注意力机制attention和Transformer
参考文献:https://zhuanlan.zhihu.com/p/146130215
文章目录
-
- 一,注意力机制
- 二,自注意力(self-attention)
- 三,软注意力机制
-
- 1,空域注意力
- 2,通道注意力机制
- 3,混合域模型
- 4,Non-Local
- 5,位置注意力机制
- 四,强注意力机制
- 基于强化学习的注意力机制
- 全局&局部注意力机制
- 多维度注意力机制
- 多源注意力机制
- 层次化注意力机制
- 注意力之上嵌一个注意力机制
- 多跳注意力机制
- 使用拷贝机制的注意力机制
- 基于记忆的注意力机制
- NLP中的attention和transformer
-
- Transformer应用于视觉任务
-
- 图像分类
- 图像处理
一,注意力机制
attention 机制可以认为是一种资源分配的机制,可以理解为对于原来平均分配的资源根据对象的重要程度重新分配资源,重要的单位多分一点,不重要不好的的少分一点,attention的资源分配方式就是权重。
注意力机制的实质:
实质是一个寻址的过程,如上图所示:给定一个任务相关的查询向量q,通过计算与key的注意力分布并附加在Value上,从而计算attention value得分 ,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。
视觉注意力分为几种,核心思想是基于原有的数据找到其之间的关联性,然后突出其某些重要特征,有通道注意力,像素注意力,多阶注意力等,也有把NLP中的自注意力引入
二,自注意力(self-attention)
参考文献:http://papers.nips.cc/paper/7181-attention-is-all-you-need
参考资料:https://zhuanlan.zhihu.com/p/48508221
GitHub:https://github.com/huggingface/transformers
self-attention的计算过程如下:
- 将输入单词转化成嵌入向量;
- 根据嵌入向量得到q,k,v三个向量,分别是query 向量,key向量和value向量
- 为每个向量计算一个score:score=q×v;
- 为了梯度的稳定,Transformer使用了score归一化,即除以sqrt(dk);
- 对score施以softmax激活函数;
- softmax点乘Value值v,得到加权的每个输入向量的评分v;
- 相加之后得到最终的输出结果z。
计算过程: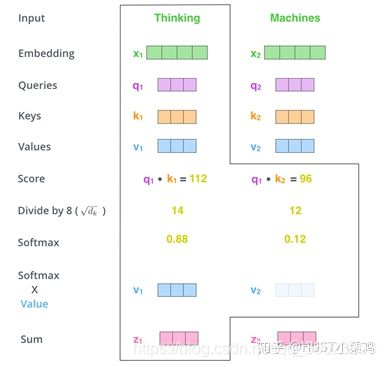
所以输出向量序列可以写为:
H = V ∗ s o f t m a x ( K T Q d 3 ) H=V*softmax(\frac{K^TQ}{\sqrt{d3}}) H=V∗softmax(d3KTQ)
三,软注意力机制
软注意力是一个[0,1]间的连续分布问题,更加关注区域或者通道,软注意力是确定性注意力,学习完成后可以通过网络生成,并且是可微的,可以通过神经网络计算出梯度并且可以前向传播和后向反馈来学习得到注意力的权重
1,空域注意力
论文地址:http://papers.nips.cc/paper/5854-spatial-transformer-networks
GitHub地址:https://github.com/fxia22/stn.pytorch
让神经网络看哪里,感受野位置(原来是权值共享),通过注意力机制,将原始图片中的空间信息变换到一个空间并保留了关键信息,spatial transformer其实就是注意力机制的实现,因为训练出的spatial transformer能够找出图片信息中需要被关注的区域,同时这个transformer又能够具有旋转、缩放变换的功能,这样图片局部的重要信息能够通过变换而被框盒提取出来。
2,通道注意力机制
代表是SENet
论文:Squeeze-and-Excitation Networks(https://arxiv.org/abs/1709.01507)
GitHub地址:https://github.com/moskomule/senet.pytorch
告诉神经网络看什么,卷积网络的每一层都有好多卷积核,每个卷积核对应一个特征通道,相对于空间注意力机制,通道注意力在于分配各个卷积通道之间的资源,分配粒度上比前者大了一个级别。
先Squeeze操作,将各通道的全局空间特征作为该通道的表示,使用全局平均池化生成各通道的统计量
再Excitation操作,学习各通道的依赖程度,并根据依赖程度对不同的特征图进行调整,得到最后的输出。
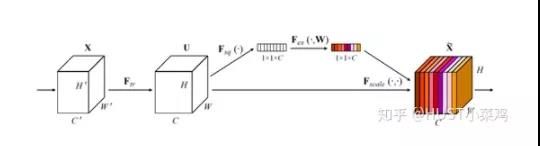
整体结构如上所示。
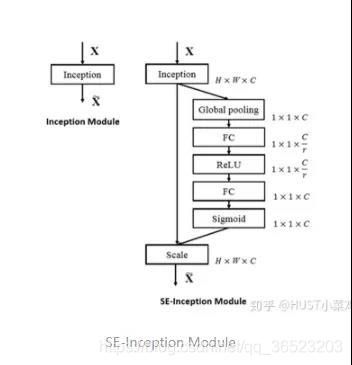
卷积层的输出并没有考虑对各通道的依赖,SEBlock的目的在于然根网络选择性的增强信息量最大的特征,是的后期处理充分利用这些特征并抑制无用的特征。
SE算法流程如下:
1,将输入特征进行全局平均池化,变成11channel
2,然后bottleneck特征交互一下,先压缩channel数,再重构回channel数
3,最后接个sigmoid,生成channel间0~1的attention weights,最后scale乘回原输入特征
3,混合域模型
论文:Residual Attention Network for image classification(CVPR 2017 Open Access Repository)
文章中注意力的机制是软注意力基本的加掩码(mask)机制,但是不同的是,这种注意力机制的mask借鉴了残差网络的想法,不只根据当前网络层的信息加上mask,还把上一层的信息传递下来,这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题。
论文2:Dual Attention Network for Scene Segmentation(CVPR 2019 Open Access Repository)
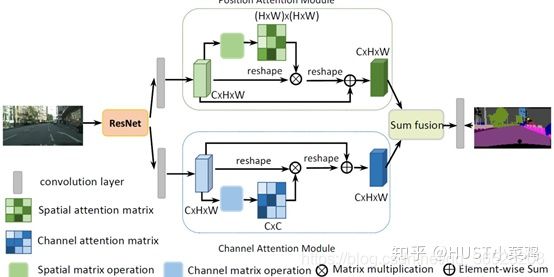
4,Non-Local
论文:non-local neural networks(CVPR 2018 Open Access Repository)
GitHub地址:https://github.com/AlexHex7/Non-local_pytorch
这一方法是针对感受野提出的,感受野都是局部信息local的运算,池化也是的。相反的,non-local指的就是感受野可以很大,而不是一个局部领域。全连接就是non-local的,而且是global的。但是全连接带来了大量的参数,给优化带来困难。卷积层的堆叠可以增大感受野,但是如果看特定层的卷积核在原图上的感受野,它毕竟是有限的。这是local运算不能避免的。然而有些任务,它们可能需要原图上更多的信息,比如attention。如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息。
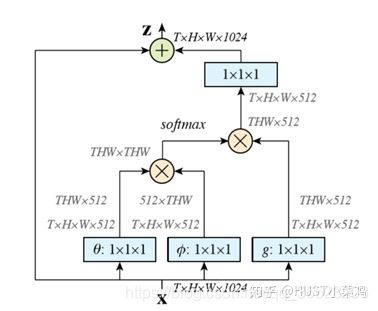
算法流程如下:
1,首先对输入的 feature map X 进行线性映射(通过1x1卷积,来压缩通道数),然后得到 θ,ϕ,g 特征,2,通过reshape操作,强行合并上述的三个特征除通道数外的维度,然后对 进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系)
3,然后对自相关特征 以列or以行(具体看矩阵 g 的形式而定) 进行 Softmax 操作,得到0~1的weights,这里就是我们需要的 Self-attention 系数;
4,最后将 attention系数,对应乘回特征矩阵g中,然后再上扩channel 数,与原输入feature map X残差
5,位置注意力机制
论文:CCNet: Criss-Cross Attention for Semantic Segmentation(ICCV 2019 Open Access Repository)
Github地址:https://github.com/speedinghzl/CCNet
该方法的亮点是减少了参数量。
attention map计算的是所有像素与所有像素之间的相似性,空间复杂度为(HxW)x(HxW),而本文采用了criss-cross思想,只计算每个像素与其同行同列即十字上的像素的相似性,通过进行循环(两次相同操作),间接计算到每个像素与每个像素的相似性,将空间复杂度降为(HxW)x(H+W-1)
与non-local相比,CCnet的区别。
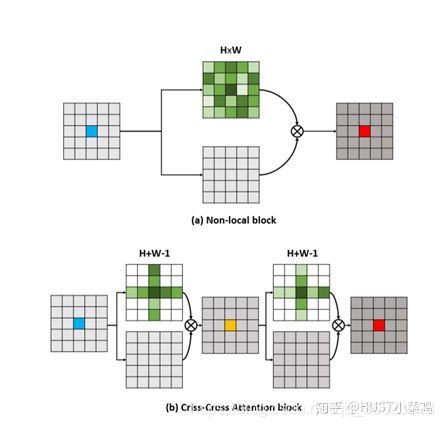
在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。和non-local的方法相比极大的降低了计算量,同时采用二阶注意力,能够从所有像素中获取全图像的上下文信息,以生成具有密集且丰富的上下文信息的新特征图。在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
四,强注意力机制
0/1问题,哪些被attention,哪些不被attention。更加关注点,图像中的每个点都可能延伸出注意力,同时强注意力是一个随机预测的过程,更加强调动态变化,并且是不可微,所以训练过程往往通过增强学习。
基于强化学习的注意力机制
选择性的Attend输入的某个部分
全局&局部注意力机制
多维度注意力机制
多源注意力机制
层次化注意力机制
注意力之上嵌一个注意力机制
多跳注意力机制
论文:NIPS2017:Convolutional Sequence to Sequence Learning
使用拷贝机制的注意力机制
论文:NIPS2015:Pointer Network
基于记忆的注意力机制
NLP中的attention和transformer
自Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合RNN和attention的模型。之后google又提出了解决Seq2Seq问题的Transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩。下面主要介绍《Attention is all you need》这篇文章.
attention原理
-
核心思想
Attention的思想理解起来比较容易,就是在decoding阶段对input中的信息赋予不同权重。在nlp中就是针对sequence的每个time step input,在cv中就是针对每个像素点。 -
原理解析
-
模型分类
-
优缺点
Transformer模型原理详解
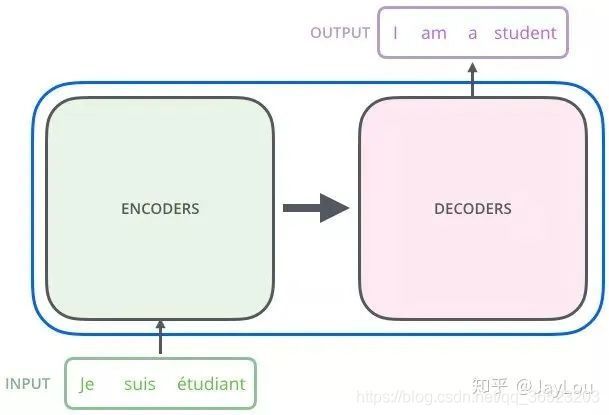
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
是seq2seq模型 Transformer=Transformer Encoder+Transformer Decoder
结构细节图:
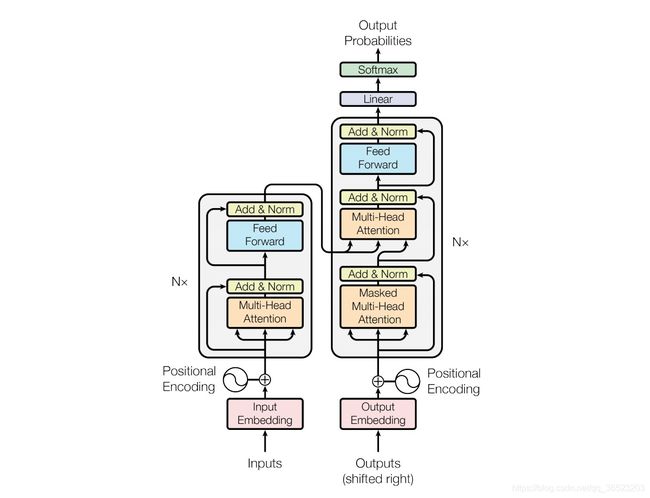
- Encoder编码
上图所示的Nx部分,由6个相同的layer组成,layer指的就是上图左侧的单元。
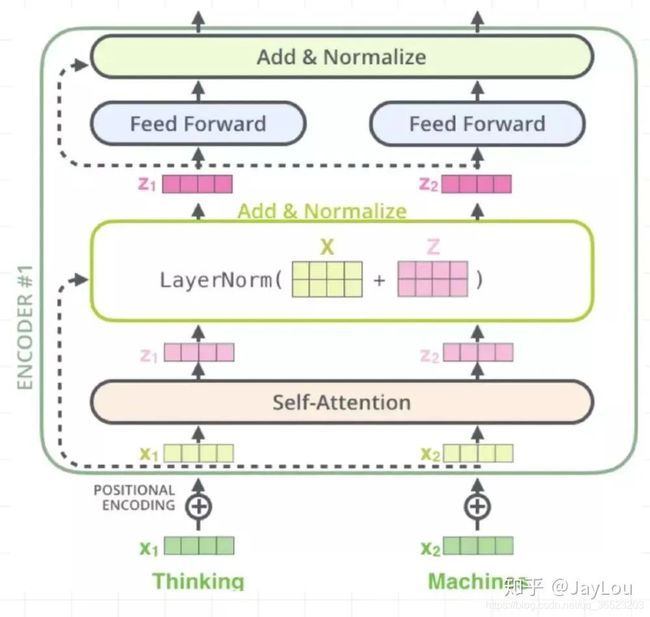
一个layer由两个sub_layer组成,分别是multi-head self-attention mechanism,用来self-attention 和fully connected feed-forward network,简单的全连接网络,对每个position的向量分别进行相同的操作,包括连个线性变换和一个ReLU激活输出(输入输出维度都是512,中间层是2048)。其中每个sub-layer都加了residual connection(残差网络连接)和normalisation(归一化),因此可以将sub-layer的输出表示为:
s u b l a y e r o u t p u t = L a y e r N o r m ( x + ( S u b L a y e r ( x ) ) ) sub_layer_output=LayerNorm(x+(SubLayer(x))) sublayeroutput=LayerNorm(x+(SubLayer(x)))
下面介绍这两个sub-layer:
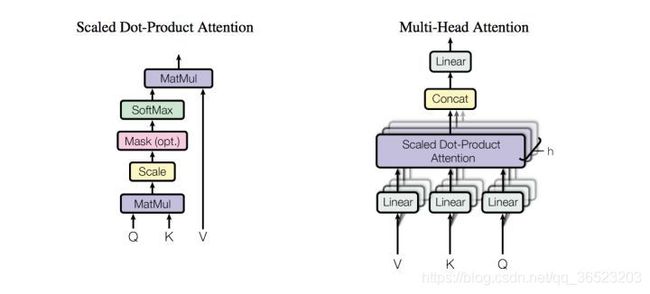
1,multi-head self-attention mechanism
attention可由以下形式表示: a t t e n t i o n − o u t p u t = A t t e n t i o n ( Q , K , V ) attention _-output=Attention(Q,K,V) attention−output=Attention(Q,K,V),multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来: M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , . . h e a d h ) W o MultiHead(Q,K,V)=Concat(head1,head2,..headh)W^o MultiHead(Q,K,V)=Concat(head1,head2,..headh)Wo,其中 h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV) ,
其中attention函数为 A t t e n t i o n ( ) = s o f t m a x ( Q K T d k ) ∗ V Attention()=softmax(\frac{QK^T}{\sqrt{d_k}})*V Attention()=softmax(dkQKT)∗V
2,Position-wise feed-forward networks
这层主要是提供非线性变换。Attention输出的维度是[batchsize* seq_len, num_heads*head_size],第二个sub-layer是个全连接层,之所以是position-wise是因为过线性层时每个位置i的变换参数是一样的。 - Transformer Decoder解码(N=6层,每层3个sub-layers)
3个sub-layers分别是:
**1,Masked multi-head self-attention mechanism,**用来进行self-attention,与Encoder不同:由于是序列生成过程,所以在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask。
图中显示与右边编码器中的self-attention编码器的区别:
2,Position-wise Feed-forward Networks,同Encoder里的sub-layer2。
3,Encoder-Decoder attention计算。
它与self-attention有所不同,都是采用multi-head计算,不过Encoder-Decoder attention采用传统的attention机制,其中的Query是self-attention mechanism已经计算出的上一时间i处的编码值,Key和Value都是Encoder的输出,这与self-attention mechanism不同。体现在代码中:
## Multihead Attention ( self-attention)
self.dec = multihead_attention(queries=self.dec,
keys=self.dec,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=True,
scope="self_attention")
## Multihead Attention ( Encoder-Decoder attention)
self.dec = multihead_attention(queries=self.dec,
keys=self.enc,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=False,
scope="vanilla_attention")
Transformer应用于视觉任务
提起Transformer,会想到NLP中的大杀器BERT和GPT-3。下面大家可以了解到将Transformer应用到计算机视觉任务中的例子。
图像分类
论文连接:https://openreview.net/pdf?id=YicbFdNTTy
图像处理
论文链接:https://arxiv.org/abs/2012.00364
论文由北京大学、华为诺亚方舟实验室、悉尼大学、鹏程实验室提出。提出了一个图像处理Transformer(IPT)