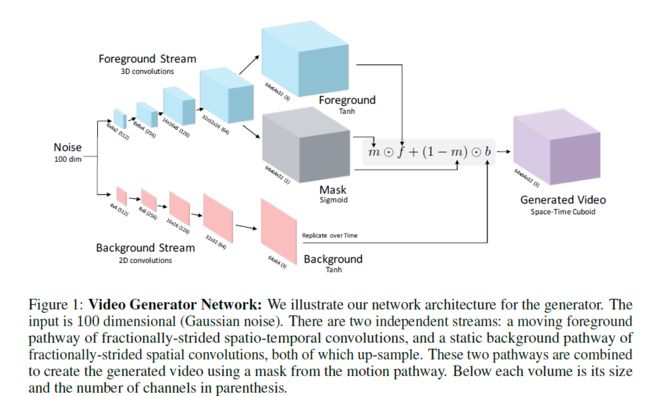
Foreground / Mask / Background
local net
local netD
local mask_net
local motion_net
local static_net
local penalty_net
if opt.finetune == '' then -- build network from scratch
net = nn.Sequential()
static_net = nn.Sequential()
static_net:add(nn.View(-1, 100, 1, 1))
static_net:add(nn.SpatialFullConvolution(100, 512, 4,4))
static_net:add(nn.SpatialBatchNormalization(512)):add(nn.ReLU(true))
static_net:add(nn.SpatialFullConvolution(512, 256, 4,4, 2,2, 1,1))
static_net:add(nn.SpatialBatchNormalization(256)):add(nn.ReLU(true))
static_net:add(nn.SpatialFullConvolution(256, 128, 4,4, 2,2, 1,1))
static_net:add(nn.SpatialBatchNormalization(128)):add(nn.ReLU(true))
static_net:add(nn.SpatialFullConvolution(128, 64, 4,4, 2,2, 1,1))
static_net:add(nn.SpatialBatchNormalization(64)):add(nn.ReLU(true))
static_net:add(nn.SpatialFullConvolution(64, 3, 4,4, 2,2, 1,1))
static_net:add(nn.Tanh())
local net_video = nn.Sequential()
net_video:add(nn.View(-1, 100, 1, 1, 1))
net_video:add(nn.VolumetricFullConvolution(100, 512, 2,4,4))
net_video:add(nn.VolumetricBatchNormalization(512)):add(nn.ReLU(true))
net_video:add(nn.VolumetricFullConvolution(512, 256, 4,4,4, 2,2,2, 1,1,1))
net_video:add(nn.VolumetricBatchNormalization(256)):add(nn.ReLU(true))
net_video:add(nn.VolumetricFullConvolution(256, 128, 4,4,4, 2,2,2, 1,1,1))
net_video:add(nn.VolumetricBatchNormalization(128)):add(nn.ReLU(true))
net_video:add(nn.VolumetricFullConvolution(128, 64, 4,4,4, 2,2,2, 1,1,1))
net_video:add(nn.VolumetricBatchNormalization(64)):add(nn.ReLU(true))
local mask_out = nn.VolumetricFullConvolution(64,1, 4,4,4, 2,2,2, 1,1,1)
penalty_net = nn.L1Penalty(opt.lambda, true)
mask_net = nn.Sequential():add(mask_out):add(nn.Sigmoid()):add(penalty_net)
gen_net = nn.Sequential():add(nn.VolumetricFullConvolution(64,3, 4,4,4, 2,2,2, 1,1,1)):add(nn.Tanh())
net_video:add(nn.ConcatTable():add(gen_net):add(mask_net))
-- [1] is generated video, [2] is mask, and [3] is static
net:add(nn.ConcatTable():add(net_video):add(static_net)):add(nn.FlattenTable())
Video的size为[batch_size, time, channel, height, width],图中表示为:height*width*time(channel)。
Convolution参数为(input_channel, kernel_number, [kernel_size], [strides], [paddings]),SpatialFullConvolution中kernel_size等为2d,VolumetricFullConvolution中kernel_size等为3d。
View(): 相当于reshape
ConcatTable():
+-----------+
+----> {member1, |
+-------+ | | |
| input +----+----> member2, |
+-------+ | | |
or +----> member3} |
{input} +-----------+
Generated Video
-- video .* mask (with repmat on mask)
motion_net = nn.Sequential():add(nn.ConcatTable():add(nn.SelectTable(1))
:add(nn.Sequential():add(nn.SelectTable(2))
:add(nn.Squeeze())
:add(nn.Replicate(3, 2)))) -- for color chan
:add(nn.CMulTable())
-- static .* (1-mask) (then repmatted)
local sta_part = nn.Sequential():add(nn.ConcatTable():add(nn.Sequential():add(nn.SelectTable(3))
:add(nn.Replicate(opt.frameSize, 3))) -- for time
:add(nn.Sequential():add(nn.SelectTable(2))
:add(nn.Squeeze())
:add(nn.MulConstant(-1))
:add(nn.AddConstant(1))
:add(nn.Replicate(3, 2)))) -- for color chan
:add(nn.CMulTable())
net:add(nn.ConcatTable():add(motion_net):add(sta_part)):add(nn.CAddTable())
SelectTable(i): 选择ConcatTable中的第i个member。
Replicate(n, dim): 在第dim个维度复制为n个
(a, b, c):nn.Replicate(3, 2)-->(a, 3, b, c)
Discriminator
netD = nn.Sequential()
netD:add(nn.VolumetricConvolution(3,64, 4,4,4, 2,2,2, 1,1,1))
netD:add(nn.LeakyReLU(0.2, true))
netD:add(nn.VolumetricConvolution(64,128, 4,4,4, 2,2,2, 1,1,1))
netD:add(nn.VolumetricBatchNormalization(128,1e-3)):add(nn.LeakyReLU(0.2, true))
netD:add(nn.VolumetricConvolution(128,256, 4,4,4, 2,2,2, 1,1,1))
netD:add(nn.VolumetricBatchNormalization(256,1e-3)):add(nn.LeakyReLU(0.2, true))
netD:add(nn.VolumetricConvolution(256,512, 4,4,4, 2,2,2, 1,1,1))
netD:add(nn.VolumetricBatchNormalization(512,1e-3)):add(nn.LeakyReLU(0.2, true))
netD:add(nn.VolumetricConvolution(512,2, 2,4,4, 1,1,1, 0,0,0))
netD:add(nn.View(2):setNumInputDims(4))
Discriminator Optimizer
-- optimization closure
-- the optimizer will call this function to get the gradients
local data_im,data_label
local fDx = function(x)
gradParametersD:zero()
-- fetch data
data_tm:reset(); data_tm:resume()
data_im = data:getBatch()
data_tm:stop()
-- ship to GPU
noise:normal()
target:copy(data_im)
label:fill(real_label)
-- real_label=1, fake_label=2
-- forward/backwards real examples
local output = netD:forward(target)
errD = criterion:forward(output, label)
local df_do = criterion:backward(output, label)
netD:backward(target, df_do)
-- generate fake examples
local fake = net:forward(noise)
target:copy(fake)
label:fill(fake_label)
-- forward/backwards fake examples
local output = netD:forward(target)
errD = errD + criterion:forward(output, label)
local df_do = criterion:backward(output, label)
netD:backward(target, df_do)
errD = errD / 2
return errD, gradParametersD
end
Generator Optimizer
local fx = function(x)
gradParameters:zero()
label:fill(real_label)
local output = netD.output
err = criterion:forward(output, label)
local df_do = criterion:backward(output, label)
local df_dg = netD:updateGradInput(target, df_do)
net:backward(noise, df_dg)
return err, gradParameters
end
使用updateGradInput是为了不对netD进行backpropagation,仅仅是用链式法则计算梯度的中间过程。