回顾一下FM
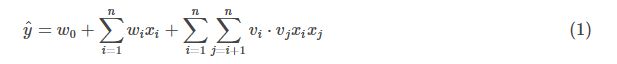
image.png

image.png
在FFM(Filed-aware Factorization Machines)中每一维特征(feature)都归属于一个特征的filed,field和feature是一对多的关系。比如
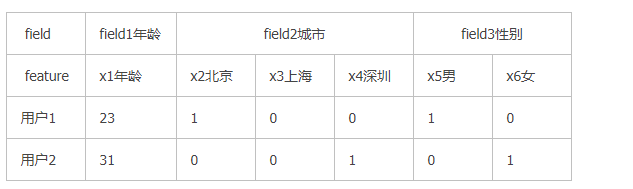
image.png
1.对于连续特征,一个特征就对应一个Field。或者对连续特征离散化,一个分箱成为一个特征。比如

image.png
2.对于离散特征,采用你one-hot 编码,同一种属性的归到一个Field不论是连续特征还是离散特征,他们都有一个共同点,同一个filed下只有一个feature的值不是0,其它的feature的值都是0
不论是连续特征还是离散特征,它们都有一个共同点,同一个field下只有一个feature的值不是0,其它的feature的值都是0。

image.png
FFM 将隐向量进一步细分,每个特征具有多个隐向量 (等于 field 的数目)。公式如下:

image.png

image.png
3 总结
优点:
引入 field 域的概念,让某一特征与不同特征做交互时,可发挥不同的重要性,提升模型表达能力;
可解释性强,可提供某些特征组合的重要性。
缺点:
复杂度高,不适用于特征数较多的场景。
4 代码实战
理论结合代码食用更佳, 代码中会加入充分注释,以易理解。
Tips: 模型搭建代码使用 TF2.0 实现
FFM层代码:
(将 FFM 封装成 Layer,随后在搭建 Model 时直接调用即可)
import tensorflow as tf
from tensorflow.keras.layers import Input, Layer
from tensorflow.keras.regularizers import l2
class FFM_Layer(Layer):
def __init__(self, feature_columns, k, w_reg=1e-4, v_reg=1e-4):
super(FFM_Layer, self).__init__()
# FFM需要提前指定field的数目,因此需要传入数值特征与类别特征的列表feature_columns(具体可参照github中utils.py文件中对数据的处理过程)
self.dense_feature_columns, self.sparse_feature_columns = feature_columns
self.k = k # 隐向量v的维度
self.w_reg = w_reg # 权重w的正则项系数
self.v_reg = v_reg # 权重v的正则项系数
self.feature_num = sum([feat['feat_onehot_dim'] for feat in self.sparse_feature_columns]) \
+ len(self.dense_feature_columns) # 类别特征onehot处理之后数据集的总维度
self.field_num = len(self.dense_feature_columns) + len(self.sparse_feature_columns) # field个数=数值特征个数+类别特征个数
def build(self, input_shape):
self.w0 = self.add_weight(name='w0', shape=(1,), # shape:(1,)
initializer=tf.zeros_initializer(),
trainable=True)
self.w = self.add_weight(name='w', shape=(self.feature_num, 1), # shape:(n, 1)
initializer=tf.random_normal_initializer(),
regularizer=l2(self.w_reg),
trainable=True)
self.v = self.add_weight(name='v', # shape:(n, field, k),比FM的V矩阵多一个维度
shape=(self.feature_num, self.field_num, self.k),
initializer=tf.random_normal_initializer(),
regularizer=l2(self.v_reg),
trainable=True)
def call(self, inputs, **kwargs):
# 输入为Criteo数据集,前13维为数值特征,后面为类别特征,可参照github中Data文件夹)
dense_inputs = inputs[:, :13] # 数值特征
sparse_inputs = inputs[:, 13:] # 类别特征
# one-hot encoding
x = tf.cast(dense_inputs, dtype=tf.float32) # 类型转换
for i in range(sparse_inputs.shape[1]): # 类别特征onehot处理
x = tf.concat(
[x, tf.one_hot(tf.cast(sparse_inputs[:, i], dtype=tf.int32),
depth=self.sparse_feature_columns[i]['feat_onehot_dim'])], axis=1) # shape:(None, n)
linear_part = self.w0 + tf.matmul(x, self.w) # 线性部分 shape:(None, 1)
inter_part = 0
field_f = tf.tensordot(x, self.v, axes=1) # 为了方便,先计算公式中的Vij*Xi. shape:[None, n] x [n, field, k] = [None, field, k]
for i in range(self.field_num): # 域之间两两相乘,[None, field, k]->[None, k],(因为公式无法化简,所以无法避免嵌套for循环的计算,导致了较高的复杂度)
for j in range(i+1, self.field_num):
inter_part += tf.reduce_sum(
tf.multiply(field_f[:, i], field_f[:, j]), # [None, k]
axis=1, keepdims=True
)
return linear_part + inter_part # [None, k]
Model 搭建:
from layer import FFM_Layer
from tensorflow.keras import Model
class FFM(Model):
def __init__(self, feature_columns, k, w_reg=1e-4, v_reg=1e-4):
super(FFM, self).__init__()
self.dense_feature_columns, self.sparse_feature_columns = feature_columns
self.ffm = FFM_Layer(feature_columns, k, w_reg, v_reg) # 定义FFM层
def call(self, inputs, **kwargs):
output = self.ffm(inputs) # 输入FFM层
output = tf.nn.sigmoid(output) # 非线性转换
return output
到此模型搭建就结束了。
完整的代码 (包括数据的处理以及模型的训练) 可参考以下 Github仓库,自行下载数据集到本地运行即可。
Githubgithub.com
写在最后
下一篇预告:Wide&Deep 推荐算法与深度学习的碰撞