redis的前世今生(一)
写在文章之前
redis刚学时只了解了个大概,操作了下基本的增删改查,也没有练手它的常见应用场景,所以对于底层原理和实现过程都不清楚了解。最近在填以前落下的坑,这里记录下redis。深入学习了一番,发现有不少知识盲区,更多陌生的词出现了,或许这就是学习的常态吧。
什么是redis
说到redis,就不能不说下nosql。
redis是一个nosql(not only sql)数据库,翻译成中文叫做非关系型型数据库。
什么是nosql?
NoSQL,泛指非关系型的数据库,它可以作为关系型数据库的良好补充。随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速。而传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,例如:
1、High performance - 对数据库高并发读写的需求
web2.0网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。关系数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘IO就已经无法承受了。其实对于普通的BBS网站,往往也存在对高并发写请求的需求,例如网站的实时统计在线用户状态,记录热门帖子的点击次数,投票计数等,因此这是一个相当普遍的需求。
2、Huge Storage - 对海量数据的高效率存储和访问的需求
类似Facebook,twitter,Friendfeed这样的SNS网站,每天用户产生海量的用户动态,以Friendfeed为例,一个月就达到了2.5亿条用户动态,对于关系数据库来说,在一张2.5亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。再例如大型web网站的用户登录系统,例如腾讯,盛大,动辄数以亿计的帐号,关系数据库也很难应付。
3、High Scalability && High Availability- 对数据库的高可扩展性和高可用性的需求
在基于web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,为什么数据库不能通过不断的添加服务器节点来实现扩展呢?
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
| 键值(Key-Value)存储数据库 | 列存储数据库 | 文档型数据库 | 图形(Graph)数据库 | |
|---|---|---|---|---|
| 相关产品 | Redis、Voldemort、Berkeley DB | Cassandra, HBase, Riak | CouchDB、MongoDB | Neo4J、InfoGrid、Infinite Graph |
| 典型应用 | 内容缓存,主要用于处理大量数据的高访问负载。 | 分布式的文件系统 | Web应用(与Key-Value类似,Value是结构化的) | 社交网络 |
| 数据模型 | 一系列键值对 | 以列簇式存储,将同一列数据存在一起 | 一系列键值对 | 图结构 |
| 优势 | 快速查询 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 数据结构要求不严格 | 利用图结构相关算法 |
| 劣势 | 存储的数据缺少结构化 | 功能相对局限 | 查询性能不高,而且缺乏统一的查询语法 | 需要对整个图做计算才能得出结果,不容易做分布式的集群方案 |
Redis简介
Redis 的全称是:Remote Dictionary Server,本质上是一个 Key-Value 类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据 flush 到硬盘上进行保存。因为是纯内存操作,Redis 的性能非常出色,每秒可以处理超过 10 万次读写操作,是已知性能最快的Key-Value DB。Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存 1MB 的数据,因此 Redis 可以用来实现很多有用的功能。
另外 Redis 也可以对存入的 Key-Value 设置 expire 时间,因此也可以被当作一 个功能加强版的memcached 来用。Redis 的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis 支持哪几种数据类型?
String、List、Set、Sorted Set、hashes
redis采用key-value的方式存储数据:
- key-value速度快
- redis存储的只有部分数据,如果采用的是sql那样的表结构,很多数据查不到
redis 与memcache 的区别:
memcache ——> 数据向计算移动
redis ——> 计算向数据移动
Redis 相比 memcached 有哪些优势?
(1) memcached 所有的值均是简单的字符串,redis 作为其替代者,支持更为丰富的数据类型
(2) redis 的速度比 memcached 快很多
(3) redis 可以持久化其数据
Redis的应用场景
- 缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
- 分布式集群架构中的session分离。
- 聊天室的在线好友列表。
- 任务队列。
- (秒杀、抢购、12306等等) 应用排行榜。
- 网站访问统计。
- 数据过期处理(可以精确到毫秒)
redis底层原理
redis使用的是IO多路复用模型,而IO多路复用模型的前身是BIO和NIO,也需了解下。
BIO
有了Block的定义,就可以讨论BIO和NIO了。BIO是Blocking IO的意思。在类似于网络中进行read, write, connect一类的系统调用时会被卡住。
举个例子,当用read去读取网络的数据时,是无法预知对方是否已经发送数据的。因此在收到数据之前,能做的只有等待,直到对方把数据发过来,或者等到网络超时。
对于单线程的网络服务,这样做就会有卡死的问题。因为当等待时,整个线程会被挂起,无法执行,也无法做其他的工作。
顺便说一句,这种Block是不会影响同时运行的其他程序(进程)的,因为现代操作系统都是多任务的,任务之间的切换是抢占式的。这里Block只是指Block当前的进程。
于是,网络服务为了同时响应多个并发的网络请求,必须实现为多线程的。每个线程处理一个网络请求。线程数随着并发连接数线性增长。这的确能奏效。实际上2000年之前很多网络服务器就是这么实现的。但这带来两个问题:
- 线程越多,Context Switch就越多,而Context Switch是一个比较重的操作,会无谓浪费大量的CPU。
- 每个线程会占用一定的内存作为线程的栈。比如有1000个线程同时运行,每个占用1MB内存,就占用了1个G的内存。
问题的关键在于,当调用read接受网络请求时,有数据到了就用,没数据到时,实际上是可以干别的。使用大量线程,仅仅是因为Block发生,没有其他办法。
当然你可能会说,是不是可以弄个线程池呢?这样既能并发的处理请求,又不会产生大量线程。但这样会限制最大并发的连接数。比如你弄4个线程,那么最大4个线程都Block了就没法响应更多请求了。
要是操作IO接口时,操作系统能够总是直接告诉有没有数据,而不是Block去等就好了。于是,NIO登场。
NIO
NIO是指将IO模式设为“Non-Blocking”模式。在Linux下,一般是这样:
void setnonblocking(int fd) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
再强调一下,以上操作只对socket对应的文件描述符有意义;对磁盘文件的文件描述符做此设置总会成功,但是会直接被忽略。
这时,BIO和NIO的区别是什么呢?
在BIO模式下,调用read,如果发现没数据已经到达,就会Block住。
在NIO模式下,调用read,如果发现没数据已经到达,就会立刻返回-1, 并且errno被设为EAGAIN。
在有些文档中写的是会返回
EWOULDBLOCK。实际上,在Linux下EAGAIN和EWOULDBLOCK是一样的,即#define EWOULDBLOCK EAGAIN
于是,一段NIO的代码,大概就可以写成这个样子。
struct timespec sleep_interval{.tv_sec = 0, .tv_nsec = 1000};
ssize_t nbytes;
while (1) {
/* 尝试读取 */
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) {
if (errno == EAGAIN) { // 没数据到
perror("nothing can be read");
} else {
perror("fatal error");
exit(EXIT_FAILURE);
}
} else { // 有数据
process_data(buf, nbytes);
}
// 处理其他事情,做完了就等一会,再尝试
nanosleep(sleep_interval, NULL);
}
这段代码很容易理解,就是轮询,不断的尝试有没有数据到达,有了就处理,没有(得到EWOULDBLOCK或者EAGAIN)就等一小会再试。这比之前BIO好多了,起码程序不会被卡死了。
但这样会带来两个新问题:
- 如果有大量文件描述符都要等,那么就得一个一个的read。这会带来大量的Context Switch(
read是系统调用,每调用一次就得在用户态和核心态切换一次) - 休息一会的时间不好把握。这里是要猜多久之后数据才能到。等待时间设的太长,程序响应延迟就过大;设的太短,就会造成过于频繁的重试,干耗CPU而已。
要是操作系统能一口气告诉程序,哪些数据到了就好了。
于是IO多路复用被搞出来解决这个问题。
IO多路复用
IO多路复用(IO Multiplexing) 是这么一种机制:程序注册一组socket文件描述符给操作系统,表示“我要监视这些fd是否有IO事件发生,有了就告诉程序处理”。
IO多路复用是要和NIO一起使用的。尽管在操作系统级别,NIO和IO多路复用是两个相对独立的事情。NIO仅仅是指IO API总是能立刻返回,不会被Blocking;而IO多路复用仅仅是操作系统提供的一种便利的通知机制。操作系统并不会强制这俩必须得一起用——你可以用NIO,但不用IO多路复用,就像上一节中的代码;也可以只用IO多路复用 + BIO,这时效果还是当前线程被卡住。但是,IO多路复用和NIO是要配合一起使用才有实际意义。因此,在使用IO多路复用之前,请总是先把fd设为O_NONBLOCK。
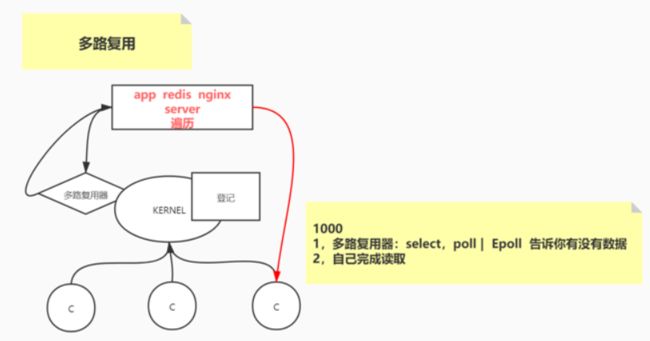
Redis为什么是单线程(redis6之后采用多线程)
注意:redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块仍用了多个线程。
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽,既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
多路I/O复用模型,非阻塞IO
下面举一个例子,模拟一个tcp服务器处理30个客户socket。 假设你是一个监考老师,让30个学生解答一道竞赛考题,然后负责验收学生答卷,你有下面几个选择:
-
第一种选择:按顺序逐个验收,先验收A,然后是B,之后是C、D。。。这中间如果有一个学生卡住,全班都会被耽误。 这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
-
第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
-
第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。。。 这种就是IO复用模型,Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。 这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。
针对上面的举例在Redis中表现为
有30个redis客户端(考生)与redis服务器的网络连接模块(监考老师)保持TCP连接,客户端会不定时的发送请求给服务器,当有一个redis客户端发起请求,会触发unix系统像epoll这样的系统调用,Redis的I/O 多路复用模块封装了底层的epoll这样的 I/O 多路复用函数,然后转发到相应的事件处理器。
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD(文件描述符),当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
redis的持久化方式:
将内存中的数据异步写入硬盘中,两种方式:RDB(默认)和AOF
| RDB | AOF | |
|---|---|---|
| 原理 | 通过bgsave命令触发,然后父进程执行fork操作创建子进程,子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换(定时一次性将所有数据进行快照生成一份副本存储在硬盘中) | 开启后,Redis每执行一个修改数据的命令,都会把这个命令添加到AOF文件中。 |
| 优点 | 是一个紧凑压缩的二进制文件,Redis加载RDB恢复数据远远快于AOF的方式。 | 实时持久化。 |
| 缺点 | 由于每次生成RDB开销较大,非实时持久化。 | 所以AOF文件体积逐渐变大,需要定期执行重写操作来降低文件体积,加载慢。 |
参考文章:
链接:https://www.2cto.com/database/201711/697225.html 作者:想进步总不是坏事
链接:https://juejin.im/post/5caae9876fb9a05e1530288b 作者:java后端技术
链接:https://www.zhihu.com/question/32163005/answer/55772739 作者:罗志宇
链接:https://www.jianshu.com/p/ef418ccf2f7d 作者:大宽宽