
前情提要:
- 概述
- Julia是一门牛B、‘无耻’的语言
- 本地环境教程
- Julia1.0.0安装指南(含 Juno IDE)
- Windows教程
- Mac教程
- 目前兼容的机器学习程序包
- Julia1.0.0安装指南(含 Juno IDE)
- 在线环境教程
- 无痛体验:几行代码识别图片内容
- 如何进行Julia无痛体验
- 深度定制免费无痛环境
- 如何科学的找程序包
前段时间把环境和各种版本情况理了一遍,应该说该有的学习基础设施都有了。
笔者关注的是机器学习方面的,因此会侧重去看这些方面的资料。
说到机器学习,首先得要有数据,不然学习个啥呢。有了数据之后,那么很多语言的第一步就是处理数据。Julia也一样,有专门的数据处理程序包。
今天就说一下DataFrames这个程序包。用过其他机器学习语言的都知道,DataFrames就是数据框,中文直译。
笔者自己学习程序语言的方式是不喜欢去看书的(程序书是用来查的),程序一定是一边写一边看一边用才会掌握的好和快,尤其是看牛人写的程序。
记得前面有教程说过如何导入Github上的程序库吧。
来,先记得这个地址:https://github.com/scidom/StatsLearningByExample.jl.git
然后点开Juliabox上Git 这个按钮

会出来一个对话框:
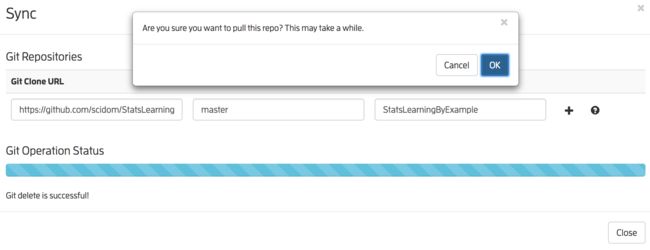
粘贴刚才那个地址到 Git Clone URL框里,然后点后面的+号(如果需要修改一下同步到Juliabox的文件夹名字的请按+号前修改)。然后按下[OK]。
很快Juliabox就会把https://github.com/scidom/StatsLearningByExample.jl.git里的内容同步过来。
然后你的Juliabox就会多出来这个文件夹(StatsLearningByExample):
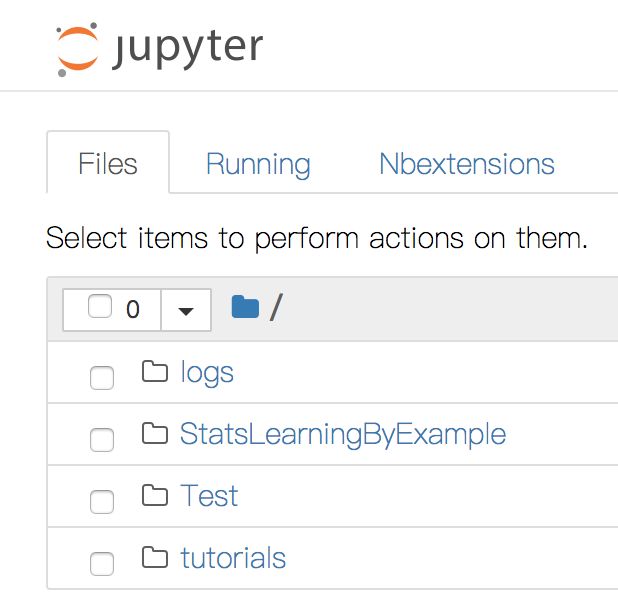
接下来点进去02-DataFrames目录:

点开第一个02-01-DataFramesBasics.ipynb,
然后点Cell下面的Run All:
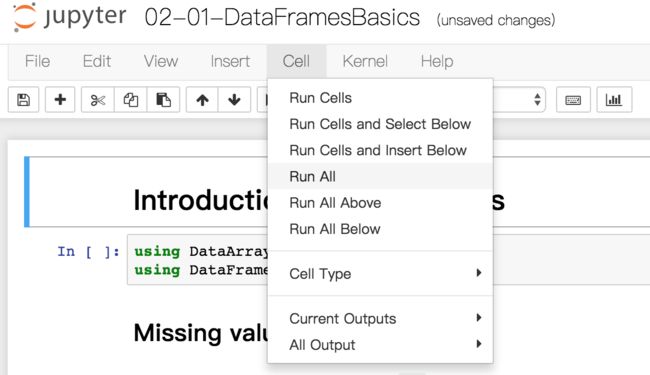
这个命令就会把所有的代码跑一遍。
这个就是今天的课程,因为已经有代码且作者已经用英文讲解了,所以接下来会倒序(按照程序代码来说是倒序)重点总结一下:
(文末有笔者运行结果,方便暂时不能操作的同学看):
-
DataFrames是由DataArrays组成的
- DataFrames本身的基本信息获取
- 可以对DataFrames内数据进行简单统计描述
- 可以获得DataFrames某行/某列数据
DataArrays可以进行矩阵运算
-
DataArrays里有个特殊成员NA(缺失值)
所有数值和NA进行运算结果都是NA
NA(缺失值)和NaN(Not a Number: 不是数字)是两个东西,数值类型也不一样
有几个注意的地方:
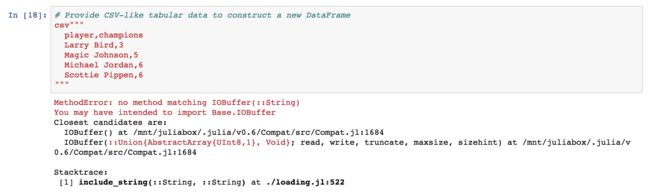
这个地方其实应该是文档的注释部分,作者应该没注意弄,变成代码运行报错了。
改成文档格式即可,忽略也可以。
还有这里:

第8句写了不可能通过DataArray([0.1, NA, -2.4])语句直接完成DataArray构建,这里应该是个错误示范(应该报错)。
作者希望提示大家用第9句的语法来完成构建动作。
实际上,作者写的是2年前,现在我们看到的是两种语法都得出了正确结果。也就是目前两种写法都可以。
其他的就不多解释了,大家要学习应该能看懂。
以下是笔者运行的结果,供参考:
Introduction to DataFrames
In [1]:
using DataArrays
using DataFrames
Missing values¶
- A missing value is represented by
NAin Julia. -
NAis not part of Base, it is provided by theDataArrayspackage. -
NApoisons other values.
In [2]:
# NA poisons other values
1+NA
Out[2]:
missing
In [3]:
# Check if the evaluation of an expression results in NA
isna(1+NA)
Out[3]:
true
In [4]:
# Note the difference between NaN and NA
(isa(NaN, Float64), isa(NA, Float64))
Out[4]:
(true, false)
DataArrays
-
DataArray's are used for representing arrays that contain missing values -
DataArray{T}allows storingTorNA - In other words,
DataArray{T}addsNA's toArray{T} -
PooledDataArray{T}is used for storing data efficiently. -
PooledDataArray{T}compressesDataArray{T}.
Constructing DataArrays
In [5]:
# Call the DataArray() constructor by passing a Vector to it
DataArray([0.1, 0.5, -2.4])
Out[5]:
3-element DataArrays.DataArray{Float64,1}:
0.1
0.5
-2.4
In [6]:
# Construct a DataArray by calling the @data() macro with a Vector input argument
@data([0.1, 0.5, -2.4])
Out[6]:
3-element DataArrays.DataArray{Float64,1}:
0.1
0.5
-2.4
In [7]:
# Convert Vector to DataArray
convert(DataArray, [0.1, 0.5, -2.4])
Out[7]:
3-element DataArrays.DataArray{Float64,1}:
0.1
0.5
-2.4
In [8]:
# It is not possible to call DataArray() with NA in its input argument
DataArray([0.1, NA, -2.4])
Out[8]:
3-element DataArrays.DataArray{Float64,1}:
0.1
missing
-2.4
In [9]:
# However, it is possible to pass NA to the @data() macro
@data([0.1, NA, -2.4])
Out[9]:
3-element DataArrays.DataArray{Float64,1}:
0.1
missing
-2.4
In [10]:
# The DataArray() constructor can be called with a Matrix input argument
DataArray([0.4 1.2; 3.5 7.2])
Out[10]:
2×2 DataArrays.DataArray{Float64,2}:
0.4 1.2
3.5 7.2
In [11]:
# The @data() macro can also be called with a Matrix input argument
@data([0.4 1.2; 3.5 7.2])
Out[11]:
2×2 DataArrays.DataArray{Float64,2}:
0.4 1.2
3.5 7.2
In [12]:
# Convert a Matrix to DataArray
convert(DataArray, [0.4 1.2; 3.5 7.2])
Out[12]:
2×2 DataArrays.DataArray{Float64,2}:
0.4 1.2
3.5 7.2
Numerical computing with DataArrays
In [13]:
# Numerical computing can be done with data vectors
x = @data([0.1, NA, -2.4])
y = @data([-9.9, 0.5, 6.7])
x+y
Out[13]:
3-element DataArrays.DataArray{Float64,1}:
-9.8
missing
4.3
In [14]:
# To remove missing values (NA), call dropna()
x = @data([0.1, NA, -2.4])
dropna(x)
Out[14]:
2-element Array{Float64,1}:
0.1
-2.4
In [15]:
# Numerical computing can be done with data matrices and data vectors
A = @data([0.4 1.2 4.4; NA 7.2 3.9; 5.1 1.8 4.5])
y = @data([-9.9, 0.5, 6.7])
A*y
Out[15]:
3-element DataArrays.DataArray{Float64,1}:
26.12
missing
-19.44
DataFrames
-
DataFrame's are used for representing data tables. - A
DataFrameis a list ofDataArray's. - So every
DataArrayof aDataFramerepresents a column of the corresponding data table. -
DataFrame's accommodate heterogeneous data that might contain missing values. - Every column (
DataArray) of aDataFramehas its own type.
Example 02-01-01: NBA champions
Constructing DataFrames
In [16]:
# Call the DataFrame() constructor with keyword arguments (columns) of type Vector
DataFrame(
player = ["Larry Bird", "Magic Johnson", "Michael Jordan", "Scottie Pippen"],
champions = [3, 5, 6, 6]
)
Out[16]:
| player | champions | |
|---|---|---|
| 1 | Larry Bird | 3 |
| 2 | Magic Johnson | 5 |
| 3 | Michael Jordan | 6 |
| 4 | Scottie Pippen | 6 |
In [17]:
# Start with an empty DataFrame and populate it
ChampionsFrame = DataFrame()
ChampionsFrame[:player] = ["Larry Bird", "Magic Johnson", "Michael Jordan", "Scottie Pippen"]
ChampionsFrame[:champions] = [3, 5, 6, 6]
ChampionsFrame
Out[17]:
| player | champions | |
|---|---|---|
| 1 | Larry Bird | 3 |
| 2 | Magic Johnson | 5 |
| 3 | Michael Jordan | 6 |
| 4 | Scottie Pippen | 6 |
Provide CSV-like tabular data to construct a new DataFrame
In [19]:
# Call the DataFrame() constructor with keyword arguments (columns) of type DataArray
player = @data(["Larry Bird", "Magic Johnson", "Michael Jordan", "Scottie Pippen"])
champions = @data([3, 5, 6, 6])
ChampionsFrame = DataFrame(player=player, champions=champions)
Out[19]:
| player | champions | |
|---|---|---|
| 1 | Larry Bird | 3 |
| 2 | Magic Johnson | 5 |
| 3 | Michael Jordan | 6 |
| 4 | Scottie Pippen | 6 |
In [20]:
# Construct a DataFrame by joining two existing DataFrames
height = [2.06, 2.06, 1.98, 2.03]
HeightsFrame = DataFrame(player=player, height=height)
join(ChampionsFrame, HeightsFrame, on = :player)
Out[20]:
| player | champions | height | |
|---|---|---|---|
| 1 | Larry Bird | 3 | 2.06 |
| 2 | Magic Johnson | 5 | 2.06 |
| 3 | Michael Jordan | 6 | 1.98 |
| 4 | Scottie Pippen | 6 | 2.03 |
Quering basic information about DataFrames
In [21]:
# Get number of rows of a DataFrame
size(ChampionsFrame, 1)
Out[21]:
4
In [22]:
# Get number of columns of a DataFrame
size(ChampionsFrame, 2)
Out[22]:
2
In [23]:
# Get a numeric summary of a DataFrame
describe(ChampionsFrame)
Out[23]:
| variable | mean | min | median | max | nunique | nmissing | eltype | |
|---|---|---|---|---|---|---|---|---|
| 1 | player | Larry Bird | Scottie Pippen | 4 | 0 | String | ||
| 2 | champions | 5.0 | 3 | 5.5 | 6 | 0 | Int64 |
Indexing DataFrames
In [24]:
# Index DataFrame by column name to get a specific column
ChampionsFrame[:player]
Out[24]:
4-element DataArrays.DataArray{String,1}:
"Larry Bird"
"Magic Johnson"
"Michael Jordan"
"Scottie Pippen"
In [25]:
# Index DataFrame by row numbers to get specific rows
ChampionsFrame[2:3, :]
Out[25]:
| player | champions | |
|---|---|---|
| 1 | Magic Johnson | 5 |
| 2 | Michael Jordan | 6 |
KevinZhang
Aug 30, 2018