【深度学习】-走迷宫任务学习一(实现智能体随机移动)
深度强化学习之走迷宫学习一
-
- 建立迷宫
- 智能体的实现
本文档用于深度强化学习的学习记录,首先通过迷宫任务来学习强化学习过程的基本思想
【迷宫任务进阶】
阶段一:实现一个智能体,该智能体在迷宫中随机搜索并朝目标前进
阶段二:使智能体直接朝目标前进(策略迭代法)
阶段三:价值迭代(对智能体的状态及动作赋予价值),求取价值最大的动作与状态(得到正确的值)
PS:在此先记录阶段一的学习
建立迷宫
# 引入库函数
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
%matplotlib inline
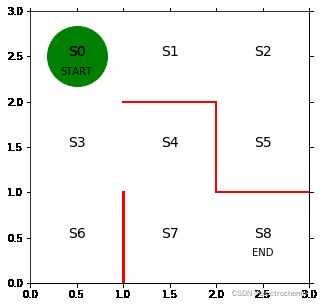
#绘制迷宫初始状态
def plot():
fig=plt.figure(figsize=(5,5))
ax=plt.gca()
# 画墙壁
plt.plot([1,1],[0,1],color='red',linewidth=3)
plt.plot([1,2],[2,2],color='red',linewidth=2)
plt.plot([2,2],[2,1],color='red',linewidth=2)
plt.plot([2,3],[1,1],color='red',linewidth=2)
# 画状态
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(1.5,2.5,'S1',size=14,ha='center')
plt.text(2.5,2.5,'S2',size=14,ha='center')
plt.text(0.5,1.5,'S3',size=14,ha='center')
plt.text(1.5,1.5,'S4',size=14,ha='center')
plt.text(2.5,1.5,'S5',size=14,ha='center')
plt.text(0.5,0.5,'S6',size=14,ha='center')
plt.text(1.5,0.5,'S7',size=14,ha='center')
plt.text(2.5,0.5,'S8',size=14,ha='center')
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(0.5,2.3,'START',ha='center')
plt.text(2.5,0.3,'END',ha='center')
# 设置画图范围
ax.set_xlim(0,3)
ax.set_ylim(0,3)
plt.tick_params(axis='both',which='both',bottom='off',top='off',labelbottom='off',right='off',left='off',labelleft='off')
# 当前位置S0用绿色圆圈
line,=ax.plot([0.5],[2.5],marker="o",color='g',markersize=60)
# 显示图
plt.show()
#函数检测(这是一个静止的显示状态)
fig=plot()
智能体的实现
定义智能体行为方式的规则称为策略,意味着“在状态s下采取动作a的概率遵循由参数theta确定的策略pi”
在任务中,状态s指智能体在迷宫中的位置,动作a指智能体在该状态下可以执行的操作(如向上、向右、向下和向左),参数theta指在状态s下采用该动作的概率。
因此可以将迷宫任务初始状态转化为矩阵
#迷宫初始状态,1表示该方向可以前进,np.nan表示有墙壁而无法前进,[向上,向右,向下,向左]
theta_0=np.array([[np.nan,1,1,np.nan], #S0
[np.nan,1,np.nan,1], #S1
[np.nan,np.nan,1,1], #S2
[1,1,1,np.nan], #S3
[np.nan,np.nan,1,1], #S4
[1,np.nan,np.nan,np.nan], #S5
[1,np.nan,np.nan,np.nan], #S6
[1,1,np.nan,np.nan], #S7
]) # S8位目标 不需要策略
#将对应于前进方向的theta值转换为百分比作为概率
def simple_convert_into_pi_from_theta(theta):
''' 简单计算比率'''
[m,n]=theta.shape # 读取theta矩阵
pi=np.zeros((m,n))
for i in range(0,m):
pi[i,:]=theta[i,:]/np.nansum(theta[i,:]) # 计算比率
pi=np.nan_to_num(pi) # 将nan转换为0,因为朝墙壁方向移动的概率为0
return pi
#初始策略
pi_0=simple_convert_into_pi_from_theta(theta_0)
print("初始策略为pi_0=",pi_0)
初始策略为pi_0= [[0. 0.5 0.5 0. ]
[0. 0.5 0. 0.5 ]
[0. 0. 0.5 0.5 ]
[0.33333333 0.33333333 0.33333333 0. ]
[0. 0. 0.5 0.5 ]
[1. 0. 0. 0. ]
[1. 0. 0. 0. ]
[0.5 0.5 0. 0. ]]
#根据智能体状态实现智能体的随机移动
# 设置状态索引,求一步移动后的状态s
def get_next_s(pi,s):
direction = ["up", "right", "down", "left"]
next_direction=np.random.choice(direction,p=pi[s,:]) # 从direction中以概率p,随机选择方向,s是智能体状态(0-8)
# 根据动作确定下一步状态
if next_direction=='up':
s_next=s-3 # 向上移动 状态数-3
if next_direction=="right":
s_next = s + 1
if next_direction=="down":
s_next = s + 3
if next_direction=="left":
s_next = s - 1
return s_next
#智能体持续移动并达到目标的函数的定义
def goal_maze(pi):
s=0
state_history=[0]#创建列表记录智能体的移动轨迹
while (1):
next_s=get_next_s(pi,s)
state_history.append(next_s)#记录智能体移动轨迹历史
if next_s==8:
break
else:
s=next_s
return state_history
#智能体由状态s0到达目标状态s8所移动的轨迹历史
state_history=goal_maze(pi_0)
print("s0-s8移动记录",state_history)#变化的
print("s0-s8移动步数",len(state_history))#变化的
#因为智能体按概率随机移动,所以每次执行的状态变化的轨迹可能不同
s0-s8移动记录 [0, 3, 6, 3, 4, 7, 8]
s0-s8移动步数 7
以上便是迷宫任务阶段一的实现过程