深入理解Tomcat
目录
-
-
-
- 02 HTTP 必知必会
- 03 Servlet容器
- 04 Tomcat系统架构-连接器
- 05 Tomcat系统架构-容器
- 06 Tomcat请求过程流转
- 07 Tomcat启动流程
-
- 7.1 Catalina 组件
- 7.2 Server 组件
- 7.2 Service 组件
- 7.3 Engine组件
- 08 NioEndpoint组件:Tomcat如何实现非阻塞I/O?
-
- 8.1 LimitLatch
- 8.2 Acceptor
- 8.3 Poller
- 8.4 SocketProcessor
- 8.5 Exector
- 8.6 如何实现高并发
- 09 Tomcat如何实现异步I/O
-
- 09.1 Nio2Endpoint
- 9.2 SocketProdes是何如获取数据的?
- 10 AprEndpoint组件: Tomcat Apr 提高I/O性能
-
- 10.1 java堆 与 非堆内存
- 10.2 sendFile特性
- 10.3 小结
- 11 Tomcat的线程池技术
-
- 11.1 tomcat 线程池定制的任务队列
- 12 Tomcat实现WebSocket
-
- 12.1 ServletContainerInitializer
- 13 Tomcat热加载 和 热部署
-
- 13.1 后台检测任务
- 13.2 热加载
- 13.3 热部署
- 14 tomcat如何打破双亲委派政策
-
- 14.1 类加载器的核心方法
- 14.2 tomcat自定义的WebAppClassLoader
-
- loadclass()方法
- 14. 3 为什么要破坏双亲委派机制
- 15 tomcat如何隔离多web应用
-
- 15.1 如何解决第一个问题,web应用隔离?
- 15.2 如何解决第二个问题,不同web应用共享jar库,例如:Spring?
- 15.3 如何解决第三个问题,如何隔离Tomcat的类与 web应用的类?
- 15.4 Spring类加载的问题
- 15.5
- 16 Tomcat如何实现Servlet规范
-
- 16.1 Servlet管理创建
- 16.2 Filter链的执行逻辑
- 16.3 Listener机制
- 17 Tomcat如何实现异步Servlet
-
- 17.1 第一问题:
- 17.2 第二个问题:
- 18. SpringBoot 支持Tomcat
-
- 18.1 容器内置容器如何启动:
- 18.2 如何定制servlet
- 19 SpringBoot如何管理Session
-
- 19.1 session 是如何创建的
- 19.2 Session的清理
- 20 Tomcat 集群通讯组件原理
- 参考
-
-
02 HTTP 必知必会
因为http是无状态的 所以出现了,cookies 存储状态信息,但是存储在本地不安全,这么也就有了 session,存储在服务器端,配合cooikes来进行标识;
03 Servlet容器
Servlet其实是一个接口,定义了servlet规范。一个http请求 到服务器的工作流程如下:
1、将请求信息封装成ServletRequest
2、调用servlet的service方法
3、如果不存在,那么就调用init方法创建
4、调用service方法,然后返回reponse对象,返回给客户端
 servlet容器,web容器,spring容器,springmvc容器的区别;
servlet容器,web容器,spring容器,springmvc容器的区别;
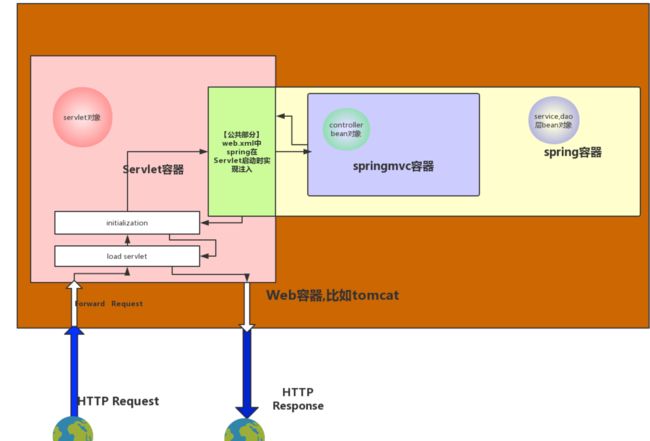
SpringMVC的容器直接管理跟DispatcherServlet相关的Bean,也就是Controller,ViewResolver等,并且SpringMVC容器是在DispacherServlet的init方法里创建的。而Spring容器管理其他的Bean比如Service和DAO。
并且SpringMVC容器是Spring容器的子容器,所谓的父子关系意味着什么呢,就是你通过子容器去拿某个Bean时,子容器先在自己管理的Bean中去找这个Bean,如果找不到再到父容器中找。但是父容器不能到子容器中去找某个Bean。父容器 不能依赖子容器;
上图来源于网络
04 Tomcat系统架构-连接器
tomcat设计了两个核心组件:连接器Connector, 容器Container;连接负责对外交流,容器负责内部处理;

连接器的基本功能:
1、监听网络端口
2、接收网络请求连接
3、将请求解析转换为 Tomcat Request 对象
4、将Tomcat Request 转换为 Servlet Request
**5、调用Servlet 获得 Servlet Response **
6、将获得的结果转换,响应返回给前端
根据上述功能,Tomcat 就把它抽象成了三个核心类,EndPoint 、Process、Adapter 来分别处理
- 网络通信
- 应用层协议解析
- Tomcat Request 到 Servlet的转换
组件之间通过接口进行交互,封装变化,将系统中经常变化的部分,和稳定的部分进行隔离;有助于增加复用性,并降低系统的耦合度;
其交互处理的逻辑如下:
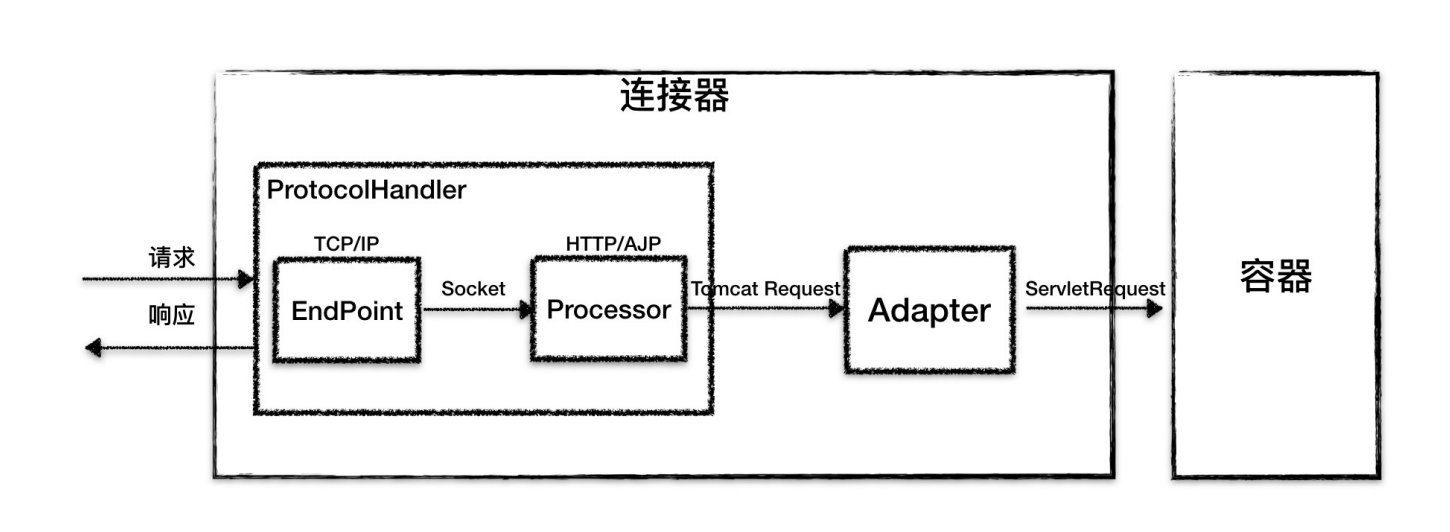
4.1 ProtocolHandler 组件
这个组件内部包含两个组件,EndPoint 和 Processor;
**EndPoint: **负责通信的端点,是具体的Socket接收和发送的处理器,该组件是实现Tcp/Ip 协议的(内部有个线程池处理请求)
**Processor:**用来实现 HTTP 协议,Processor 接收来自 EndPoint 的 Socket,读取字节流解析成 Tomcat Request 和Response 对象,并通过 Adapter 将其提交到容器处理,Processor 是对应用层协议的抽象。

EndPoint 负责底层 Socket通信,Proccesor 负责应用层协议解析。连接器通过适配器 Adapter 转换调用容器。
05 Tomcat系统架构-容器
容器的层次结构,Tomcat设计了4种容器,分别是Engin 、Host、Context 、Wapper
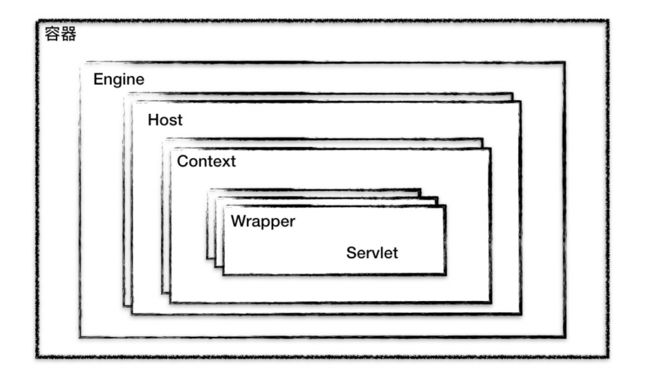
他们是一个包含关系。Tomcat 通过一种分层的架构,使得 Servlet 容器具有很好的灵活性。
- Context 表示一个 Web 应用程序;
- Wrapper 表示一个 Servlet,一个 Web 应用程序中可能会有多个 Servlet;
- Host 代表的是一个虚拟主机,或者说一个站点,可以给 Tomcat 配置多个虚拟主机地址,而一个虚拟主机下可以部署多个 Web 应用程序;
- Engine 表示引擎,用来管理多个虚拟站点,一个 Service 最多只能有一个 Engine。

上图展示了,根据Url是如何找到对应的wapper进行处理;
连接器中Adapter 会调用容器的 Service 方法来执行 Servlet,最先拿到请求的是 Engine 容器,Engine 容器对请求做一些处理后,会把请求传给自己子容器 Host 继续处理,依次类推,最后这个请求会传给 Wrapper 容器,Wrapper 会调用最终的 Servlet 来处理。那么这个调用过程具体是怎么实现的呢?
答案是使用 Pipeline-Valve 管道。
- Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。

在连接器里 会有一个触发调用 Engine的一个 value,然后以责任链的模式不断传递,Wrapper 容器的最后一个 Valve 会创建一个 Filter 链,并调用 doFilter() 方法,最终会调到 Servlet 的 service 方法
06 Tomcat请求过程流转

组件是如何创建,初始化,销毁的呢,管理他们的生命周期是一个很关键的问题?如何实现一键启动?
答:tomcat的核心组件都抽象出公共的部分 lifecycle接口其中定义了:init()、start()、stop() 和 destroy()这么几个核心方法;在父组件中创建的时候需要调用子组件的init方法。所以只要调用顶层的 Service的init方法,整个tomcat就启动了。
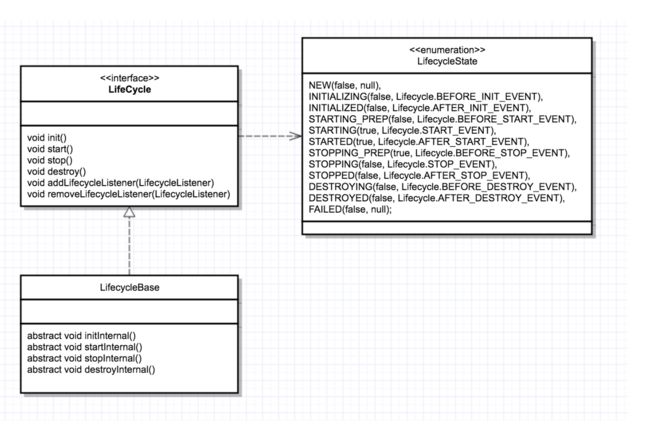
这是lifecyle的模版方法
@Override
public final synchronized void init() throws LifecycleException {
// 1、判断状态
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try {
// 2 触发 INITIALIZING 事件的监听器
setStateInternal(LifecycleState.INITIALIZING, null, false);
// 3 调用子类初始化方法
initInternal();
// 触发 INITIALIZED 事件的监听器
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
}
}
Tomcat 自定义了一些监听器,这些监听器是父组件在创建子组件的过程中注册到子组件的。比如 MemoryLeakTrackingListener 监听器,用来检测 Context 容器中的内存泄漏,这个监听器是 Host 容器在创建 Context 容器时注册到 Context 中的。我们还可以在 server.xml 中定义自己的监听器,Tomcat 在启动时会解析 server.xml,创建监听器并注册到容器组件。
整体类图:

07 Tomcat启动流程
通常我通过执行tomcat bin下的 startup.sh 脚本启动tomcat,那么tomcat到底是如何启动的呢? 具体流程如下:

7.1 Catalina 组件
它是个启动类,通过解析server.xml ,创建相应的组件,并调用server的start方法,向下传递启动。Catalina是一个管理则者的身份,它还需要处理各种异常场景,当发生 ctrl+ c 强制关闭时,是如何释放资源的。Catalina在JVM中注册了一个关闭的钩子。
public void start() {
if (getServer() == null) {
load();
}
if (getServer() == null) {
log.fatal("Cannot start server. Server instance is not configured.");
return;
}
long t1 = System.nanoTime();
// Start the new server
try {
getServer().start();
} catch (LifecycleException e) {
return;
}
// Register shutdown hook
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
// 注册一个jvm的回调函数;内部其实是进行资源的释放和清理
Runtime.getRuntime().addShutdownHook(shutdownHook);
}
// 监听停止请求
if (await) {
await();
stop();
}
}
7.2 Server 组件
Server的具体实现类是StandServer.这个组件会管理 service的生命周期。在server内部维护着多个service组件。还有一个重要的任务就是,启动Socket来监听停止端口。
7.2 Service 组件
Service组件的具体实现类是StandardService,
/**
*
* 这是service 实例
*
*/
private Server server = null;
/**
*
* 连接器
*/
protected Connector connectors[] = new Connector[0];
private final Object connectorsLock = new Object();
/**
* engine容器
*
*/
private Engine engine = null;
@Override
protected void startInternal() throws LifecycleException {
// 1、触发启动监听器
setState(LifecycleState.STARTING);
// 2、启动引擎
if (engine != null) {
synchronized (engine) {
engine.start();
}
}
// 3、mapper监听器 热加载部署
mapperListener.start();
// 4、连接器的启动 内部会启动子组建 如:endoint组件
synchronized (connectorsLock) {
for (Connector connector: connectors) {
connector.start();
}
}
}
}
service作为管理者,最重要的是维护其他组件的生命周期;启动组件时要维护依赖关系。
7.3 Engine组件
engine组件的本质是一个容器,它继承了ContainerBase基类,并实现了Engine接口
08 NioEndpoint组件:Tomcat如何实现非阻塞I/O?
uninx下有5种IO模型:同步阻塞IO, 同步非阻塞IO, IO多路复用,信号驱动IO, 异步IO。见: IO模型
网络IO通信过程:
对于一个网络I/O通信过程,比如网络数据的读取,会涉及两个对象。一个是调用这个IO操作的用户线程,另一个就是操作系统内核。 当发生IO操作时,网络数据读取会经历两个步骤:
- 用户线程等待将数据从网卡拷贝到内核空间,
- 内核将数据从内核空间拷贝到用户空间
各种 I/O 模型的区别就是:它们实现这两个步骤的方式是不一样的。
java的多路复用器的使用其实就是两步:
1、创建一个seletor,在他身上注册感兴趣的事情,然后调用select方法,等待感兴趣的事发生。
2、感兴趣的事情发生了,比如可以读了,这时便创建一个新的线程去处理 Channel.
Tomcat 的 NioEndpoint 包括LimitLatch、Acceptor、Poller、SocketProcessor 和 exector组件。如下图:

8.1 LimitLatch
这是一个连接控制器,他负责最大连接数。默认值为10000
public class LimitLatch {
private static final Log log = LogFactory.getLog(LimitLatch.class);
private class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 1L;
public Sync() {
}
// 实现逻辑:是否小于限制的值
@Override
protected int tryAcquireShared(int ignored) {
long newCount = count.incrementAndGet();
if (!released && newCount > limit) {
// Limit exceeded
count.decrementAndGet();
return -1;
} else {
return 1;
}
}
@Override
protected boolean tryReleaseShared(int arg) {
count.decrementAndGet();
return true;
}
}
// 线程调用这个方法来获得接收新连接的许可,线程可能被阻塞
public void countUpOrAwait() throws InterruptedException {
if (log.isDebugEnabled()) {
log.debug("Counting up["+Thread.currentThread().getName()+"] latch="+getCount());
}
sync.acquireSharedInterruptibly(1);
}
/**
*调用这个方法来释放一个连接许可,那么前面阻塞的线程可能被唤醒
*/
public long countDown() {
sync.releaseShared(0);
long result = getCount();
if (log.isDebugEnabled()) {
log.debug("Counting down["+Thread.currentThread().getName()+"] latch="+result);
}
return result;
}
其内部实现是通过AQS同步框架来处理并发。AQS 就是一个骨架抽象类,它帮我们搭了个架子,用来控制线程的阻塞和唤
醒。具体什么时候阻塞、什么时候唤醒由你来决定。
8.2 Acceptor
跑在一个单独的线程里,在一个死循环里调用accept方法来接收连接,一旦有请求进来,就返回channel对象,接着教给Poller去处理。多个Acceptor共享ServerSocktChannel. 在NioEndpoint中完成初始化. 部分代码如下:
public void bind() throws Exception {
serverSock = ServerSocketChannel.open();
socketProperties.setProperties(serverSock.socket());
InetSocketAddress addr = (getAddress()!=null?new InetSocketAddress(getAddress(),getPort()):new InetSocketAddress(getPort()));
serverSock.socket().bind(addr,getBacklog());
// 设置为阻塞模式
serverSock.configureBlocking(true); //mimic APR behavior
serverSoc
上面的代码主要执行这么两个操作:
- 当应用层连接达到时,操作系统还能接收连接。操作系统能继续接收的最大连接数就是这个队列长度,可以通过 acceptCount 参数配置,默认是 100。
- ServerSocktChannel是以阻塞的方式获得连接的。连接得到的Channel对象,SocketChannel 对象封装在一个 PollerEvent 对象中,并将 PollerEvent 对象压入 Poller 的 Queue 里,这是个典型的生产者 - 消费者模式,Acceptor 与 Poller 线程之间通过 Queue 通信。
8.3 Poller
Poller 的本质是一个 Selector,也跑在单独线程里。Poller 在内部维护一个 Channel 数组,它在一个死循环里不断检测 Channel 的数据就绪状态,一旦有 Channel 可读,就生成一个 SocketProcessor 任务对象扔给Executor 去处理。并且如果发现超时的SocketChannle,就需要关闭。
8.4 SocketProcessor
Poller 会创建 SocketProcessor 任务类交给线程池处理,而 SocketProcessor实现了 Runnable 接口。读取Channel数据生成ServletRequest对象。
8.5 Exector
Executor 就是线程池,负责运行 SocketProcessor 任务类,SocketProcessor 的 run 方法会调用Http11Processor 来读取和解析请求数据。
8.6 如何实现高并发
连接检测、检测IO事件、事件处理 这三个过程都有独立的线程去执行。
09 Tomcat如何实现异步I/O
异步最大的特点是,应用程序不需自己去触发,数据从内核空间叫用户空间的拷贝。应用程序是无法主动访问内核空间的。那么有两种处理方式,有两种方式:1、内核主动拷贝数据到应用程序中 2、等待应用程序通过 Selector 来查询,当数据就绪后,应用程序再发起一个 read 调用,这时内核再把数据从内核空间拷贝到用户空间。
数据准备好后,数据从内核拷贝到用户空间的这一段时间,应用程序还是阻塞的。
同步与异步的区别:
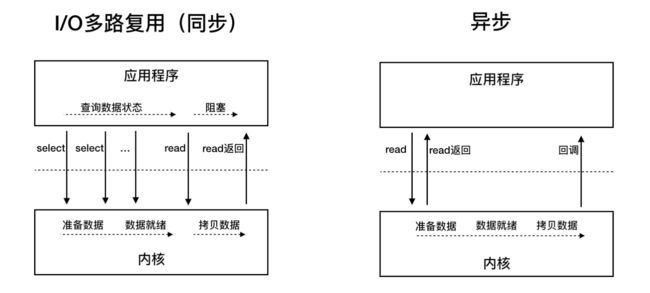
通过注册的回调函数,内核会主动通知数据。调用readAPI时需要告诉内核2件事情: 1、数据准备好后存储在哪个buffer,以及应用程序指定的回调函数。
09.1 Nio2Endpoint
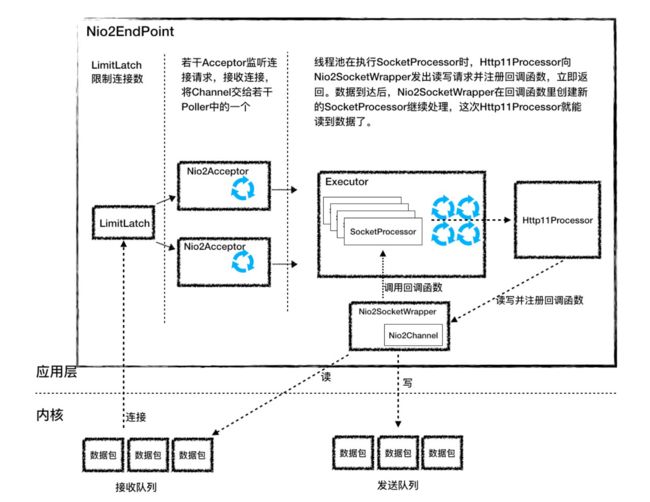
- Nio2EndPoint与 NIoEndPoint最大的区别是 前者没有Poller组件,也就是没有Selector,因为不许需要应用程序去主动读取数据,内核会将准备好的数据回调。
9.2 SocketProdes是何如获取数据的?
Http11Processor调用Channle获取数据时应该会立马异步返回结果的,如果读取到数据的?
Http11Processor 是通过 2 次 read 调用来完成数据读取操作的。
- 第一次read获得连接;注册回调函数准备第二次read
- 第二次read创建新的SocketProcessor处理数据。
10 AprEndpoint组件: Tomcat Apr 提高I/O性能
AprEndPonit与NioEndPoint类似,都是实现了非阻塞的I/O,但是区别就是aprEndPoint是通过调用JNI调用本地的库实现非阻塞IO的。本地库是使用C语言编写,当频繁的IO操作时,效率会高于java语言。
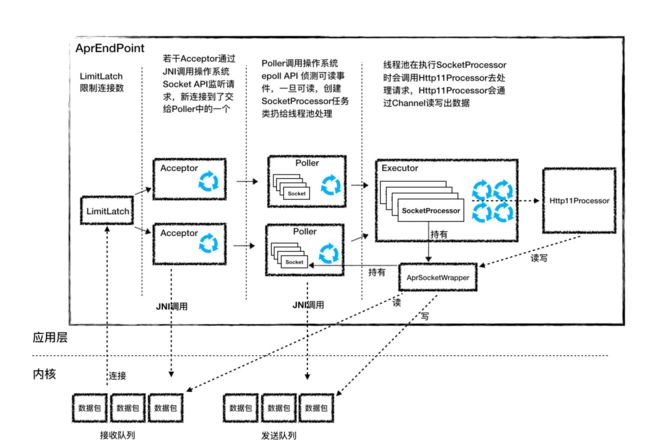
区别就是组件的实现方式不一样:
- Acceptor的作用是监听连接,并建立连接的,本质是调用了操作系统的4个API: socket、bind、listen、accept.是通过JNI native关键字修饰的方法。
- **Poller **acceptor接收到一个新的socket连接后,会把这个socket交给poller去处理,Poller不是调用java NIO里的Selector来查询状态,而是通过JNI调用apr里的poll方法,APR又是调用澳操作系统的 epoll api来实现的。其中有一个参数可以控制,当数据到达时才建立连接,这样优化了性能。
10.1 java堆 与 非堆内存
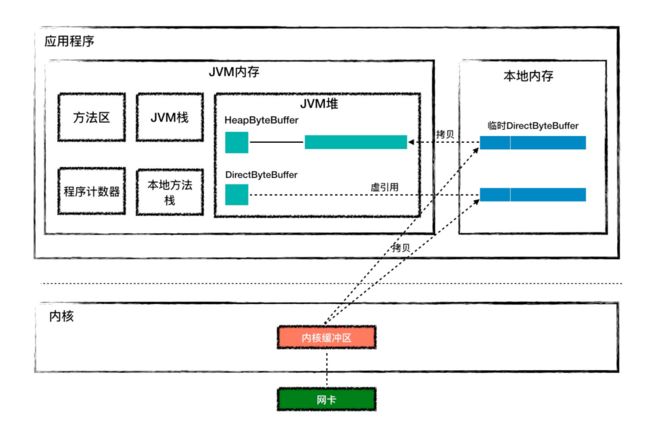
HeapByteBuffer 与 DirectByteBuffer的区别
- HeapByteBuffer复制的时候,数据需要从内核先复杂到 本地内存的临时buffer中,然后再从临时buffer 复制到jvm堆里面,这样会防止在复制的过程中 发生GC
- **DirectByteBuffer也是在 **在jvm堆里面分配内存,而数组的内存是从本地内存分配的。DirectByteBuffer 对象中有个 long 类型字段 address,记录着本地内存的地址,在接收数据的时候,内存地址传递给 C 程序C 程序会将网络数据从内核拷贝到这个本地内存,JVM 可以直接读取这个本地内存,这种方式少了一次复制,所以效率也就会更高
10.2 sendFile特性
正常情况,当我们tomcat发生IO时,例如:读取一个问题,然后通过网络发送处理,工作流程如下:
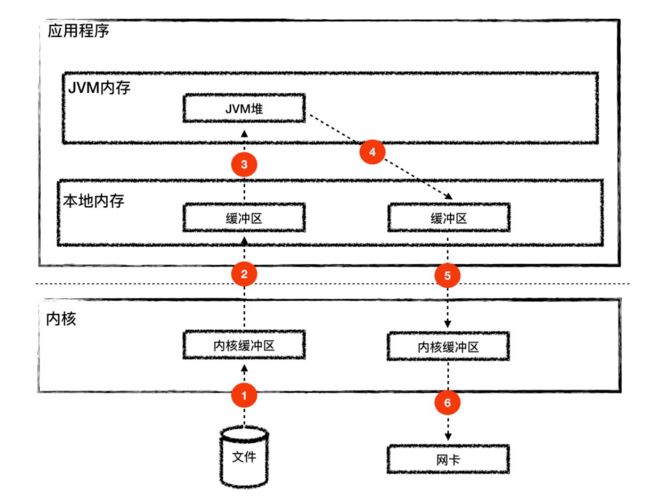
数据发生了6次拷贝,多次在内核态 与用户态之间转换,会耗费大量的cpu资源。但是sendfile可以进行优化,不经过核心到用户态的 拷贝。

10.3 小结
DirectByteBuffer可以减少拷贝次数;sendfile减少核心态到用户态之间的切换;netty就是通过directBytebuffer收集数据的,它采用了本地内存技术。
11 Tomcat的线程池技术
tomcat的线程池也是基于定制版的 ThreadPoolExecutor的。
/**
*
*
* 限制了最大线程数 及 最大队列的数
*
*
*/
// 定制队列
taskqueue = new TaskQueue(maxQueueSize);
// 定制线程工厂
TaskThreadFactory tf = new TaskThreadFactory(namePrefix,daemon,getThreadPriority());
// 定制线程池
executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), maxIdleTime, TimeUnit.MILLISECONDS,taskqueue, tf);
整个执行流程:
-
- 前 corePoolSize 个任务时,来一个任务就创建一个新线程。
-
- 再来任务的话,就把任务添加到任务队列里让所有的线程去抢,如果队列满了就创建临时线程。
-
- 如果总线程数达到 maximumPoolSize,则继续尝试把任务添加到任务队列中去。
-
- 如果缓冲队列也满了,插入失败,执行拒绝策略。
与传统线程池中区别最大的一步 就是第三步骤,如果总数达到maximumPoolSize,传统的做法是直接执行拒绝策略,但是tomcat的线程池是会继续尝试一次插入;
public void execute(Runnable command, long timeout, TimeUnit unit) {
submittedCount.incrementAndGet();
try {
super.execute(command);
// 发生拒绝策略 捕捉异常
} catch (RejectedExecutionException rx) {
if (super.getQueue() instanceof TaskQueue) {
final TaskQueue queue = (TaskQueue)super.getQueue();
try {
// 尝试处理任务
if (!queue.force(command, timeout, unit)) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException("Queue capacity is full.");
}
} catch (InterruptedException x) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} else {
submittedCount.decrementAndGet();
throw rx;
}
}
}
11.1 tomcat 线程池定制的任务队列
默认情况下:LinkedBlockingQueue是无边界的,最大值是Integer.MAX_VALUE; 那么也就是当达到核心线程时,任务队列永远不会满,也就没有机会创建新的线程了,但是tomcat的任务队列是定制了的,重写了队列的offer方法。
@Override
public boolean offer(Runnable o) {
//we can't do any checks
if (parent==null) return super.offer(o);
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o);
// 已经提交的任务 小于当前线程数
if (parent.getSubmittedCount()<(parent.getPoolSize())) return super.offer(o);
// 已提交的任务大于当前线程数
if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false;
//if we reached here, we need to add it to the queue
return super.offer(o);
}
只有当前线程数大于核心线程数、小于最大线程数,并且已提交的任务个数大于当前线程数时,也就是说线程不够用了,但是线程数又没达到极限,才会去创建新的线程。其实可以直接设置队列长度 = 最大 - 核心线程数,也就缓冲队列的形式存在。
12 Tomcat实现WebSocket
websocket可以实现服务器与浏览器端全双工的通信,浏览器与服务端都可以主动向对方发送消息。websocket是一套应用层的协议,为了跟现有的 HTTP 协议保持兼容,它通过 HTTP 协议进行一次握手,握手之后数据就直接从 TCP 层的 Socket 传输,就与 HTTP 协议无关了。
浏览器请求会带上websocket相关的请求头。数据会以fream的形式传输出去,
使用方法通过:
@ServerEndpoint(value = “/websocket/chat”) 定义这是个业务类,并且通过相关注解定义事件:
例如:@OnOpen、@OnClose、@OnError和在@OnMessage
12.1 ServletContainerInitializer
是 Servlet 3.0 规范中定义的用来接收 Web 应用启动事件的接口,这样有机会在web启动过程中做一些初始化工作。
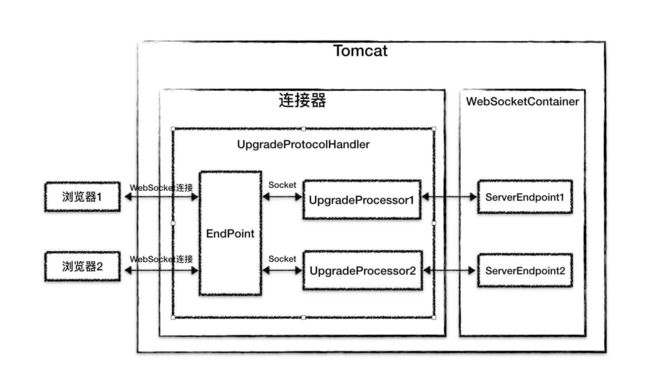
Tomcat 对 WebSocket 请求的处理没有经过Servlet 容器,而是通过 UpgradeProcessor 组件直接把请
求发到 ServerEndpoint 实例,并且 Tomcat 的WebSocket 实现不需要关注具体 I/O 模型的细节
13 Tomcat热加载 和 热部署
热加载:web容器启动一个后台线程,定时检测class文件的变化,发现后重新加载类。
热部署:也是定时检测,但是会重新重启整个应用容器,并清空sesson
13.1 后台检测任务
在tomcat后台会有一个注册一个任务定时处理,任务的核心代码如下:
*/
protected class ContainerBackgroundProcessor implements Runnable {
@Override
public void run() {
Throwable t = null;
String unexpectedDeathMessage = sm.getString(
"containerBase.backgroundProcess.unexpectedThreadDeath",
Thread.currentThread().getName());
try {
while (!threadDone) {
try {
Thread.sleep(backgroundProcessorDelay * 1000L);
} catch (InterruptedException e) {
// Ignore
}
if (!threadDone) {
// 处理当前容器,也就是主容器
// 该方法执行两个操作:
// 1、掉用当前容器的 backprocess方法
// 2、递归调用子容器的 backprocess方法
// engin > contain > host > wapper
processChildren(ContainerBase.this);
}
}
} catch (RuntimeException|Error e) {
t = e;
throw e;
} finally {
if (!threadDone) {
log.error(unexpectedDeathMessage, t);
}
}
}
- 这样的好处是父容器中出发后台处理后,也有调用子容器进行处理。
13.2 热加载
tomcat的热加载其实就是在Context容器中实现的,Context实现了自己的backgroundProcess 方法,
@Override
public void backgroundProcess() {
if (!getState().isAvailable())
return;
Loader loader = getLoader();
if (loader != null) {
try {
// 调用了wapperload方法,进行热部署
// 1、销毁所有context的子容器
// 2、销毁所有filter和servlet
// 3、启动context (整个过程中并未销毁session)
loader.backgroundProcess();
} catch (Exception e) {
log.warn(sm.getString(
"standardContext.backgroundProcess.loader", loader), e);
}
}
...........
// 调用父类的backgroundProcess();
super.backgroundProcess();
}
13.3 热部署
热部署是由一个周期性时间完成的;其实 HostConfig 会检查 webapps 目录下的所有 Web 应用:如果原来 Web 应用目录被删掉了,就把相应 Context 容器整个销毁掉。是否有新的 Web 应用目录放进来了,或者有新的 WAR包放进来了,就部署相应的 Web 应用。
14 tomcat如何打破双亲委派政策
jvm的中存在3个类加载器:
- BootstrapClassLoader 是启动类加载器,由 C 语言实现,用来加载 JVM 启动时所需要的核心类,比如
rt.jar、resources.jar等。
- ExtClassLoader 是扩展类加载器,用来加载\jre\lib\ext目录下 JAR 包。
- AppClassLoader 是系统类加载器,用来加载 classpath下的类,应用程序默认用它来加载类。
类加载器需要加载一个类的时候,需要委托父类去加载。父类加载不到时,在子类加载,如果父类为空,那就使用BootStrap类加载器。
14.1 类加载器的核心方法
findClass 方法的主要职责就是找到“.class”文件,可能来自文件系统或者网络,找到后把“.class”文件读到内存得到字节码数组,然后调用 defineClass 方法得到Class 对象。
loadClass 是个 public 方法,说明它才是对外提供服务的接口。具体就是进行类加载,双亲委派政策就是在这里执行,会调用父类的loadclass
如果要打破双亲委派政策,那就要继承 ClassLoader 抽象类,并且需要重写它的 loadClass 方法,因为 ClassLoader 的默认实现就是双亲委托。
14.2 tomcat自定义的WebAppClassLoader
它打破双亲委托机制,首先自己去加载某个类,如果找不到,那么就代理给父类加载,这样的话目的就是为了,优先加载web应用下自己定义的类。
该类中的findClass方法,在loadclass方法中将会被调用
@Override
public Class<?> findClass(String name) throws ClassNotFoundException {
Class<?> clazz = null;
try
try {
if (securityManager != null) {
PrivilegedAction<Class<?>> dp =
new PrivilegedFindClassByName(name);
clazz = AccessController.doPrivileged(dp);
} else {
// 【流程1】在web应用下查找类
clazz = findClassInternal(name);
}
if ((clazz == null) && hasExternalRepositories) {
try {
// 【流程2】没有找到,那就父类进行查找
clazz = super.findClass(name);
}
}
// 【流程3】 父类没有找到那就classnotfund异常
if (clazz == null) {
if (log.isDebugEnabled())
log.debug(" --> Returning ClassNotFoundException");
throw new ClassNotFoundException(name);
}
return (clazz);
}
loadclass()方法
@Override
public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
if (log.isDebugEnabled())
log.debug("loadClass(" + name + ", " + resolve + ")");
Class<?> clazz = null;
// 检查本地是否已经加载过这个类在缓存当中
clazz = findLoadedClass0(name);
if (clazz != null) {
if (log.isDebugEnabled())
log.debug(" Returning class from cache");
if (resolve)
resolveClass(clazz);
return (clazz);
}
// 检查系统类加载器中的cache是否加载过
clazz = findLoadedClass(name);
if (clazz != null) {
if (log.isDebugEnabled())
log.debug(" Returning class from cache");
if (resolve)
resolveClass(clazz);
return (clazz);
}
// 尝试使用 java的ext加载器加载,防止web应用破坏重新java核心类
ClassLoader javaseLoader = getJavaseClassLoader();
if (tryLoadingFromJavaseLoader) {
try {
clazz = javaseLoader.loadClass(name);
if (clazz != null) {
if (resolve)
resolveClass(clazz);
return (clazz);
}
} catch (ClassNotFoundException e) {
// Ignore
}
}
if (log.isDebugEnabled())
log.debug(" Searching local repositories");
try {
// 尝试在本地class尝试加载
clazz = findClass(name);
if (clazz != null) {
if (log.isDebugEnabled())
log.debug(" Loading class from local repository");
if (resolve)
resolveClass(clazz);
return (clazz);
}
} catch (ClassNotFoundException e) {
// Ignore
}
// 使用系统类加载器加载
if (!delegateLoad) {
if (log.isDebugEnabled())
log.debug(" Delegating to parent classloader at end: " + parent);
try {
clazz = Class.forName(name, false, parent);
if (clazz != null) {
if (log.isDebugEnabled())
log.debug(" Loading class from parent");
if (resolve)
resolveClass(clazz);
return (clazz);
}
} catch (ClassNotFoundException e) {
// Ignore
}
}
}
throw new ClassNotFoundException(name);
}
上面loadclass的核心流程为:
1、检查tomcat加载器缓存是否加载过
2、系统加载器缓存中是否加载过
3、如果都没有,就让ExtClassLoader去加载,这一步比较关键,目的防止 Web 应用自己的类覆盖 JRE 的核心
类。
4、如果 ExtClassLoader 加载器加载失败,也就是说 JRE 核心类中没有这类,那么就在本地 Web 应用目录下查找并加载。
5、如果本地目录下也有这个类,那就就通过Class.forName(name, false, parent); 调用系统类加载器,进行加载
6、如果上述都加载失败,那么抛出classnotfound异常。
14. 3 为什么要破坏双亲委派机制
- 因为tomcat想让web应用的类更快被加载,这个servlet规范推荐的一种做法。
15 tomcat如何隔离多web应用
问题:
1、如果两个web应用运行在tomcat当中,两个Web 应用中有同名的 Servlet,但是功能不同,Tomcat
需要同时加载和管理这两个同名的 Servlet 类,保证它们不会冲突?
2、如两个 Web 应用都依赖同一个第三方的 JAR 包,比如 Spring,那 Spring 的 JAR 包被加载到内存后,
Tomcat 要保证这两个 Web 应用能够共享。
3、需要隔离Tomcat本身的类和web应用的类。
15.1 如何解决第一个问题,web应用隔离?
每一个web应用都创建一个类加载实例WebAppClassLoader。因为不同的类加载器,加载同一个类名也会被认定为不是同一个类。
15.2 如何解决第二个问题,不同web应用共享jar库,例如:Spring?
SharedClassLoader 加载器作为WebAppClassLoader 的父加载器,专门用来加载共享的 jar库。因为加载的时候会委托给父类加载。
15.3 如何解决第三个问题,如何隔离Tomcat的类与 web应用的类?
CatalinaClassloader,专门用来加载Tomcat自身的类,但是同时也会带来一些问题,如果 tomcat与web需要加载一些共享类时,改如何处理?,那么在CatalinaClassloader 与 SharedClassLoader加载器上就有共同的父加载器 -----CommonClassLoader。兄弟加载器相互隔离,父子加载器可以共享加载。
15.4 Spring类加载的问题
jvm的实现中有一条规则:如果一个类有A加载器加载,那么这个类依赖的类也是由类加载器加载。spring的加载与业务类肯定有关联关系,
但是spring的共享类库由SharedClassLoader加载,而web应用应用下的数据是由WebAppClassLoader加载。**于是线程上下文加载器登场了,类加载器保存在线程私有数据中,**WebAppClassLoarder 类加载器,并在启动 Web 应用的线程里设置线程上下文加载器,这样 Spring
启动时就将线程上下文加载器取出来,用来加载 Bean。
15.5
每个 Web 应用自己的 Java 类文件和依赖的 JAR 包,分别放在WEB-INF/classes和WEB-INF/lib目录下面。

16 Tomcat如何实现Servlet规范
16.1 Servlet管理创建
tomcat将Servlet包装成一个Wrapper,因为基于面向对象的思想,这个wapper中还包含相关的配置信息,url,初始化的参数。tomcat为了提高启动速度,在tomcat启动的时候并不会创建servlet(除非你把 Servlet 的loadOnStartup参数设置为true,但是会创建Wrapper。
Servlet何时被创建?
Tomcat 的 Pipeline-Valve 机制,每个容器组件都有自己的 Pipeline,每个 Pipeline 中有一个 Valve 链,并且每个容器组件有一个 BasicValve(基础阀 也末尾节点)。Wrapper 作为一个容器组件,它也有自己的 Pipeline和 BasicValve,Wrapper 的 BasicValve 叫StandardWrapperValve。是在该类的invock方法中会调用到wapper里进行初始化。
@Override
public final void invoke(Request request, Response response)
throws IOException, ServletException {
try {
if (!unavailable) {
// 初始化servlet方法
servlet = wrapper.allocate();
}
// 创建filter链条;每次获取符合映射到filterChain
ApplicationFilterChain filterChain =
ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
// 执行filter方法 最后一个filter 会执行到servlet.service方法
filterChain.doFilter(request.getRequest(), response.getResponse());
}
16.2 Filter链的执行逻辑
内部循环调用:
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
try {
Filter filter = filterConfig.getFilter();
// 内部循环调用filter方法进行传递
filter.doFilter(request, response, this);
} catch (IOException | ServletException | RuntimeException e) {
throw e;
} catch (Throwable e) {
e = ExceptionUtils.unwrapInvocationTargetException(e);
ExceptionUtils.handleThrowable(e);
throw new ServletException(sm.getString("filterChain.filter"), e);
}
return;
}
// 调用service方法
servlet.service(request, response);
}
16.3 Listener机制
Listener 也是一种扩展机制,你可以监听容器内部发生的事件,原理就是观察者模式,获取所有的监听器,当事件发生时,执行调用处理。
17 Tomcat如何实现异步Servlet
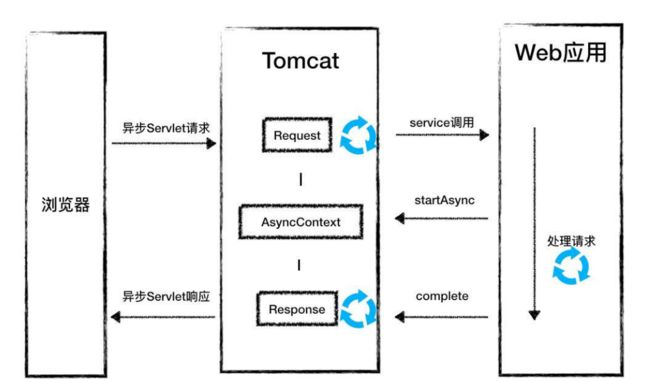
如果有耗费时的线程,将会占用tomcat线程,一直不释放。此时就可以采用异步servlet. 内部就是开启另外一个线程去处理业务,tomcat线程将立即释放;这样内部处理会有这两个问题需要解决:
1、tomcat线程立即释放了,request\response 数据如何保存
2、在返回数据给浏览器前 request\response对象不能被销毁,如何返回数据给浏览器
17.1 第一问题:
在开始异步线程时,需要调用一个函数 startSync 会返回AsyncServletContext 对象,这里就是用来保存request\response对象的。处理完请求后就是从这里拿数据响应给客户端;
17.2 第二个问题:
在 Tomcat 中,负责 flush 响应数据的是 CoyoteAdaptor,它还会销毁 Request 对象和
Response 对象,因此需要通过某种机制通知 CoyoteAdaptor:
this.request.getCoyoteRequest().action(ActionCode.ASYNC_START, this);
如果当前请求是一个异步 Servlet 请求,它会把当前Socket 的协议处理者 Processor 缓存起来,将 SocketWrapper 对象和相应的 Processor存到一个 Map 数据结构里。
返回数据也就是调用这个缓存是socket进行处理。
18. SpringBoot 支持Tomcat
spingBoot内部嵌入了tomcat,那么他是如何支持和启动tomcat的呢?
WebApplicationInitializer
ServletContextInitializer在servlet 3.0 中定义中:
为了支持可以不使用web.xml。提供了ServletContainerInitializer,它可以通过SPI机制,当启动web容器的时候,会自动到添加的相应jar包下找到META-INF/services下以ServletContainerInitializer的全路径名称命名的文件,它的内容为ServletContainerInitializer实现类的全路径,将它们实例化:
WebApplicationInitializer
当使用外置容器启动war包时,就需要配置一个SpringBootServletInitializer 来传入主类,从外部启动

// 扫描相关类WebApplicationInitializer
@HandlesTypes(WebApplicationInitializer.class)
public class SpringServletContainerInitializer implements ServletContainerInitializer {
// webAppInitializerClasses扫描结果
@Override
public void onStartup(Set<Class<?>> webAppInitializerClasses, ServletContext servletContext)
throws ServletException {
List<WebApplicationInitializer> initializers = new LinkedList<WebApplicationInitializer>();
if (webAppInitializerClasses != null) {
for (Class<?> waiClass : webAppInitializerClasses) {
if (!waiClass.isInterface() && !Modifier.isAbstract(waiClass.getModifiers()) &&
WebApplicationInitializer.class.isAssignableFrom(waiClass)) {
try {
initializers.add((WebApplicationInitializer) waiClass.newInstance());
}
catch (Throwable ex) {
throw new ServletException("Failed to instantiate WebApplicationInitializer class", ex);
}
}
}
}
servletContext.log(initializers.size() + " Spring WebApplicationInitializers detected on classpath");
AnnotationAwareOrderComparator.sort(initializers);
for (WebApplicationInitializer initializer : initializers) {
// 所有容器初始化器的onStartup方法
initializer.onStartup(servletContext);
}
}
}
ServletContextInitializer这是SpringBoot提供的一些机制,用于程序化、动态配置ServletContext中的接口。(注意:这些实现类Bean是Spring管理的,而非Servlet容器管理的)
18.1 容器内置容器如何启动:
1、在容器启动过程中 onRefresh() 调用子类的刷新方法时会启动内置web服务器
@Override
protected void onRefresh() {
super.onRefresh();
try {
// 内部会创建相关容器
createEmbeddedServletContainer();
}
catch (Throwable ex) {
throw new ApplicationContextException("Unable to start embedded container",
ex);
}
}
在容器启动时会添加WebServerFactoryCustomizerBeanPostProcessor 后置处理器 ,用于定制容器
// 调用定制化接口
private void postProcessBeforeInitialization(WebServerFactory webServerFactory) {
LambdaSafe.callbacks(WebServerFactoryCustomizer.class, getCustomizers(), webServerFactory)
.withLogger(WebServerFactoryCustomizerBeanPostProcessor.class)
.invoke((customizer) -> customizer.customize(webServerFactory));
}
18.2 如何定制servlet
- Servlet注解
@ServletComponentScan 注解后,使用 @WebServlet、
@WebFilter、@WebListener 标记的 Servlet、Filter、Listener 就可以自动注册到
- ServletRegistrationBean
@Bean
public ServletRegistrationBean servletRegistrationBean() {
return new ServletRegistrationBean(new HelloServlet(),"/hello");
}
- ServletContextInitializer 接口
@Component
public class MyServletRegister implements ServletContextInitializer {
@Override
public void onStartup(ServletContext servletContext) {
//Servlet 3.0 规范新的 API
ServletRegistration myServlet = servletContext
.addServlet("HelloServlet", HelloServlet.class);
myServlet.addMapping("/hello");
myServlet.setInitParameter("name", "Hello Servlet");
}
}
19 SpringBoot如何管理Session
19.1 session 是如何创建的
通常我们使用api的时候,是通过request.getSession() 方法获得session. 这个request 是被处理过的HttpServletRequest,因为处于安全考虑,tomcat将他包装成一个RequestFacade的方法来进行代理,获取。
内部创建逻辑:
Context context = getContext();
if (context == null) {
return null;
}
Manager manager = context.getManager();
if (manager == null) {
return null;
}
// 创建的session 会被放在一个currentHashMap当中
session = manager.createSession(sessionId);
session.access();
创建其实是由context中的manager进行创建。
19.2 Session的清理
通过Tomcat的后台子线程, ContainerBackgroundProcessor进行处理。调用过程如下:

@Override
public void backgroundProcess() {
if (!getState().isAvailable())
return;
Loader loader = getLoader();
if (loader != null) {
try {
loader.backgroundProcess();
} catch (Exception e) {
log.warn(sm.getString(
"standardContext.backgroundProcess.loader", loader), e);
}
}
Manager manager = getManager();
// 调用 StandardManager的backgroundProcess方法 session每 60秒执行一次
manager.backgroundProcess();
}
}

Servlet 规范中定义了 HttpServletRequest 和 HttpSession 接口,Tomcat 实现了这些接
口,但具体实现细节并没有暴露给开发者,因此定义了两个包装类,RequestFacade 和
StandardSessionFacade。
20 Tomcat 集群通讯组件原理
tomcat支持集群部署的能力,同时也带来了分布式系统通用的问题,多个节点保持数据的一致性问题,也就是CAP里面的 C一致性问题。
tomcat是通过组播来实现通信的。tomcat集群中的节点在启动时和运行时都会周期性(默认 500 毫秒)发送组播心跳包,同一个集
群内的节点都在相同的组播地址和端口监听这些信息;默认3秒不发送组播节点的,就被认为是崩溃的,会从集群列表中删除,集群中的每个成员都维护了一个集群列表。
参考
极客时间《深入拆解Tomcat&Jetty》
https://www.cnblogs.com/tanshaoshenghao/p/10932306.html tomcat源码启动分析
https://github.com/heroku/devcenter-embedded-tomcat 启动tomcat