论文阅读笔记6——FairMOT:On the Fairness of Detection and Re-identification in MOT
这篇文章很好,打算精读。
原文:原文
代码:代码
\space
0.Abstract
传统的MOT方法是将目标探测和重识别分开。但是作者发现两个任务会倾向于相互竞争,这是需要谨慎处理的问题。尤其是检测精度会极大地影响重识别的任务.
因此之前的方法偏向于检测任务,这对于重识别不公平,也就是二者不对等。作者基于无锚的CenterNet提出了FairMOT,但是并不是CenterNet和re-ID的简单结合,而是设计了很多细节,达到了很好的效果。
\space
1.Introduction
传统的方法都是将检测和重识别两个任务分开进行,这些二步的方法不能达到很好的实时的速度,尤其是目标比较多的时候,因为两步之间不分享特征。
随着多任务学习的成熟,one-shot方法(用一个网络估计目标和学习re-ID特征) 得到了更多关注。
例如Voigtlaender et al. 在Mask R-CNN上增加了一个re-ID分支,来提取re-ID的特征,虽然减少了推理时间,但是精度比two-step要差,主要差在跟踪性能上。例如,ID switches显著增加。这说明结合两个任务是个非同小可的任务,应该被谨慎对待。
直接将检测和重识别整成一个网络的失败主要有三个因素:
第一个因素,就是有锚引起的。锚最初是为了检测设计的,但并不适合用来提取re-ID的特征。这一点主要有两个原因:
- 基于锚的one-shot tracker,比如TrackRCNN忽略了re-ID任务,因为它们首先用锚来检测目标然后基于检测结果提取re-ID特征。但是当两个任务有冲突的时候,检测任务会更受偏重。
- 锚也会在训练re-ID的feature过程中造成模糊性,因为锚和目标可能会造成一对多和多对一的关系,尤其在拥挤场景。
第二个因素是由特征共享引起的。对于re-ID feature,通常提取的是较底层的特征,来区分不同id,但检测feature在不同的id上也是相似的。这种冲突和共享特征的初衷相悖,并会造成效果下降。
第三个因素是re-ID feature的维度。过去的工作中,re-ID feature的维度通常都很大,例如512或者1024,比检测的feature大得多。这种不平衡也造成了性能下降,而且作者发现了一个通用规律,那就是用低维的re-ID feature在将检测和重识别联合的网络中会达到更好的精度和效果,这也揭示了MOT和re-ID任务的区别。
为此,作者提出了一个简单的方法,称作FairMOT,优雅地(哈哈哈这个用词很cute)解决了上述的三个问题,FairMOT的基本结构如下图所示:

\space
FairMOT是基于CenterNet(Zhou et al. Objects as points arXiv:1904.07850)设计的。
detection和re-ID是同质(homogeneous)的。detection不用锚,估计目标的中心和size,位置感知的测量map代表了中心和size。类似地,re-ID分支估计每个像素的re-ID特征,以表征以像素为中心的对象。这两个分支是完全同质的,本质上不同于以前执行检测的方法,因此FairMOT消除了以前的检测分支的不公平缺点。
按:和前几天看的TransCenter的基本思路类似,第一都是将detection和association同时进行而不是分为分立的两步,这个思想早在JDE就有了。第二就是都基于pixel做事情,抛弃了anchor。FairMOT参考的是CenterNet,TransCenter参考的是CenterTrack,而CenterNet和CenterTrack的一作是同一个人。
\space
2.Related Works
作者将之前的工作分为两类,即按照是否将检测和数据关联分开进行。
2.1 检测和跟踪分立的
检测方法:(不是很重要)
从最开始的DPM,faster-RCNN,SDP,到后来有人用VGG16。以及有人用级联的RCNN,也取得了很好的效果。
对于跟踪方法,主要有二:
-
基于位置和运动的方法
最开始是SORT和IOU-Tracker。注意IOU-Tracker是不用Kalman滤波的,只依赖于检测框的IOU进行判断,当运动速度很小的时候,效果还不错。当然,SORT和IOU-Tracker比较简单,但是在拥挤的场景和快速运动的情况就歇菜了。
有人借鉴单目标跟踪的方法,但模型速度太慢。
为了解决轨迹分割的问题,长时间的特征学习就变得重要。主要有两个工作。尤其注意MAT,它比较好地考虑了相机运动的问题。 -
还有计算外观特征进行匹配。此部分在其他综述中有更详细的,就不看了。
\space
2.2 检测和跟踪一体的
第一类方法就是将目标探测和re-ID特征提取放在一个网络里,例如Track-RCNN(是将一个re-ID放在一个Mask-RCNN上然后为每个目标回归出一个边界框和re-ID feature)和JDE(基于YOLOv3)。
这种方法可以提高速度,但是精度还是不如两步分立的方法。
第二类方法是联合检测和运动预测。暂略。
FairMOT属于第一种(将检测和re-ID放入一个网络)。作者说他们研究了之前这种方法性能不足的原因(这里没交代,是否主要是因为密集情况下使用检测框?)
CSTrack也是近期的工作,从特征的角度来缓解两个任务之间的冲突,并提出了一个互相关网络模块,使模型能够学习与任务相关的表示。
但是本工作比较系统地从三个角度(这里没交代)解决了之前的问题,而且比CSTrack表现更好。
CenterTrack也与此类似(如之前我说的),都是基于中心点的检测。但是CenterTrack并没有提取外观特征,且只在相邻两帧之间进行关联。FairMOT可以做到用外观特征长时间的关联,而且能处理遮挡的情况。
\space
多任务学习
对于两个同时的任务,如何balance也是一个问题。 有一些工作,一个叫Uncertianty的通过single-task loss来自动调整。MGDA通过找到特定任务的梯度中一个共同的方向更新共享网络的权重。
在后面作者评估了这些工作。
\space
\space
3.One-shot tracker中的不公平问题
前面作者说在One-shot tracker中存在不公平的问题,主要从三个方面说明。一是由于锚引起的不公平问题,二是由特征引起的,三是由特征的维度引起的。在前面都有提到,这里相当于是一个展开。
先总结在这里:
由于锚引起的不公平问题,一是re-ID依赖于检测的结果,这样在训练的时候模型会偏重于检测,这是不公平。但后面说锚和id不是一一对应的问题,会出现一对多多对一这种,但这些我认为本质上还是在特定情况下锚的精准度的问题
跟特征有关的冲突,主要是对特征的深浅层次要求不同和维度的冲突。作者认为re-ID特征不需要那么大的维度。
\space
3.1 锚引起的不公平
第一种不公平是由锚造成的
基于锚的设计并不适用于学习re-ID特征,尽管检测结果良好,但会导致大的ID switches。
从三个角度来解释这个问题:
1.被忽视的re-ID任务。
例如Track RCNN,它是一种级联风格,也就是说先提出目标建议(也就是box),然后再计算box里的特征。这样re-ID特征就很依赖于目标建议的质量。在训练阶段,模型就会很偏重于估计精确的目标建议,而不是高质量的re-ID特征(因为建议不精确,则re-ID特征无意义)。因此这种“检测第一位,re-ID第二位”的策略并不能让re-ID network得到公平的学习。
2.一个锚对应多个id
基于锚的方法通常都是用ROI-Align方法来从建议区域中提取特征。但ROI-Align中很多采样的区域可能属于其他id,这样提取的feature肯定就不是最优的。
(本质还是锚的精细度问题,在拥挤或重叠场景)
ROI-Align:为了解决ROI pooling的精确度提出的方法,ROI Pooling
的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故ROI
Pooling这一操作存在两次量化的过程。量化之后和最开始的位置就会出现偏差。ROI
Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。
3.多个锚对应一个id
他说只要(锚的)IOU的值足够大,就可能使得多个锚对应一个id。并且对于将特征图进行下采样来平衡精度和速度的这种操作,对于检测来说没什么问题,但对于re-ID的特征提取来说就太粗糙了,anchor无法与中心对齐
3.2 特征引起的不公平
如前文所说,检测和re-ID对特征的要求不同。检测通常要求深层的特征,但re-ID通常要求浅层的特征。
3.3 特征维度引起的不公平
作者说还是低维的特征对于one-shot MOT好一些。主要有三个原因:
1.还是两个任务的竞争问题。re-ID的维度高,必然会导致损害检测的精度。因为检测的特征维度通常是比较低的(类的数目+box的位置),这样就造成了一种不平衡。
2.MOT任务和re-ID任务不同。MOT任务只需要在两相邻帧间匹配就行了,但re-ID任务需要将查询和大量候选相匹配,因此要高维,所以在MOT当中不需要高维 (没懂)
3.低维提高速度。
\space
\space
4.FairMOT
4.1 主干网络
在看主干网络之前,先学习一下深层聚集(Deep layer aggregation,DLA)的概念。(参考DLA论文精读)
DLA说白了就是让网络有更立体的结构,而不仅仅是一层一层递进式,来更好地融合block之间的信息。可以分为两种结构:迭代深度聚合和分层深度聚合(iterative deep aggregation (IDA)和hierarchal deep aggregation (HDA)).
DLA采用的聚合结构和现有的特征融合结构最为类似。融合主要从空间和语义两个维度上进行。语义融合,或者说在通道和深度方向上的聚合,能够提高推断“是什么”的能力。而空间信息的融合,或者说在分辨率和尺度上的聚合,可以提高推断“在哪儿”的能力。DLA可以看作是这两种融合的组合技术。
IDA
IDA沿着重复迭代堆叠的主干网络进行。本文中将网络中堆叠起来的的块按照分辨率分成层级,更深的层级有更多语义信息但是空间信息更为粗糙。从浅层到深层的跳跃连接能够融和尺度和分辨率。如下图所示:

HDA
HDA吸收树结构中块和层级,来保留并组合特征通道。通过HDA,浅层和深层的网络层可以组合到一起,这样的组合信息可以跨越各个层级来学习到更丰富的组合信息。IDA虽然能有效的组合层级,但是IDA依旧是呈序列的,它尚不足以融合网络的各个块的信息。结构如下所示:
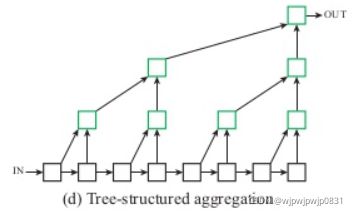
DLA指的是一系列架构族,因此它兼容各种基础主干网络。DLA这种架构对于块与层级的内部架构并没有要求。
DLA的论文里提出了一个Dilated Residual Network,结构跟FairMOT的很像。在层级间采用了IDA连接,在层级内采用了HDA。这些聚合可以通过简单的共享AN(Aggregation Node)来进行组合。
如下图:

\space
FairMOT中Encoder-Decoder的结构如下图所示:

\space
主干网络基于ResNet34,但是采用了DLA的结构,叫做DLA34,如结构图中所示。实际上就是把不同尺度特征给拼接融合,输出的map维度是 C × H × W C\times H\times W C×H×W,其中 H H H和 W W W都是原图尺寸的1/4, C C C是通道数。
值得注意的是,在上采样模块中的卷积层都替换成了可变型卷积,这样就可以根据目标的范围和姿势来动态地调整感受野。
除此之外,其他能提供多尺度卷积特征的网络也可以用,比如Higher HRNet。
\space
4.2 Detection Branch
后面介绍两个branch。Detection Branch是根据CenterTrack做的,但是其他anchor-free的办法也可以
。
大致思路是:
三个并行的heads加在DLA34里,分别估计热度图,目标中心的偏置和边界框的size。
DLA输出了一个feature map,每个head就在这个feature map上进行3x3卷积,有256个通道。然后再经过1x1卷积(应该是为了改变通道数)产生最终的输出。
4.2.1 热度图的loss
负责heatmap的head进行预测以后,产生了一个 1 × H × W 1\times H \times W 1×H×W的headmap。
这里计算loss的方法和TransCenter很像。TransCenter首先想产生一个heatmap的GT,然后以每几个点为中心,计算预测点和GT中心点的高斯函数值,并取最大值。最大值为1表示中心点重合,否则表示不重合,再根据loss进行计算。
对于GT的边界框 b i = x 1 i , y 1 i , x 2 i , y 2 i \textbf{b}_i={x_1^i,y_1^i,x_2^i,y_2^i} bi=x1i,y1i,x2i,y2i,则GT中心点为 c x i = x 1 i + x 2 i 2 c_x^i=\frac{x_1^i+x_2^i}{2} cxi=2x1i+x2i, c y i = y 1 i + y 2 i 2 c_y^i=\frac{y_1^i+y_2^i}{2} cyi=2y1i+y2i.由于feature map的大小为原图大小的1/4,则feature map上的中心点为 c ~ x i , c ~ y i = ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ \widetilde{c}_x^i,\widetilde{c}_y^i=\lfloor \frac{c_x^i}{4} \rfloor,\lfloor \frac{c_y^i}{4} \rfloor c xi,c yi=⌊4cxi⌋,⌊4cyi⌋.
则在坐标 ( x , y ) (x,y) (x,y)处的热度图响应定义为:

其中 N N N是目标个数。
疑问:TransCenter中是max的形式。这里如果有一个点和GT中心点重合,那肯定大于1呀,因为是求和。疑问。
最终的loss为:

其中 M ^ \hat{M} M^是估计值。 α , β \alpha,\beta α,β是参数。
\space
4.2.2 尺寸和偏移的loss
size和offset对于一个像素点都要预测两个量(水平竖直),因此size head S ^ ∈ R 2 × H × W \hat{S}\in\textbf{R}^{2\times H \times W} S^∈R2×H×W,offset同理。
GT size定义为: s i = ( x 2 i − x 1 i , y 2 i − y 1 i ) \textbf{s}^i=(x_2^i-x_1^i,y_2^i-y_1^i) si=(x2i−x1i,y2i−y1i).GT offset定义为: o i = ( c x i 4 , c y i 4 ) − ( ⌊ c x i 4 ⌋ , ⌊ c y i 4 ⌋ ) \textbf{o}^i=(\frac{c_x^i}{4} , \frac{c_y^i}{4})-(\lfloor \frac{c_x^i}{4} \rfloor,\lfloor \frac{c_y^i}{4} \rfloor) oi=(4cxi,4cyi)−(⌊4cxi⌋,⌊4cyi⌋)
offset的意义就在于可以一定程度上弥补下采样带来的损失。
依旧用hat表示估计值,loss如下:
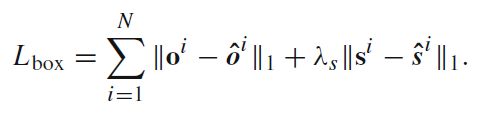
\space
\space
4.3 Re-ID分支
Re-ID branch的任务就是产生能区分不同目标的特征,完成分类任务。 跟detection branch的head类似,用128个kernel来从骨干网络输出的特征上去提取Re-ID特征。这样Re-ID得到的feature map可表示为 E ∈ R 128 × H × W E\in\textbf{R}^{128\times H \times W} E∈R128×H×W
如此每一个像素点的特征就可以用128维的向量表示( E x , y ∈ R 128 E_{x,y} \in\textbf{R}^{128} Ex,y∈R128),当然此方法是基于像素的,因此就只考虑中心点的特征。
Re-ID的loss
loss采用了交叉熵的形式, 具体地,我们知道GTbox,就按照之前的方式预测出的中心点 c ~ x i , c ~ y i \widetilde{c}_x^i,\widetilde{c}_y^i c xi,c yi,我们可以在Re-ID提取的feature map上找到 E c ~ x i , c ~ y i E_{\widetilde{c}_x^i,\widetilde{c}_y^i} Ec xi,c yi。这是一个分类问题,因此经过FC层和全连接层之后就可以输出一个概率向量 P = { p ( k ) , k = 1 , 2 , . . . , K } \textbf{P}=\{p(k),k=1,2,...,K\} P={p(k),k=1,2,...,K},其中 K K K是训练集中所有id的数量,也就是类别的总数。采用one-hot编码,第 i i i个检测是否属于第 k k k类就记作 L i ( k ) \textbf{L}^i(k) Li(k),自然 L i ( k ) ∈ { 0 , 1 } \textbf{L}^i(k)\in\{0,1\} Li(k)∈{0,1}.
综上,Re-ID的loss表示为:

\space
\space
4.4 训练FairMOT
detection分两部分,将detection总的loss表示为:

detection和Re-ID并行训练,为了平衡两个任务的训练程度,采用Kendall et al. 提出的uncertainty loss(JDE也是用的这个):
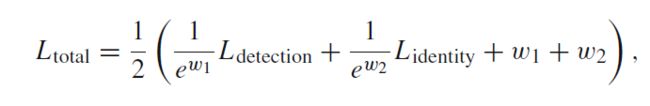
作者做了数据增强,并采用single image training的方法在COCO或CrowdHuman数据集上进行了预训练。
\space
4.5 FairMOT的推理过程
用NMS在feature map上提取最大关键点,然后保留大于阈值的点的位置,然后,根据预测的偏移量和框的大小计算相应的边框。并且在预测的目标中心提取Re-ID特征向量。
之后进行数据关联。数据关联三个阶段:
- 用Kalman滤波和Re-ID特征获得初步结果,匹配的时候还是用的匈牙利算法。
- 对于无法匹配的轨迹和检测,尝试根据它们的框之间的重叠来匹配它们(作者这里没有仔细讲,不知道具体怎么实现的)。作者还时刻更新外观特征来处理外观变化。
- 最后,将未匹配的检测初始化为新的轨迹,并将未匹配的轨迹保存30帧,以备将来再次出现。
\space
Experiments部分就不看了,等用到这个算法的时候再来看技术细节。
\space
FairMOT和JDE、TransCenter都有很多的相似之处。都是one-shot模型,而且和TransCenter一样,都是以像素为单位考虑特征。这篇文章讲得很详细,额外的收获是还学习了DLA。一个不需要让读者频繁点开参考文献的文章就是好文章,哈哈哈哈