Java学习 day50_tomcat
服务器
静态web资源:一成不变的内容。不管任何人,或者说任何时刻看到的内容都是相同的
动态web资源:富有交互性,变化性。抖音的推荐、淘宝的首页商品推荐,登录
整个互联网的发展历程,也是从静态web资源发展到动态web资源的过程。
刷新页面,时时刻刻更新最新的时间 java Web动态服务器开发。
服务器:
深入去剖析,其实有两个层面
硬件层面:一台性能很高效的计算机
软件层面:一个软件,可以将本地的资源发布到网络上面去,供网络上面的其他用户来使用。
手动编写简易服务器(尽自己所能,掌握多少是多少)
1.需要持续去监听某个端口号,监听有无请求到来
2.当有请求到来时,我需要能够去解析出请求的意图,请求希望访问哪个资源文件,然后接下来将该文件给响应出去
package com.cskaoyan.server;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 新建一个服务器程序 ServerSocket
*/
public class MainServer {
public static void main(String[] args) {
try {
//创建了一个程序,监听着8090端口号
ServerSocket serverSocket = new ServerSocket(8090);
//该程序需要监听有没有程序发送请求过来,发送到当前机器的8090端口号
//这个socket就是连接进来的请求
//请求里面应当包含请求的信息,如何获取该部分信息呢?
//如果没有请求方连接进来,那么改行代码会一直阻塞等待
//你需要去做的事情,就是往当前机器的8090端口号发送请求
//可以发送任意类型的请求信息,也包含HTTP请求
Socket client = serverSocket.accept();
//获取请求方传递过来的数据,只需要将inputStream进行解析处理即可
//如果请求方发送的是文本请求信息,那么可以直接将该inputStream转成字符串
InputStream inputStream = client.getInputStream();
byte[] bytes = new byte[1024];
int length = inputStream.read(bytes);
String requestInfo = new String(bytes, 0, length);
System.out.println(requestInfo);
} catch (IOException e) {
e.printStackTrace();
}
}
}
当前版本有没有问题?
package com.cskaoyan.server;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 新建一个服务器程序 ServerSocket
*/
public class MainServer2 {
public static void main(String[] args) {
try {
//创建了一个程序,监听着8090端口号
ServerSocket serverSocket = new ServerSocket(8090);
//该程序需要监听有没有程序发送请求过来,发送到当前机器的8090端口号
//这个socket就是连接进来的请求
//请求里面应当包含请求的信息,如何获取该部分信息呢?
//如果没有请求方连接进来,那么改行代码会一直阻塞等待
//你需要去做的事情,就是往当前机器的8090端口号发送请求
//可以发送任意类型的请求信息,也包含HTTP请求
while (true){
//主线程只负责去持续不断监听客户端连接进来
Socket client = serverSocket.accept();
//获取请求方传递过来的数据,只需要将inputStream进行解析处理即可
//如果请求方发送的是文本请求信息,那么可以直接将该inputStream转成字符串
new Thread(new Runnable() {
@Override
public void run() {
InputStream inputStream = null;
try {
inputStream = client.getInputStream();
byte[] bytes = new byte[1024];
//这一步其实也是阻塞步骤,如果程序阻塞在read这步,那么如果有新的客户端连接进来,程序可以处理吗
//改进的方式就是使用多线程,如何新建一个新线程?
int length = inputStream.read(bytes);
String requestInfo = new String(bytes, 0, length);
System.out.println(requestInfo);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
改进版可以解决很多阻塞问题。
比如浏览器输入http://localhost:8090/1.html 或者 http://localhost:8090/2.html
逻辑应该是怎么样的?
服务器应当去响应1.html的内容或者2.html的内容,
如果有的话,应当把文件的内容显示出来
如果没有的话,应当返回404状态码
应当分别去响应
GET /1.html HTTP/1.1
Host: localhost:8090
Connection: keep-alive
sec-ch-ua: “Chromium”;v=“92”, " Not A;Brand";v=“99”, “Google Chrome”;v=“92”
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: Idea-31d5f4eb=af750744-2158-4f3c-bba9-e7eae63a38fd
GET /2.html HTTP/1.1
Host: localhost:8090
Connection: keep-alive
sec-ch-ua: “Chromium”;v=“92”, " Not A;Brand";v=“99”, “Google Chrome”;v=“92”
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: Idea-31d5f4eb=af750744-2158-4f3c-bba9-e7eae63a38fd
接下来需要去做什么事情?
拿到请求资源
根据请求资源,然后到本地硬盘上面去找该文件是否存在,如果存在,则将文件的内容响应出去;如果不存在,则响应404
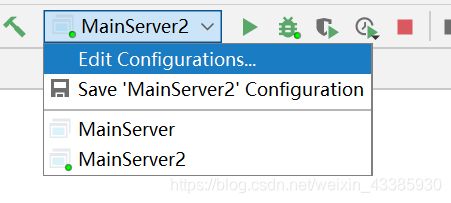
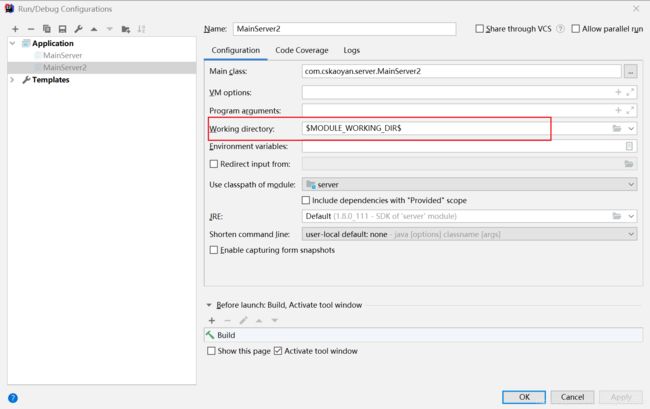
如果一个project下面设置了多个module,那么需要设置这么一个配置,如果不设置。那么工作目录指向的是project的目录,而不是当前module 的目录
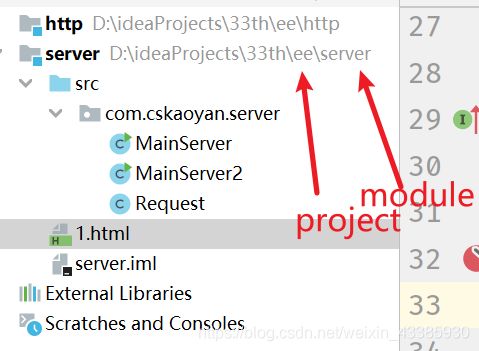
工作目录又和new File的相对路径是直接相关联的
package com.cskaoyan.server;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 新建一个服务器程序 ServerSocket
*/
public class MainServer2 {
public static void main(String[] args) {
try {
//创建了一个程序,监听着8090端口号
ServerSocket serverSocket = new ServerSocket(8090);
//该程序需要监听有没有程序发送请求过来,发送到当前机器的8090端口号
//这个socket就是连接进来的请求
//请求里面应当包含请求的信息,如何获取该部分信息呢?
//如果没有请求方连接进来,那么改行代码会一直阻塞等待
//你需要去做的事情,就是往当前机器的8090端口号发送请求
//可以发送任意类型的请求信息,也包含HTTP请求
while (true){
//主线程只负责去持续不断监听客户端连接进来
Socket client = serverSocket.accept();
//获取请求方传递过来的数据,只需要将inputStream进行解析处理即可
//如果请求方发送的是文本请求信息,那么可以直接将该inputStream转成字符串
new Thread(new Runnable() {
@Override
public void run() {
Request request = new Request(client);
// /1.html /2.html
String reqeustURI = request.getReqeustURI();
//相对的是什么路径?工作目录
//这个地方的绝对路径 = 工作目录 + 里面的相对路径
File file = new File(reqeustURI.substring(1));
StringBuffer buffer = new StringBuffer();
OutputStream outputStream = null;
try {
outputStream = client.getOutputStream();
if(file.exists() && file.isFile()){
//文件存在且文件不是目录,把该文件响应出去
//client其实就是对于连接进来的客户端的封装
//如果希望获取客户端提交过来的数据,那么使用client.getInputStream
//如果希望向客户端返回数据,则使用client.getOutputStream
//HTTP响应报文 响应行 响应头 响应体(文件的内容)
// 按住alt + 鼠标
FileInputStream fileInputStream = new FileInputStream(file);
int length = 0;
byte[] bytes = new byte[1024];
buffer.append("HTTP/1.1 200 OK\r\n");
buffer.append("Content-Type:text/html\r\n");
buffer.append("\r\n");
outputStream.write(buffer.toString().getBytes("utf-8"));
while ((length = fileInputStream.read(bytes)) != -1){
outputStream.write(bytes, 0, length);
}
return;
}
//文件不存在,则返回404
buffer.append("HTTP/1.1 404 Not Found\r\n");
buffer.append("Content-Type:text/html\r\n");
buffer.append("\r\n");
buffer.append("File Not Found
");
outputStream.write(buffer.toString().getBytes("utf-8"));
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
常见的静态web服务器
服务器的原理:其实就是将客户输入的网络路径进行解析,服务器需要在本地硬盘上面的指定路径去寻找该文件,最后响应出去。其实就是IO流,只不过此时不再是文件IO流
JavaEE规范:
是一个很大的范畴。指的是在企业开发过程中,为了方便企业级应用开发的方便,sun公司制定的一个标准。举例说明,假如希望获取当前请求报文的请求资源路径
选用A公司的服务器产品,A服务器将请求报文解析成了ARquest对象,设计了一套代码,从ARquest.getReqeustURI来获取请求资源路径
今后可能公司想更换服务器产品,更换成B服务器,B服务器将请求报文解析成了BRquest,获取请求资源路径的方法叫做BRquest.getResources()
之前已经写了一套获取请求资源路径的代码,此时由A产品变更到B产品,此时代码还能用吗?
不利于行业的发展,sun公司制定了一个标准。其中关于请求报文的封装这部分,制定了一个接口叫做ServletRequest,接口里面定义了一个方法叫做getRequestURI用来获取请求资源路径
各个不同服务器生产厂商全部都实现该接口
serveletRequest.getReqeustURI()
Tomcat
安装
建议直接解压缩到某个盘符根目录即可。不要放置在很深的目录下以及中文目录下。
目录
其中tomcat的目录中有一个logs目录,其实很关键,很容易被大家忽略。
一般情况下,如果启动tomcat失败,那么logs目录下的日志会记录下来报错信息。大家需要做的事情就是找到对应的报错信息。
tips:可以按照修改时间降序来查看,和你报错时间比较接近的文件,然后仔细去排查错误信息。
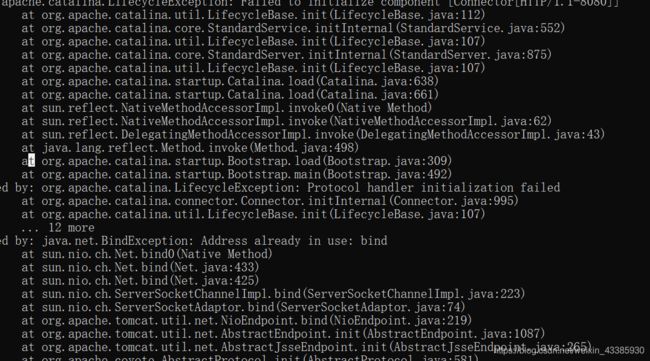
这种一般情况下就是错误日志。
webapps目录是一个非常重要的目录。解下来部署资源文件基本都是在该目录下的。
bin目录启停tomcat的文件存放目录
conf目录配置文件的存放目录
启停tomcat
1.启动(常见的错误问题,启动过程一闪而过----------------有且只有一个问题,JAVA_HOME没有配置正确)
bin目录下执行startup.bat文件
bin目录下唤出cmd,执行startup
2.停止
bin目录下执行shutdown.bat文件
bin目录下唤出cmd,执行shutdown
点击启动框的叉号
ctrl + c
在我的电脑上,直接在bin目录里执行./startup.sh 和./shutdown.sh来启动和关闭tomcat

部署资源
如果你想将一个文件发布到网络上面,供网上的其他用户一起来访问,那么这个时候就可以将该文件部署到服务器中。
在tomcat中,部署资源的最小单位是应用,如果你希望部署一个静态资源页面,那么必须要将该文件放置于一个应用中才可以。
如何配置一个应用呢?
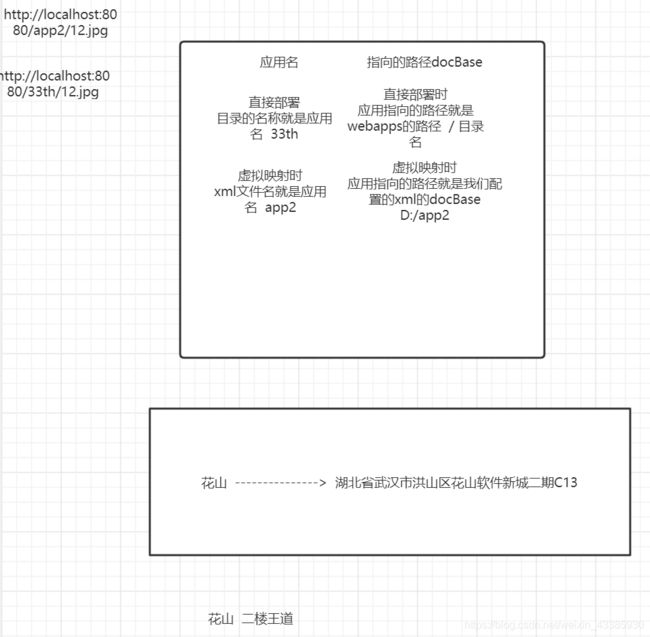
最简单的方式就是在tomcat的webapps目录下新建一个目录,当tomcat启动的时候,该目录就会解析成为一个应用,同时该目录的名称也会成为当前应用的名称。
直接部署
就是上述介绍的方式,在webapps目录下新建一个目录,会被解析成为一个应用,在该目录中放置文件,就完成了资源文件的部署。
如何访问呢?
当你输入http://localhost:8080时,相当于已经定位到了tomcat的webapps目录,那么接下来如何访问到该资源文件,只需要写出该资源文件相当于tomcat的webapps的相对路径关系即可。
http://localhost:8080/33th/1.html
当然除此之外,还可以通过war包来部署。war包你可以理解为类似于zip格式的压缩包,tomcat启动的时候,会自动将war包展开,形式一个目录,形成目录之后,后面的过程和上面的案例又是完全一致的了。
关于war包的说明:
今后大家工作,开发阶段 使用自己的电脑来开发,但是最终开发完成之后,需要将代码进行合并,然后部署到一台服务器上面,测试环境(会在这台机器上面进行测试)
虚拟映射
上述的部署资源的方式都是将文件放置在tomcat的webapps目录下的,这种方式叫做直接部署,但是如果你不希望将文件放置在webapps目录下,也希望tomcat可以部署我们资源文件,那么可以采用接下来的方式,这种方式资源文件没有放置在webapps目录下,所以呢,相当于虚拟的映射到webapps目录下,也叫作虚拟映射。
对于该配置方式本质的理解:
把握一个核心点。服务器部署资源,其实就是将用户输入的网络路径转换成本地硬盘路径就可以了
核心的点就是本地硬盘路径。
至于该文件是放置在tomcat的webapps目录里还是外面,有影响吗?????没影响,只要拿到该文件的绝对硬盘路径,那么我就可以把该文件响应出去。 new File (path)
分析一下:
直接部署,如何拿到一个文件的绝对路径的?
文件放置在webapps目录下,tomcat能否知道tomcat的webapps的硬盘路径?可以知道
最后再拼接上/33th/1.html就可以拿到1.html绝对硬盘路径。
1.conf/Catalina/localhost目录下配置一个xml文件
该文件的名称会被当做应用的名称。
<Context docBase="D:\app2"/>
当接下来访问时,如果输入http://localhost:8080/app2 此时相当于已经定位到了D:/app2目录,接下来,如何去访问某个资源文件,只需要去写出相对路径关系即可。
你可以把xml文件的名字改得和文件名不一样,但是这样就必须在输入url时保持和xml的文件名一致
http://localhost:8080/app2/12.jpg
-
conf/server.xml文件中 Host节点下新增一个Context节点
<Context path="/app111" docBase="D:\applicationxxxx"/>任何一个应用都需要应用名,在这种情况下,它没有文件名的概念,所以需要有一个path属性来当做应用名,写法是/开头
http://localhost:8080/app111/1.txt
虚拟映射方式一更为好一些,为什么呢?因为方式一不会对原有的server.xml文件产生任何侵入性影响。
tomcat组件(希望能够掌握)
tomcat其实是由一系列可配置的组件所构成的。变形金刚的每个部分。tomcat的组件是可以进行配置的,也就是可以动态的去调整改变的,如何去调整呢?可以通过server.xml文件来进行修改调整。
执行过程:
tomcat在启动的时候会读取server.xml文件里面的内容,然后将其解析成一个一个的组件对象。
比如一个组件
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
tomcat启动的时候就会生成一个Connector组件对象,该对象会持续监听8080端口号,如果一个客户端发送请求到当前机器的8080端口号,Connector会读取该请求信息并且进行解析,解析的时候会按照HTTP/1.1格式来进行处理。
Engine组件下面有一个Host组件,两者之间的关系其实非常类似于行政区域中的省和市的关系。(Host对应着我们设置的应用程序)
请求到达engine之后,会进一步下发给host,engine的职责就是这个。政策的下发,首先下发给省,省下发给市
Engine、Host、Context之间的关系就类似于省、市、县的关系。
tomcat的请求执行流程(尽可能掌握)
以访问http://localhost:8080/app/1.html为例
1.客户端浏览器输入指定路径时,首先进行域名解析,TCP三次握手建立一个可靠的TCP连接,浏览器会帮助用户生成一个HTTP请求报文
2.HTTP请求报文经过tcp层、ip层、链路层,最终从机器出去,在网络中中转传输到达目标机器
3.再次经过链路层、ip层、tcp层,重新拿到原先的HTTP请求报文,会被监听着8080端口号的HTTP/1.1 Connector接收到
4.Connector的职责其实也比较单一,所做的事情就是将请求报文进行解析,并且拆解封装成为request对象,同时还会提供一个response对象(联想一下,你去超市购物,你一般会推一个小推车),将这两个对象传给engine
5.engine的职责就是将这两个对象进行进一步下发(联想类比,行政区域 省市县概念)给Host,如果没有找到一个合适的Host,则默认情况下就会交给localhost来处理
6.host的职责也非常单一,将这两个对象进行进一步下发给Context(应该交给哪个Context来执行呢?Context的来源有哪些呢?---- 直接部署、虚拟映射两个方式),尝试将/app当做一个应用,也就是Context来处理,寻找有没有配置一个叫做/app的应用,如果找到,则将这两个对象进行进一步下发给该Context对象(path、docBase)
7.要去寻找一个叫做/1.html的文件,如何去找呢? 会按照docBase + /1.html拼接形成一个绝对路径。如果找到,则将该文件的流拿到,然后写入到response对象中;如果没有找到,则写入一些404的状态码到respponse中
8.Context执行完毕,这两个对象又会被返回到Connector,它会读取response对象里面的内容,按照HTTP响应报文的格式要求,生成HTTP响应报文,会再次经过底层网络架构返回给客户端
9.客户端拿到HTTP响应报文之后,会对响应报文进行解析,读取响应体里面的内容,将响应体里面的内容呈现到浏览器的主窗口中。
Engine(有且只有一个)、Host(默认只有一个,可以配置多个,但是不配置也没关系)、Context(正常情况下,绝对不止一个)
Connector {
request
response
engine(request,response)
//读取response里面的数据
}
engine{
host(request,response);
}
host{
Context(request,response);
}
tomcat设置(掌握)
缺省应用
tomcat在处理请求时,如果没有找到一个合适的应用,比如访问http://localhost:8080/app2/1.html,正常情况下,会将/app2当做一个应用来处理,如果没有找到该应用,会将请求交给缺省应用来处理,缺省应用的特点是应用名是不需要写,在配置的时候,注意,需要写成ROOT,上述请求如果交给缺省ROOT应用来处理,那么它会在该应用内去寻找一个叫做/app2/1.html的文件
如何设置一个ROOT应用呢?
1.直接部署,webapps目录下,新建一个ROOT,那么该应用就是ROOT缺省应用
2.虚拟映射方式一,conf/Catalina/localhost下新增一个ROOT.xml文件
ROOT应用下的文件访问时,直接将该应用去掉即可。
将资源文件放置在缺省应用下,访问的时候不需要带应用名的。
设置默认访问页面
有的情况下,发现访问http://localhost:8080/app,/app是一个应用名,但是并没有写清楚具体的访问资源,那么此时应该访问的是哪个页面呢?
在tomcat的conf/web.xml文件中定义了如下配置
<welcome-file-list>
<welcome-file>index.htmlwelcome-file>
<welcome-file>index.htmwelcome-file>
<welcome-file>index.jspwelcome-file>
welcome-file-list>
如果访问的时候路径指向的是一个应用,而不是一个具体的文件,那么会按照配置的如下顺序来访问,依次去查找在当前应用下有没有配置该资源文件,如果找到,则加载该文件,如果没有找到,则最终显示404
优先查看当前应用内有没有配置Index.html,其次index.htm,最后index.jsp,如果三个文件都没有,则返回404,如果在某一文件找到,则加载该文件。
http://localhost:8080/
表示的是加载的是ROOT应用下的index.jsp文件
设置端口号
默认情况下tomcat Connector HTTP/1.1监听的是8080端口号,如果希望更改端口号,直接修改Connector的port即可。在某些情况下,发现访问资源时没有携带端口号,为什么呢?http://localhost
http//:www.cskaoyan.com
如果没有端口号,那么说明它使用的是当前协议的默认端口号,对于http协议来说,默认端口号是80端口号
也就是说,如果希望访问tomcat的资源时,不携带端口号,那么需要tomcat的connector监听80端口号即可。