之前
之前利用Jsoup做了个小DEMO爬取百度免费API(* http://apistore.baidu.com/ ),很简单,用Jsoup就可以做到,因为页面加载后的数据填充到html里面,此时查看源代码会看见数据都在源代码里面,这时候可以利用Jsoup爬取,前几天有个需求要爬取天眼查的数据( http://www.tianyancha.com *),自以为和之前做的DEMO一样,不难,就利用原来的DEMO改改,之后居然获取不到想要的。
需求:搜索(条件包括搜索框,注册资本,地区)
以下是我将要爬取的页面:
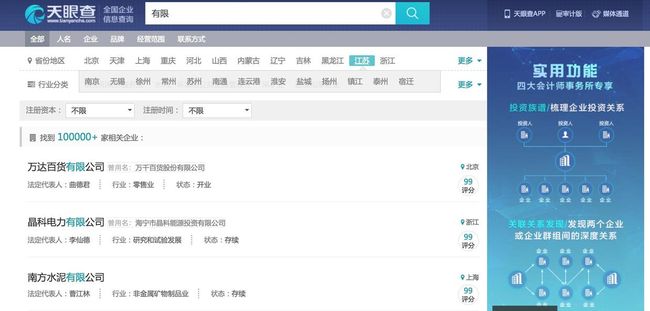
搜索:有限
习惯性审查一下要爬取的元素:
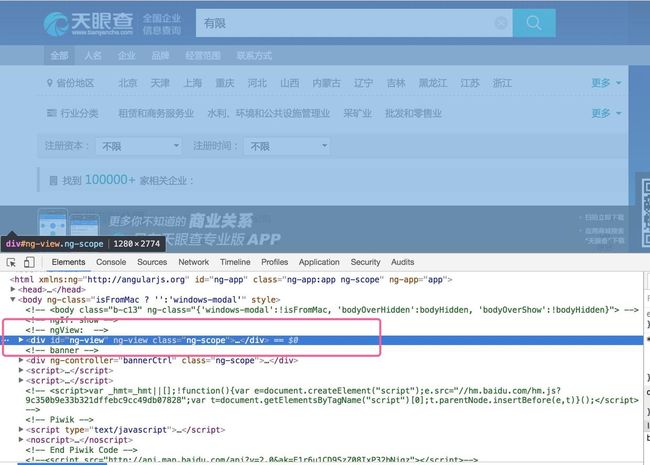
胸有成竹代码就出来:
Document doc = Jsoup.connect("http://www.tianyancha.com/search?key=有限").ignoreHttpErrors(true).timeout(100000).get();
System.out.println(doc.body());
执行--》

WTF?
只有这点东西?明明我审查元素的时候有那么多?为什么抓取出来就这么点?这不科学。
爬取的2个办法:
- 利用Jsoup爬取
- 利用Ajax请求返回的数据
其一不行,取其二
通过Ajax请求数据,再填充到body里面,于是研究Ajax请求,通过Chrome的NetWork可以抓到:

这个接口返回的就是列表的数据,欣喜若狂,这也太简单了,双击访问出现:

WTF²
这。。到底是咋回事
在搜索了很多文章后发现,这个网站本来就是从各大政府网站爬取过来的数据,哪能那么容易就轻松被别人爬取走。况且:

失望中另辟蹊径
失望中又想到另外的办法,既然不能通过Jsoup去爬取,那么是不是有方法可以模拟人为访问,访问后加载完所有的css和js,等数据都返回,再爬取,这不就可以了。
开启搜索引擎一阵搜:
HttpUnit(http://blog.csdn.net/hfhwfw/article/details/37838615)
-
HtmlUnit(https://my.oschina.net/MiniBu/blog/140729) -
WebDriver(https://my.oschina.net/dyhunter/blog/94090)
以上方法都是做自动化测试用的,根本不是用来爬取数据的,所以兼容性不能不是很好。各种尝试都没有得到想要的效果。
最后发现了phantomjs ( http://phantomjs.org/ )。
下载phantomjs后终端就行,加入环境变量自行百度,此处不再多说。
windows下载对应的phantomjs.exe
运行:
/User/music-man/Downloads/phantomjs/phantomjs /User/music-man/Downloads/phantomjs/code.js http://www.tianyancha.com/search?key=有限
注意中间的空格。第一个是phantomjs,第二个是code.js的路径,第三个是爬取的路径。
code.js
system = require('system')
address = system.args[1];
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
console.log(page.content);
phantom.exit();
}
});
此时终端执行命令,发现整个页面已经爬取下来。
接下来就是如何与Java结合了。
执行命令Java可以这么做
Runtime rt = Runtime.getRuntime();
String exec = "/Users/music-man/Downloads/phantomjs/phantomjs /Users/music-man/Downloads/phantomjs/code.js " + url;
Process p = rt.exec(exec);
InputStream is = p.getInputStream();
这样就可以获得输入流了,获得输入流之后想要怎么操作就简单了吧。
获取了文件流,想操作dom,如何操作呢?
看了一下Jsoup,发现
public static Document parse(InputStream in, String charsetName, String baseUri)
第一个参数是输入流,第二个是字符集,第三个是地址:
Document doc = Jsoup.parse(is, "UTF-8", url);
获取到Document再操作dom元素就很明了了。
最后用JFrame做了个界面
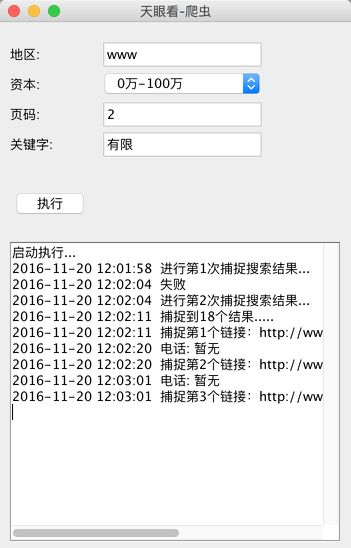
不稳定
执行起来发现不稳定,有时候能爬取到页面,有时候就会失败,让我以为是网站做的限制,后来发现多次重复爬取效率过快的话网站会让输入验证码,导致卡住。
解决
爬取不到我初步怀疑是因为爬取的时候页面还没加载完毕,就进行抓取,有时候网速快,加载好了就能抓取到,有时候没有加载好,爬取失败。看了下phantomjs例子(https://github.com/ariya/phantomjs/blob/master/examples/page_events.js)
发现可以采用js的方法setTimeout
最终code.js改为
system = require('system')
address = system.args[1];
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
window.setTimeout(function () {
page.render("test1.png"); //截图
console.log(page.content);
phantom.exit();
}, 5000);
}
});
增加了setTimeout方法后,等待5s差不多执行完页面和js,此时再去抓取页面,发现成功率大大提高。
(2017年12月05日 删除图片,泄漏隐私了)
抓取到后再把需要的写出文件就可以了。