Python数据可视化的例子——散点图(scatter)
(关系型数据的可视化)
散点图用于发现两个数值变量之间的关系
如果需要研究两个数值型变量之间是否存在某种关系,例如正向的线性关系,或者是趋势性的非线性关系,那么散点图将是最佳的选择。
1.matplotlib模块
matplotlib模块中的scatter函数可以非常方便地绘制两个数值型变量的散点图。这里首先将该函数的语法及参数含义写在下方,以便读者掌握函数的使用:
scatter(x, y, s=20, c=None, marker='o', cmap=None, norm=None, vmin=None,
vmax=None, alpha=None, linewidths=None, edgecolors=None)
- x:指定散点图的x轴数据。
- y:指定散点图的y轴数据。
- s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制。
- c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小。
- marker:指定散点图点的形状,默认为空心圆。
- cmap:指定某个Colormap值,只有当c参数是一个浮点型数组时才有效。
- norm:设置数据亮度,标准化到0~1,使用该参数仍需要参数c为浮点型的数组
- vmin、vmax:亮度设置,与norm类似,如果使用norm参数,则该参数无效。 alpha:设置散点的透明度。
- linewidths:设置散点边界线的宽度。
- edgecolors:设置散点边界线的颜色。
下面以iris(鸢尾花)数据集为例:

探究如何应用matplotlib模块中的scatter函数绘制花瓣宽度与长度之间的散点图,绘图代码如下:
import pandas as pd
import matplotlib.pyplot as plt
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 读入数据
iris = pd.read_csv(r'iris.csv')
# 绘制散点图
plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据
y = iris.Petal_Length, # 指定散点图的y轴数据
color = 'steelblue' # 指定散点图中点的颜色
)
# 添加x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
# 显示图形
plt.show()

如上图所示,通过scatter函数就可以非常简单地绘制出花瓣宽度与长度的散点图。如果使用pandas模块中的plot方法,同样可以很简单地绘制出散点图。
2.pandas模块
import pandas as pd
import matplotlib.pyplot as plt
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 读入数据
iris = pd.read_csv(r'iris.csv')
# Pandas模块绘制散点图
# 绘制散点图
iris.plot(x = 'Petal_Width',
y = 'Petal_Length',
kind = 'scatter', #scatter——散点图
title = '鸢尾花的花瓣宽度与长度关系')
# 修改x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 显示图形
plt.show()
结果:

尽管使用这两个模块都可以非常方便地绘制出散点图,但是绘制分组散点图会稍微复杂一点。如果读者使用seaborn模块中的lmplot函数,那么绘制分组散点图就太简单了,而且该函数还可以根据散点图添加线性拟合线。
3.seaborn模块
为了使读者清楚地掌握lmplot函数的使用方法,有必要介绍一下该函数的语法和参数含义:
lmplot(x, y, data, hue=None, col=None, row=None, palette=None,
col_wrap=None, size=5, aspect=1, markers='o',
sharex=True, sharey=True, hue_order=None, col_order=None,
row_order=None, legend=True, legend_out=True, scatter=True,
fit_reg=True, ci=95, n_boot=1000, order=1, logistic=False,
lowess=False, robust=False, logx=False, x_partial=None,
y_partial=None, truncate=False, x_jitter=None, y_jitter=None,
scatter_kws=None, line_kws=None)
- x,y:指定x轴和y轴的数据。
- data:指定绘图的数据集。
- hue:指定分组变量。
- col,row:用于绘制分面图形,指定分面图形的列向与行向变量。
- palette:为hue参数指定的分组变量设置颜色。
- col_wrap:设置分面图形中每行子图的数量。
- size:用于设置每个分面图形的高度。
- aspect:用于设置每个分面图形的宽度,宽度等于size*aspect。
- markers:设置点的形状,用于区分hue参数指定的变量水平值。
- sharex,sharey:bool类型参数,设置绘制分面图形时是否共享x轴和y轴,默认为True。
- hue_order,col_order,row_order:为hue参数、col参数和row参数指定的分组变量设值水平值顺序。
- legend:bool类型参数,是否显示图例,默认为True。
- legend_out:bool类型参数,是否将图例放置在图框外,默认为True。
- scatter:bool类型参数,是否绘制散点图,默认为True。
- fit_reg:bool类型参数,是否拟合线性回归,默认为True。
- ci:绘制拟合线的置信区间,默认为95%的置信区间。
- n_boot:为了估计置信区间,指定自助重抽样的次数,默认为1000次。
- order:指定多项式回归,默认指数为1。
- logistic:bool类型参数,是否拟合逻辑回归,默认为False。
- lowess:bool类型参数,是否拟合局部多项式回归,默认为False。
- robust:bool类型参数,是否拟合鲁棒回归,默认为False。
- logx:bool类型参数,是否对x轴做对数变换,默认为False。
- x_partial,y_partial:为x轴数据和y轴数据指定控制变量,即排除x_partial和y_partial变量的影响下绘制散点图。
- truncate:bool类型参数,是否根据实际数据的范围对拟合线做截断操作,默认为False。
- x_jitter,y_jitter:为x轴变量或y轴变量添加随机噪声,当x轴数据与y轴数据比较密集时,可以使用这两个参数。
- scatter_kws:设置点的其他属性,如点的填充色、边框色、大小等。
- line_kws:设置拟合线的其他属性,如线的形状、颜色、粗细等。
该函数的参数虽然比较多,但是大多数情况下读者只需使用几个重要的参数,如x、y、hue、data等。接下来仍以iris数据集为例,绘制分组散点图,绘图代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#设置绘图风格
plt.style.use('ggplot')
#处理中文乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#坐标轴负号的处理
plt.rcParams['axes.unicode_minus']=False
# 读入数据
iris = pd.read_csv(r'iris.csv')
# seaborn模块绘制分组散点图
sns.lmplot(x = 'Petal_Width', # 指定x轴变量
y = 'Petal_Length', # 指定y轴变量
hue = 'Species', # 指定分组变量
data = iris, # 指定绘图数据集
legend_out = False, # 将图例呈现在图框内
truncate=True # 根据实际的数据范围,对拟合线作截断操作
)
# 修改x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
#设置横纵坐标的刻度范围
plt.xlim((0, 2.7)) #x轴的刻度范围被设为a到b
plt.ylim((0, 7.5)) #y轴的刻度范围被设为a'到b'
# 显示图形
plt.show()
结果:
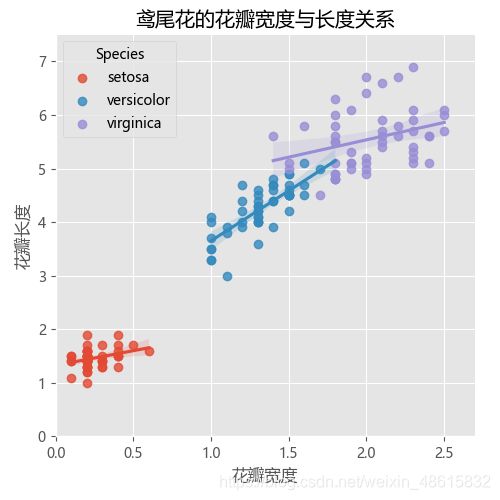
注:setosa、versicolor、virginica是鸢尾花的不同种类
如上图所示,lmplot函数不仅可以绘制分组散点图,还可以对每个组内的散点添加回归线(上图默认拟合线性回归线)。分组效果的体现是通过hue参数设置的,如果需要拟合其他回归线,可以指定lowess参数(局部多项式回归)、logistic参数(逻辑回归)、order参数(多项式回归)和robust参数(鲁棒回归)。