1.SVD分解
1.1先谈什么是特征值分解?
(1)特征值
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:
(2)线性变换
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵
它其实对应的线性变换是下面的形式:
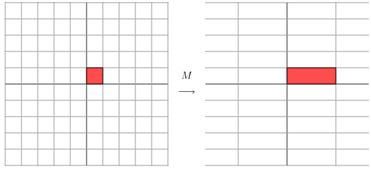
因为这个矩阵M乘以一个向量(x,y)的结果是:
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时拉长,当值<1时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:
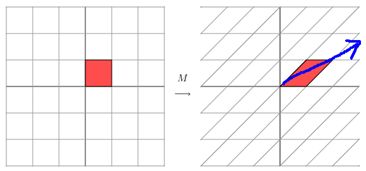
这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。
(3)重点来了!特征值的意义
也就是之前说的:提取这个矩阵最重要的特征。总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
1.2奇异值
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
那么奇异值和特征值是怎么对应起来的呢?假设矩阵 A 的维度为 mxn,虽然 A 不是方阵,但是下面的矩阵却是方阵,且维度分别为 mxm、nxn。
因此,我们就可以分别对上面的方阵进行分解:
其中,Λ1 和 Λ2 是对角矩阵,且对角线上非零元素均相同,即两个方阵具有相同的非零特征值,特征值令为。值得注意的是,k<=m 且 k<=n
根据 σ1, σ2, … , σk 就可以得到矩阵 A 的特征值为:
接下来,我们就能够得到奇异值分解的公式:
也可以表示为下面这种形式:(推导待议)
其中,U 称为左奇异矩阵,维度是 mxm,V 称为右奇异矩阵,维度是 nxn。Σ 并不是方阵,其维度为 mxn,Σ对角线上的非零元素就是 A 的特征值 。图形化表示奇异值分解如下图所示:
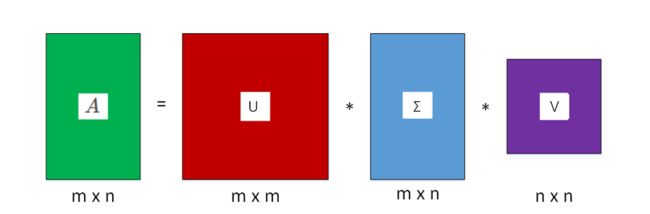
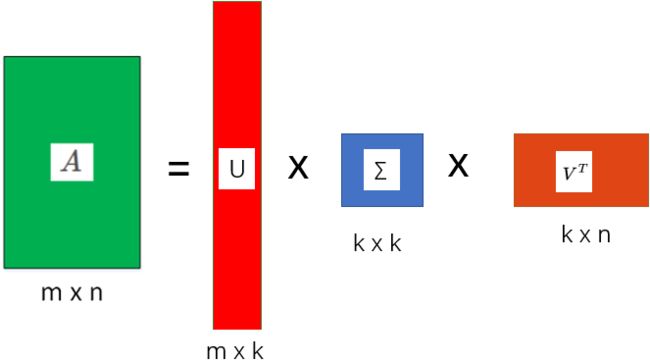
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
k是一个远小于m、n的数,这样矩阵的乘法看起来像是下面的样子:
1.3形象理解SVD
奇异值分解到底有什么用呢?如何形象化地理解奇异值?我们一起来看下面的例子。

我们对该图片进行奇异值分解,则该图片可写成以下和的形式:
上式中,是按照从大到小的顺序的。
首先,若我们只保留最大的奇异值 ,舍去其它奇异值,即 ,然后作图:

结果完全看不清楚,再多加几个奇异值,取前 5 个最大的奇异值,然后作图:

现在貌似有点轮廓了,继续增加奇异值,取前 10 个最大的奇异值,然后作图:

又清晰了一些,继续将奇异值增加到 20 个,然后作图:

现在已经比较清晰了,继续将奇异值增加到 50 个,然后作图:

可见,取前 50 个最大奇异值来重构图像时,已经非常清晰了。我们得到和原图差别不大的图像。也就是说,随着选择的奇异值的增加,重构的图像越来越接近原图像。
基于这个原理,奇异值分解可以用来进行图片压缩。例如在本例中,原始图片的维度是 870×870,总共需要保存的像素值是:870×870=756900。若使用 SVD,取前 50 个最大的奇异值即可,则总共需要存储的元素个数为:
显然,所需存储量大大减小了。在需要存储许多高清图片,而存储空间有限的情况下,就可以利用 SVD,保留奇异值最大的若干项,舍去奇异值较小的项即可。
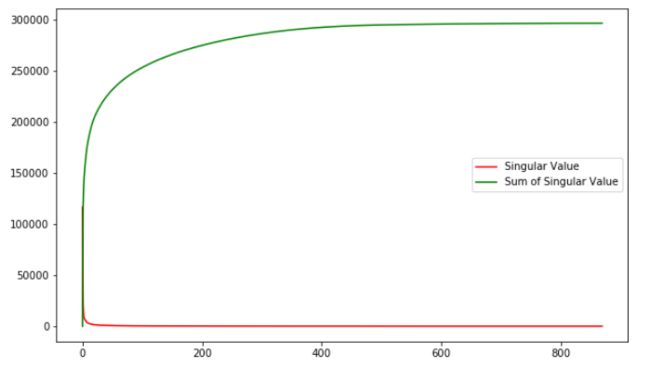
值得一提的是,奇异值从大到小衰减得特别快,在很多情况下,前 10% 甚至 1% 的奇异值的和就占了全部的奇异值之和的 99% 以上了。这对于数据压缩来说是个好事。下面这张图展示了本例中奇异值和奇异值累加的分布
SVD 数据压缩的示例代码为:
from skimage import io
import matplotlib.pyplot as plt
from PIL import Image
img=io.imread('./ng.jpg')
m,n = img.shape
io.imshow(img)
plt.show()
P, L, Q = np.linalg.svd(img)
tmp = np.diag(L)
if m < n:
d = np.hstack((tmp,np.zeros((m,n-m))))
else:
d = np.vstack((tmp,np.zeros((m-n,n))))
# k = 50
img2 = P[:,:50].dot(d[:50,:50]).dot(Q[:50,:])
io.imshow(np.uint8(img2))
plt.show()
tmp = np.uint8(img2)
im = Image.fromarray(tmp)
im.save("out.jpg")
2.Word embedding
cs224n课程第一周里,提到了2种生成word embedding的方法。一种是基于word2vec的神经网络生成词向量的方法。另一种是基于统计的词向量生成的方法:使用共现矩阵,再进行SVD分解。
首先要说明,这2种方法输出的word embedding 都是distributed representation(稠密表达,也叫分布式表达)。
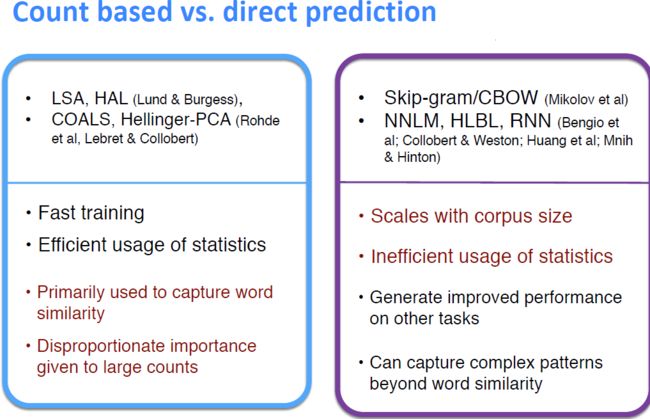
其次值得说的是,这2种方法各有优缺点(可能面试里会问,见下图),在glove方法中,综合进行了两种算法,达到最优的效果。
那么,我们这里详细探讨一下利用SVD生成词向量的过程。
2.1生成共现矩阵
构造一个矩阵A,这个矩阵的大小是
这里V是词表的长度。这个矩阵称之为共现矩阵。
我们要统计,每个中心词在左右k个窗口的范围内,上下文词出现的词频。于是这里的共现矩阵,第一个维度(列),代表这个中心词,第二个维度(行)代表这个中心词对应的上下文词。 为第i个词作为中心词时,对应第j个词作为其上下文词时候的词频。举个例子
I enjoy flying。
I like NLP。
I like deep learning。
这里设置k=1,则共现矩阵为:
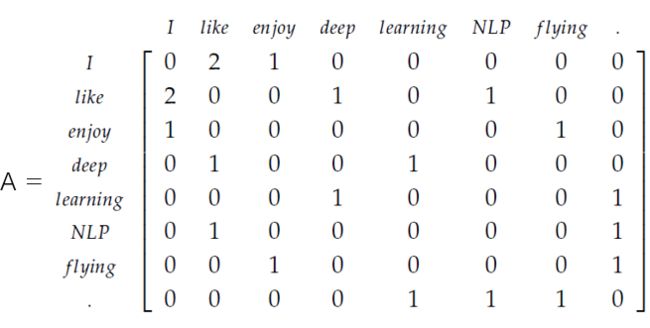
可以看出,这里的共现矩阵A为对称矩阵,也就是对中心词like,enjoy的出现次数是等于对于中心词enjoy,like的出现次数。
2.2 SVD对矩阵A分解
假设A的size是,那么U的矩阵是,奇异值矩阵S是,而的size 是. 这里m是词表长度,k是指最后需要输出的词向量维度,一般我们取100-300之间的一个值。
SVD分解公式可以写作
写成分量式为(待证明)
由线性代数基本知识可知,对于任意矩阵X(size )来说,我们可以进行奇异值分解,这里都是size 的对角矩阵,并且每个值都是非负实数,按大小从大到小排列。

那么我们对进行降维,只保留前K个值,这样U和V也会跟着变,从维度上看,矩阵去掉了后面的一些列,变成了;矩阵去掉了前面的一些行,变成了(实质上做了空间变换,而不是简单的去除一些数据)。也就是下面的图:
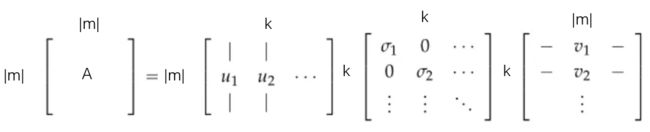
这里就解释了,为什么是用U的行来做word embedding。
2.3如果U对应的词向量,那么V对应的是什么呢?
还有一个问题,如果U对应的词向量,那么V对应的是什么呢?对于词共现矩阵来说,V的意义还不是很清晰,我们考虑这样一个矩阵:
词-文档矩阵 Word-Document Matrix,行是所有的词,维度为V,列是每个文档,维度为M。对这样一个矩阵进行SVD分解,并降维到K个奇异值上取值。
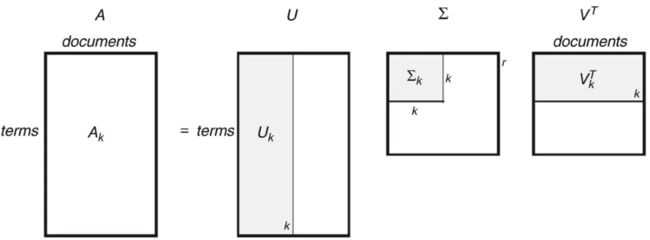
SVD分解公式可以写作
U的矩阵size
的矩阵size 是
写成分量式为:
对应的第i个词和第j个主题的相关度,是词的主题向量。
对应第j个文档和第k个主题的相关度,所以是第j个文档的文档向量。
这样就说明了V在SVD分解的意义。
以上就是全部内容;(公式挂了 下面贴一张图)

本文主要参考:[http://redstonewill.com/1529/]
(http://redstonewill.com/1529/)
https://blog.csdn.net/shenziheng1/article/details/52916278
https://mp.weixin.qq.com/s/aMb0kexW9bpKDenBbrkXlg