知识图谱:【知识图谱问答KBQA(四)】——P-tuning V1
Abstract
虽然具有传统微调的 GPT 未能在自然语言理解 (NLU) 上取得很好的结果,但我们证明采用可训练的连续提示嵌入 P-Tuning 的GPT 在 NLU 任务上可以优于或可与类似大小的BERT相媲美。在知识探测 (LAMA) 基准测试中,最好的 GPT 在测试期间无需提供任何额外文本即可恢复 64% (P@1) 的世界知识,这大大提高了之前的最佳水平 20+ 个百分点。在 SuperGlue 基准测试中,GPT 在监督学习中实现了与类似大小的 BERT 相当甚至更好的性能。重要的是,我们发现 P-tuning 还提高了 BERT 在少样本和监督设置中的性能,同时大大减少了对prompt工程的需求。因此,Ptuning 在少量 SuperGlue 基准测试中的表现优于最先进的方法。
Introduction
语言模型预训练已成为许多自然语言处理任务的成功方法。 有证据表明,在预训练期间,语言模型不仅学习上下文化的文本表示,还学习语法、句法、常识甚至世界知识。根据训练目标,预训练语言模型可以分为三类:用于自然语言生成(NLG)的单向语言模型(例如,GPT)、用于自然语言理解(NLU)的双向语言模型(例如,BERT)和 用于结合前两种范式的混合语言模型(例如,XLNet、UniLM)。长期以来,研究人员观察到 GPT 风格的模型在具有微调的 NLU 任务中表现不佳,因此假设它们自然不适合语言理解。
新兴的 GPT-3 及其在使用手工提示的小样本和零样本学习方面的特殊表现席卷了机器学习社区,它的成功表明,使用适当的手动prompt的巨大单向语言模型可能适用于自然语言理解。然而,手工制作一个表现最好的prompt就像大海捞针,这通常需要不切实际的大型验证集,在许多情况下,Prompt工程实际上意味着过度拟合测试集,此外,也很容易创建导致性能大幅下降的对抗性提示。鉴于这些问题,最近的工作重点是自动搜索离散提示并证明了它们的有效性。 然而,由于神经网络本质上是连续的,离散提示可能是次优的。
在这项工作中,我们提出了一种新的方法 P-tuning 在连续空间中自动搜索prompt,以弥合 GPT 和 NLU 应用之间的差距。P-tuning 利用很少的连续自由参数作为提示,作为预训练语言模型的输入。 然后,我们使用梯度下降作为离散提示搜索的替代方法来优化连续提示。简单的 P-tuning 方法为 GPT 带来了实质性的改进。我们在两个 NLU 基准上检查基于 P-tuning 的 GPT:LAMA 知识探测和 SuperGLUE。结果表明GPT 在相同规模的 BERT 模型中表现出具有竞争力的性能,并且对于某些数据集,GPT 甚至优于 BERT。进一步的实验表明,BERT 式的模型在某种程度上也可以从 P-tuning 中受益。 我们展示了具有 P-tuning 的 ALBERT 大大优于以前的方法,并在少样本 SuperGLUE 基准上取得了新的最先进的结果。
我们的发现打破了 GPT 只能生成但无法理解的刻板印象。 它还表明,语言模型包含的世界知识和先前的任务知识比我们之前假设的要多得多。 P-tuning 还可以作为一种通用方法来调整预训练的语言模型以获得最佳的下游任务性能。 总而言之,我们做出以下贡献:
1)通过 P-tuning,GPT 在自然语言理解方面可以与 BERT 一样具有竞争力(有时甚至更好),这可以提高预训练语言模型的性能。 这表明 GPT 式架构在自然语言理解方面的潜力被低估了。
2)我们表明,P-tuning 是一种在少样本和全监督设置中改进 GPT 和 BERT 的通用方法。特别是,通过 P-tuning,我们的方法在 LAMA 知识探测和少样本 SuperGlue 方面优于最先进的方法,这表明语言模型在预训练期间掌握了比我们之前想象的更多的世界知识和先验任务知识。
Motivation
GPT-3 和 DALLE 的奇迹似乎表明,巨型模型始终是提升机器智能的灵丹妙药。 然而,繁荣的背后,也有不可忽视的挑战。一个致命的问题是巨型模型的可移植性很差。 下游任务的微调对于那些万亿规模的模型几乎不起作用。 即使对于多多样本(many-shot)微调设置,这些模型仍然太大而无法快速记住微调样本。作为替代,GPT-3 和 DALL-E 利用手工prompt来引导模型用于下游应用。然而,手工prompt搜索严重依赖于不切实际的大型验证集,且其性能也不稳定。
鉴于这一挑战,虽然最近的一些工作集中在通过挖掘训练语料库、梯度搜索和使用单独的模型来自动搜索离散提示,我们深入研究寻找可以差异优化的连续prompt的问题。
Method: P-tuning
在本节中,我们将介绍 P-tuning 的实现。 与离散提示类似,P-tuning 仅对输入应用非侵入性修改。 尽管如此,P-tuning 用其差分输出嵌入替换了预训练语言模型的输入嵌入。
1.Architecture
给定一个预训练的语言模型 M,一串离散输入标记 x1:n = {x0, x1, …, xn} 通过预训练的嵌入层 (e ∈ M)将被映射到输入嵌入 {e(x0), e(x1), … , e(xn)} 。在特定场景中,在特定场景中,以上下文 x 为条件,我们经常使用一组目标标记 y 的输出嵌入进行下游处理。例如,在预训练中,x 指的是未掩码的token,而 y 指的是 [MASK]; 而在句子分类中,x 指的是句子token,而 y 通常指的是 [CLS]。
prompt p 的作用是将上下文 x、目标 y 和自身组织成模板 T。例如,在预测一个国家首都的任务(LAMA-TREx P36)中,模板可能是“The capital of Britain is [MASK]”。 (见下图),其中“The capital of … is …”是prompt,“Britain”是上下文,“[MASK]”是目标。Prompts可以非常灵活,我们甚至可以将它们插入到上下文或目标中。

令 V 表示语言模型 M 的词汇表,[Pi] 表示模板 T 中的第 i 个 prompt token。为简单起见,给定模板 T = {[P0:i ], x, [Pi+1:m], y},与满足 [Pi] ∈ V 并将 T 映射到:
![]()
P-tuning 将 [Pi] 视为伪标记并将模板映射到:
![]()
其中 hi(0 ≤ i < m) 是使我们能够找到比 M 的原始词汇 V 可以表达的更好的连续prompt的可训练嵌入张量。最后,利用下游损失函数 L,我们可以通过以下方式差分优化连续提示 hi(0 ≤ i < m):

2.Optimization
虽然训练连续prompt的想法很简单,但在实践中,它面临两个优化挑战:
1)离散性:M的原始词嵌入e在预训练后已经变得高度离散。 如果 h 用随机分布初始化,然后用随机梯度下降 (SGD) 进行优化,已经证明只改变小邻域的参数,优化器很容易陷入局部最小值;
2)关联:另一个问题是,直觉上,我们认为提示嵌入 hi 的值应该相互依赖而不是独立。 我们需要一些机制来将提示嵌入相互关联。
鉴于面临的挑战,在 P-tuning 中,使用提示编码器将 hi 建模为一个序列,该编码器由一个非常精简的神经网络组成,可以解决离散性和关联问题。在实践中,选择双向长短期记忆网络 (LSTM),使用 ReLU 激活的两层多层感知器 (MLP) 来鼓励离散性。正式地说,语言模型 M 的真实输入嵌入 h’i 来自:

虽然 LSTM head 的使用确实为连续prompt的训练增加了一些参数,但 LSTM head 比预训练模型小几个数量级。此外,在推理中,我们只需要输出嵌入 h 并且可以丢弃 LSTM 头。
此外,我们还发现添加少量锚token有助于 SuperGLUE 基准测试中的一些 NLU 任务。例如,对于 RTE 任务,token“?” 在提示模板中“[PRE][prompt tokens][HYP]?[prompt tokens][MASK]”是专门添加的作为anchor token,对性
能影响很大。 通常这样的锚词表征每个组件,在这种情况下“?” 表示“[HYP]”充当询问部分。
Experiments
1.Knowledge Probing
知识探测,或称为事实检索,评估语言模型从预训练中获得的真实世界的知识有多少。LAMA 数据集使用从知识库中选择的三元组创建的完形填空测试对其进行评估,例如,我们将三元组(Dante,born-in,Florence)转化为带有手工提示“Dante was Born in [MASK].”的完形填空句,然后我们要求语言模型推断目标。因为我们想要评估从预训练中获得的知识,预训练的语言模型的参数是固定的(即未微调)。
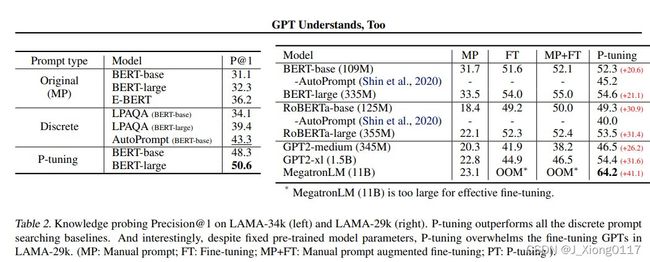
2.SuperGLUE


思维导图
