一.BufferPool:
ByteBuffer的创建和释放时比较消耗资源的,为了实现内存的高效利用,Kafka客户端使用BufferPool来实现ByteBuffer的复用。核心字段如下:

每个BufferPool对象只针对特定大小(由poolableSize字段指定)的ByteBuffer进行管理,对于其他大小的ByteBuffer并不会缓存进BufferPool。一般情况下,我们会调整MemoryRecords的大小(RecordAccumulator.batchSize字段指定),使每个MemoryRecords可以缓存多条消息。但是当一条消息的字节数大于MemoryRecords时,就不会复用BufferPool中缓存的ByteBuffer,而是额外分配ByteBuffer,在它被使用完后也不会放到BufferPool进行管理,而是让GC回收。如果经常出现这种情况就要考虑调整batchSize的配置了。
下面介绍BufferPool的关键字段:
- free: 是一个Deque
队列,缓存了指定大小的ByteBuffer对象。 - lock:是一个ReentrantLock,因为会有多线程并发分配和回收ByteBuffer,所以使用锁控制并发,保证线程安全。
- waiters:记录因申请不到足够空间而阻塞的线程,此队列中实际记录的事阻塞线程对应的Condition对象。
- totalMemory:记录因申请不到足够空间而阻塞的线程,此队列中实际记录的事阻塞线程对应的Condition对象。
- availableMemory:记录可用空间的大小,这个空间是totalMemory-free列表中全部ByteBuffer的大小。
BufferPool.allocate()方法负责从缓冲池中申请ByteBuffer,当缓冲池中空间不足的时候,会阻塞调用线程。分析下allocate()申请空间的过程:
/**
* Allocate a buffer of the given size. This method blocks if there is not enough memory and the buffer pool
* is configured with blocking mode.
*
* @param size The buffer size to allocate in bytes
* @param maxTimeToBlockMs The maximum time in milliseconds to block for buffer memory to be available
* @return The buffer
* @throws InterruptedException If the thread is interrupted while blocked
* @throws IllegalArgumentException if size is larger than the total memory controlled by the pool (and hence we would block
* forever)
*/
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
this.lock.lock();//加锁同步
try {
// check if we have a free buffer of the right size pooled
// 请求的是poolableSize指定大小的ByteBuffer,且free中有空闲的ByteBuffer
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();//返回合适的ByteBuffer
// now check if the request is immediately satisfiable with the
// memory on hand or if we need to block
// 当申请的不是poolableSize,则执行下面的处理
//free队列中都是poolableSize大小的ByteBuffer,可以直接计算整个free队列的空间
int freeListSize = this.free.size() * this.poolableSize;
if (this.availableMemory + freeListSize >= size) {
// we have enough unallocated or pooled memory to immediately
// satisfy the request
//为了让availableMemory>size,freeUp()方法会从free队列中不断释放
//ByteBuffer,直到availableMemory满足这次申请。
freeUp(size);
this.availableMemory -= size;//减少availableMemory
lock.unlock();//解锁
//这里并没有使用free队列的buffer,而是直接分配size大小的HeapByteBuffer
return ByteBuffer.allocate(size);
} else {
// we are out of memory and will have to block
//没有空间了,只能阻塞了
int accumulated = 0;
ByteBuffer buffer = null;
Condition moreMemory = this.lock.newCondition();
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory);//将Condition添加到waiters中
// loop over and over until we have a buffer or have reserved
// enough memory to allocate one
while (accumulated < size) {//循环等待
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);//阻塞
} catch (InterruptedException e) {
//异常,移除此线程对应的Condition
this.waiters.remove(moreMemory);
throw e;
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
this.waitTime.record(timeNs, time.milliseconds());
}
if (waitingTimeElapsed) {//超时,报错
this.waiters.remove(moreMemory);
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
//请求的是poolableSize大小的ByteBuffer,且free中有空闲的ByteBuffer
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// just grab a buffer from the free list
buffer = this.free.pollFirst();
accumulated = size;
} else {//分配一部分,并继续等待空闲空间
// we'll need to allocate memory, but we may only get
// part of what we need on this iteration
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.availableMemory);
this.availableMemory -= got;
accumulated += got;
}
}
// 分配到空间了,移除condition
// remove the condition for this thread to let the next thread
// in line start getting memory
Condition removed = this.waiters.removeFirst();
if (removed != moreMemory)
throw new IllegalStateException("Wrong condition: this shouldn't happen.");
// signal any additional waiters if there is more memory left
// over for them
if (this.availableMemory > 0 || !this.free.isEmpty()) {
if (!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
}
// unlock and return the buffer
lock.unlock();//解锁
if (buffer == null)
return ByteBuffer.allocate(size);
else
return buffer;
}
} finally {
if (lock.isHeldByCurrentThread())
lock.unlock();
}
}
继续分析deallocate()方法:
/**
* Return buffers to the pool. If they are of the poolable size add them to the free list, otherwise just mark the
* memory as free.
*
* @param buffer The buffer to return
* @param size The size of the buffer to mark as deallocated, note that this maybe smaller than buffer.capacity
* since the buffer may re-allocate itself during in-place compression
*/
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();//加锁同步
try {
//释放的ByteBuffer的大小是poolableSize,放入free队列中进行管理
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
//释放的ByteBuffer大小不是poolableSize,不会复用ByteBuffer,仅仅修改availableMemory的值
this.availableMemory += size;
}
//唤醒一个因空间不足而阻塞的线程
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();//解锁
}
}
二.RecordAccumulator
分析完MemoryRecords,RecordBatch以及BufferPool,再来看RecordAccumulator:
主要的field分析:
batches:TopicPartition与RecordBatch集合的映射关系,类型是CopyOnWriteMap,是个线程安全的集合,但是其中的Deque是ArrayDeque类型,是非线程安全的集合。所以追加新消息或发送RecordBatch的时候,需要同步加锁。
每个Deque中都保存了发往对应TopicPartition的RecordBatch集合。batchSize:指定每个RecordBatch底层ByteBuffer的大小。
Compression:压缩类型。
incomplete: 未发送完成的RecordBatch集合,低层通过Set
集合实现。 free:BufferPool对象。
drainIndex:使用drain方法批量导出RecordBatch时,为了防止饥饿,使用drainIndex记录上次发送停止时的位置,下次继续从此位置开始发送。
KafkaProducer.send()方法会调用RecordAccumulator.append()方法将消息追加到RecordAccumulator中,主要逻辑如下:
1.在batches集合中查找TopicPartition对应的Deque,查找不到,则创建新的Deque,并添加到batches集合中。
2.用synchronized对Deque加锁。
3.调用tryAppend()方法,尝试向Deque中最后一个RecordBatch追加Record。
4.追加成功,则返回RecordAppendResult(封装了ProducerRequestResult)
5.synchronized结束,解锁。
6.追加失败,尝试从BufferPool中申请新的ByteBuffer。
7.使用synchronized对Deque加锁。
8.追加成功,则返回;失败,则用第6步得到的ByteBuffer创建RecordBatch。
9.将Record追加到新建的RecordBatch中,并将新建的RecordBatch追加到Deque的尾部。
10.将新建的RecordBatch追加到incomplete集合。
11.synchronized解锁。
12.返回RecordAppendResult,RecordAppendResult会作为唤醒Sender线程的条件。
/**
* Add a record to the accumulator, return the append result
*
* The append result will contain the future metadata, and flag for whether the appended batch is full or a new batch is created
*
*
* @param tp The topic/partition to which this record is being sent
* @param timestamp The timestamp of the record
* @param key The key for the record
* @param value The value for the record
* @param callback The user-supplied callback to execute when the request is complete
* @param maxTimeToBlock The maximum time in milliseconds to block for buffer memory to be available
*/
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
try {
// check if we have an in-progress batch
//1.查找TopicPartition对应的Deque
Deque dq = getOrCreateDeque(tp);
synchronized (dq) {//2.对Deque加锁
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
//3.向Deque中最后一个RecordBatch追加Record
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null)
return appendResult;//4.追加成功返回
}//5.解锁
// we don't have an in-progress record batch try to allocate a new batch
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
//6.追加失败,从BufferPool中申请新空间。
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
//7.对Deque加锁后,再次调用tryAppend()方法尝试追加Record
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
//8.追加成功,则返回,释放步骤7申请的新空间
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return appendResult;
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
//9.在新创建的RecordBatch中追加Record,并将其添加到Batches集合中
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
//10.新创建的RecordBatch中追加到incomplete集合。
incomplete.add(batch);
//11.返回RecordAppendResult
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}//12.解锁
} finally {
appendsInProgress.decrementAndGet();
}
}
RecordAccumulator.tryAppend()方法会查找batches集合中对应队列的最后一个RecordBatch对象,并调用其tryAppend()完成消息追加。
- 第2步和第7步对Deque加synchronized锁然后重试的原因?
这里的Deque使用的是ArrayDeque(非线程安全),所以需要加锁同步。 - 为什么分多个synchronized块而不是一个完整的synchronized块中完成呢?
目的:提升吞吐量
因为向BufferPool申请新ByteBuffer的时候,可能会导致阻塞。我们假设在一个synchronized块中完成所有的追加操作。假设场景:线程1发送的消息比较大,需要向BufferPool申请新的空间,而此时BufferPool空间不足,线程1在BufferPool上等待,此时线程1依然持有相应的Deque的锁;线程2发送的消息较小,Deque最后一个RecordBatch剩余空间够用,但是线程1没释放Deque的锁,线程2也要等待,如果类似线程2的线程很多,就造成很多不必要的线程阻塞,降低了吞吐量。这里体现了“减少锁的持有时间”的优化手段。 -
为什么第二次加锁后重试,就是第7步调用了tryAppend()方法?
目的:避免内存碎片的出现。
如下场景(如果第二次加锁没调用tryAppend()):
线程1发现最后一个RecordBatch空间不够用,申请空间并创建一个新的RecordBatch对象添加到Deque尾部;线程2和线程1并发执行,也将新创建一个RecordBatch对象添加到Deque尾部。根据上面逻辑知道,之后添加操作只会在Deque尾部进行,这就会是如下场景,RecordBatch4不再被使用,这就出现了内部碎片。如下图所示:
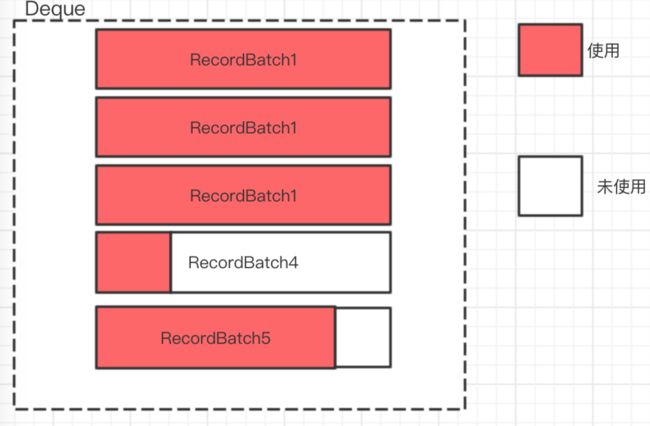 内部碎片
内部碎片
回到KafkaProducer.doSend()方法,doSend()方法的最后一步是判断此次向RecordAccumulator中追加消息后是否满足唤醒Sender线程条件,这里唤醒Sender线程的条件是消息所在队列的最后一个RecordBatch满了或此队列不止一个RecordBatch。
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
在客户端将消息发送给服务端之前,会调用RecordAccumulator.ready()方法获得集群中符合发送消息条件的节点集合。这些条件是站在RecordAccumulator角度对集群中的Node进行删选的,具体条件如下:
1.Deque中有多个RecordBatch或是的第一个RecordBatch是否满了。
2.是否超时了。
3.是否有其他线程在等待BufferPool释放空间(即BufferPool的空间耗尽了)。
4.是否有线程正在等待flush操作完成。
5.Sender线程准备关闭。
看下RecordAccumulator.ready()方法,它会遍历集合中每个分区,先查找当前分区Leader副本所在的Node,如果满足上述5个条件,就把此Node信息记录到readyNodes集合中。遍历完成后返回ReadyCheckResult对象,记录了:
- 满足发送条件的Node集合。
- 在遍历过程中是否有找不到Leader副本的分区(可以认为Metadata中当前的元数据过时了)。
- 下次调用ready()方法进行检查的时间间隔。
/**
* Get a list of nodes whose partitions are ready to be sent, and the earliest time at which any non-sendable
* partition will be ready; Also return the flag for whether there are any unknown leaders for the accumulated
* partition batches.
*
* A destination node is ready to send data if:
*
* - There is at least one partition that is not backing off its send
*
- and those partitions are not muted (to prevent reordering if
* {@value org.apache.kafka.clients.producer.ProducerConfig#MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION}
* is set to one)
* - and any of the following are true
*
* - The record set is full
* - The record set has sat in the accumulator for at least lingerMs milliseconds
* - The accumulator is out of memory and threads are blocking waiting for data (in this case all partitions
* are immediately considered ready).
* - The accumulator has been closed
*
*
*/
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
//用来记录可以向哪些Node节点发送信息
Set readyNodes = new HashSet<>();
//记录下次需要调用ready的时间间隔
long nextReadyCheckDelayMs = Long.MAX_VALUE;
//根据Metadata元数据中是否有找不到Leader副本的分区
boolean unknownLeadersExist = false;
//是否有线程在阻塞等待BufferPool释放空间
boolean exhausted = this.free.queued() > 0;
//下面遍历batches集合,对其中每个分区的Leader副本所在的Node都进行判断
for (Map.Entry> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque deque = entry.getValue();
//查找分区的Leader副本所在的Node
Node leader = cluster.leaderFor(part);
//找不到Leader副本所在的Node,不能发送信息
if (leader == null) {
//unknownLeadersExist = true,会触发MetaData更新。
unknownLeadersExist = true;
} else if (!readyNodes.contains(leader) && !muted.contains(part)) {
synchronized (deque) {//加锁读取deque中的元素。
//读取deque中的第一个RecordBatch
RecordBatch batch = deque.peekFirst();
if (batch != null) {
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
long waitedTimeMs = nowMs - batch.lastAttemptMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
boolean full = deque.size() > 1 || batch.records.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
//是否是符合发送消息的节点的5个条件
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough
// since we'll just wake up and then sleep again for the remaining time.
//记录下次需要调用ready()方法检查的时间间隔
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeadersExist);
}
调用RecordAccumulator.ready()方法得到readyNodes集合后,这个集合还是要经过NetworkClient的过滤之后,才能最终得到发送消息的Node集合。
然后Sender会调用RecordAccumulator.drain()方法,这个方法会根据上述的Node集合获取要发送的消息,返回Map
RecordAccumulator.drain()方法的作用是映射转换,将RecordAccumulator记录的TopicPartition->RecordBatch集合的映射,转换成了NodeId->RecordBatch集合映射。为什么要转换?
因为在网络I/O层面,生产者是面向Node节点发送消息数据,不关心这些数据属于哪个TopicPartition;但是在KafkaProducer的业务逻辑层,则是按TopicPartition生成数据,只会关心发送到哪个TopicPartition,不会关心TopicPartition在哪个Node上。Sender线程每次向每个Node节点最多发一个ClientRequest请求,其中封装了追加到此Node节点上多个分区信息,请求到服务端后,由Kafka服务端进行解析。
/**
* Drain all the data for the given nodes and collate them into a list of batches that will fit within the specified
* size on a per-node basis. This method attempts to avoid choosing the same topic-node over and over.
*
* @param cluster The current cluster metadata
* @param nodes The list of node to drain
* @param maxSize The maximum number of bytes to drain
* @param now The current unix time in milliseconds
* @return A list of {@link RecordBatch} for each node specified with total size less than the requested maxSize.
*/
public Map> drain(Cluster cluster,
Set nodes,
int maxSize,
long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
//转换后的结果
Map> batches = new HashMap<>();
for (Node node : nodes) {//遍历指定的ready Node集合
int size = 0;
//获取当前Node上的分区集合
List parts = cluster.partitionsForNode(node.id());
// 记录要发送的RecordBatch
List ready = new ArrayList<>();
/*
drainIndex是batches的下标,记录上次发送停止的位置,下次继续从这个位置发送
如果一直从索引0的队列开始发送,可能会出现一直只发送前几个分区的消息的情况,造成其它分区饥饿。
to make starvation less likely this loop doesn't start at 0
*/
int start = drainIndex = drainIndex % parts.size();
do {
//获取分区信息
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
// Only proceed if the partition has no in-flight batches.
if (!muted.contains(tp)) {
//找到tp对应的deque
Deque deque = getDeque(new TopicPartition(part.topic(), part.partition()));
if (deque != null) {
synchronized (deque) {
RecordBatch first = deque.peekFirst();//获取第一个RecordBatch。
if (first != null) {
boolean backoff = first.attempts > 0 && first.lastAttemptMs + retryBackoffMs > now;
// Only drain the batch if it is not during backoff period.
if (!backoff) {
if (size + first.records.sizeInBytes() > maxSize && !ready.isEmpty()) {
// there is a rare case that a single batch size is larger than the request size due
// to compression; in this case we will still eventually send this batch in a single
// request
break;
} else {
//从队列中获取一个 RecordBatch,并将这个RecordBatch放到ready集合中。
//每个deque只取一个RecordBatch。
RecordBatch batch = deque.pollFirst();
batch.records.close();//关闭Compressor及底层输出流,并将MemoryRecords设置为只读。
size += batch.records.sizeInBytes();
ready.add(batch);
batch.drainedMs = now;
}
}
}
}
}
}
//增加drainIndex
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex);
batches.put(node.id(), ready);//记录NodeId与RecordBatch的对应关系
}
return batches;
}
通过drainIndex的累加保证防止饥饿的发生。
这样整个KafkaProducer.send()方法过程中用到的所有组件介绍完毕,下面几节介绍Sender线程是如何发送消息的。