这篇文章大多是我自己的基于iOS开发一个想法过程,实现并不难。不过我并不会贴出全部代码,天知道我组织文章的根据是什么,能看懂都是缘分。
前言
讨论缓存时,都会分内存缓存和硬盘缓存,本文主要是基于内存缓存的,但是完全可以稍加改动便可以应用于硬盘缓存中。在做其他文件IO的时,会有很多情况会基于C。基于此,我选择了使用C来实现核心部分。而它的作用是主要用于WebView在内存中的缓存数据。
关于LFU的一些概念之类的东西就不说了,原理实现网上一大堆。基于自己单链表通过栈来实现LFU的方式实现一下,这不一定是最优解,也有可能是最差解。不管怎么说,先通过一个图阐述一下主要的数据结构:

多想一点儿东西
在看了上图之后,首先的想法就是去把具体算法撸出来。但是在开动写代码之前,我们需要想的东西应该要更多。在面向过程的思想中想开来,使用栈的时候取出操作可以很快速的完成最快可以达到时间复杂度为O(1),而在维护栈顺序的时候,最坏的时间复杂度为O(N),其查找和位置更新是在同一个循环中完成的,避免了不必要的时间消耗。
加入到面向对象中
显然用C来做业务逻辑开发始终有点儿蹩脚,所以得引入到面向对象中。我把这个类取名叫做PPWebFetchCache吧,既然都面向对象了,要不再弄点儿设计模式进去?考虑到易于操作性,对于PPWebFetchCache类,我做了一个单例,当然也可以自己生成一个对象。到了这里下面应该要想的就是对象的属性和操作方法等等事情,但是自己想着就用了一个单例模式这不是表明我设计模式很low吗?不过事实的确是这样,我没有什么好的设计模式拿出来~~~
所以我就硬塞了一个简单工厂模式进去。它做什么呢?我想的是“现在只是做LFU,万一哪一天变化来了,让我用写一个LRU的缓存策略,那我不是死得很惨!”,所以我又创建了一个继承于PPWebFetchCache类的PPWebFetchLFUCache,和另一个用于将来实现LRU算法的PPWebFetchLRUCache类。并在最后给父类添加了属性maxMemoryCost、maxMemoryCountLimit和两个操作方法storeCacheInMemory、memoryCacheWithURL。
走进实现细节
上面说的LFU是针对于某一个URL的使用次数。在思考如何使用最少时间拿到URL对应的数据时,显然散列表最理想的数据结构,而且在iOS中用散列表实现的代表便是Dictionary。所以大致的逻辑是:
使用NSDictionary来实现URL和数据一对一在内存中的存储。而LFU主要用于管理某一URL的使用次数,淘汰掉使用次数最少的URL,并在内存字典中删除对应的数据。
PPWebFetchCache对外暴露的接口只有存和取,而具体的加入和删除操作则是在内部通过maxMemoryCost、maxMemoryCountLimit控制实现。
异步环境
显然在数据存取的时候,我们不应该放在主线程中去做这些事儿。因此我创建串行队列用来执行这些事务:
static dispatch_queue_t background_serialQueue(){
static dispatch_queue_t queue;
if (!queue) {
char *const label = "com.example.webprefetchCache";
dispatch_queue_attr_t attr = dispatch_queue_attr_make_with_qos_class(DISPATCH_QUEUE_SERIAL, QOS_CLASS_USER_INITIATED, 0);
queue = dispatch_queue_create(label, attr);
}
return queue;
}
void async_inbackground(void(^block)(void)){
dispatch_async(background_serialQueue(), block);
}
为什么要用串行队列?因为在队列内部操作,我不需要关心会出现资源竞争的问题。而在串行队列以外其他队列中来操作单例的相关数据时,我就需要去关心的线程安全的问题。因此我直接使用适用于静态分配的的互斥量PTHREAD_MUTEX_INITIALIZER来保证数据的同步操作。反观如果我去使用pthread_mutex_init来动态生成一个互斥量的话,我还要操心什么时候去destroy掉它(当然这里得仔细思考造成死锁的问题)。
static inline pthread_mutex_t mutext_lock(void){
static pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
return lock;
}
static void safeProgressWith(void(^block)(void)){
pthread_mutex_t lock = mutext_lock();
pthread_mutex_lock(&lock);
block();
pthread_mutex_unlock(&lock);
}
在加锁等操作时,尽量让其颗粒度更低。这样可以减少不必要的线程处于waiting状态,也就相应地减少出现低优先级线程饿死的情况发生(尽量减少CPU密集型线程的时间片)。
LFU的具体实现
LFU只是针对于URL的淘汰策略,淘汰了URL之后,根据该URL到NSDictionary中找出对应的数据进行移除。这里使用链表的方式实现栈结构,其结构如下:
typedef struct __PPWebLFUFetchInlayerNode_ * _PPWebLFUInlayerNodeRef;
typedef struct __PPWebLFUFetchInlayerNode_ {
char *url;
int use_count;
_PPWebLFUInlayerNodeRef next;
}_PPWebLFUFetchInlayerNode;
在PPWebFetchLFUCache类中保存了一个_PPWebLFUInlayerNodeRef的指针,这个指针指向栈顶:
@interface PPWebFetchLFUCache:PPWebFetchCache{
_PPWebLFUInlayerNodeRef _lfuStack;
}
走到这里我们大可以直接使用_lfuStack成员变量来对栈进行相应的操作,但是我们可以更进一步!这里思维跳跃一下,当我们在插入一个节点时如何去判断当前节点是新增节点、还是存在于栈中的节点、抑或是需要删除的结点?
如果只是简单的回答“我在插入节点时,先遍历一遍栈看元素是否存在于其中”,这样做毫无意义,而且平添一倍的时间消耗,因为后面的插入操作时,还要去遍历一次找到对应的节点位置。
为了能够更好地在同一个循环中处理插入数据,查找数据,删除数据等操作。这里需要在执行C操作时在适当地点给我们回调,让我们有机会在一次循环中做完这些操作。为什么要用回调呢?我们完全可以把删除的相关逻辑放在某一次循环中,这样就需要我们在调用逻辑时传入一些判断条件。这无疑是增加了算法的局限性,从另一点来说,这个算法的适用范围就大大降低了。
所以我引入了一个上下文环境,这个环境主要用于包裹相关信息数据和函数指针回调:
typedef struct __PPWebLFUFetchCacheContext *PPWebLFUFetchCacheContextRef;
typedef struct __PPWebLFUFetchCacheContext {
_PPWebLFUInlayerNodeRef *node;/// root
void *info;/// 一般传入fetchCacher对象
void (*appendInStackRootCallback)(void *info, char *const key);/// 栈顶插入回调
void (*appendInStackBottomCallback)(void *info, char *const key);/// 栈底插入回调
void (*appendInStackCallback)(void *info, char *const key);/// 栈中插入回调
}PPWebLFUFetchCacheContext;
/// 调用这个方法之后,如果不再需要使用这个指针,需要调用free来释放内存空间
PPWebLFUFetchCacheContextRef PPWebLFUFetchCacheContextCreate(void *root,
void *info,
void (* _Nonnull appendInStackRootCallback)(void *info, char *const key),
void (* _Nonnull appendInStackBottomCallback)(void *info, char *const key),
void (* _Nonnull appendInStackCallback)(void *info, char *const key)){
PPWebLFUFetchCacheContextRef ctx = (PPWebLFUFetchCacheContextRef)malloc(sizeof(PPWebLFUFetchCacheContext));
ctx->node = root;
ctx->info = info;
ctx->appendInStackRootCallback = appendInStackRootCallback;
ctx->appendInStackBottomCallback = appendInStackBottomCallback;
ctx->appendInStackCallback = appendInStackCallback;
return ctx;
}
至于这里为什么选择一个上下文?当我们需要多个回调时,完全没有必要把每一个回调都添加到函数参数中去,我们可以把这些参数包装起来。而且这样包装起来做还有一个优势,就是新增回调场景时就要方便许多!
元素添加
现在所有的条件都已具备,是时候来处理这些具体的逻辑了。就像是在学红黑树的时候一般都会把它那5个特性先提出来是吧。所以这里需要明确几点特性:
- 1、由链表实现的一个栈,只有一个根节点(上面提到的,包装在上下文中的lfustack);
- 2、栈的深度是有限制的;
- 3、添加和删除操作是基于栈顶;
- 4、栈内元素的使用次数是从小到大,从上到下生长;

基于以上,我定义了一个元素添加函数的原型:
bool _PPWebFetchLFUInlayerQueueAdd(PPWebLFUFetchCacheContextRef context,char *const url)
很明显传入的context是需要在外面创建好的一个指针变量,但是context的具体成员变量我们没有控制,全部传入NULL都可以(因为懒,不想对函数指针做非空判断,所以我把函数指针设置为_Nonnull。。。),这没有什么问题。因此首先要做的就是判断栈是否为空:
if (!(*(context->node))) {/// 创建栈顶指针
_PPWebLFUInlayerNodeRef node = allocNewNode(url);
if (!node) {
return false;
}
__block _PPWebLFUInlayerNodeRef *_broot = (context->node);
safeProgressWith(^{
*_broot = node;
(context->appendInStackRootCallback)(context->info,url);
});
return true;
}
在上面这段代码中我们使用了context的一个函数指针回调,当在空栈中加入根节点,这是符合该函数指针回调语义的。
此时的栈分布情况很简单,但还是画出来更加明显:

在这之后插入结点时,我们便需要考虑新添加进来的URL是新节点还是在原有节点上增加使用次数。这里我们需要一个循环从根节点开始遍历栈,如果找到了对应的URL,便将其使用次数加一,如果走到栈底还是未能命中对应的URL,则需要以该URL为数据创建一个新节点,并将这个节点作为栈根。实现代码如下:
if (0 == strcmp(lead->url, url)) {
(context->node)->use_count++;
}else{
(context->appendInStackRootCallback)(context->info,url);
return appendRootNodeInStack((context->node), url);
}
上面涉及到的函数appendRootNodeInStack主要用于生成一个节点之后,并将该节点设置为根:
bool appendRootNodeInStack(_PPWebLFUInlayerNodeRef *root ,char *const url){
/// 在栈顶插入
_PPWebLFUInlayerNodeRef node = allocNewNode(url);
if (!node) {
return false;
}
__block _PPWebLFUInlayerNodeRef *_broot = root;
safeProgressWith(^{
node->next = *_broot;
*_broot = node;
});
return true;
}
所以现在会出现两种情况,如下所示:

这段逻辑代码目前并没有放在循环中来做,它和栈中已经存在四个、五个节点的情况是类似的,但它的情况要简单许多,它只需要处理使用次数更新或者头节点插入的情况,不会涉及到删除(除非你不做缓存)、移位操作。到最后我会把这段代码合并起来,而那正是我设计这套算法的中心思想。
节点移动和删除
针对节点的移动,需要考虑多个情况,包括:从栈顶移动到栈底、从栈顶移动到栈中某一个位置、从栈中某一个位置移动到栈中另一个位置、从栈中某一个位置移动到栈底、不移动。
我把这些情况依次描述到图中,这样看着更直观:
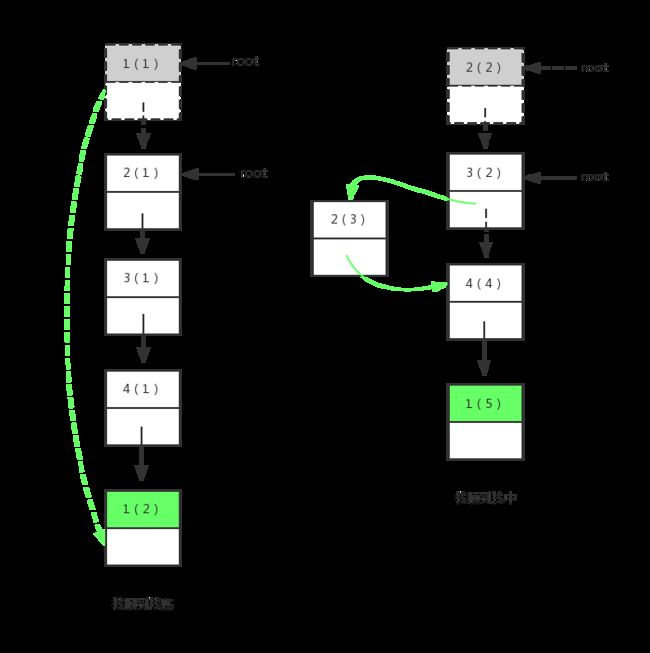
下面是后面两种情况:
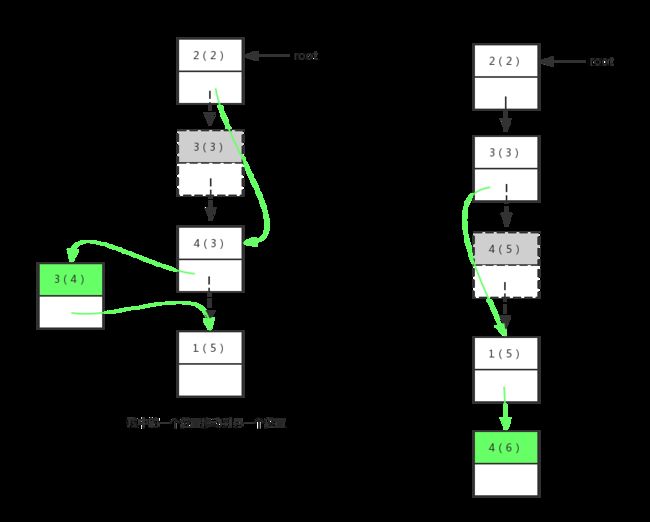
从上面虚线箭头到实线箭头的变化可以很明显看出来,是复杂了不少。而最后一种无变化的,我就没有列出来。看看前面四种情况变化后的栈元素排列情况,从左到右,从上到下依次是:
- 2->3->4->1;
- 3->2->4->1;
- 2->4->3->1;
- 2->3->1->4;
从上面四种情况来看,对于一个节点的移动可以分为两部拆开来看,分别是——取出、放入两个过程。我直接把中间的的算法列出来:
_PPWebLFUInlayerNodeRef previous = lead;
_PPWebLFUInlayerNodeRef pivot = NULL;
_PPWebLFUInlayerNodeRef prepivot = NULL;
do {
if (0 != strcmp(lead->url, url)) {
if (!pivot) {
continue;
}
if (pivot->use_count <= lead->use_count) {
break;/// 跳出循环去执行放入
}
if (*(context->node)==pivot) {
__block _PPWebLFUInlayerNodeRef *_broot = (context->node);
safeProgressWith(^{
*_broot = previous->next;
});
}else{/// 取出
prepivot->next=pivot->next;
}
continue;
}
lead->use_count++;
pivot = lead;
prepivot = previous;
} while ((void)(previous=lead),(void)(lead=lead->next),lead);
if (!pivot) {/// 在栈顶插入
(context->appendInStackRootCallback)(context->info,url);
return appendRootNodeInStack((context->node), url);
}
if (!lead) {/// 处理栈底情况
previous->next=pivot;
pivot->next=NULL;
(context->appendInStackBottomCallback)(context->info,url);
}else{/// 处理栈中的放入
pivot->next=previous->next;
previous->next=previous==pivot?lead:pivot;
(context->appendInStackCallback)(context->info,url);
}
这段代码把上面提到的if-else判断也一起合并进来了,这里pivot主要是用来记录找到目标URL的哨兵,而prepivot用来记录哨兵前面一个节点(如果使用双向链表完全可以不用这个零时变量)。
到这里基本上是把该算法的核心部分说完了,该算法的最坏时间复杂度就是O(N),这种最坏时间复杂度的情况分别是:新节点插入,栈顶一次直接移动栈底(这个情况是发生在使用次数都为1时,栈顶元素此时+1的情况)。最优的时间复杂度情况是O(1),直接栈顶数据更新。
最后就是节点的删除操作,仅仅只是删除操作时间复杂度肯定是O(1)的。但是事情往往没有这么简单,必须要考虑当前添加进来的元素是到达容量限制的新元素,还是栈里面已经存在的元素呢?难道我们又要去遍历一次栈然后来做删除操作吗?这是完全没有必要的,因为要出现删除节点的情况,肯定是发生在向栈中Push元素时发生。
因此我将上面各个情况分为三种大体情况,并为这三种情况提供了三个回调,而这个三个回调都是放在上面的context中:
- 在栈顶插入元素(appendInStackRootCallback);
- 处理栈底情况(appendInStackBottomCallback);
- 处理中间节点(appendInStackCallback);
基于这:
我们可以一次循环中完成新增、移动、删除操作!
上面提到的三个回调,可以通过调用PPWebFetchLFUCache实例方法来看一下一个整体过程:
- (BOOL)insertCacheMap:(NSData *)object forKey:(NSString *)key{
PPWebLFUFetchCacheContextRef ctx = PPWebLFUFetchCacheContextCreate(
&_lfuStack,
(__bridge void *)(self),
&progressingAppendInStackRootCallback,
&progressingAppendInStackBottomCallback,
&progressingAppendInStackCallback);
bool result = _PPWebFetchLFUInlayerQueueAdd(ctx, (char *)[key UTF8String]);
if (result == false) {
PPWebLFUFetchCacheContextRelease(&ctx);
return NO;
}
if (![self.cacheMap.allKeys containsObject:key]) {
safeProgressWith(^{
[self.cacheMap setObject:object forKey:key];
self.currentCacheUsage += object.length;
});
}
PPWebLFUFetchCacheContextRelease(&ctx);
return YES;
}
在上面创建上下文的代码中,第一个参数为保存在PPWebFetchLFUCache单例中的一个成员变量,而info参数主要用来传递self,这里用context时,_lfuStack会被context保留,而_lfuStack又会被PPWebFetchLFUCache单例保留,但是在函数返回之前会对context做release操作,会把对_lfuStack的保留置空,所以不要想着OC里面常出现的引用计数不会降为0的问题。而且也不会出现相互持有的关系。
而回调函数中,主要来看progressingAppendInStackRootCallback的回调:
void progressingAppendInStackRootCallback(void *info, char *const key){
PPWebFetchLFUCache *cacher = (__bridge PPWebFetchLFUCache *)(info);
if (!cacher) {
return;
}
if (cacher.cacheMap.allKeys.count >= kMaxMemoryCountLimit) {
[cacher deleteCacheMap];
progressingAppendInStackRootCallback(info, key);
}else{
return;
}
}
下面我直接把删除函数贴出来,这并没有什么难点:
_PPWebLFUInlayerNodeRef _PPWebFetchLFUInlayerQueueDelete(PPWebLFUFetchCacheContextRef context ,char **url){
if (!(context->node)) {
return NULL;
}
_PPWebLFUInlayerNodeRef lead = NULL;
lead = *(context->node);
__block _PPWebLFUInlayerNodeRef *_broot = (context->node);
if ((*_broot)->next) {
safeProgressWith(^{
*_broot = (*_broot)->next;
});
}
if (url) {
(*url) = (lead->url);
}
return lead;
}
上面出现的deleteCacheMap方法中会把不再使用的节点free掉。
后语
上面代码中很多地方都用到了safeProgressWith函数,其实现也在上面列出来了。使用它的目的有两个:
第一个、PPWebFetchLFUCache类的操作是可以在多线程异步环境下操作的,所以我必须要保证cacheMap的数据同步;
第二个、虽然基于C的操作我都是放在一个串行的队列中进行:
async_inbackground(^{
BOOL result = [self insertCacheMap:data forKey:url];
if (complete) {
complete(result);
}
});
但是_lfuStack成员变量是可以通过hook的方法拿到,并让其在异步环境下去进行修改,这个我没法去控制,但是我要做到在LFU内做到一个同步操作,所以基于跟节点的操作都是在加锁状态下完成的。这里需要注意的就是不要出现互斥锁的嵌套使用,如果使用的是同一个锁变量的话,那肯定会造成死锁的。
完。。。