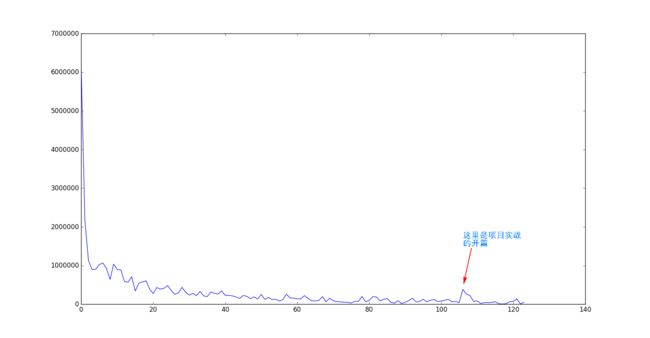
猜想:看廖雪峰python教程的时候我就在想,这上百篇的教程,到底有多少人能够坚持到最后呢?然后就想到学完一定要把这种半途而废的现象赤裸裸地展现出来,哈哈哈。结果请看图片,不言自明,下降趋势明显。
参考资料
- 这是一个人写的爬虫入门教程,我觉得很适合入门
- Python 爬虫:把廖雪峰教程转换成 PDF 电子书
- 《python编程:从入门到实践》第15章开始有讲怎么画图
步骤方法:
1、请详细耐心看完以上的几篇入门文章之后
2、所有教程的链接在第一篇教程的左边,我们需要获取所有的链接,这个在参考文章2里面有说到,请查看。
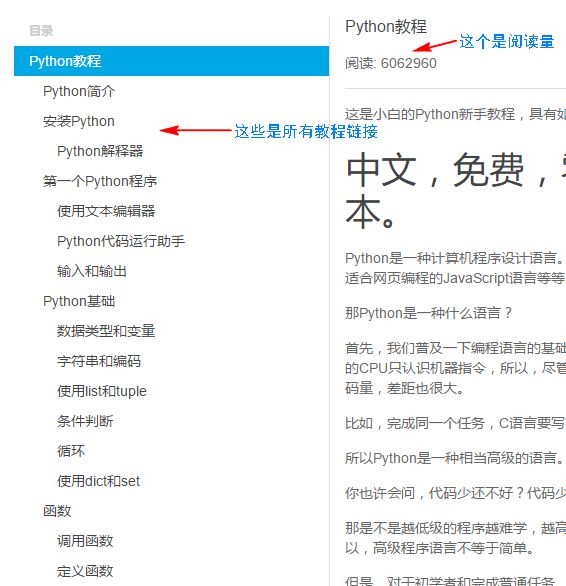
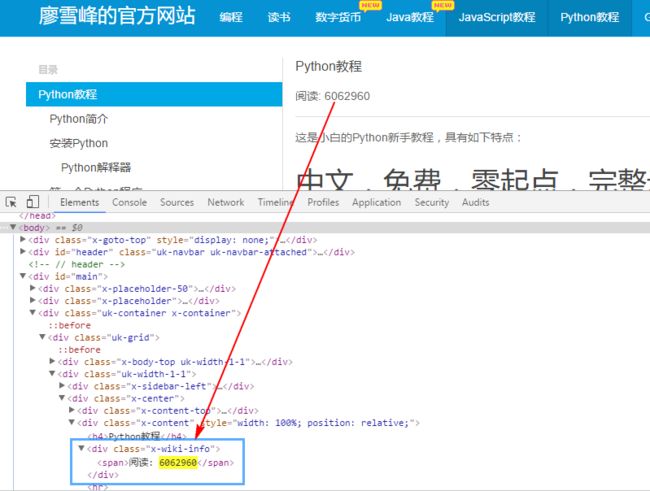
3、阅读量按F12,然后Ctrl+F,输入阅读量的数字,发现这个数字在网页中的位置,于是我们知道这在x-wiki-info这个class中,通过beautifulsoup的查找方法,我们可以得到这个标签,之后就很容易得到这个数字了
4、最后是把数字以折线图的形式画出来,请看参考文档3
5、之后学了异步之后改为异步请求多个网页,看看效果怎么样,见代码2
40个网站在相同的网速之下异步和同步所花时间之比为2:3
6、上个步骤容易导致下载的网速过快,然后就被封掉了,从这篇文章的最后教我们用协程的信号量来控制协程的个数,这样子就可以避免上述问题了。见代码3
- 代码1:同步执行源码:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import time
import os
START_URL = 'https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
# 时间测量的装饰器
def timing(f):
def wrap(*args):
time1_s = time.time()
ret = f(*args)
time2_s = time.time()
print('%s function took %0.3f s' % (f.__name__, (time2_s-time1_s)))
return ret
return wrap
@timing
def get_all_urls():
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
response = requests.get(START_URL,headers=headers)
# print(response.content.decode())
bsobj = BeautifulSoup(response.content, 'lxml')
urls = bsobj.find('ul',{'class':'uk-nav uk-nav-side','style':'margin-right:-15px;'}).find_all('li')
return urls
@timing
def ReadNum(url):
# print(url)
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
response = requests.get(url, headers=headers)
# print(response.content.decode())
soup = BeautifulSoup(response.content, 'lxml')
ReadInfo = soup.find(class_='x-wiki-info')
num = int(ReadInfo.span.string.split(':')[1])
return num
# print(num)
def main():
all_readInfo = []
urls = get_all_urls()
# ReadNum('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000')
urls_num = len(urls)
for i,url in enumerate(urls):
# if i <= 5:
num = ReadNum('https://www.liaoxuefeng.com' + urls[i].a['href'])
if num is not None:
all_readInfo.append(num)
print('还剩下',urls_num - i)
# else:
# break
plt.plot(all_readInfo)
plt.show()
代码2:异步执行源码,python版本要大于3.4
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import time
import aiohttp
import asyncio
START_URL = 'https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
READING_INFO = []
NUM_LEFT = 0
# 时间测量的装饰器
def timing(f):
def wrap(*args):
time1_s = time.time()
ret = f(*args)
time2_s = time.time()
print('%s function took %0.3f s' % (f.__name__, (time2_s-time1_s)))
return ret
return wrap
@timing
def get_all_urls():
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
response = requests.get(START_URL,headers=headers)
# print(response.content.decode())
bsobj = BeautifulSoup(response.content, 'html.parser')
tags = bsobj.find('ul',{'class':'uk-nav uk-nav-side','style':'margin-right:-15px;'}).find_all('a')
urls = []
for tag in tags:
urls.append('https://www.liaoxuefeng.com' + tag['href'])
# print(urls)
return urls
def read_num(url):
# print(url)
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
response = requests.get(url, headers=headers)
# print(response.content.decode())
soup = BeautifulSoup(response.content, 'html.parser')
ReadInfo = soup.find(class_='x-wiki-info')
num = int(ReadInfo.span.string.split(':')[1])
return num
# print(num)
async def read_num_asyncio(url,index):
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
async with aiohttp.ClientSession() as client:
async with client.get(url, headers=headers) as resp:
assert resp.status == 200
txt = await resp.text()
# async with aiohttp.get(url, headers=headers) as resp:
# assert resp.status == 200
# txt = await resp.text()
# # print(txt)
soup = BeautifulSoup(txt,'html.parser')
read_info = soup.find(class_='x-wiki-info')
num = int(read_info.span.string.split(':')[1])
# print(num)
global NUM_LEFT,READING_INFO
READING_INFO[index] = num
NUM_LEFT += 1
print(NUM_LEFT)
# return num
# 异步方法读取100+个教程网页然后提取出阅读量
def asyncio_get_reading_num(urls):
loop = asyncio.get_event_loop()
tasks = [read_num_asyncio(url,index) for index,url in enumerate(urls) if index < 20]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
@timing
def main():
urls = get_all_urls()
print(len(urls))
global READING_INFO
READING_INFO = [0] * len(urls)
asyncio_get_reading_num(urls)
# all_readInfo = []
# urls_num = len(urls)
# for i,url in enumerate(urls):
# if i <= 40:
# num = read_num(url)
# if num is not None:
# all_readInfo.append(num)
# print(i)
# else:
# break
# plt.plot(READING_INFO)
# plt.show()
if __name__ == '__main__':
main()
- 代码3:用协程信号量来限制协程运行个数
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import time
import aiohttp
import asyncio
START_URL = 'https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
READING_INFO = []
NUM_LEFT = 0
# 时间测量的装饰器
def timing(f):
def wrap(*args):
time1_s = time.time()
ret = f(*args)
time2_s = time.time()
print('%s function took %0.3f s' % (f.__name__, (time2_s-time1_s)))
return ret
return wrap
@timing
def get_all_urls():
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
response = requests.get(START_URL,headers=headers)
# print(response.content.decode())
bsobj = BeautifulSoup(response.content, 'html.parser')
tags = bsobj.find('ul',{'class':'uk-nav uk-nav-side','style':'margin-right:-15px;'}).find_all('a')
urls = []
for tag in tags:
urls.append('https://www.liaoxuefeng.com' + tag['href'])
# print(urls)
return urls
def read_num(url):
# print(url)
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
response = requests.get(url, headers=headers)
# print(response.content.decode())
soup = BeautifulSoup(response.content, 'html.parser')
ReadInfo = soup.find(class_='x-wiki-info')
num = int(ReadInfo.span.string.split(':')[1])
return num
# print(num)
async def read_num_asyncio(url,index,sem):
# 要模拟浏览器登陆
headers = {'User-Agent': USER_AGENT}
with (await sem):
async with aiohttp.ClientSession() as client:
async with client.get(url, headers=headers) as resp:
assert resp.status == 200
txt = await resp.text()
# async with aiohttp.get(url, headers=headers) as resp:
# assert resp.status == 200
# txt = await resp.text()
# # print(txt)
soup = BeautifulSoup(txt,'html.parser')
read_info = soup.find(class_='x-wiki-info')
num = int(read_info.span.string.split(':')[1])
# print(num)
global NUM_LEFT,READING_INFO
READING_INFO[index] = num
NUM_LEFT += 1
print(NUM_LEFT)
# return num
# 异步方法读取100+个教程网页然后提取出阅读量
def asyncio_get_reading_num(urls):
# 设置线程的信号量,最多5个协程在工作,根据网站的流量或者实际测试确定
# 如果没有进行限制,那么中途可能被封IP
sem = asyncio.Semaphore(5)
loop = asyncio.get_event_loop()
# tasks = [read_num_asyncio(url,index,sem) for index,url in enumerate(urls) if index < 20]
tasks = [read_num_asyncio(url, index, sem) for index, url in enumerate(urls)]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
@timing
def main():
urls = get_all_urls()
print(len(urls))
global READING_INFO
READING_INFO = [0] * len(urls)
asyncio_get_reading_num(urls)
# all_readInfo = []
# urls_num = len(urls)
# for i,url in enumerate(urls):
# if i <= 40:
# num = read_num(url)
# if num is not None:
# all_readInfo.append(num)
# print(i)
# else:
# break
plt.plot(READING_INFO)
plt.show()
if __name__ == '__main__':
main()