docker最早是LXC(Linux Container)的二次封装发行,后来使用的是Libcontainer技术,从1.11开始进一步演化为 runC 和 containerd,其利用的也是Linux内核特性namespaces(名称空间) 、 cgroups (控制组)和AUFS(最新的overlay2)等技术,是操作系统层面的虚拟化技术。
关于Libcontainer,contianerd相关的技术:参考如下
Libcontainer原理
谈谈docker,containerd,runc,docker-shim之间的关系
核心概念
namespace(名称空间)
其中 namespace 是为了将操作系统中的资源进行完全隔离,也就是用户空间中,每个容器只能感知到自己是唯一的进程。
这六个namespace 分别是:
- MOUNT :文件系统挂接点 开始支持的内核版本:2.4.19
- UTS :nodename 和 domainname 开始支持的内核版本:2.6.19
- IPC :特定的进程间通信资源,包括System V IPC 和 POSIX message queues 开始支持的内核版本:2.6.19
- PID :进程 ID 开始支持的内核版本:2.6.24 (每个 PID namespace 中的进程可以有其独立的 PID; 每个容器可以有其 PID 为 1 的root 进程;也使得容器可以在不同的 host 之间迁移,因为 namespace 中的进程 ID 和 host 无关了。这也使得容器中的每个进程有两个PID:容器中的 PID 和 host 上的 PID)
- NETWORK :网络相关的系统资源 开始支持的内核版本:2.6.29
- USER :用户和组 ID 空间 开始支持的内核版本:3.8 ( 每个 container 可以有不同的 user 和 group id;一个 host 上的非特权用户可以成为 user namespace 中的特权用户)
Centos 的内核一般比较老,如Centos6 就不适合运行docker,最新的centos7.6的默认内核版本才是3.10.0。从上面可以看出USER的namespace是从3.8后才加入的。而运行一个docker内核版本最好是3.10+。而最新的centos7.6才刚刚满足。
croups(控制组)
Linux Cgroup 可让您为系统中所运行任务(进程)的用户定义组群分配资源 — 比如 CPU 时间、系统内存、网络带宽或者这些资源的组合。您可以监控您配置的 cgroup,拒绝 cgroup 访问某些资源,甚至在运行的系统中动态配置您的 cgroup。
它主要提供了如下功能:
- Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting: 一些审计或一些统计,主要目的是为了计费。
- Control: 挂起进程,恢复执行进程。
其限制的资源类型为:
- blkio — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
- memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
默认情况下,Docker 启动一个容器后,会在 /sys/fs/cgroup 目录下的各个资源目录下生成以容器 ID 为名字的目录(group),比如:
$ ls /sys/fs/cgroup/
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids systemd
$ pwd
/sys/fs/cgroup/cpu/docker/a871a1b033b4282d8b02eba5d05615094e172db89440fef82bcf78f50c57991e
$ ls
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
$ cat cpu.cfs_quota_us
-1
这里的 -1 表示没有任何限制。
docker 在启动的时候,如果加上资源限制的参数的话,就会限制其资源,如
$ docker run -d --name nginx001 --cpu-quota 25000 --cpu-period 100 --cpu-shares 30 nginx
AUFS(联合文件系统)
AUFS 是一种 Union File System(联合文件系统),又叫 Another UnionFS,后来叫 Alternative UnionFS,再后来叫成高大上的 Advance UnionFS。所谓 UnionFS,就是把不同物理位置的目录合并mount到同一个目录中。UnionFS的一个最主要的应用是,把一张CD/DVD和一个硬盘目录给联合 mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改(当然,修改的文件存于硬盘上的目录里)。
在大神的博客中举了很详细的例子来理解AUFS,这里直接就贴链接吧。
理解Docker(7):Docker 存储 - AUFS 刘世民(Sammy Liu)
摘选其中AUFS的特点:
- AUFS 是一种联合文件系统,它把若干目录按照顺序和权限 mount 为一个目录并呈现出来
- 默认情况下,只有第一层(第一个目录)是可写的,其余层是只读的。
- 增加文件:默认情况下,新增的文件都会被放在最上面的可写层中。
- 删除文件:因为底下各层都是只读的,当需要删除这些层中的文件时,AUFS 使用 whiteout 机制,它的实现是通过在上层的可写的目录下建立对应的whiteout隐藏文件来实现的。
- 修改文件:AUFS 利用其 CoW (copy-on-write)特性来修改只读层中的文件。AUFS 工作在文件层面,因此,只要有对只读层中的文件做修改,不管修改数据的量的多少,在第一次修改时,文件都会被拷贝到可写层然后再被修改。
- 节省空间:AUFS 的 CoW 特性能够允许在多个容器之间共享分层,从而减少物理空间占用。
- 查找文件:AUFS 的查找性能在层数非常多时会出现下降,层数越多,查找性能越低,因此,在制作 Docker 镜像时要注意层数不要太多。(在DockerFile中,每RUN一次就是加一层)
- 性能:AUFS 的 CoW 特性在写入大型文件时第一次会出现延迟。
既然是多层结构,就要提到操作系统在运行时最重要的两个文件系统bootfs和rootfs。
- boot file system (bootfs):包含 boot loader 和 kernel。用户不会修改这个文件系统。实际上,在启动(boot)过程完成后,整个内核都会被加载进内存,此时 bootfs 会被卸载掉从而释放出所占用的内存。同时也可以看出,对于同样内核版本的不同的 Linux 发行版的 bootfs 都是一致的。
-
root file system (rootfs):包含典型的目录结构,包括 /dev, /proc, /bin, /etc, /lib, /usr, and /tmp 等再加上要运行用户应用所需要的所有配置文件,二进制文件和库文件。
Linux 系统在启动时,roofs 首先会被挂载为只读模式,然后在启动完成后被修改为读写模式,随后它们就可以被修改了。
同一个内核版本的所有 Linux 系统的 bootfs 是相同的,而 rootfs 则是不同的。在 Docker 中,基础镜像中的 roofs 会一直保持只读模式,Docker 会利用 union mount 来在这个 rootfs 上增加更多的只读文件系统,最后它们看起来就像一个文件系统即容器的 rootfs。如下图
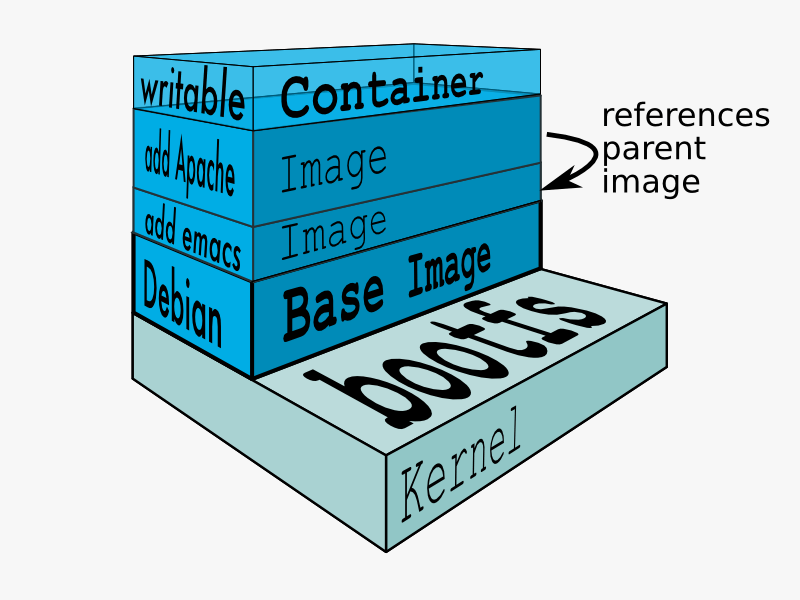 docker-镜像叠加.png
docker-镜像叠加.png
$ pwd
/var/lib/docker/aufs/diff/b2188d5c09cfe24acd6da5ce67720f81138f0c605a25efc592f1f55b3fd3dffa
$ docker history training/webapp
IMAGE CREATED CREATED BY SIZE COMMENT
6fae60ef3446 16 months ago /bin/sh -c #(nop) CMD ["python" "app.py"] 0 B
16 months ago /bin/sh -c #(nop) EXPOSE 5000/tcp 0 B
16 months ago /bin/sh -c #(nop) WORKDIR /opt/webapp 0 B
16 months ago /bin/sh -c #(nop) ADD dir:9b2a69f6f30d18b02b5 703 B
16 months ago /bin/sh -c pip install -qr /tmp/requirements. 4.363 MB
16 months ago /bin/sh -c #(nop) ADD file:c59059439864153904 41 B
16 months ago /bin/sh -c DEBIAN_FRONTEND=noninteractive apt 135.3 MB
16 months ago /bin/sh -c apt-get update 20.8 MB
16 months ago /bin/sh -c #(nop) MAINTAINER Docker Education 0 B
17 months ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0 B
17 months ago /bin/sh -c sed -i 's/^#\s*\(deb.*universe\)$/ 1.895 kB
17 months ago /bin/sh -c echo '#!/bin/sh' > /usr/sbin/polic 194.5 kB
17 months ago /bin/sh -c #(nop) ADD file:f4d7b4b3402b5c53f2 188.1 MB
它是基于 Ubuntu Docker 基础镜像。在基础镜像层中,我们能看到完整的 Ubuntu rootfs:
$ ls -l
total 76
drwxr-xr-x 2 root root 4096 Apr 27 2015 bin
drwxr-xr-x 2 root root 4096 Apr 11 2014 boot
drwxr-xr-x 3 root root 4096 Apr 27 2015 dev
drwxr-xr-x 61 root root 4096 Apr 27 2015 etc
drwxr-xr-x 2 root root 4096 Apr 11 2014 home
drwxr-xr-x 12 root root 4096 Apr 27 2015 lib
drwxr-xr-x 2 root root 4096 Apr 27 2015 lib64
drwxr-xr-x 2 root root 4096 Apr 27 2015 media
drwxr-xr-x 2 root root 4096 Apr 11 2014 mnt
drwxr-xr-x 2 root root 4096 Apr 27 2015 opt
drwxr-xr-x 2 root root 4096 Apr 11 2014 proc
drwx------ 2 root root 4096 Apr 27 2015 root
drwxr-xr-x 7 root root 4096 Apr 27 2015 run
drwxr-xr-x 2 root root 4096 Apr 27 2015 sbin
drwxr-xr-x 2 root root 4096 Apr 27 2015 srv
drwxr-xr-x 2 root root 4096 Mar 13 2014 sys
drwxrwxrwt 2 root root 4096 Apr 27 2015 tmp
drwxr-xr-x 10 root root 4096 Apr 27 2015 usr
drwxr-xr-x 11 root root 4096 Apr 27 2015 var
overlay2和devicemapper
overlay2
现在最新docker已经改用overlay2技术来处理镜像的叠加。
在overlay和overlay2驱动程序支持xfs的文件系统。
OverlayFS使用两个目录,把一个目录置放于另一个之上,并且对外提供单个统一的视角。这两个目录通常被称作层,这个分层的技术被称作union mount。术语上,下层的目录叫做lowerdir,上层的叫做upperdir。对外展示的统一视图称作merged。
下图展示了Docker镜像和Docker容器是如何分层的。镜像层就是lowerdir,容器层是upperdir。暴露在外的统一视图就是所谓的merged。
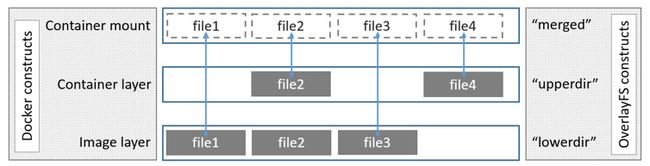
overlay驱动只能工作在两层之上。也就是说多层镜像不能用多层OverlayFS实现。替代的,每个镜像层在/var/lib/docker/overlay中用自己的目录来实现,使用硬链接这种有效利用空间的方法,来引用底层分享的数据。
创建一个容器,overlay驱动联合镜像层和一个新目录给容器。镜像顶层是overlay中的只读lowerdir,容器的新目录是可写的upperdir。
$ docker pull ubuntu
Using default tag: latest
latest: Pulling from library/ubuntu
5ba4f30e5bea: Pull complete
9d7d19c9dc56: Pull complete
ac6ad7efd0f9: Pull complete
e7491a747824: Pull complete
a3ed95caeb02: Pull complete
Digest: sha256:46fb5d001b88ad904c5c732b086b596b92cfb4a4840a3abd0e35dbb6870585e4
Status: Downloaded newer image for ubuntu:latest
上图的输出结果显示pull了5个目录包含了5个镜像层,每一层在/var/lib/docker/overlay/下都有自己的目录。还是再次提醒下,如你所见,Docker1.10之后,镜像层和目录名不再对应。
$ ls -l /var/lib/docker/overlay/
total 20
drwx------ 3 root root 4096 Jun 20 16:11 38f3ed2eac129654acef11c32670b534670c3a06e483fce313d72e3e0a15baa8
drwx------ 3 root root 4096 Jun 20 16:11 55f1e14c361b90570df46371b20ce6d480c434981cbda5fd68c6ff61aa0a5358
drwx------ 3 root root 4096 Jun 20 16:11 824c8a961a4f5e8fe4f4243dab57c5be798e7fd195f6d88ab06aea92ba931654
drwx------ 3 root root 4096 Jun 20 16:11 ad0fe55125ebf599da124da175174a4b8c1878afe6907bf7c78570341f308461
drwx------ 3 root root 4096 Jun 20 16:11 edab9b5e5bf73f2997524eebeac1de4cf9c8b904fa8ad3ec43b3504196aa3801
一般来说,overlay/overlay2驱动更快一些,几乎肯定比aufs和devicemapper更快,在某些情况下,可能比btrfs也更快。即便如此,在使用overlay/overlay2存储驱动时,还是需要注意以下一些方面:
- Page Caching,页缓存。OverlayFS支持页缓存共享,也就是说如果多个容器访问同一个文件,可以共享一个或多个页缓存选项。这使得overlay/overlay2驱动高效地利用了内存,是PaaS平台或者其他高密度场景的一个很好地选项。
- copy_up。和AuFS一样,在容器第一次修改文件时,OverlayFS都需要执行copy-up操作,这会给写操作带来一些延迟——尤其这个要拷贝的文件很大时。不过,一旦文件已经执行了这个向上拷贝的操作后,所有后续对这个文件的操作都只针对这份容器层的新拷贝而已。
devicemapper
而devicemapper呢,这是个性能很差的实现方法,不幸的是老一点的Centos使用的就是这种技术。其实现类似于lvm的快照之类的。其Thin Provisioning的文档中说,这还处理实验阶段,不要上Production.
These targets are very much still in the EXPERIMENTAL state. Please do not yet rely on them in production.
大牛程序员Jeff Atwood 也多次发Twitter,DeviceMapper这种东西问题太多了,我们应该把其加入黑名单。
而Docker的创始人在回应devicemapper时指出。如果你在使用loopback的devicemapper的话,当你的存储出现了问题后,正确的解决方案是: rm -rf /var/lib/docker
参考文章:
理解Docker(3):Docker 使用 Linux namespace 隔离容器的运行环境 刘世民(Sammy Liu)
理解Docker(4):Docker 容器使用 cgroups 限制资源使用 刘世民(Sammy Liu)
Docker -- 从入门到实践
DOCKER基础技术:AUFS
DOCKER存储驱动之OVERLAYFS简介