一、写在前面的话
看完Stephen Merity的这篇论文,最强烈的念头是我也好想这样写论文。通篇博客式写法,大版篇幅在发牢骚,最后真的只是粗略看完,就滚去看代码了。大神的代码注释里写满了尝试过程,老实说,非常推荐读下源码,看看大神在写代码时尝试与优化的思路。
回归正题,这篇论文算是工程实践类型的论文,本质上创新点并不足,从源码上看,大神在优化和调参上应该下了不少功夫,有一定的借鉴意义。
二、SHARNN网络结构

SHARNN主要可以分成三部分:残差RNN层、单头自注意力层和Boom层
2.1 残差RNN层
if self.rnn:
x, new_hidden = self.rnn(h, None if hidden is None else hidden)
#x = self.rnn_down(self.drop(x))
# Trim the end off if the size is different
ninp = h.shape[-1]
z = torch.narrow(x, -1, 0, x.shape[-1] // ninp * ninp)
# Divide the hidden size evenly into chunks
z = x.view(*x.shape[:-1], x.shape[-1] // ninp, ninp)
# Collapse the chunks through summation
#h = h + self.drop(x).sum(dim=-2)
x = self.drop(z).sum(dim=-2)
#x = x + z.sum(dim=-2)
h = h + x if self.residual else x.float()
这一部分中间的一段操作主要是为了应对双向时的处理,只有单向时并不影响,也就是说,这一部分代码的核心就是输入经过RNN之后,加上dropout,再使用一次残差结构。
2.2 单头自注意力层
def attention(query, key, value, attn_mask=None, need_weights=True, dropout=None):
# https://pytorchnlp.readthedocs.io/en/latest/_modules/torchnlp/nn/attention.html
# Needs [batch, heads, seqlen, hid]
batch_size, heads, query_len, dim = query.size()
key_len = key.size(2)
# Scaling by dim due to http://nlp.seas.harvard.edu/2018/04/03/attention.html
attention_scores = torch.matmul(query, key.transpose(-1, -2).contiguous()) / math.sqrt(dim)
if attn_mask is not None:
attn_mask = attn_mask.view(1, 1, *attn_mask.shape[-2:])
attention_scores = attention_scores + attn_mask # Mask is additive and contains -Infs
attention_weights = F.softmax(attention_scores, dim=-1)
if dropout:
attention_weights = dropout(attention_weights)
attention_weights = attention_weights.view(batch_size, heads, query_len, key_len)
mix = torch.matmul(attention_weights, value)
return mix, attention_weights

上面的代码是自注意力计算的代码,没啥好说的,就是正常的自注意力机制,有趣的是源码在Q、K、V的处理:
qs, ks, vs = torch.sigmoid(self.qs), torch.sigmoid(self.ks), torch.sigmoid(self.vs)
#qs, ks, vs = self.qs, self.ks, self.vs
#vs = torch.tanh(self.vs)
if self.vq:
#vs, _ = self.vq(vs)
vs = self.vq(vs)
#qs, ks, vs = [x.reshape((1, 1, -1)) for x in self.vq(torch.sigmoid(self.qkvs))[0, :]]
elif self.vq_collapsed:
vs = self.vs
#qs, ks, vs = self.qs, self.ks, self.vs
#q = qs * query
#if self.q: query = self.q(query)
if self.q:
query = self.q(query)
query = self.qln(query.float())
if self.k: key = self.k(key)
if self.v: value = self.v(value)
# This essentially scales everything to zero to begin with and then learns from there
#q, k, v = self.qs * query, self.ks * key, self.vs * value
q, k, v = qs * query, ks * key, vs * value
#q, k, v = query, key, vs * value
#q, k, v = qs * query, ks * key, value
#k, v = ks * key, vs * value
#q, k, v = query, key, value
if self.drop:
# We won't apply dropout to v as we can let the caller decide if dropout should be applied to the output
# Applying dropout to q is equivalent to the same mask on k as they're "zipped"
#q, k, v = self.drop(q), k, v
q, k, v = self.drop(q), k, self.drop(v)
original_q = q
if not batch_first:
q, k, v = q.transpose(0, 1), k.transpose(0, 1), v.transpose(0, 1)
batch_size, query_len, nhid = q.size()
assert nhid == self.nhid
key_len = k.size(1)
###
dim = self.nhid // self.heads
q = q.view(batch_size, query_len, self.heads, dim).transpose(1, 2)
k, v = [vec.view(batch_size, key_len, self.heads, dim).transpose(1, 2) for vec in [k, v]]
mix, focus = attention(q, k, v, dropout=self.drop, attn_mask=attn_mask, **kwargs)
mix = mix.transpose(1, 2).contiguous().view(batch_size, -1, self.nhid)
if not batch_first:
mix = mix.transpose(0, 1)
哈哈,满满的尝试,贼像每次默默调参的自己。这边先是对 都使用了一个sigmoid函数, 是可训练的参数。另外 都是一个全连接层,默认是只有query使用全连接进行映射,同时给query增加了层归一化。这部分代码最后还有残差部分,这一块的注释写得特别逗:
if self.r:
# The result should be transformed according to the query
r = torch.cat([mix, original_q], dim=-1)
if self.drop: r = self.drop(r)
r = self.gelu(self.r(r))
mix = torch.sigmoid(self.r_gate) * mix + r
# BUG: This does _nothing_ as mix isn't set to r ...
# But ... I got good results with this ... so ...
# Let's leave it as is for right now ...
# This does imply that I don't necessarily need complex post mixing ops
2.3 Boom层
class Boom(nn.Module):
def __init__(self, d_model, dim_feedforward=2048, dropout=0.1, shortcut=False):
super(Boom, self).__init__()
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout) if dropout else None
if not shortcut:
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.shortcut = shortcut
#self.act = nn.ReLU()
self.act = GELU()
#self.act = nn.Tanh()
def forward(self, input):
x = self.act(self.linear1(input))
if self.dropout: x = self.dropout(x)
if self.shortcut:
# Trim the end off if the size is different
ninp = input.shape[-1]
x = torch.narrow(x, -1, 0, x.shape[-1] // ninp * ninp)
# Divide the hidden size evenly into chunks
x = x.view(*x.shape[:-1], x.shape[-1] // ninp, ninp)
# Collapse the chunks through summation
#h = h + self.drop(x).sum(dim=-2)
z = x.sum(dim=-2)
else:
z = self.linear2(x)
return z
这个Boom层,无力吐槽,大佬们都是取名字的鬼才
三、实验结果
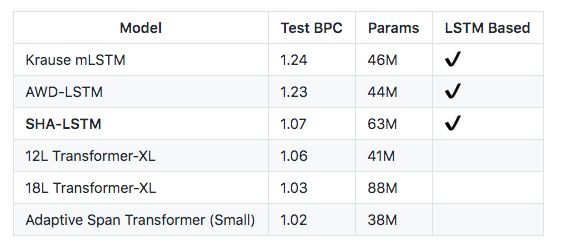
结果没跑过,也就没啥发言权,大神也没怎么好好对比,毕竟看论文吐槽就感觉是在放飞自我。结果上没有什么特别的优势,毕竟也是开了个头,按这个思路做做,说不定可以出来点东西
参考
- SHARNN论文
- SHARNN代码