Solr:企业级搜索应用服务器
一.Solr简介
1.为什么使用Solr
在海量数据下,对MySQL或Oracle进行模糊查询或条件查询的效率是很低的.而搜索功能在绝大多数项目中都是必须的,如何提升搜索效率是很多互联网项目必须要考虑的问题
既然使用关系型数据库进行搜索效率比较低,最直接的解决方案就是使用专用搜索工具进行搜索,从而提升搜索效率
2.常见搜索解决方案
基于Apache Lucene(全文检索工具库)实现搜索.但是Lucene的使用对于绝大多数的程序员都是"噩梦级"的.
3.Solr简介
Solr是基于Apache Lucene构建的用于搜索和分析的开源解决方案.可提供可扩展索引,搜索功能,高亮显示和文字解析功能
Solr本质就是一个Java web项目,且内嵌了Jetty服务器,所以安装起来非常方便.客户端操作Solr的过程和平时我们缩写项目一样,就是请求Solr中控制器,处理完数据后把结果响应给客户端
4.正向索引和方向索引
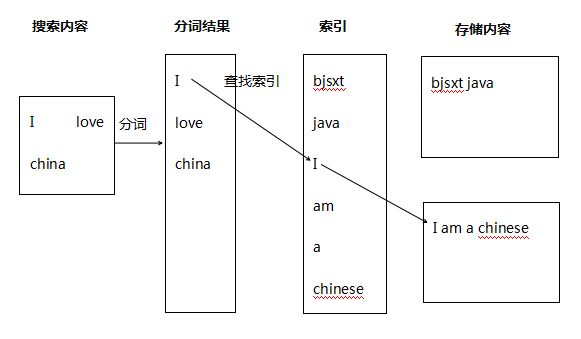
只要讨论搜索就不得不提的两个概念:正向索引(forward index)和反向索引(inverted index)
正向索引:从文档内容到词组的过程.每次搜索的时候需要搜索所有文档,每个文档比较搜索条件和词组
文档 词组
I am a chinese I,am,a,chinese
反向索引:是正向索引的逆向.建立词组和文档的映射关系.通过找到词组就能找到文档内容(和新华字典找字很像)
词组 文档
I,am,a,chinese I am a chinese
二.Solr搜索原理
1.搜索原理
Solr能够提升检索效率的主要原因就是分词和索引(反向索引)
分词:会对搜索条件/存储内容进行分词,分成日常所使用的词语
索引:存储在Solr中内容会按照程序员的要求来是否建立索引.如果要求建立索引会把存储内容中关键字(分词)建立索引
2.Solr中数据存储说明
Solr为了给内容建立索引,所以Solr就必须具备数据存储能力.所有需要被搜索的内容都需要存储在Solr中,在开发中需要把数据库中数据添加到Solr中进行初始化,每次修改数据库中数据还需要同步Solr中的数据
Solr中数据存储是存储在Document对象中,对象中可以包含的属性和属性类型都定义在schema.xml中.如果需要自定义属性或自定义属性类型都需要修改schema.xml配置文件.从Solr5开始schema.xml更改名称为managed-schema(没有扩展名)
三.Solr单机版安装
略
四.可视化管理界面
在关闭防火墙的前提下,可以在windows的浏览器中访问Solr.
输入:http://192.168.232.132:8983就可以访问Solr的可视化管理界面
左侧有5个菜单.分别是:
(1)Dashboard:面板显示Solr的总体信息
(2)Logging:日志
(3)Core Admin:Solr的核心.类似于数据的Database
(4)Java Properties:所有Java相关属性
(5)Thread Dump:线程相关信息
(6)如果有Core,将显示在此处

五.新建核心
Solr安装完成后默认是没有核心的.需要手动配置
需要在solr/server/solr下新建文件夹,并给定配置文件,否则无法建立

1.新建目录
在/usr/local/solr/server/solr中新建自定义名称目录.此处示例名称为testcore
# cd /usr/local/solr/server/solr
# mkdir testcore
2.复制配置文件
在configsets里面包含了_default和sample_techproducts_configs.里面都是配置文件示例._default属于默认配置,较纯净.sample_techproducts_configs是带有了一些配置示例.
# cp -r configsets/_default/conf/ testcore/
3.填写Core信息
在可视化管理界面中Core Admin中编写信息后点击Add Core后,短暂延迟后testcore就会创建成功.schema处不用更改

4.出现testcore
在客户端管理界面中,选择新建的Core后,就可以按照自己项目的需求进行操作了

六.分词Analysis
在Solr可视化管理界面中,Core的管理菜单项都会有Analysis.表示根据Scheme.xml(managed-schema)中配置要求进行解析
对英文解析就比较简单了,只要按照空格把英文语句拆分成英文单机即可

但是如果条件是中文时,把一句话按照字进行拆分就不是很合理了.正确的方式是按照合理的词组进行拆分

1.中文分词器安装及配置步骤
上传ik-analyzer.jar到webapps中
去https://search.maven.org/search?q=com.github.magese下载对应版本的ik-analyzer.可以在
"软件/Analyzer"中直接获取.
1.1上传jar到指定目录
上传ik-analyzer-8.2.0.jar到
/usr/local/solr/server/solr-webapp/webapp/WEB-INF/lib目录中
1.2修改配置文件
修改/usr/local/solr/server/solr/testcode/conf/managed-schema
# vim /usr/local/solr/server/solr/testcode/conf/managed-schema
添加下面内容
排版:Esc退出编辑状态下:gg=G
1.3重启
# cd /usr/local/solr/bin
# ./solr stop -all
# ./solr start -force
1.4验证
可以在可视化管理界面中找到myfield属性进行验证

2.managed-schema配置说明
2.1
表示定义一个属性类型.在Solr中属性类型都是自定义的.在上面配置中name="text_ik"为自定义类型.当某个属性取值为text_ik时IK Analyzer才能生效.
2.2
表示向Document中添加一个属性
常用属性:
name:属性名
type:属性类型.所有类型都是solr使用
indexed:是否建立索引
stored:solr是否把该属性值响应给搜索用户
required:该属性是否是必须的.默认id是必须的
multiValed:如果为true,表示该属性为符合属性,此属性中包含了多个其他的属性.常用在多个列作为搜索条件时,ab这些列定义成一个新的符合属性,通过搜索一个符合属性就可以实现搜索多个列.当设置为true时与
2.3
唯一主键.Solr中默认定义id属性为唯一主键.ID的值是不允许重复的
2.4
名称中允许*进行通配.代表满足特定名称要求的一组属性
七.Dataimport
可以使用Solr自带的Dataimport功能把数据库中数据快速导入到solr中.
必须保证managed-schema和数据库中表的列对应
1.修改配置文件
修改solrconfig.xml,添加下面内容
2.新建data-config.xml
和solrconfig.xml同一目录下新建data-config.xml
url="jdbc:mysql://192.168.232.132:3306/maven?serverTimezone=Asia/Shanghai" user="root" password="root"/> 3.添加jar 向solr-webapp中添加三个jar.在dist中两个还有一个数据库驱动 4.操作 重启solr后,在可视化管理页面中进行数据导入 注意: 点击导入按钮后,要记得点击刷新按钮 以XML格式举例 1.新增/修改 当id不存在时新增,当id存在修改 2.删除 2.1根据主键删除 2.2根据条件删除 1.查询全部 只要在q参数中写入*:*即是搜索全部数据 2.条件查询 在q参数部分写入字段名:搜索条件值,即是条件搜索 3.分页查询 在条件start,rows中输入从第几条数据开始查询,查询多少条数据.下标从0开始.类似MySQL数据库中的limit 4.查询排序 在sort条件中输入字段名排序规则.排序规则包括asc和desc 5.高亮查询 选中hl高亮复选框,在hl.fl中输入高亮显示的字段名称.在hl.simple.pre中输入高亮前缀,在hl.simple.post中输入高亮后缀 SolrJ是Solr提供的Java客户端API.通过SolrJ可以实现Java程序对Solr中数据的操作 大前提:添加SolrJ依赖.依赖版本和Solr版本严格对应 1.新增/修改实现 String url = "htto://192.168.232.132:8983/solr/testcode"; HttpSolrClient solrClient = new HttpSoleClient.Builder(url).build(); SolrInputDocument inputDocument = new SolrInputDocument(); inputDocument.addField("id",3); inputDocument.addField("myfield","myfield3"); solrClient.add(inputDocument); solrClient.commit(); 2.删除实现 String url = "http://192.168.232.132:8983/solr/testcore"; HttpSolrClient solrClient = new HttpSolrClient.Builder(url).build(); solrClient.deleteById("3"); solrClient.commit(); 3.查询实现 public void testQuery(){ try{ String url = "http://192.168.232.132:8983/solr/testcore"; HttpSolrClient solrClient = new HttpSolrClient.Builder(url).build(); //封装了所有查询条件 SolrQuery params = new SolrQuery(); params.setQuery("name:丰富的"); //排序 params.setSort("price",SolrQuery.ORDER.desc); //分页 params.setStart(0); params.setRows(1); //高亮 params.setHighlight(true); params.addHighlightField("name"); params.setHighlightSimplePre(""); params.setHighlightSimplePost(""); QueryResponse response = solrClient.query(params); SolrDocumentList list = response.getResults(); System.out.println("总条数:"+list.getNumFound()); //高亮数据 Map response.getHighlighting(); for(SolrDocument doc:list){ System.out.println(doc.get("id")); Map List if(HLList!=null&&HLList.size()>0){//显示高亮数据 System.out.println(HLList.get(0)); }else{ System.out.println(doc.get("name")); } System.out.println(doc.get("price")); System.out.println("================="); } solrClient.close(); }catch(SolrServerException e){ e.printStackTrace(); }catch(IOException e){ e.printStackTrace(); } } 1.Spring Data简介 Spring Data是Spring的顶级项目.里面包含了N多个二级子项目,每个子项目对应一种技术或工具.器目的为了让数据访问更加简单,更加方便的和Spring进行整合 Spring Data项目如果单独使用是还需要配置XML配置文件的,当和Spring Boot整合后使用起来非常方便.spring-boot-starter-data-xx就是对应的启动器 2.实现步骤 2.1添加依赖 spring-boot-starter-test 2.2编写配置文件 spring: data: solr: host:http://192.168.232.132:8080/solr # zk-host:192.168.232.132:2181,192.168.232.132:2182,192.168.232.132:2183 2.3编写测试类 @RunWith(SpringJUnit4ClassRunner.class) @SpringBootTest(classes=MyApplication.class) public class MyTest{ @Autowired private SolrTemplate solrTemplate; public void testInsert(){ SolrInputDocument doc = new SolrInputDocument(); doc.setField("id","002"); doc.setField("item_title","这是一个手机3"); UpdateResponse ur = solrTemplate.saveBean("collection1",doc); if(ur.getStatus()==0){ System.out.println("成功"); }else{ System.out.println("失败"); } solrTempalte.commit("collection1"); } public void testDelete(){ UpdateResponse ur = soleTemplate.deleteByIds("collection1","change.me"); if(ur.getStatus()==0){ System.out.println("成功"); }else{ System.out.println("失败"); } solrTempalte.commit("collection1"); } public void query(){ SimpleQuery query = new SimpleQuery(); Criteria c = new Criteria("item_keywords"); c.is("手机"); query.addCriteria(c); query.setOffset(1L); query.setRows(1); ScoredPage System.out.println(sp.getContent()); } @Test public void queryHL(){ List SimpleHighlightQuery query = new SimpleHighlightQuery(); //设置查询条件 Criteria c = new Criteria("item_keywords"); c.is("手机"); query.addCriteria(c); //分页 query.setOffset(0L); query.setRows(10); //排序 Sort sort = new Sort(Sort.Direction.DESC,"id"); query.addSort(sort); //高亮设置 HighlightOptions hlo = new HighlightOptions(); hlo.addField("item_title item_sell_point"); hlo.setSimplePrefix(""); hlo.setSimplePostfix(""); query.setHighlightOptions(hlo); HighlightPage //System.out.println(hl.getContent()); List for(HighlightEntry List DemoPojo dp = hle.getEntity(); for(HighlightEntry.Highlight h:list){//一个对象里面可能多个属性是高亮属性 if(h.getField().getName().equals("item_title")){ dp.setItem_title(h.getSnipplets().get(0)); } } listResult.add(dp); } System.out.println(listResult); } } Solr可以搭建具备容错能力和高可用的Solr集群.集群中集群配置,自动负载均衡和查询故障转义,Zookeeper集群实现集群协调管理,这些全部功能统称为SolrCloud SolrCloud是基于Zookeeper进行管理的.在Solr中已经内置了Zookeeper相关内容,当执行集群创建命令会自动创建Zookeeper相关内容.这个使用的是Zookeeper的集群管理功能实现的 1.搭建 1.1创建 SolrCloud已经包含在了Solr中,可以直接启动Solr集群 # ./solr -e cloud -noprompt -force 此命令等同于# ./solr -e cloud -force全部参数为默认值 运行成功后会在example文件夹多出cloud文件夹 1.2停止 # ./solr stop -all 1.3重新运行 # ./solr start -c -p 8983 -s ../example/cloud/node1/solr/ -force # ./solr start -c -p 7574 -z localhost:9983 -s ../example/cloud/node2/solr/ -force 1.4增加集群节点 把"example/cloud/node1/"目录中的无效数据删除.只保存node1/solr/目录中的 solr.xml和zoo.cfg两个配置文件.其他都删除.目录只保存node1/ 下的solr和logs两个子目录 复制node1目录 cp -r node1/ node2 cp -r node1/ node3 启动多个Solr节点,搭建SolrCloud集群 # ./solr start -c -p 8983 -s ../example/cloud/node1/solr -force # ./solr start -c -p 7574 -z localhost:9983 -s ../example/cloud/node2/solr/ -force # ./solr start -c -p 6666 -z localhost:9983 -s ./example/cloud/node3/solr/ -force
八.菜单项目Documents使用方法
九.菜单项目query查询使用办法


![]()


十.使用SolrJ操作Solr
十一.Spring Data for Apache Solr
十二.SolrCloud