找了几个比较流行的markdwon解析的库之后选择了marked来研究,选择marked的原因主要是从代码量和支持语法两个方面考虑的,由于自己单枪匹马的干,所以选用的库不能太大了(我怕搞不定),marked的源码只有1000多行,而且代码结构还是比较清晰的,整个扒下来也就定义了三个类,分别是Lexer(块级语法解析)、InlineLexer(行内语法解析)和Renderer(渲染成html字符串),这里就不过多说明marked了,其中我借鉴了Lexer和InlineLexer两个类的实现。

嗯,好了,下面开始正式安利
支持语法
项目已经支持了比较常用的一些语法,具体请查看Grammar.md
使用示例如下
markdown365-parser
参数说明
gfm: GitHub flavored markdown语法支持. 默认:
truetables: GFM tables语法支持. 必须要求
gfm为true. 默认:truebreaks: GFM line breaks解析规则支持. 必须要求
gfm为true. 默认:falsepedantic: 是否尽可能遵守
markdown.pl的部分内容. 不去掉一些不严格的内容. 默认:falsesmartypants: 是否替换特殊符号. 默认:
falsebase:这里是用来指定markdwon文档中的链接地址、图片地址的前置链接,如markdown中的说有图片都指向另一个域的时候,base就可以设置为指定域名。这里这个参数主要时考虑到编写桌面markdown编辑器用的,因为编辑器打开markdown文件时,对应的图片的路径要转换为相对markdown文件所在目录的相对路径,具体可参考我的另一个项目markdown365
$el:文档要渲染到的dom节点
源码目录结构
src
│ index.js # 入口文件 Parser类
│ utils.js # 工具代码
│
├─lexer # markdown解析相关代码 把字符串解析为vnode
│ block-lexer.js # 块级语法解析 BlockLexer类
│ block-rules.js # 块级语法解析规则
│ index.js # Lexer类
│ inline-lexer.js # 行内语法解析 InlineLexer类
│ inline-rules.js # 行内语法解析规则
│
├─renderer # 渲染类 把vnode diff并渲染到真实dom中
│ index.js # Renderer类
│
└─vnode # vnode定义代码
index.js # 传入节点信息返回vnode
vnode.js # Vnode类
Markdwon解析流程介绍
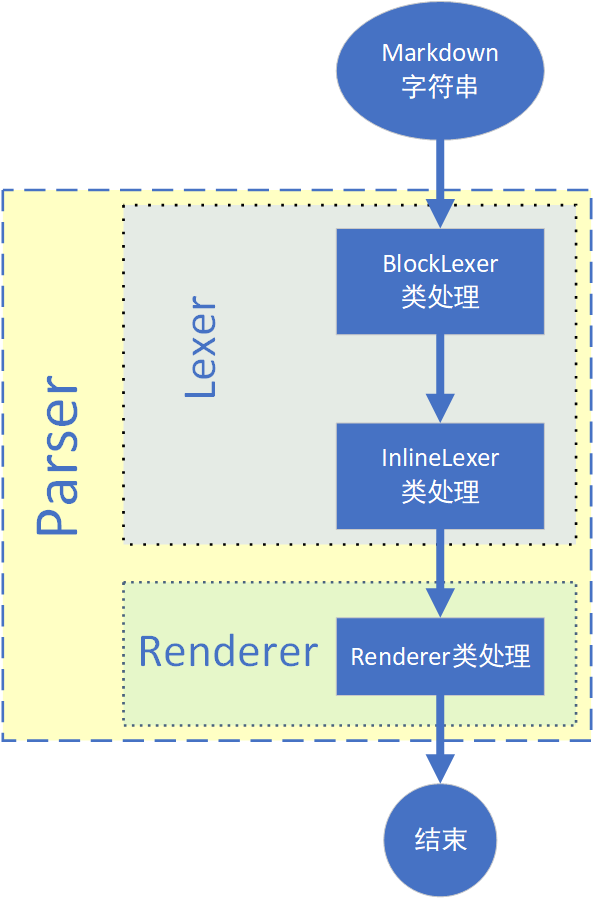
下面分别介绍每一个类的作用
- Parser类:Parser类初始化后就可以调用parse方法,然后就开始执行lex和render
import Lexer from './lexer'
import Renderer from './renderer'
import h from './vnode'
export default class Parser {
/**
* 挂载类的静态方法,使得可直接调用Parser.parse
*/
static parse (src, options) {
const parser = new Parser(options)
return parser.parse(src)
}
/**
* 初始化Parser类
* @param {Object} options
*/
constructor (options) {
this.options = options
// 初始化Lexer
this.lexer = new Lexer(this.options)
// 初始化Renderer
this.renderer = new Renderer(this.options)
// 初始化vnode
this.vnode = h({
$el: $el,
tag: $el.tagName.toLowerCase(),
type: 'node',
children: []
})
}
/**
* 解析源码并渲染到dom
* @param {String} src
* @return {Parser} this
*/
parse (src) {
/**
* 必须创建新的vnode
* 创建的vnode将和this.vnode进行对比
* 否则render diff的时候就会失败
* h为创建vnode的方法
*/
const vnode = h({
$el: this.vnode.$el,
tag: this.vnode.tag,
type: 'node',
children: this.lex(src)
})
this.render(vnode)
this.vnode = vnode
return this.vnode
}
/**
* 把源码解析为vnode
* @param {String} src
* @return {Vnode}
*/
lex (src) {
return this.lexer.lex(src)
}
/**
* 把Vnode渲染到dom
* @param {Vnode} vnode
*/
render (vnode) {
this.renderer.patch(vnode, this.vnode)
}
}
- Lexer类:Lexer包含BlockLexer和InlineLexer两个部分,分别用来解析块级语法和行内语法,其中比较重点的是lexInline方法,该方法中会遍历解析块级语法解析后的vnode对象,如果vnode对象的source存在就要解析,并且由于块级节点解析后的会存在text类型的未解析的节点,即text类型的节点中还可以解析出一些语法。例如:一段文字中还包含链接或者斜体等,这些都是属于行内解析的范畴,但我们知道text类型的节点是不存在子接点的,所以解析出来的vnode对象不能挂载到原text节点的子节点上,所以就得把解析出来的节点挂载到原text节点的父节点上,并且对应的位置也不能错乱,详细见下面源码说明
import BlockLexer from './block-lexer'
import InlineLexer from './inline-lexer'
export default class Lexer {
/**
* Static Lex Method
*/
static lex (src, options) {
const lexer = new Lexer(options)
return lexer.lex(src)
}
/**
* 初始化Lexer类
* @param {Object} options
*/
constructor ({
gfm = true,
tables = true,
pedantic = false,
breaks = false,
smartypants = false,
base = ''
} = {}) {
this.options = {
gfm,
tables,
breaks,
pedantic,
smartypants,
base
}
// 初始化块级语法解析
this.blockLexer = new BlockLexer(this.options)
// 初始化行内语法解析
this.inlineLexer = new InlineLexer(this.options)
// 定义vnode
this.vnode = []
}
/**
* 把源码解析为vnode
* @param {String} src
* @return {Vnode}
*/
lex (src) {
const { vnode, links } = this.lexBlock(src)
// 设置参考式的链接或者图片
this.inlineLexer.setLinks(links)
this.vnode = this.lexInline(vnode)
return this.vnode
}
/**
* 解析源码的块级语法
* @param {String} src
* @return {Vnode}
*/
lexBlock (src) {
return this.blockLexer.parser(src)
}
/**
* 解析经过块级语法解析的vnode对象
* 解析对象中未被解析的行内语法
* @param {Vnode} vnodes
* @return {Vnode}
*/
lexInline (vnodes) {
let i = 0
let vnode = vnodes[i]
while (vnode) {
// 需要进行行内解析的情况
if (vnode.source) {
if (vnode.type === 'text') { // 为text的时候
// 此处说明请参考后面的行内解析说明
// 把text从text node移动到text node的父节点上
const children = this.inlineLexer.parser(vnode)
// 记录原来位置的元素下标
let oi = i
// 把节点加入到父节点中对应的位置(相同下标处)
while (children.length) {
const vn = children.shift()
/**
* 合并text节点
* 如果前一个是text,并且当前vn也是text
* 就合并成一段文字,减少节点个数
*/
if (oi !== i && vnodes[i].type === 'text' && vn.type === 'text') {
vnodes[i].text += vn.text
} else {
vn.parent = vnode.parent
// 在原来的位置后面插入新的值
vnodes.splice(++i, 0, vn)
}
}
// 从父节点上移除被解析的节点,该节点已经被解析为其他的节点替代了
i--
vnodes.splice(oi, 1)
} else { // 为node或者html类型的时候
vnode.children = this.inlineLexer.parser(vnode)
.map(item => {
item.parent = vnode
return item
})
}
vnode.source = null
} else {
this.lexInline(vnode.children)
}
i++
vnode = vnodes[i]
}
return vnodes
}
}
行内解析说明,如下代码只进行说明,实际情况子节点还有parent属性,该属性指向父节点
- 进行行内解析前
const vnode = {
uid: 0,
$el: null,
tag: 'li',
type: 'node',
parent: null,
attributes: {},
text: '',
source: null,
children: [
{
uid: 1,
$el: null,
tag: null,
type: 'text',
children: [],
attributes: {},
text: '',
source: '[x] [google](https://www.google.com/)'
}
]
}
- 行内解析后应为
const vnode = {
uid: 0,
$el: null,
tag: 'li',
type: 'node',
parent: null,
attributes: {},
text: '',
source: null,
children: [
{
uid: 1,
$el: null,
tag: 'input',
type: 'node',
attributes: {
checked: 'checked',
disabled: 'disabled',
type: 'checkbox'
},
text: '',
source: null,
children: []
},
{
uid: 2,
$el: null,
tag: 'a',
type: 'node',
attributes: {
href: 'https://www.google.com/'
},
text: '',
source: null,
children: [
{
uid: 3,
$el: null,
tag: null,
type: 'text',
attributes: {},
text: 'google',
source: null,
children: []
}
]
}
]
}
- BlockLexer类:BlockLexer类最主要的方法是lex,该方法是正真语法解析部分,在方法内部使用while循环,直到src被解析完才返回vnode,并且里面的每一个解析规则的顺序是不能随意更换的,因为规则之间会存在相互包含的关系,例如一个h1语法段落肯定是可以被解析为p标签的,所以这就要求h1的解析规则放在p标签规则解析的前面,如果不能匹配才会匹配为p标签。其次,对与lex的另两个参数的作用,top参数主要是为了区分一段文字是解析为p标签还是解析为text类型的节点,如果没有父节点就解析为p标签,反之则为text节点。bq参数用来区分是否为blockquote标签下的内容,在blockquote便签下的内容不会被解析到参考式的链接中去,其实也就是参考式的链接只能写在顶级,否则不会生效
import block from './block-rules'
import h from '../vnode'
import { isDef } from '../utils'
/**
* Block Lexer
*/
export default class BlockLexer {
static rules = block
/**
* Static Lex Method
*/
static lex (src, options) {
const blockLexer = new BlockLexer(options)
return blockLexer.parser(src)
}
/**
* 初始化类
* @param {Object} options
*/
constructor ({
gfm = true,
tables = true,
pedantic = false,
base = ''
} = {}) {
this.options = {
gfm,
tables,
pedantic,
base
}
// 初始化解析规则
this.rules = block.normal
// 初始化参考式的链接或图片存储的对象
this.links = {}
// 初始化vnode
this.vnode = []
if (this.options.gfm) {
if (this.options.tables) {
this.rules = block.tables
} else {
this.rules = block.gfm
}
}
}
/**
* 解析源码
* @param {String} src
* @return {Object} vnode links
*/
parser (src) {
src = src
.replace(/\r\n|\r/g, '\n')
.replace(/\t/g, ' ')
.replace(/\u00a0/g, ' ')
.replace(/\u2424/g, '\n')
this.vnode = this.lex(src, true)
return {
vnode: this.vnode,
links: this.links
}
}
/**
* 解析源码
* @param {String} src
* @param {Boolean} top 是否是顶级的标签
* @param {Boolean} bq 是否为blockquote便签中的元素
* @return {Vnode}
*/
lex (src, top, bq) {
src = src.replace(/^ +$/gm, '')
const vnodes = []
let token
let vnode
while (src) {
/**
* 解析各种块级语法规则
* src = src - 被解析的部分
* 直到src = ''才停止解析
*/
if (src) {
throw new Error('Infinite loop on byte: ' + src.charCodeAt(0))
}
}
return vnodes
}
/**
* 解析table
* @param {Array} thead 表头每一列
* @param {Array} tbody 表格每一行
* @param {Array} align 表格每一列对齐方式
* @return {Vnode}
*/
lexTable (thead, tbody, align) {
return h({
tag: 'table',
children: [
h({
tag: 'thead',
children: thead.map((th, index) => /** 表头部分 */)
}),
h({
tag: 'tbody',
children: tbody.map(tr => /** 表格主体部分 */)
})
]
})
}
}
- InlineLexer类:InlineLexer中主要的方法是lex,lex有两个参数,其中src为带解析的源码字符串,parent为的当前解析text的父元素,该参数主要用来判断tasklink,要进入tasklink解析条件,必须要在父元素为li才行,否则不会解析为tasklist
import inline from './inline-rules'
import { isDef, transformURL } from '../utils'
import h from '../vnode'
/**
* Inline Lexer & Compiler
*/
export default class InlineLexer {
static vision = process.env.VERSION
static rules = inline
/**
* Static Lexing/Compiling Method
*/
static lex (vnode, links, options) {
let inlineLexer = new InlineLexer(options, links)
return inlineLexer.parser(vnode)
}
/**
* 初始化类
* @param {Object} options
* @param {Object} links
*/
constructor ({
gfm = true,
pedantic = false,
breaks = false,
smartypants = false,
base = ''
} = {}, links = {}) {
this.options = {
gfm,
pedantic,
breaks,
smartypants,
base
}
this.rules = inline.normal
if (this.options.gfm) {
if (this.options.breaks) {
this.rules = inline.breaks
} else {
this.rules = inline.gfm
}
} else if (this.options.pedantic) {
this.rules = inline.pedantic
}
this.setLinks(links)
}
/**
* 设置参考式的链接对象集合
* @param {Object} links
*/
setLinks (links) {
if (typeof links !== 'object') {
throw new TypeError('`links` isn\'t a object.')
}
this.links = links
}
/**
* 解析行内内容
* @param {Vnode} vnode
*/
parser (vnode) {
return this.lex(vnode.source, vnode.parent)
}
/**
* Lexing/Compiling
* @param {String} src
* @param {Vnode} parent
*/
lex (src, parent = null) {
let vnodes = []
let link,
text,
href,
token
let vnode
while (src) {
/**
* 解析各种行内语法规则
* src = src - 被解析的部分
* 直到src = ''才停止解析
*/
if (src) {
throw new Error('Infinite loop on byte: ' + src.charCodeAt(0))
}
}
return vnodes
}
/**
* 生成链接
* @param {String} cap 链接中子节点源码
* @param {Object} link 链接对象
* @returns {Vnode}
*/
lexLink (cap, link) {}
/**
* Smartypants Transformations
* @param {String} text
* @return {String}
*/
smartypants (text) {
/**
* 转义一些内容
*/
}
}
- Vnode类:
- vnode类
export default class VNode {
static uid = 0 // 每次创建一个vnode就会加一,这是每个vnode的唯一标识
constructor ({
$el = null,
tag = null,
type = 'node', // 可为node/text/html
parent = null,
children = [],
attributes = {},
text = null,
source = null
} = {}) {
this.uid = VNode.uid++
this.$el = $el
this.tag = tag
this.type = type
this.parent = parent
this.children = children
this.attributes = attributes
this.text = text
this.source = source
}
}
- h函数:快速创建vnode的方法
import VNode from './vnode'
export default ({
$el = null,
tag = null,
type = 'node',
parent = null,
children = [],
attributes = {},
text = '',
source = null
} = {}) => {
const vnode = new VNode({
$el,
tag,
type,
parent,
children,
attributes,
text,
source
})
// 每个子节点都把parent指向当前节点vnode
vnode.children.forEach(item => {
item.parent = vnode
})
return vnode
}
- Renderer类:Renderer类参考了vue中的render实现方法,其中主要是在对比的时候就对真实dom进行修改,当patch结束dom更新也就结束了
export default class Renderer {
static vision = process.env.VERSION
/**
* Static render Method
*/
static render (vnode, oldVnode) {
const renderer = new Renderer()
return renderer.patch(vnode, oldVnode)
}
/**
* 比较新旧两个节点
* 并更新到dom
* @param {Vnode} vnode
* @param {Vnode} oldVnode
*/
patch (vnode, oldVnode) {}
/**
* 对比新旧节点属性
* @param {Vnode} vnode
* @param {Vnode} oldVnode
*/
patchAttributes (vnode, oldVnode) {}
/**
* 对比子新旧节点的子节点列表
* @param {Array} newCh
* @param {Array} oldCh
*/
patchChildren (newCh = [], oldCh = []) {}
/**
* 创建新dom元素
* 并赋值给vnode.$el
* @param {Vnode} vnode
* @return {Vnode}
*/
create (vnode) {}
/**
* 追加节点
* @param {Vnode} parent
* @param {Vnode} vnode
*/
append (parent, vnode) {}
/**
* 在指定节点前插入节点
* @param {Vnode} parent
* @param {Vnode} vnode
* @param {Vnode} before
*/
insert (parent, vnode, before) {}
/**
* 移除节点
* @param {Vnode} vnode
*/
removeEl (vnode) {}
/**
* 替换旧节点为新的节点
* @param {Vnode} parent
* @param {Vnode} vnode
* @param {Vnode} oldVnode
*/
replace (parent, vnode, oldVnode) {}
}
diff原理说明
diff原理基本和vue的思路一致,只是在vue diff的基础上做了简化和修改。这里可以打开源码对比着看,同时这里也推荐一篇对于vue diff源码解析的文章Vue原理解析之Virtual Dom
-
单个节点进行比较
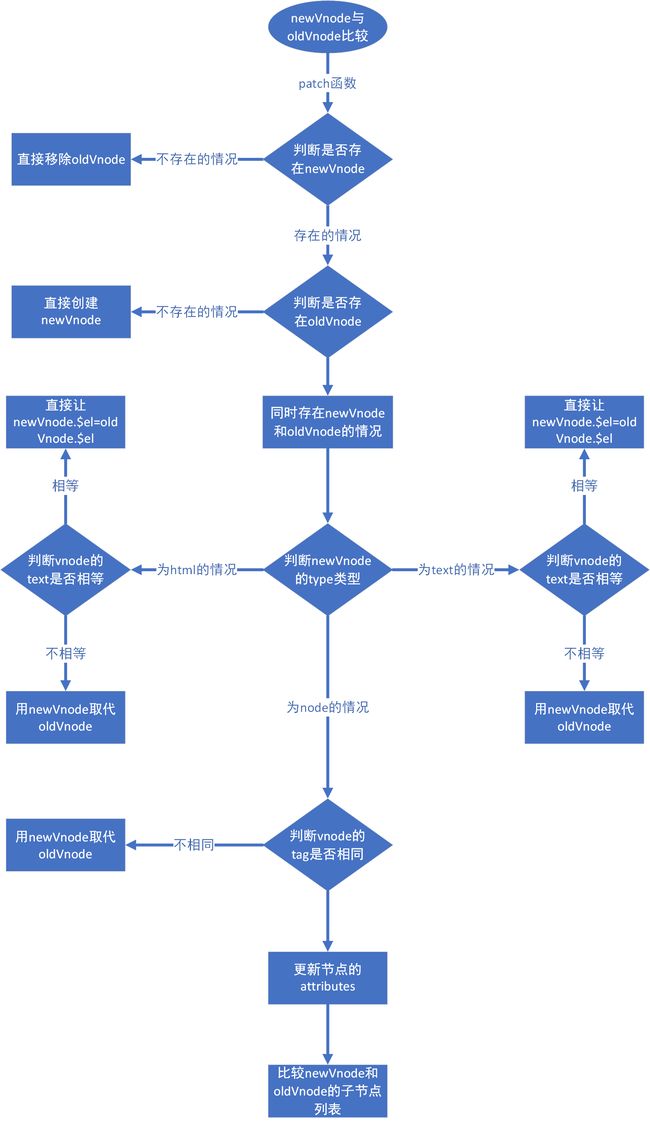 diff原理
diff原理 - 子节点列表diff,子节点相对于单个节点的对比就复杂很多了,会存在列表中添加节点、删除节点、节点位置移动、某一个节点被替换这几种基本情况。这里先放上
patchChildren方法的源码。
/**
* 对比子新旧节点的子节点列表
* @param {Array} newCh
* @param {Array} oldCh
*/
patchChildren (newCh = [], oldCh = []) {
let oldStartIdx = 0 // 记录旧节点数组中的开始下标
let newStartIdx = 0 // 记录新节点数组中的开始下标
let oldEndIdx = oldCh.length - 1 // 记录旧节点冲末尾向前匹配的位置下标
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
// 循环节点列表,直到新列表和旧列表的每一个一个节点都被比较完
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode.tag === newStartVnode.tag) {
this.patch(newStartVnode, oldStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (oldEndVnode.tag === newEndVnode.tag) {
this.patch(newEndVnode, oldEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (oldStartVnode.tag === newEndVnode.tag) { // Vnode moved right
this.patch(newEndVnode, oldStartVnode)
this.insert(oldEndVnode.parent, oldStartVnode, oldCh[oldEndIdx + 1])
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (oldEndVnode.tag === newStartVnode.tag) { // Vnode moved left
this.patch(newStartVnode, oldEndVnode)
// 把旧节点真实dom移动到newEndVnode的位置
this.insert(oldStartVnode.parent, oldEndVnode, oldStartVnode)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 这种情况就是一个节点变成了另一个节点的情况
this.replace(newStartVnode.parent, this.create(newStartVnode), oldStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}
}
// 以下情况为节点增加或者减少了的情况
if (oldStartIdx > oldEndIdx) {
// 插入新节点的情况
for (; newStartIdx <= newEndIdx; ++newStartIdx) {
this.insert(newCh[newStartIdx].parent, this.create(newCh[newStartIdx]), newCh[newEndIdx + 1])
}
} else if (newStartIdx > newEndIdx) {
// 移除就无用的旧节点
for (; oldStartIdx <= oldEndIdx; ++oldStartIdx) {
this.removeEl(oldCh[oldStartIdx])
}
}
}
下面分别对while循环中的每一个条件进行说明
- 如果
oldStartVnode.tag === newStartVnode.tag,那么旧认为这两个节点是匹配的,即认为为相同节点,直接对比更新这两个节点,如:在末尾追加节点这种情况或者节点子元素变化
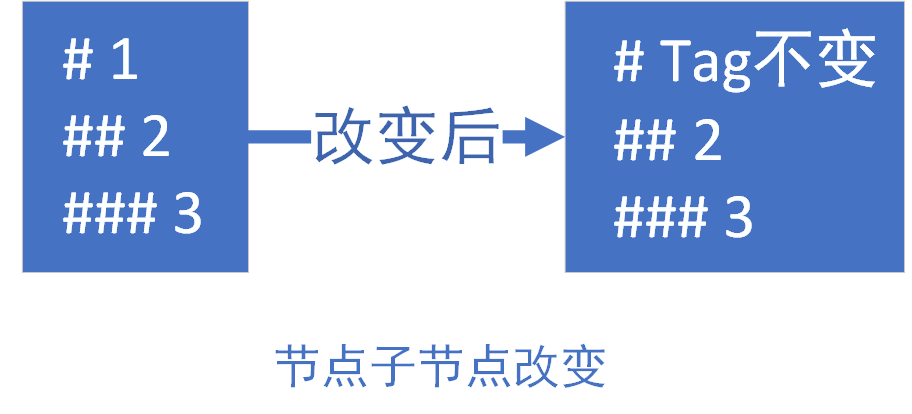 1.png
1.png - 如果
oldEndVnode.tag === newEndVnode.tag,那么就用新的节点去更新旧节点,如:第一个节点变为了其他类型的节点
 2.png
2.png - 如果
oldStartVnode.tag === newEndVnode.tag,那么就对比这两个节点,并且将真实dom节点移动到newEndVnode.tag所在的位置
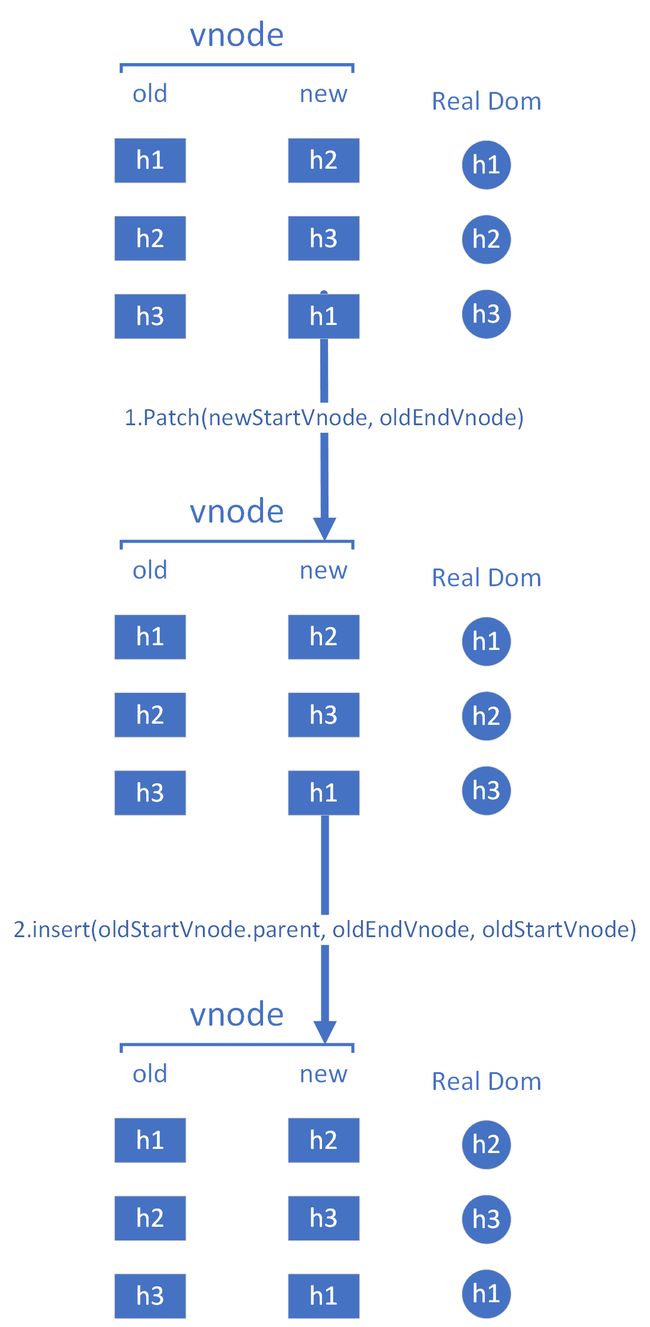 3.png
3.png -
oldEndVnode.tag === newStartVnode.tag的情况基本和3一样,只是移动节点的位置要反过来,这里就不放图了 - 如果以上几种情况都不能满足的话,就让节点
newStartVnode取代oldStartVnode
循环结束之后的条件判断 - 如果
oldStartIdx > oldEndIdx,比如在末尾追加节点的情况,这是就需要插入新节点
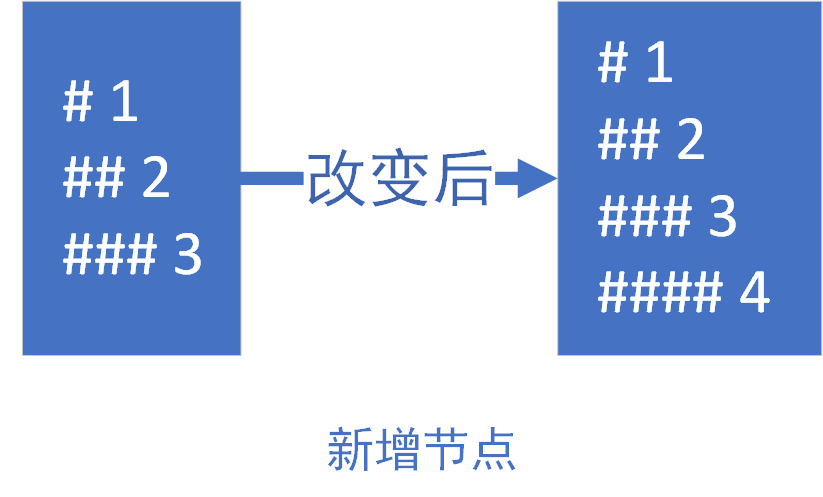 4.png
4.png - 如果
newStartIdx > newEndIdx,这种情况可以用移除节点来做类比,所以就需要移除旧的多余的节点
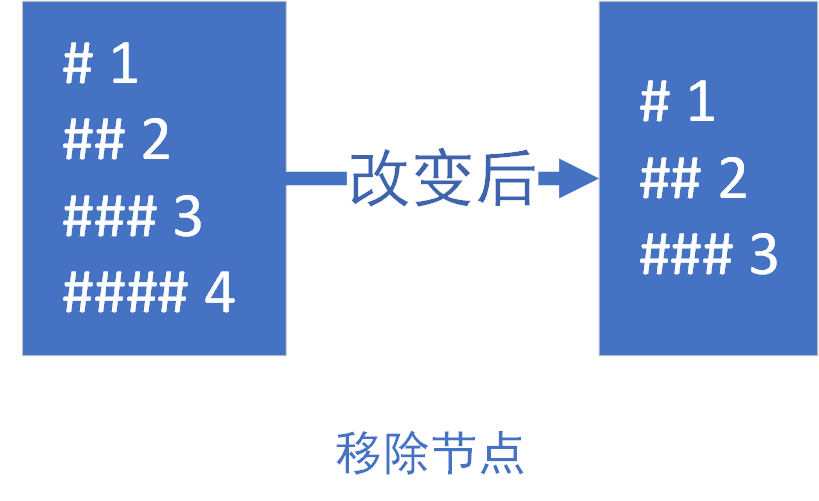 5.png
5.png
对于整个render的diff来说,整体的效率还是很低,还不完善,特别是对于子节点列表对比的方法,还有很大的优化空间
最后
项目目前很多功能还不是很完善,对于markdwon的解析也只是做了比较基础的支持,还有一部分语法没有能够支持,特别是对于html的支持还存在BUG,并且目前对于语法如何扩展也还存在问题,当前的代码结构不易于扩展语法。对于diff部分也还有很多需要改进的地方。所以如果有兴趣,欢迎提交pr。
能力有限,所以以上内容有很多不详细的地方,也可能存在错误,还请热心的同学帮忙指正。