Kubernetes 笔记(一) -- Kubernetes 集群架构
1. Kubernetes 集群架构
Kuberetes 本身是由一系列组件组成的容器编排系统,每个组件各司其职从而实现容器的调度、部署以及自动伸缩等功能。
Kubernetes 整体的架构图
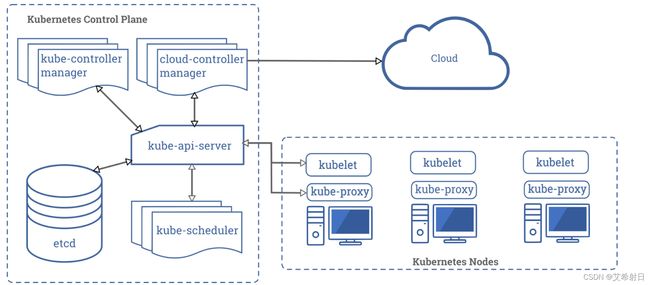
1.1 Master (Control Plane)节点
集群中的控制节点,为单数数量,运行集群中的控制面板逻辑的相关组件。kube-system namespace 下的资源都会在这一个或者多个Master 节点上运行,且默认会有node-rule.kubernetes.io/master:NoSchedule 的 taint,用来告知调度模块不要将用户定义的 Pod 等资源划分到这些节点上运行,以便维持集群控制逻辑的所需资源稳定。Master 节点上主要运行的组件有 4 个:
- etcd
- api-server
- controller manager
- scheduler
1.2 Worker节点
实际运行用户应用,部署业务的 Pod 的节点。如架构图所示,每个worker节点都会有 kubelet,kube-proxy 和 container runtime。
1.3 Master 节点组件
etcd
强一致性,高可用,采用 RAFT一致性协议的 key-value 数据库,Kubernetes 用来保存配置,Kuberntes object 等所有集群相关的数据,是 Kubernetes 唯一存储数据的地方。
etcd 采用乐观锁机制控制对所存储资源的访问,其保存的所有资源都有一个资源版本,每次编辑时都会更新。如果资源版与保存的修订版不同,kube-apiserver 会利用它来拒绝冲突的编辑请求。
api-server
api-server 是提供 Kubernetes 控制面板的 API 的前端,采用 RESTful 协议,支持无状态水平伸缩。api-server 是唯一可以与 etcd 通信的组件,其提供了一系列的 CRUD 接口供外部访问以操作数据,它会校验请求中 Pods,Services,ReplicaSet 等object的数据的合法性,同时还会进行身份认证、鉴权、准入控制等操作。
controller-manager
运行一系列的控制器进程,每个控制器都是一个单独的进程,执行基于控制循环的状态拟合,保证集群的运行状态与我们的期望状态保持一致。
一些常见的控制器
- Deployment Controller
- ReplicaSet Controller
- DaemonSet
- Job Controller
scheduler
隶属于Kubernetes控制面板中的重要成员之一,负责监听集群中还未分配到所属节点的 Pod,其根据一系列调度规则,将 Pod 调度到合适的节点运行。
1.4 Worker 节点组件
container-runtime
用于负责运行容器的软件,目前Kubernetes 支持:Docker,containerd,CRI-O 等支持Kubernetes CRI(Container runtime interface) 的所有软件。
CRI(容器运行时接口)于Kubernetes 1.5版引用,是一种插件行的接口,这种接口使得kubelet可以运行各种容器而不需要重新编程,是一种容器标准协议。也就是说,除了Docker外,还可以用其它公司的容器,比如Google自己的rkt容器。
kubelet 会通过 grpc 和 CRI 联系,下面这个图可以清楚看到相关的关系。
目前来说,有两个主流的CRI插件: Redhat的 CRI-O 和 Docker 的 containerd
CRI-O 是Kubernetes CRI 的实现,可以使用兼容OCI(Open Container Initiative)的运行时。它是使用Docker作为kubernetes的运行时的轻量级替代方案。今天,它支持runc和Kata Containers作为容器运行时,但是原则上可以plug in 任何符合OCI的容器。
Docker 家的 CRI 是 containerd,也是默认和最流行的CRI插件。

Kubelet
Kubelet 是一个运行在每个节点上的 agent,用来负责监控容器符合预期地在 Pod 中运行。kubelet会通过各种方式获取到 Pod 的 Spec,以此为依据来负责监控在Kubernetes中,以PodSpec描述创建的容器的运行和健康状态。
kube-proxy
‘
Kube-proxy 一样运行在每节点上,它的角色是一个网络代理,管理在节点上的网络规则,用来允许集群中的 Pod 进行集群内外的网络通讯。一般情况 kube-proxy 会直接使用操作系统提供的网络包过滤层的能力(比如iptable,ipvs),否则它需要自己实际负责流量的分发。
1.5 其他附加组件
CNI plugin
为集群中的 Pod 设置 IP 并实现跨集群的网络通信。
Ingress Controller
该组件基于 Ingress 对外部请求做路由,将 K8s 中的服务暴露给外界访问,最常用的一般是
NGINX Ingress Controlle
Kube DNS
K8s 内部的 DNS 服务,用来对 Service、Pod 做 DNS 解析实现集群内部的服务发现,现在默认使用的是 CoreDNS。
2. Kubernetes 资源对象
Kubernetes 将一切视为资源,在 Kubernetes 系统中,Kubernetes 对象是持久化的实体,其本质是对分布式系统所需要的各种功能的抽象,其表现形式就是 yaml 文件。Kubernetes 基本上就是由 kubectl 命令操作的 yaml 描述文件,下面是一个 yaml 文件示例:
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
一个完整的资源对象的 yaml 文件由四部分组成:
- apiVersion & kind:创建该对象所使用的 Kubernetes API 的版本和对象的类别。
- metadata:元信息,帮助唯一性标识对象的一些数据,包括一个 name 字符串、UID 和可选的 namespace。
- spec:对象规格,不同的对象有不同的 spec,用于定义其相关属性,创建对象时设置其内容,描述我们希望对象所具有的特征,也就是 「期望状态」。
- status: 对象的
「当前状态」,由 Kubernetes 系统组件设置并更新,在创建对象时我们只需要定义上述三部分内容即可。在任何时刻,Kubernetes Control Pannel 都一直积极地管理着对象的实际状态,以使之与期望状态相匹配。
使用 kubectl get objectType objectName -o yaml 可以在命令行上查看资源对象完整的 yaml。比如:
$ kubectl get pod nginx -o yaml
下图是常用的一些 Kubernetes 对象,所有的对象类型可以用下面命令查看:
$ kubectl api-resources
