Selenium 自动化测试从零实战经验
测试自动化是现在的一种趋势,更是许多厌倦功能测试想转型高端测试的测试从业者的迫切需求。关于测试自动化的资料比比皆是,但是杂乱无章,而且好多知识只是一带而过,并且更多针对 Selenium 这块的测试以 Python 语言居多,Java 语言很少。其实,Java 语言更加灵活,毕竟面向对象语言中 Java 才是当之无愧的王者。
怎样良好的整合 Java 知识与 Selenium 完美结合,是本课要讲解的内容,同时,会以实际案例来逐步引出 Selenium 的使用。课程主要有以下特色:
(1)内容由浅入深,零基础自动化人员也能看得懂。
(2)始终以解决实际问题为出发点,通过实际案例引出 Selenium 的相关知识,最大限度的避免课程枯燥,用生动的语言来描述自动化。
(3)细化每个实施的细节,希望讲解一个知识点就能彻底的讲透,并且会以一种由浅入深的形式进行讲解。
说了这么多,希望读者阅读完全部文章后会以最大限度的掌握自动化,并且爱上自动化!好了,下面开始步入正题。
准备工作
“工欲善其事必先利其器”,做自动化也是如此,所以先花一点时间来介绍要准备的工作。
(1)软件工具准备:JDK 和 Eclipse,搭建 Java 的开发环境,需要注意的是二者的版本必须统一,即 32 位的 JDK 必须对应 32 位的 Eclipse。
(2)框架软件准备:TestNG
安装方式有两种:
1.help-Eclipse Markplace 市场查找下载安装。
2.在 TestNG 官网上下载对应版本的插件,help-Install new Software 安装已经下载好的插件。
当然所有的插件安装都是这两种方式。
(3)Foxfire(火狐浏览器,建议使用 30~32 版本,目前最新的版本兼容性不好且对插件的支持不够理想)。在火狐浏览器里要下载其插件,必须使用的有:
Firebug+firepath 用来辅助我们进行元素定位。
Selenium IDE 主要用来验证自动化脚本是不是与实际情况一致。
需要说明的是,Selenium IDE 本身就有用来做简单 UI 界面录制回放的功能。
(4)Google Chrome(谷歌浏览器),演示的时候可能只调用火狐浏览器,但是谷歌浏览器是当前 UI 自动化测试的首选,因为其稳定,插件更新快。
(5)必要的 jar 包
log4j-1.2.11.jar,用来支持日志功能的 jar。
selenium-server-standalone-2.43.1.jar,核心 jar 必须要有。
(6)浏览器必要的 driver
谷歌的 chromedriver.exe。
IE 的 IEDriverServer64.exe。
Windows 10 自带的 Microsoft Edge 的 Microsoft WebDriver。
写到这里有可能会问,为什么需要这么多的 driver,其实如果只针对一套流程进行自动化操作,只需要操作一个浏览器即可,但是如果想用同一个流程验证不同浏览器的兼容性时,那么需要同时启动多个浏览器,所以提前准备好主流浏览器的 driver,对我们的工作来说是非常有必要的。
上面的工作全都完成,在 Eclipse 里创建一个纯净的自动化工作目录,将下载好的插件、驱动、jar 都配置好,此时 Eclipse 的工程目录如下图所示:
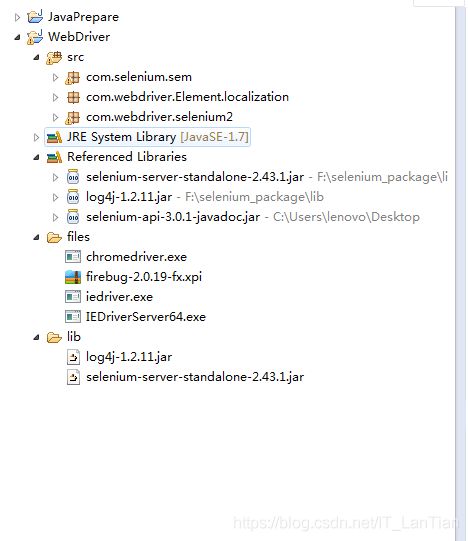
其中 files 是新建的目录,用来存储各种浏览器的驱动。lib 也是新建的目录,用来存储各种 jar 包。当然,这两个文件的名称都可以自行改变。好了准备工作到此结束,下面进行定位的讲解。
定位实战
UI 自动化的实质其实就是做下面两件事情:
定位到 Web 界面的被测试元素;
对定位到的元素进行录入、单击、双击、拖拽、上传文件、清空等等操作的过程。
请看下面的例子。
(1)打开百度网站的首页:

(2)在输入框输入 GitChat:
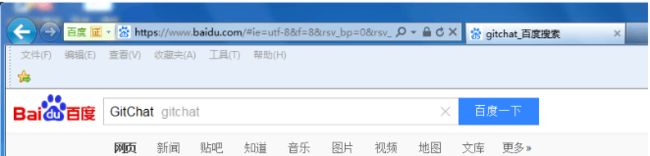
此场景运用自动化的思维解决就是:首先要打开一个浏览器 | 在导航栏处输入百度的网址 | 定位到输入框 | 键盘敲入 GitChat 的过程。操作火狐浏览器实现 Java 代码如下:
package com.test.baidu;import org.openqa.selenium.By;import org.openqa.selenium.WebDriver;import org.openqa.selenium.WebElement;import org.openqa.selenium.firefox.FirefoxDriver;public class Baidu { public static void main(String[] args) { //启动火狐浏览器 WebDriver driver = new FirefoxDriver(); //将导航栏导航到百度首页 driver.navigate().to(“http://www.baidu.com”); //定位到输入框 WebElement element = driver.findElement(By.id(“kw”)); //输入 GitChat element.sendKeys(“GitChat”); }}
这里重点先讲解里面的定位问题:
WebElement element = driver.findElement(By.id(“kw”));
定位方式
常用的定位方式如下:
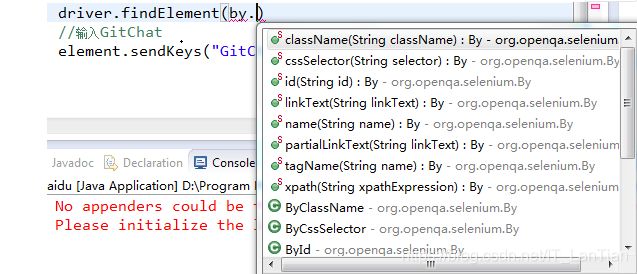
这些都是常用的定位方式,有 by.id、by.name、by.cssSelector、by.xpath 等等。其中除了 by.cssSelector、by.xpath 外,其他的 by 后面的 id、name、link Text 等指的是 HTML 标记语言中页签内的属性内容,如百度输入框的 HTML 源代码如下:
这段代码里的 class、id 就是属性。所以针对百度输入框我们使用的是其 id 的属性。
xpath 定位
首先要明白为什么使用 xpath 定位,它的好处有如下几个方面:
方便维护
定位准确
推荐以后大家无论任何被测试对象都采用 xpath 定位的方式
其次需要了解 xpath 常用符号说明,常用的符号及含义如下所示:
/:表示绝对路径,绝对路径是指从跟目录开始
//:表示相对路径
.:表示当前层
…:表示上一层
*:表示通配符
@:表示属性
[]:属性的判断条件表达式
最后运用上面的符号结合 xapth 的相关语法进行定位演示。
演示场景
任找一个 HTML 网页进行定位实战,按照页面代码结构逐级定位得出的结果解释如下,希望通过下面的逐级定位内容能理解相对路径、HTML 的层级结构。
(1)/html/div:没有节点可以被选择,因为 / 代表绝对路径,本定位表示的是 HTML 下一级目录的元素,很明显 HTML 的下一级是 head 和 body,所以本写法无法定位到任何元素。
(2)/html//div:选中 HTML 标签中的所有 div 元素,// 相对路径。就完全等价于 //div 的写法。
(3)//div/div 表示所选择的 div 元素下又包含 div 元素的所有元素。此时完全等价于 //div/div/. 的写法。
(4)//div/div/…:表示 //div/div 定义到的上一层 div 上。
(5)//div/div/*:此时会将 div 下的子节点含有 div 的这层节点下的所有元素都匹配到。
(6)//div[@id=“input”]:此时表示在 div 目录下选择一个 id=input 的子节点。
and 与 or 连接符在 xpath 中的使用
and 的使用:此种定位的应用场景为下图所示:

此种场景的 HTML 编码为:
Saab
Opel
Audi
此时我们想定位到 Saab 怎么写呢?(当然也可以不使用 and 连接符进行书写)书写为://input[@class=“Saab” and @name=“identity”],当然若写成 //input[@class=“Saab”] 肯定也不会有问题。
or 的使用:如果定位到 Saab 或者定位到 Opel,此时书写方式为://input[@class=“Saab” or @class=“Opel”]。
定位顺序(从1开始切记)
现在学习第二种方式,比如定位 Saab。可以这样写://input[@name=‘identity’][2],同理定位 Volvo,//input[@name=‘identity’][1](这就是一开始强调的,这种写法必须从 1 开始编号)。
定位 Opel,写成://input[@name=‘identity’][3]
定位 Audi,写成://input[@name=‘identity’][4]
常用函数
Xpath 定位还可以使用一些函数,常用的函数如下:
(1)contains():包含。若要匹配出 Saab 还可以这样写://input[@name=“identity” and contains(@class,‘S’)]
(2)text():一个节点的文本值。举个例子,这里面篮字显示的英文结果,HTML 代码为:
英文结果
可见这四个字没有任何属性值信息,所以定位此信息的时候需要使用 text() 函数。场景如下图所示:
此时定位英文结果即可使用://a[text()=“英文结果”]
(3)last()函数,定位 Audi 写成 //input[@name=‘identity’][4],可以看到 Audi 这个元素本身就处于 input 最后一个了,此时可以使用 last() 函数进行匹配://input[@name=“identity”][last()]。
(4)starts-with:以 starts-with 为开头写法实例://input[starts-with(@id,‘user’)]代表 input 下 id 以 user 为开头的元素。
(5)not():表示否定,一般情况下会与返回值为 true 或者 false 的函数组合起来使用。比如上面提到的 contains() 与 starts-with。
用实例来说:现在想要定位到不是 Audi 车除外的三种车元素,此时写法为://input[@name=“identity” and not (contains(@class,‘A’))]。
当然 not() 还有一种特殊用法就是直接 Not。//input[not(@class)] 表示匹配出 input 下所有不含 class 属性的元素。
总结:唯一需要注意的是所有函数的写法 function(@属性,‘内容’)。
Xpath 轴定位说明
(1)基本轴
轴可以在位置路径中快捷引用特定的节点(忽略属性和名称空间节点)。child 例子:
“child::" 当前节点的子节点。 “child::childnodename” 当前节点名为childnodename的子节点。 “child::text()” 当前节点文本子节点。 “child::node()” 当前节点的子节点。 "child::/child::nodename” 取当前节点的子节点的名为nodename的子节点。
(2)特殊轴
self当前节点descendant当前节点的后代(子节点或子节点的子节点…)parent当前节点的父节点ancestor当前节点的祖先节点(父节点和父节点的父节点…)preceding按文档顺序位于当前节点之前的非祖先节点attribute当前节点的属性namespace当前节点的名称空间preceding-sibling当前节点之前的所有兄弟节点following当前节点之后的所有节点following-sibling当前节点之后的所有兄弟节点descendant-or-self当前节点和后代节点ancestor-or-self当前节点和祖先节点
以上的两种轴类型,没什么好说的,先记住吧。具体怎么用请看下面实例。
第一个实例:继续定位上述中的 Volvo,使用 xpath 轴书写如下://div[@id=“radio”]/descendant::input[1] 也可以定位到。
第二个实例:定义 Audi 上的所有节点,使用 xpath 轴写法如下://input[@name=“identity” and @class=“Audi”]/preceding-sibling:
(3)需要注意的几个问题。
[] 后面需要跟 /,/ 后面在加上关键字。
轴关键字后面必须使用 ::,这个后面可以接节点名称,如 input、div 等。如果后面跟的是 *,代表全部。
轴后面接节点名称是节点前面的定位方式全部可以继续适用。
对于轴的使用建议是能不用就不用,条条大路通罗马,没必要非使用轴进行定位。
cssSelector 定位
了解即可,能用 xpath 就不用 cssSelector。原因很简单,HTML 的代码我们更熟悉。
CSS 常用符号说明
1.#表示 id
2… 表示class
3.:表示子元素,层级
值得注意的是:一个空格也表示子元素,但是所有的后代子元素,就相当于 xpath 中的相对路径。
上面是我收集的一些视频资源,在这个过程中帮到了我很多。如果你不想再体验一次自学时找不到资料,没人解答问题,坚持几天便放弃的感受的话,可以加入我们群【902061117】,里面有各种软件测试资源和技术讨论。
当然还有面试,面试一般分为技术面和hr面,形式的话很少有群面,少部分企业可能会有一个交叉面,不过总的来说,技术面基本就是考察你的专业技术水平的,hr面的话主要是看这个人的综合素质以及家庭情况符不符合公司要求,一般来讲,技术的话只要通过了技术面hr面基本上是没有问题(也有少数企业hr面会刷很多人)
我们主要来说技术面,技术面的话主要是考察专业技术知识和水平,上面也是我整理好的精选面试题。
加油吧,测试人!如果你需要提升规划,那就行动吧,在路上总比在起点观望的要好。事必有法,然后有成。
资源不错就给个推荐吧~