重温SQL行转列,性能又双叒提升了
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10年DBA工作经验
一位上进心十足的【大数据领域博主】!
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程,B站及腾讯课堂讲师,直播量破10W
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
-
- 一、列转行
-
- 1.1 UNION ALL
- 1.2 insert all into ... select
- 1.3 MODEL
- 二、行转列
-
- 2.1 max+decode
- 三、多列转换成字符串
- 四、多行转换成字符串
-
- 4.1 ROW_NUMBER + LEAD
前言
最近粉丝们提的问题都与行列转换有关系,所以我对行列转换的相关知识做了一个总结,希望对 大家有所帮助,同时有何错疏,恳请大家指出,我也是在写作过程中学习,算是一起和大家学习吧行列转换包括以下六种情况:
- 列转行
- 行转列
- 多列转换成字符串
- 多行转换成字符串
- 字符串转换成多列
- 字符串转换成多行
一、列转行
简单的说就是将原表中的列名作为转换后的表的内容,这就是列转行
1.1 UNION ALL
create table TEST_JEM
(
NAME VARCHAR2(255),
JANUARY NUMBER(18),
FEBRUARY NUMBER(18),
MARCH NUMBER(18),
APRIL NUMBER(18),
MAY NUMBER(18)
);
insert into TEST_JEM(NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('长寿', 58, 12, 26, 18, 269);
insert into TEST_JEM(NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('璧山', 33, 18, 17, 16, 206);
insert into TEST_JEM(NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('杨家坪', 72, 73, 79, 386, 327);
insert into TEST_JEM(NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('巫溪', 34, 9, 7, 21, 33);
insert into TEST_JEM(NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('丰都', 62, 46, 39, 36, 91);
insert into TEST_JEM(NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('武隆', 136, 86, 44, 52, 142);
commit;
SELECT * FROM TEST_JEM;
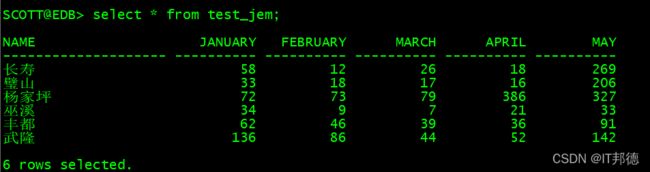
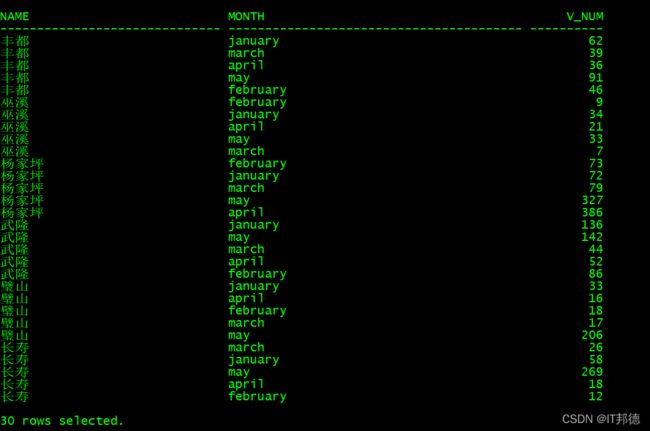
⛳️ 行转列如下
SELECT *
FROM (SELECT t.name, 'january' MONTH, t.january v_num
FROM TEST_JEM t
UNION ALL
SELECT t.name, 'february' MONTH, t.february v_num
FROM TEST_JEM t
UNION ALL
SELECT t.name, 'march' MONTH, t.march v_num
FROM TEST_JEM t
UNION ALL
SELECT t.name, 'april' MONTH, t.april v_num
FROM TEST_JEM t
UNION ALL
SELECT t.name, 'may' MONTH, t.may v_num FROM TEST_JEM t)
ORDER BY NAME;
1.2 insert all into … select
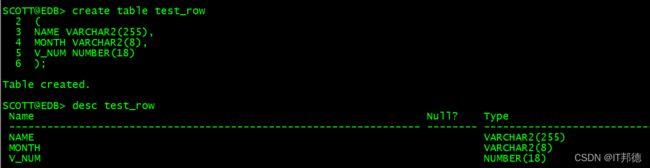
首先创建需要的表, test_row
create table test_row
(
NAME VARCHAR2(255),
MONTH VARCHAR2(8),
V_NUM NUMBER(18)
);
SQL> desc test_row
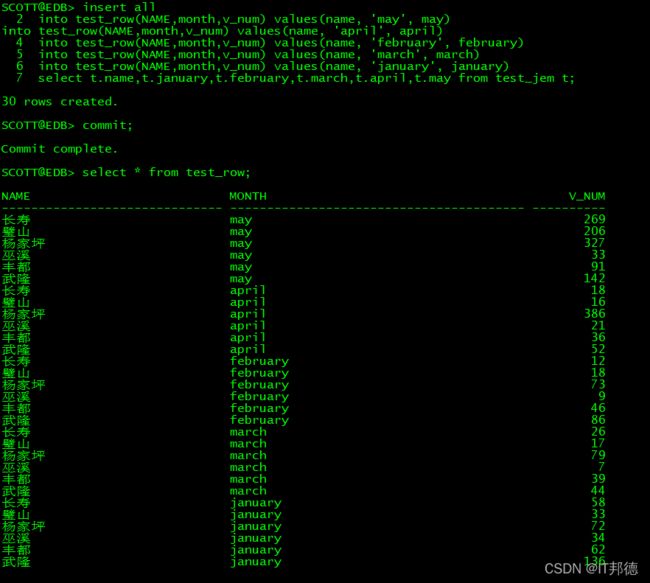
然后执行下边的 sql 语句:
注意:查询test_jem 的表进行插入
insert all
into test_row(NAME,month,v_num) values(name, 'may', may)
into test_row(NAME,month,v_num) values(name, 'april', april)
into test_row(NAME,month,v_num) values(name, 'february', february)
into test_row(NAME,month,v_num) values(name, 'march', march)
into test_row(NAME,month,v_num) values(name, 'january', january)
select t.name,t.january,t.february,t.march,t.april,t.may from test_jem t;
commit;
select * from test_row;
1.3 MODEL
CREATE TABLE t_col_row(
ID INT,
c1 VARCHAR2(10),
c2 VARCHAR2(10),
c3 VARCHAR2(10));
INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31');
INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL);
INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33');
INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34');
INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);
INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35');
INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL);
COMMIT;
SELECT * FROM t_col_row;
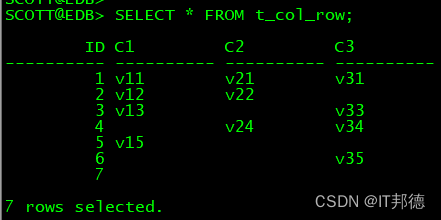
SELECT id,
cn,
cv
FROM t_col_row
MODEL RETURN
UPDATED ROWS PARTITION BY(ID)
DIMENSION BY(0 AS n)
MEASURES('xx' AS cn, 'yyy' AS cv, c1, c2, c3)
RULES UPSERT ALL(cn[1] = 'c1', cn[2] = 'c2', cn[3] = 'c3', cv[1] = c1[0],
cv[2] = c2[0], cv[3] = c3[0])
ORDER BY ID,cn;

二、行转列
行转列就是将行数据内容作为列名
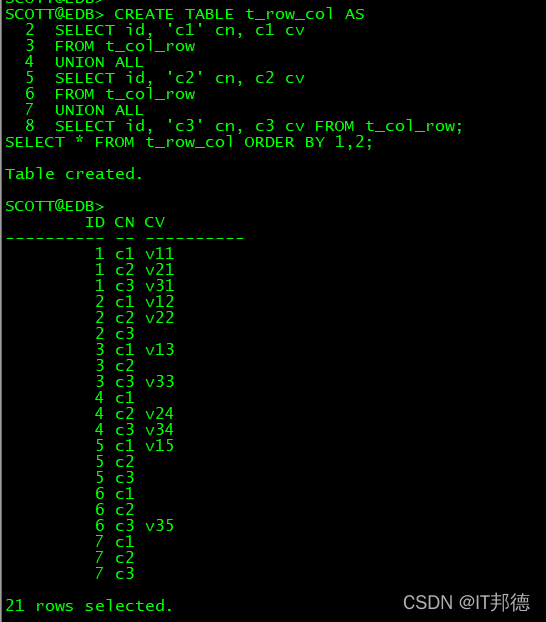
CREATE TABLE t_row_col AS
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
SELECT * FROM t_row_col ORDER BY 1,2;
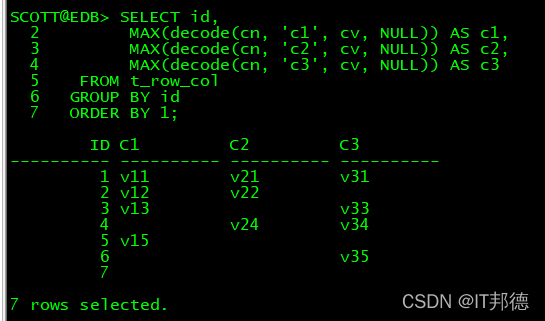
2.1 max+decode
SELECT id,
MAX(decode(cn, 'c1', cv, NULL)) AS c1,
MAX(decode(cn, 'c2', cv, NULL)) AS c2,
MAX(decode(cn, 'c3', cv, NULL)) AS c3
FROM t_row_col
GROUP BY id
ORDER BY 1;
SELECT t.name,
MAX(decode(t.month, 'may', t.v_num)) AS may,
MAX(decode(t.month, 'april', t.v_num)) AS april,
MAX(decode(t.month, 'february', t.v_num)) AS february,
MAX(decode(t.month, 'march', t.v_num)) AS march,
MAX(decode(t.month, 'january', t.v_num)) AS january
FROM test_row t
GROUP BY t.name;

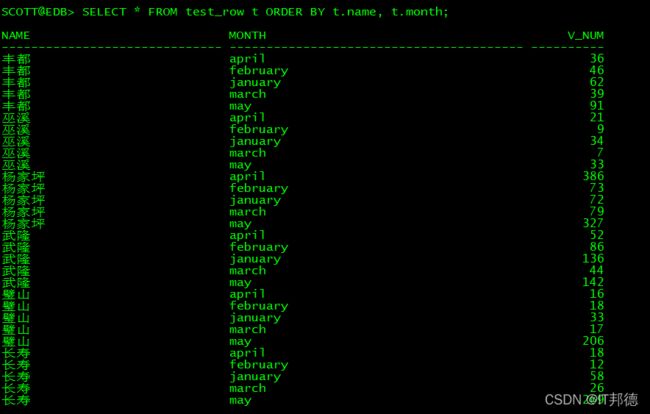
如果要实现对各个不同的区间进行统计,则:
SELECT * FROM test_row t ORDER BY t.name, t.month;
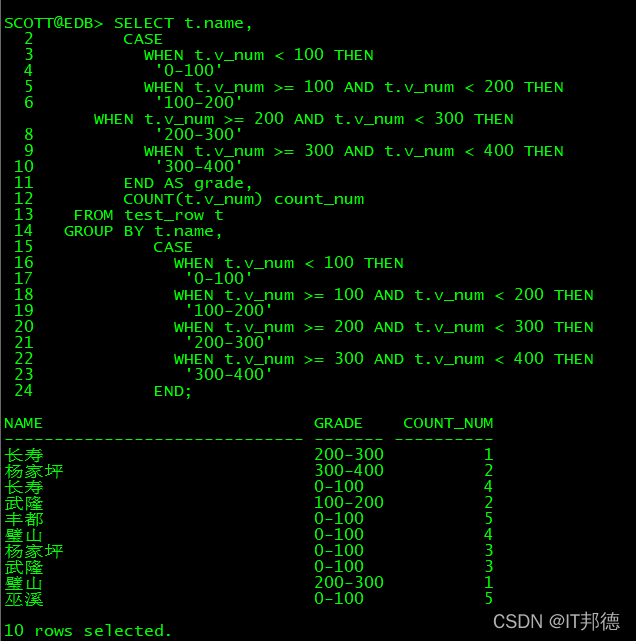
SELECT t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END AS grade,
COUNT(t.v_num) count_num
FROM test_row t
GROUP BY t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END;
三、多列转换成字符串
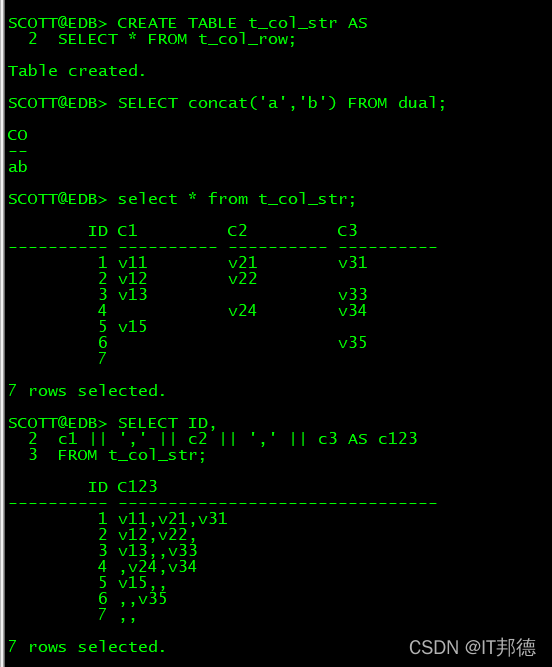
CREATE TABLE t_col_str AS
SELECT * FROM t_col_row;
这个比较简单,用|| 或 concat 函数可以实现:
SELECT concat('a','b') FROM dual;
SELECT ID,
c1 || ',' || c2 || ',' || c3 AS c123
FROM t_col_str;
四、多行转换成字符串
CREATE TABLE t_row_str(
ID INT,
col VARCHAR2(10)
);
INSERT INTO t_row_str VALUES(1,'a');
INSERT INTO t_row_str VALUES(1,'b');
INSERT INTO t_row_str VALUES(1,'c');
INSERT INTO t_row_str VALUES(2,'a');
INSERT INTO t_row_str VALUES(2,'d');
INSERT INTO t_row_str VALUES(2,'e');
INSERT INTO t_row_str VALUES(3,'c');
COMMIT;
SELECT * FROM t_row_str;

4.1 ROW_NUMBER + LEAD
SELECT id, str
FROM (SELECT id,
row_number() over(PARTITION BY id ORDER BY col) AS rn,
col || lead(',' || col, 1) over(PARTITION BY id ORDER BY col) ||
lead(',' || col, 2) over(PARTITION BY id ORDER BY col) ||
lead(',' || col, 3) over(PARTITION BY id ORDER BY col) AS str
FROM t_row_str)
WHERE rn = 1
ORDER BY 1;

大家点赞、收藏、关注、评论啦 微信公众号