Redis基础知识点总结
Redis默认端口6379
一、安装
1.去redis.cn看看最新的稳定版下载地址,http://download.redis.io/releases/redis-6.0.6.tar.gz
2.下载 wget http://download.redis.io/releases/redis-6.0.6.tar.gz
3.解压 tar -zxvf redis-6.0.6.tar.gz
4.移动 放到/usr/local/redis目录下 sudo mv redis-6.0.6 /usr/local/redis/ 由于redis目录不存在,所以相当于重命名
5.进入redis目录 cd /usr/local/redis-6.0.6
6.生成 sudo make 由于redis是C语言编写的,这个步骤相当于编译
如果出错,大概率是没安装gcc和make,安装后先make distclean 除编译内容重新编译*
7.测试 sudo make test
8.安装 sudo make install 将redis的命令安装到/usr/local/bin/目录
9.进入/usr/local/bin中查看 cd /usr/local/bin ls -all
10.将配置文件复制到/etc/目录下 配置文件为/usr/local/redis/redis.conf
sudo cp /usr/local/redis/redis.conf /etc/redis/
二、基本使用
启动服务端
redis-server 启动服务端
ps aux|grep redis 查看是否启动
redis-server --help 查看启动的帮助
sudo redis-server /etc/redis/redis.conf 指定加载的配置文件
启动客户端
redis-cli 启动客户端
redis-cli --help 查看启动帮助,可添加参数(主机、端口等等)
redis-cli -h ip地址 -p 端口号
ping
启动客户端后输入ping 如果结果为PONG则表示客户端成功连接redis服务端
select
切换数据库
select 数字 数字范围是0-databases最大值减1
默认是在select 0
help
help 命令名 查看此命令的使用帮助
核心配置选项
配置信息在/etc/redis/redis.conf
bind 127.0.0.1 如果需要远程访问,可将此行注释或者绑定一个真实ip
port 6379 端口号,默认6379
daemonize yes 设置以守护进程运行,no为非守护进程
如果以守护进程运行,则不会在命令行阻塞,类似于服务,保证了redis服务在后台的稳定运行
如果以非守护进程运行,则当前终端被阻塞
databases 16 redis默认有16个数据库
logfile 日志路径
dbfilename dump.rdb 数据文件,默认存放在家目录下
dir /var/lib/redis 数据文件存储路径
slaveof 主从复制,类似于双机备份
三、基本数据结构
redis是key:value的数据结构,每条数据都是一个键值对
键的类型的字符型,且不能重复
值的类型可以有一定的数据结构,可以为字符串string、列表list、哈希hash、集合set、有序集合zset
四、增删改查
string类型
在redis中字符串类型的value最多可以容纳的数据长度是512M
set 设置
set name LiKang
set age 22
get 获取
get name
get age
del 删除
del name
del age
插入的时候设置key的过期时间
setex key 秒数 value
ttl key 查看此key的有效期,-1为永久存在
mset 设置多个key-value
mset name Liang age 22 注意:如果后面还设置了name之前name的值会被覆盖
mget key1 key2 获取多个值
append 追加
append key value
键命令
del key1 key2 删除此key的键值对
keys * 查看都有哪些key
keys a* 查看a开头的key
exists key 查看key是否存在,1则存在,0则不存在
type key 查看此key的value的类型
expire key 秒数 给key设置过期时间
hash类型
key的值为 属性:值,这样的键值对,属性值为string类型
hset key field value 设置
例如hset person name LiKang
hget key field 获取value值
例如hget person name
hmset key field1 value1 field2 value2 设置多个值
hmget key field1 field2 获取多个值
hgetall key 获取此key下的所有键值对
hkeys key 获取此key下的所有属性
hvals key 获取此key下的所有属性值
hdel key field1 field2 删除某个属性
del key 删除此key的键值对
更新的话再hset key field value插入就行,相同字段会自动覆盖原来数据实现更新
list类型
列表元素类型为string,且数据按照插入顺序排序,元素可以重复
lpush 从左边插入
lpush key value1 value2 返回值为key中value的个数
lrange key num1 num2 从左到右获取从num1到num2之间的元素值(包括num2),0代表第一个元素,-1代表最后一个元素,l代表list,不是left
rpush 从右边插入
rpush key value1 value2 返回值为key中value的个数
无rrange命令
lrem key count value 移除数据,l代表list,不是left
count:0 代表删除key中的所有值为value的元素
count>0 删除左边的值为value的元素,删除的个数是count
count<0 删除右边的值为value的元素,删除的个数是count
lset key 下标 value 更新数据
linsert key before(after) value1 value2 在value1的前面(后面)插入value2
set类型
无序集合,元素为string类型,元素具有唯一性,不重复,对于集合没有修改操作
sadd key member1 member2 增加数据
smembers key 获取数据
srem key member 移除数据
zset类型
有序集合,元素类型为string,元素具有唯一性,不重复,每个元素都会关联一个double类型的score,表示权重,通过权重将元素从小到大排序,且没有对于集合修改操作
zadd key score1 member1 score2 member2 增加数据
如果score的值已经存在,则会将新元素插入到与它score值相同的元素的后面或者前面
如果member的值已经存在,则会修改其socre的值为新值
zrange key num1 num2 获取num1到num2之间的数据(包括num2)
zrangeby score key min max 获取score值在min到max之间的成员(包括min和max)
zscore key member 返回member的score值
zrem key member1 member2 删除指定元素
zremrangebyscore key min max 删除score值在min到max范围内的元素(包括min和max)
五、搭建主从
一个master可以拥有多个slave,一个slave又可以拥有多个slave,如此下去,形成来强大的多级服务器集群架构。
master用来写数据,slave用来读数据,经统计,网站的读写比率是10:1,也就是11个用户中只有一个用户在写数据。
通过主从配置可以实现读写分离。
配置主服务器
查看当前主机的ip地址 ifconfig
修改/etc/redis/redis.conf文件 bind 当前主机ip
重启redis服务
sudo service redis stop
sudo redis-server redis.conf
配置从服务器
复制/etc/redis/redis.conf文件 sudo cp redis.conf ./slave.conf
修改slave.conf文件
bind 主机ip (如果是和主服务器为不同电脑,绑定本机ip即可)
port 6378
添加一行slaveof 当前主机ip 主服务器端口(默认6379)
启动redis服务 sudo redis-server slave.conf
查看主从关系 redis-cli -h 当前主机ip info Replication
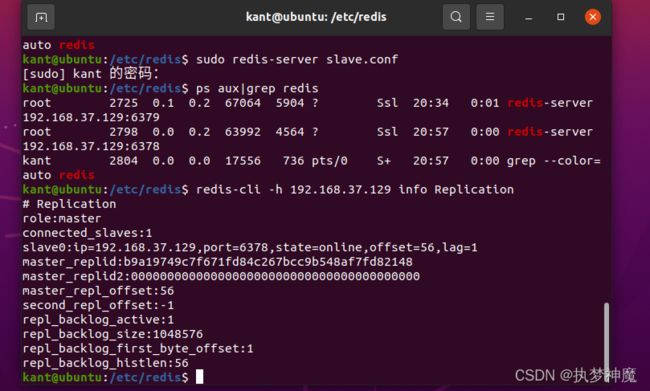
PS:主服务器可读写,从服务器只能读,且主从服务器数据可同步显示
启动redis-cli -h 主机ip -p 端口号
六、搭建集群
虽然一主可以多从,但如果同时的访问量过大(1000w),主服务肯定就会挂掉;获取发生自然灾难,数据服务就挂掉了
大公司都会有很多的服务器。
集群的概念
集群是一组相互独立的,通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户端与集群相互作用时,集群像是一个独立的服务器,集群配置是用于提高可用性和可缩放性。当请求到来时首先由负载均衡服务器处理,把请求转发到另外的一台服务器上。
分类
软件层面:只有一台电脑,在这一台电脑上启动了多个redis服务
硬件层面:存在多台实体的电脑,每台电脑上都启动了一个redis或者多个redis服务
集群的搭建
在一台ubuntu机器上面搭建集群
配置机器1
在Desktop目录下创建一个文件夹“redis_cluster",在此文件夹下创建7000.conf,内容如下
# 端口号
port 7000
# 主机ip
bind 192.168.37.129
# 是否以守护(后台)进程方式运行
daemonize yes
# pid文件
pidfile 7000.pid
# 是否使用集群
cluster-enabled yes
# 集群的文件
cluster-config-file 7000_node.conf
# 集群的超时时间
cluster-node-timeout 15000
# 备份相关
appendonly yes
在”redis_cluster“文件夹下创建7001.conf、7002.conf,除了7000改一下之外,内容和上面一样
配置机器2
和配置机器1一样,在Desktop目录下创建redis_cluster文件夹,里面创建7003.conf、7004.conf、7005.conf,除了把主机ip和7000改一下之外,其他内容都一样。
但是这里只有一台机器,所以也将7003.conf、7004.conf、7005.conf两个文件放在了机器1上
创建集群
先在redis_cluster文件夹下启动redis服务
sudo redis-server 7000.conf
sudo redis-server 7001.conf
sudo redis-server 7002.conf
sudo redis-server 7003.conf
sudo redis-server 7004.conf
sudo redis-server 7005.conf
redis的安装包中包含了redis-trib.rb,用于创建集群
接下来的操作在机器1上进行
将命令复制,这样可以在任何目录下调用此命令
sudo cp /usr/share/doc/redis-tools/examples/redis-trib.rb /usr/local/bin/
redis 5.0之前的版本创建集群
安装ruby环境,因为redis-trib.rb是用ruby开发的
sudo apt-get install ruby
创建集群(必须先开启redis服务)
–replicas 1 表示创建的集群模式是“一主一从”,共三个节点(Node)
redis-trib.rb create --replicas 1 192.168.37.129:7000 192.168.37.129:7001 192.168.37.129:7002 192.168.37.129:7003 192.168.37.129:7004 192.168.37.129:7005
redis 5.0之后的版本创建集群
5.0版本抛弃了redis-trib
直接运行如下命令,–cluster-replicas 1 表示创建的集群模式是“一主一从”,共三个节点(Node)
redis-cli --cluster create 192.168.37.129:7000 192.168.37.129:7001 192.168.37.129:7002 192.168.37.129:7003 192.168.37.129:7004 192.168.37.129:7005 --cluster-replicas 1
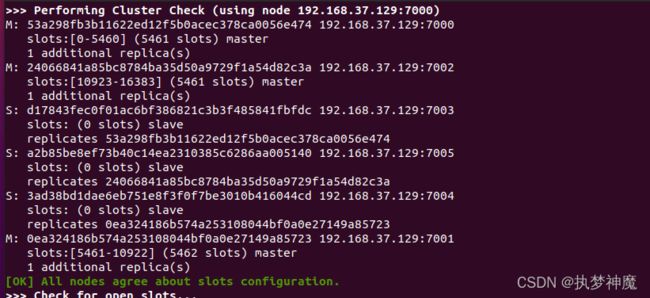
(0 slots)为slave服务,不是0的为master服务(redis 5.0之前的版本不管是slave还是master都显示为master)
连接到集群
redis-cli -h 主机ip -p 端口号 -c
get key 获取数据,如果数据不在当前节点会自动重定向
集群的注意点
在插入数据时,如果是连接的是从服务器,则会通过CRC16算法重定向到其他的一个主服务器进行插入。
如果是连接的是主服务器,也会通过CRC16算法重定向到其他的一个主服务器进行插入。
集群中每个节点都是平等的关系,每个节点都保存了各自的数据和整个集群的状态,每个节点和其他所有节点连接,而且这些连接保持活跃,保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
集群会把数据存在一个master节点,然后在这个master和其对应的slave之间进行数据同步,只有当一个master挂掉之后,才会启动一个对应的slave节点,充当master
必须要有三个或者以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。