来源:Ben Malec from Paylocity and RedisConf 2020 organized by Redis Labs
翻译:Wen Hui
转载:中间件小哥
这篇文章中我们介绍如何使用Redis 6中关于客户端缓存的支持来设计我们的客户端缓存机制。我们首先来看一个典型的web应用如下:

在loadbalancer后面我们有多个web服务器,并与相同的SQL数据库相连接。另外,在每个web服务器中,我们有多个服务器端缓存用来在服务器端缓存SQL数据库中的数据。
我们这样设计的目的是避免每次数据读操作都访问数据库从而带来较高的系统延时。但是,这种设计模式带来一个主要问题是如果其中一个web服务器接收到更新数据的请求,会更新数据库中的数据,以及这个服务器中的服务器缓存,但是其他的web服务器中会继续缓存旧的数据,从而带来数据不一致的问题。我们可以想到有多个解决方案来解决这个问题,首先一种比较常见的方案是更新数据的web服务器可以将数据更新的请求广播到其他的web服务器中。但是这种方式会带来以下两个主要问题:
1. 会很大程度上增加系统网络的负载。
2. 会导致竞态条件(race condition)以及其他一些问题。例如如果两个web服务器同时更新同一个数据,那么系统网络无法保证这两个更新请求到达其他服务器的先后顺序。
针对以上问题,一个常见的解决方案是我们可以将服务器端缓存替换成Redis,如下图所示:

这样做的好处是:
1. Redis比其他后端数据库存储要快许多。
2. 完全可以解决竞态条件或数据不一致的问题,因为多个web服务器共享了redis实例,所以客户端每次都会得到正确的结果。
但这样也带来了web服务器与Redis通信的网络延时的问题。因为在一般情况下,内存访问速度很快,所以网络延时很容易成为这种设计的瓶颈。
如果我们综合了以上两种设计,我们会得到以下设计方案:
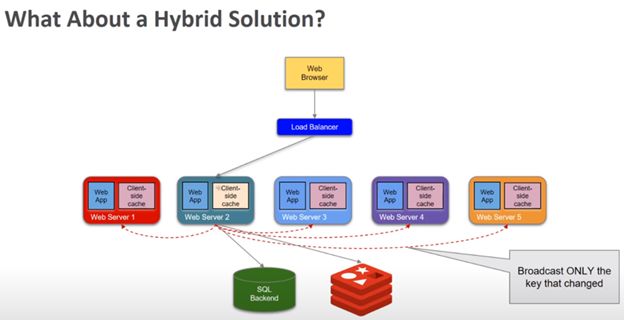
在这里,我们保留服务器端缓存,并在redis中数据改变的情况下,通过redis的广播机制来更新其他web服务器中的缓存。整体设计如下:
1. Redis始终是系统缓存的单一数据源。
2. 当Redis缓存的值更新后,通过Redis的发布订阅连接来更新其他web服务器中的缓存。
3. 在其他web服务器收到更新缓存的消息以后,会使本地服务器端缓存失效,然后再下次接收到读数据请求的时候访问redis实例以拿到更新后的值。
4. 这样设计不仅可以保持数据一致性并且可以使用服务器端缓存以降低系统延时。
5. 在多个服务器同时更新的情况下,因为Redis是单一数据源,所以所有的服务器端缓存都会得到正确的值。
6. Paylocity做了进一步的优化,没有将整个键来广播给其他web服务器,而是只广播键的hash值,这样可以进一步降低网络负载。但同时也增加一些程序的复杂度。
作者在Redis Conf 2018 对这种解决方案做了演讲,但也收到Redis 作者Savatore提到的一些潜在的问题:
1. 所有的更新操作必须通过web服务器中的缓存逻辑,如果直接更改redis的话其他web服务器端不会收到更新。
2. 所有更新都会被广播到所有的web服务器中,无论web服务器中是否缓存过更新的键。
3. 如果Redis内核可以为客户端缓存的逐出提供帮助将是一个更好的方案。
到了Redis 6.0版本,redis实现了针对客户端缓存的追踪机制,具体特性如下:
1. 在Redis中添加了关于客户端缓存追踪的新命令。
2. Opt in:Redis客户端可以选择是否启用客户端追踪。
3. 两种模式: 默认和广播模式。
4. Redis会记录键值的改动,并记录哪个客户端对哪个键值感兴趣。
5. 当键值改动后,Redis会发送给启用缓存追踪的客户端发送缓存无效信息。
6. 客户端会逐出特定的客户端缓存,下一次的请求将访问Redis以获取数据。
下面具体介绍Redis 客户端缓存追踪的具体模式:
1. 默认模式
Redis 命令:CLIENT TRACKING ON
在默认模式下, Redis会显式的记住每个客户端感兴趣哪个特定的键,如果键被更新时,Redis只给那些对这个键感兴趣的客户端发送缓存无效的信息。
优点:
可以最大限度利用网络带宽,不会有多余的消息发送给没有缓存过这个键的客户端。
缺点:
对于Redis服务器来说记住每个客户端感兴趣的键会导致使用更多的内存。
如果我们有几千个客户端和几百万个键,这种方式会消耗非常大的内存资源。
如果redis需要清理追踪部分的内存的话,需要给客户端发送缓存无效的消息, 即使特定的键值没有被改变。
2. 广播模式
Redis命令: CLIENT TRACKING ON BCAST
在广播模式下,Redis会发送给启用客户端缓存追踪的所有客户端发送缓存失效消息,无论特定的键是否缓存在客户端中。
优点:
没有在Redis服务器实例中显著使用内存。
缺点:
需要更多的网络带宽。
3. 带注册前缀的广播模式
Redis命令: CLIENT TRACKING ON BCAST PREFIX key_prefix_value
在广播模式下,可以通过注册键前缀方式来限制在键被更新的情况下,只有注册特定键前缀的客户端才会收到缓存失效的消息。
需要注意的地方是:
1. 键的名字需要仔细定义,因为这样可以减少缓存失效消息的数量。
2. 多个键前缀可以被同个客户端指定。
3. 可以通过键前缀来告诉redis哪些键会被客户端缓存而那些不会,例如:
clientSide:MyAppCode:keyname和MyAppCode:keyname。
4.默认模式中的Optin 模式
Redis命令:CLIENT TRACKING ON OPTIN
在Opt in模式下,客户端将收到所指定的键缓存失效的消息,在默认模式中,所有键是默认注册的,但在Opt in模式下,需要显式指定哪些键需要被注册。指定键被注册的命令是CLIENT CACHING YES,接下来的一个读请求的键将会被注册在Redis服务器端的追踪表里,当这个键被更新时客户端会收到缓存失效消息。
例子如下:
CLIENT CACHING YES
+OK
GET MYKEY1
$8
MyValue6
现在如果MYKEY1的值被改变,则客户端会收到缓存失效消息。
5 默认模式中的Opt Out模式
Redis 命令: CLIENT TRACKING ON OPTOUT
和OPTIN 模式相反,在OPTOUT模式下客户端键默认会被追踪,需要显式指定哪些键不需要被追踪。
如果需要关闭特定键的追踪,需要向Redis发送读请求之前使用CLIENT CACHING NO命令。
例子如下:
CLIENT CACHING NO
+OK
GET MYKEY2
$8
MyValue2
现在如果MYKEY2的值被改变,客户端不会收到缓存失效的消息。
在介绍完客户端缓存追踪的几种模式后,下一个问题就是在何种情况下需要使用何种模式。这个问题实际上跟具体的应用需求有关,实际上是在Redis内存使用和整个系统网络资源上做取舍。
你的应用是否有很多缓存更新的场景?如果不是的话可以选用广播模式,因为在这种场景下大部分的键不会被更新,所以没有必要在Redis端记住所有的键信息。
相反的,如果应用相对来说有很多更新缓存键的应用场景,那么可以选用默认模式,尤其当有很多客户端,但每个客户端缓存键的数量相对较少的情况下。默认模式是最好的选择。
另外在我们的设计中,我们会把CLIENT ID 也放到缓存无效信息中,这样特定客户端会忽略自己触发的的缓存失效消息。(注在新版本的Redis 6.0.4中,可以使用NOLOOP来达到同样的效果)
另外需要留意的是客户端追踪可以指定另一个REDIRECT选项,这个选项主要是为RESP2(旧版本)协议的客户端提供的。因为在旧版本的协议中,不支持从Redis服务器端向客户端推送消息。所以这个选项的作用是将缓存失效的消息推送到额外指定的客户端。
具体的使用方法是:
1. 在客户端启用客户端缓存前,创建一个新的客户端,使用CLIENT ID命令记录下这个客户端的ID,让后使用SUBSCRIBE redis:invalidate来订阅缓存失效消息的频道。
2. 在启用客户端缓存的时候使用这个客户端ID来接收无效消息,例如如果ID为5,则使用CLIENT TRACKING YES REDIRECT 5。
3. 这样缓存无效消息将发送到这个指定客户端中,但是需要注意的是这种方式会潜在带来潜在的竞态条件。因为如果同时有另外客户端更新Redis中的键数据,无法保证客户端收到缓存失效消息的时间。
在新版本的Redis RESP3协议中支持从Redis服务器端推送消息,但在RESP2协议中只支持客户端发送请求Redis服务器端处理并回复。
1. 现在客户端可以使用两种不同版本的协议。
2. 不需要创建新的TCP连接来接收缓存失效消息。创建新的连接对Paylocity来说是一个很大的问题,因为我们使用多个Redis集群,每个客户端保留向集群中每一个节点的连接。
3. 但现在RESP3协议的主要问题是大部分的客户端库都没有支持这个协议。
下面我们讨论使用客户端追踪的应用具体实现步骤:
1. 在客户端中,创建客户端缓存并连接Redis
2. 使用CLIENT TRACKING ON 来启用追踪。
3. 更新数据时,更新Redis 和相应的客户端缓存。需要记住的是Redis是单一数据来源。
4. 在读取数据过程中,先从客户端缓存中读取,如果未找到数据则在Redis中读取。如果在Redis中找到数据,则更新客户端本地缓存,这样的话下个请求将会通过本地缓存拿到新的数据。同时也需要从Redis中读取TTL并设置本地缓存过期时间。
5. 监听连接的无效消息频道,如果客户端接收到Redis发送的缓存失效消息,则更新本地缓存。
Paylocity的计划:
利用Redis的客户端追踪功能:
像之前介绍的那样,我们有比较少的web服务器,而且在大多数情况下键值不会经常改变,所以广播模式比较适用于这种场景。
广播前缀的方式非常适用于我们的场景,因为我们会创建一个大的Redis集群并共享给各个应用。所以我们使用应用代号来当作BROADCAST的前缀。
使用RESP3客户端:
1. 可以极大的减少总的Redis连接数
2. 目前我们使用StackExchange Redis客户端,一个非常好的客户端,只是不确定以后对RESP3协议的支持。
3. 如果我们自己实现redis客户端的话也不会有大的问题,因为我们只需要支持GET,SET 和接收缓存失效消息。
以下作者提供了使用Redis客户端缓存支持的例子:
https://github.com/bmalec/RedisClientTrackingDemo