机器学习知识点总结(待更新)
机器学习按照模型类型分为监督学习模型、无监督学习模型和概率模型三大类:
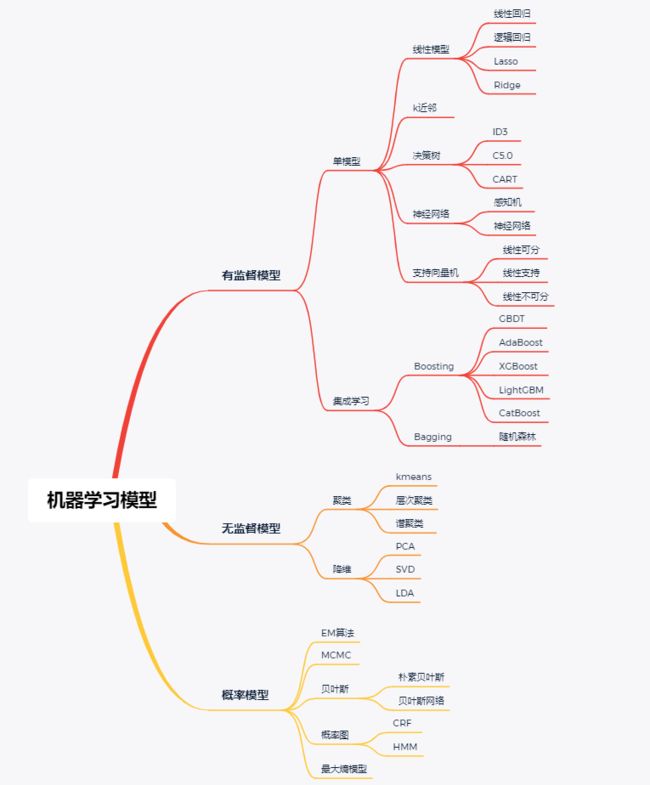
以下是作者自己整理的机器学习笔记思维导图,分享供大家学习,导图和笔记后续会继续更新。
一、什么是机器学习?
机器学习=寻找一种函数
如何寻找这个函数?
①定一个函数集合
②判断函数的好坏
③选择最好的函数
机器学习三板斧
①设计模型model
②判断模型的好坏
③选择最好的函数,优化模型
3.1修改模型,增加数据维度
3.2增加正则因子,使函数更加平滑,让参数w取值更小。(x变化较小时,整个函数结果不会变化太大,结果更准)
学习路线
监督学习:有数据标注情况下学习(回归、分类)
半监督学习:训练数据中带标记的数据不够多
迁移学习:在已学习基础上,做看似和以前学习不相关的事情,但实际效果很好(在猫狗识别基础识别大象老虎等)
非监督学习:没有具体标注数据的情况下学习(机器阅读、机器绘画)
结构化学习:超越简单的回归和分类,产生结构化的结果(如图片、语言、声音)
二、机器学习算法的类型
1. 有监督学习
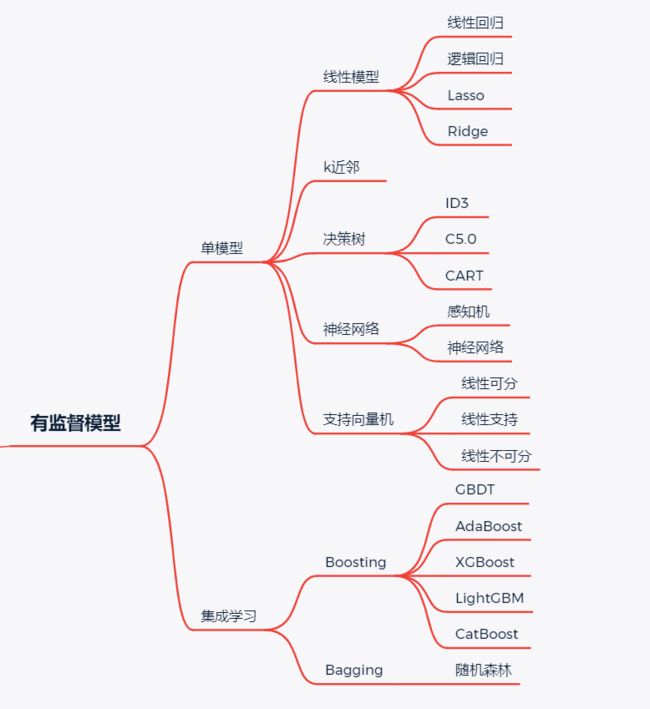
有监督学习通常是利用带有专家标注的标签的训练数据,学习一个从输入变量X到输入变量Y的函数映射。 Y = f (X)
训练数据通常是(n×x,y)的形式,其中n代表训练样本的大小,x和y分别是变量X和Y的样本值。
利用有监督学习解决的问题大致上可以被分为两类:
分类问题:预测某一样本所属的类别(离散的)。比如给定一个人(从数据的角度来说,是给出一个人的数据结构,包括:身高,年龄,体重等信息),然后判断是性别,或者是否健康。
回归问题:预测某一样本的所对应的实数输出(连续的)。比如预测某一地区人的平均身高。
下面所介绍的前五个算法(线性回归,逻辑回归,分类回归树,朴素贝叶斯,K最近邻算法)均是有监督学习的例子。
除此之外,集成学习也是一种有监督学习。它是将多个不同的相对较弱的机器学习模型的预测组合起来,用来预测新的样本。本文中所介绍的第九个和第十个算法(随机森林装袋法,和XGBoost算法)便是集成技术的例子。
2. 无监督学习
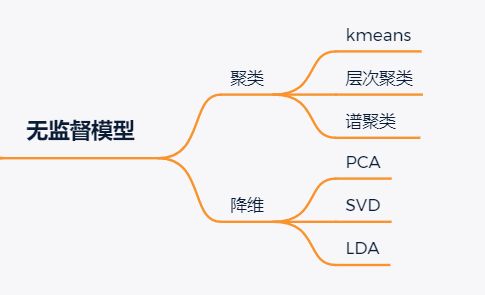
无监督学习问题处理的是,只有输入变量X没有相应输出变量的训练数据。它利用没有专家标注训练数据,对数据的结构建模。
可以利用无监督学习解决的问题,大致分为两类:
关联分析:发现不同事物之间同时出现的概率。在购物篮分析中被广泛地应用。如果发现买面包的客户有百分之八十的概率买鸡蛋,那么商家就会把鸡蛋和面包放在相邻的货架上。
聚类问题:将相似的样本划分为一个簇(cluster)。与分类问题不同,聚类问题预先并不知道类别,自然训练数据也没有类别的标签。
维度约减:顾名思义,维度约减是指减少数据的维度同时保证不丢失有意义的信息。利用特征提取方法和特征选择方法,可以达到维度约减的效果。特征选择是指选择原始变量的子集。特征提取是将数据从高纬度转换到低纬度。广为熟知的主成分分析算法就是特征提取的方法。
下面介绍的第六-第八(Apriori算法,K-means算法,PCA主成分分析)都属于无监督学习。
3. 强化学习
通过学习可以获得最大回报的行为,强化学习可以让agent(个体)根据自己当前的状态,来决定下一步采取的动作。
强化学习算法通过反复试验来学习最优的动作。这类算法在机器人学中被广泛应用。在与障碍物碰撞后,机器人通过传感收到负面的反馈从而学会去避免冲突。在视频游戏中,我们可以通过反复试验采用一定的动作,获得更高的分数。Agent能利用回报去理解玩家最优的状态和当前他应该采取的动作。
三、常见机器学习概念介绍:
1.常见机器学习算法概念简介:
1、监督学习(SupervisedLearning):有类别标签的学习,基于训练样本的输入、输出训练得到最优模型,再使用该模型预测新输入的输出;
代表算法:决策树、朴素贝叶斯、逻辑回归、KNN、SVM、神经网络、随机森林、AdaBoost、遗传算法;
2、半监督学习(Semi-supervisedLearning):同时使用大量的未标记数据和标记数据,进行模式识别工作;
代表算法:self-training(自训练算法)、generative models生成模型、SVMs半监督支持向量机、graph-basedmethods图论方法、 multiviewlearing多视角算法等;
3、无监督学习(UnsupervisedLearning):无类别标签的学习,只给定样本的输入,自动从中寻找潜在的类别规则;
代表算法:主成分分析方法PCA等,等距映射方法、局部线性嵌入方法、拉普拉斯特征映射方法、黑塞局部线性嵌入方法、局部切空间排列方法等;
4、HOG特征:全称Histogram of Oriented Gradient(方向梯度直方图),由图像的局部区域梯度方向直方图构成特征;
5、LBP特征:全称Local Binary Pattern(局部二值模式),通过比较中心与邻域像素灰度值构成图像局部纹理特征;
6、Haar特征:描述图像的灰度变化,由各模块的像素差值构成特征;
7、核函数(Kernels):从低维空间到高维空间的映射,把低维空间中线性不可分的两类点变成线性可分的;
8、SVM:全称Support Vector Machine(支持向量机),在特征空间上找到最佳的超平面使训练集正负样本的间隔最大;是解决二分类问题的有监督学习算法,引入核方法后也可用来解决非线性问题;
9、Adaboost:全称Adaptive Boosting(自适应增强),对同一个训练集训练不同的弱分类器,把这些弱分类器集合起来,构成一个更强的强分类器;
10、决策树算法(Decision Tree):处理训练数据,构建决策树模型,再对新数据进行分类;
11、随机森林算法(Random Forest):使用基本单元(决策树),通过集成学习将多棵树集成;
12、朴素贝叶斯(Naive Bayes):根据事件的先验知识描述事件的概率,对联合概率建模来获得目标概率值;
13、神经网络(Neural Networks):模仿动物神经网络行为特征,将许多个单一“神经元”联结在一起,通过调整内部大量节点之间相互连接的关系,进行分布式并行信息处理。
2.其余理论知识
偏差
偏差度量了模型的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力。偏差则表现为在特定分布上的适应能力,偏差越大越偏离真实值。
方差
方差度量了同样大小的训练集的变动所导致的学习性能的变化, 即刻画了数据扰动所造成的影响。方差越大,说明数据分布越分散。
噪声
噪声表达了在当前任务上任何模型所能达到的期望泛化误差的下界, 即刻画了学习问题本身的难度 。
泛化误差、偏差、方差和模型复杂度的关系(图片来源百面机器学习)
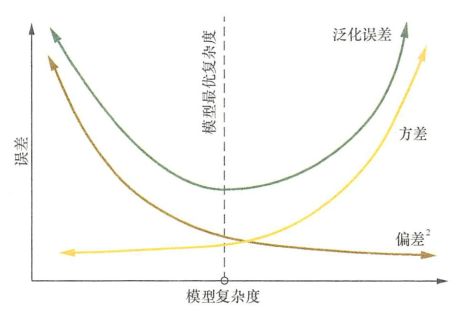
Q2什么是过拟合和欠拟合,为什么会出现这个现象?
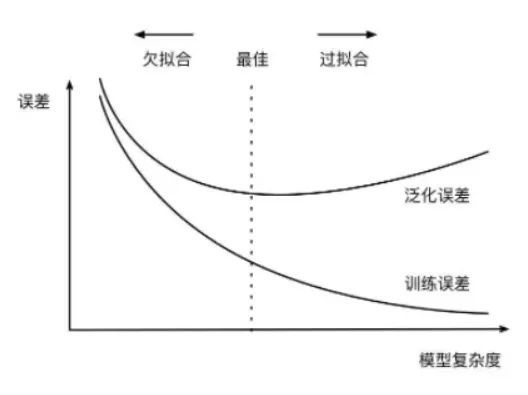
过拟合指的是在训练数据集上表现良好,而在未知数据上表现差。
欠拟合指的是模型没有很好地学习到数据特征,不能够很好地拟合数据,在训练数据和未知数据上表现都很差。如图所示:
过拟合的原因在于:
-
参数太多,模型复杂度过高;
-
建模样本选取有误,导致选取的样本数据不足以代表预定的分类规则;
-
样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
-
假设的模型无法合理存在,或者说是假设成立的条件实际并不成立。
欠拟合的原因在于:
-
特征量过少;
-
模型复杂度过低。
Q3怎么解决欠拟合?
-
增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
-
添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;
-
减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
-
使用非线性模型,比如核SVM 、决策树、深度学习等模型;
-
调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力;
-
容量低的模型可能很难拟合训练集。
Q4怎么解决过拟合?(重点)
-
获取和使用更多的数据(数据集增强)——解决过拟合的根本性方法
-
特征降维:人工选择保留特征的方法对特征进行降维
-
加入正则化,控制模型的复杂度
-
Dropout
-
Early stopping
-
交叉验证 增加噪声
Q5为什么参数越小代表模型越简单?
因为参数的稀疏,在一定程度上实现了特征的选择。
越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。因此参数越少代表模型越简单。
未完待续。。。。。
四、十大机器学习算法介绍
有监督学习
1. 线性回归算法
在机器学习当中,我们有一个变量X的集合用来决定输出变量Y。在输入变量X和输出变量Y之间存在着某种关系。机器学习的目的就是去量化这种关系。
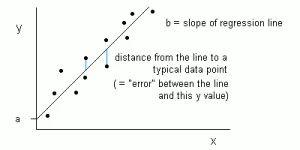
在线性回归里,输入变量X和输出变量Y之间的关系,用等式Y = a + bX 来表示。因此,线性回归的目标便是找出系数a和b的值。在这里,a是截距,b是斜率。
上图绘制了数据中X和Y的值。我们的目标是去拟合一条最接近所有点的直线。这意味着,直线上每一个X对应点的Y值与实际数据中点X对应的Y值,误差最小。
2. 逻辑回归算法
使用一个转换函数后,线性回归预测的是连续的值(比如降雨量),而逻辑回归预测的是离散的值(比如一个学生是否通过考试,是:0,否:1)。
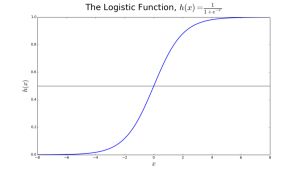
逻辑回归最适用于二分类(数据只分为两类,Y = 0或1,一般用1作为默认的类。比如:预测一个事件是否发生,事件发生分类为1;预测一个人是否生病,生病分类为1)。我们称呼其为逻辑回归(logistic regression)是因为我们的转换函数采用了logistic function (h(x)=1/(1+e的-x次方)) 。
在逻辑回归中,我们首先得到的输出是连续的默认类的概率p(0小于等于p小于等于1)。转换函数 (h(x)=1/(1+e的-x次方))的值域便是(0,1)。我们对该函数设置一个域值t。若概率p>t,则预测结果为1。
图 2 使用逻辑回归来判断肿瘤是恶性还是良性。如果概率p大于0.5,则是恶性
在图2中,判断肿瘤是恶性还是良性。默认类y=1(肿瘤是恶性)。当变量X是测量肿瘤的信息,如肿瘤的尺寸。如图所示,logistic函数由变量X得到输出p。域值t在这里设置为0.5。如果p大于t,那么肿瘤则是恶性。
我们考虑逻辑回归的一种变形:
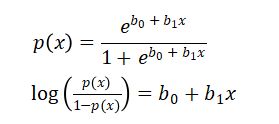
因此,逻辑回归的目标便是训练数据找到适当的参数的值,使得预测的输出和实际的输出最小。我们使用最大似然估计来对参数进行估计。
3. 分类回归树(决策树)
分类回归树是诸多决策树模型的一种实现,类似还有ID3、C4.5、CART等算法。
非终端节点有根节点(Root Node)和内部节点(Internal Node)。终端节点是叶子节点(Leaf Node)。每一个非终端节点代表一个输出变量X和一个分岔点,叶叶子节点代表输出变量Y,见图3。沿着树的分裂(在分岔点做一次决策)到达叶子节点,输出便是当前叶子节点所代表的值。
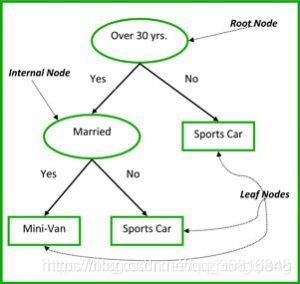
图3中的决策树,根据一个人的年龄和婚姻状况进行分类:1.购买跑车;2.购买小型货车。如果这个人30岁还没有结婚,我们沿着决策树的过程则是:‘超过30年?–是--已婚?–否,那么我们的输出便是跑车。
4. 朴素贝叶斯
在给定一个事件发生的前提下,计算另外一个事件发生的概率——我们将会使用贝叶斯定理。假设先验知识为d,为了计算我们的假设h为真的概率,我们将要使用如下贝叶斯定理:

P(h|d)=后验概率。这是在给定数据d的前提下,假设h为真的概率。
P(d|h)=可能性。这是在给定假设h为真的前提下,数据d的概率。
P(h)=类先验概率。这是假设h为真时的概率(与数据无关)
P(d)=预测器先验概率。这是数据的概率(与假设无关)
之所以称之为朴素是因为该算法假定所有的变量都是相互独立的(在现实生活大多数情况下都可以做这样的假设)。
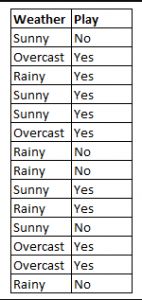
如图,当天气是晴天的时候(第一列第一行),选手的状态是如何的呢?
在给定变量天气是晴天(sunny)的时候,为了判断选手的状态是‘yes’还是‘no’,计算概率,然后选择概率更高的作为输出。
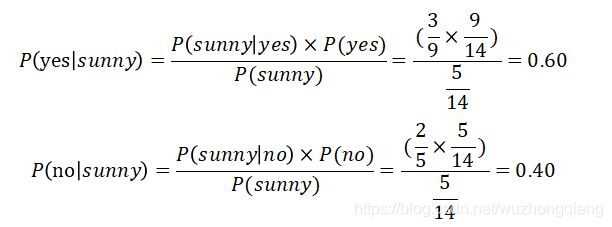
因此,当天气是晴天的时候,选手的状态是‘yes’
5. KNN(K近邻算法)
K最近邻算法是利用整个数据集作为训练集,而不是将数据集分成训练集和测试集。
当要预测一个新的输入实体的输出时,k最近邻算法寻遍整个数据集去发现k个和新的实体距离最近的实体,或者说,k个与新实体最相似的实体,然后得到这些输出的均值(对于回归问题)或者最多的类(对于分类问题)。而k的值一般由用户决定。
不同实体之间的相似度,不同的问题有不同的计算方法,包括但不限于:Euclidean distance 和Hamming distance。
无监督学习算法
6. 关联规则算法
关联规则算法在数据库的候选项集中用来挖掘出现频繁项集,并且发现他们之间的关联规则。关联规则算法在购物篮分析中得到了很好的应用。所谓的购物篮分析,是指找到数据库中出现频率最高的事物的组合。通常,如果存在关联规则:“购买了商品x的人,也会购买商品y”,我们将其记作:x–y。
比如,如果一个人购买了牛奶和糖,那么他很有可能会购买咖啡粉。在充分考虑了支持度(support)和置信度(confidence)后,得到关联规则。
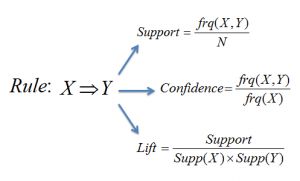
支持度(support)检验项目集是否频繁。支持度的检验是符合Apriori原理的,即当一个项目集是频繁的,那么它所有的子集一定也是频繁的。
我们通过置信度(confidence)的高低,从频繁项集中找出强关联规则。
根据提升度(lift),从强关联规则中筛选出有效的强关联规则。
7. K-means算法
k-means算法是一个迭代算法的聚类算法,它将相似的数据化到一个簇(cluster)中。该算法计算出k个簇的中心点,并将数据点分配给距离中心点最近的簇。

k-means初始化:
a) 选择一个k值。如图6,k=3。
b) 随机分配每一个数据点到三个簇中的任意一个。
c) 计算每一个簇的中心点。如图6,红色,蓝色,绿色分别代表三个簇的中心点。
将每一个观察结果与当前簇比较:
a) 重新分配每一个点到距中心点最近的簇中。如图6,上方5个点被分配给蓝色中心点的簇。
重新计算中心点:
a) 为新分配好的簇计算中心点。如图六,中心点改变。
迭代,不再改变则停止:
a) 重复步骤2-3,直到所有点所属簇不再改变。
8. PCA主成分分析
主成分分析是通过减少变量的维度,去除数据中冗余的部分或实现可视化。基本的思路将数据中最大方差的部分反映在一个新的坐标系中,这个新的坐标系则被称为“主要成分”。其中每一个成分,都是原来成分的线性组合,并且每一成分之间相互正交。正交性保证了成分之间是相互独立的。
第一主成分反映了数据最大方差的方向。第二主成分反映了数据中剩余的变量的信息,并且这些变量是与第一主成分无关的。同样地,其他主成分反映了与之前成分无关的变量的信息。

集成学习技术
集成学习是一种将不同学习模型(比如分类器)的结果组合起来,通过投票或平均来进一步提高准确率。一般,对于分类问题用投票;对于回归问题用平均。这样的做法源于“众人拾材火焰高”的想法。
集成算法主要有三类:Bagging,Boosting 和Stacking。本文将不谈及stacking。
9. 使用随机森林Bagging
随机森林算法(多个模型)是袋装决策树(单个模型)的提升版。
Bagging的第一步是针对数据集,利用自助抽样法(Bootstrap Sampling method)建造多个模型。
所谓的自助抽样,是指得到一个由原始数据集中随机的子集组成的新的训练集。每一个这样的训练集都和原始训练集的大小相同,但其中有一些重复的数据,因此并不等于原始训练集。并且,我们将原始的数据集用作测试集。因此,如果原始数据集的大小为N,那么新的训练集的大小也为N(其中不重复的数据数量为2N/3),测试集的大小为N。
Bagging的第二步是在抽样的不同的训练集上,利用相同的算法建造多个模型。
在这里,我们以随机森林为例。决策树是靠每一个节点在最重要的特征处分离来减小误差的,但与之不同,随机森林中,我们选择了随机塞选的特征来构造分裂点。这样可以减小所得预测之间的相关性。
每一个分裂点搜索的特征的数量,是随机森林算法的参数。
因此,用随机森林算法实现的Bagging,每一个树都是用随机样本构造的,每一个分裂点都是用随机的预测器构造的。
10. 用Adaboost实现Boosting
a) 因为Bagging中的每一个模型是独立构造的,我们认为它是并行集成的。与之不同,Boosting中的每一个模型,都是基于对前一个模型的过失进行修正来构造的,因此Boosting是线性的。
b) Bagging中采用的是简单的投票,每一个分类器相当于一个投票(节点分裂,相当于进行一次投票),最后的输出是与大多数的投票有关;而在Boosting中,我们对每一个投票赋予权重,最后的输出也与大多数的投票有关——但是它却是线性的,因为赋予了更大的权重给被前一个模型错误分类的实体(拥有更大的权重,则其误差的影响被放大,有助于我们得到使得更小误差的模型)。
AdaBoost指的是自适应增强(Adaptive Boosting)

在上图,第一、二、三步中弱学习模型被称作决策树桩(一个一级的决策树只依据一个输入特征进行预测;一个决策树的根节点直接连接到它的叶子节点)。构造弱学习模型的过程持续到,a)达到用户定义的数量,或者 b)继续训练已经无法提升。第四步,将三个决策树桩组合起来。
第一步:从一个决策树桩开始,根据一个输入变量作出决定
从图中可以看见,其中有两个圆圈分类错误,因此我们可以给他们赋予更大的 权重,运用到下一个决策树桩中。
第二步:依据不同的输入变量,构造下一个决策树桩
可以发现第二个决策将会尝试将更大权重的数据预测正确。和如图的情况中, 我们需要对另外三个圆圈赋予更大的权重。
第三步:依据不同的输入变量,训练不同的决策树桩
之前步骤一样,只是这次被预测错误的是三角形的数据,因此我们需要对其赋 予更大的权重。
第四步:将决策树桩组合起来
我们将三个模型组合起来,显而易见,集成的模型比单个模型准确率更高。
参考链接:十大机器学习算法的一个小总结_Miracle8070-CSDN博客_机器学习算法总结
一、机器学习处理
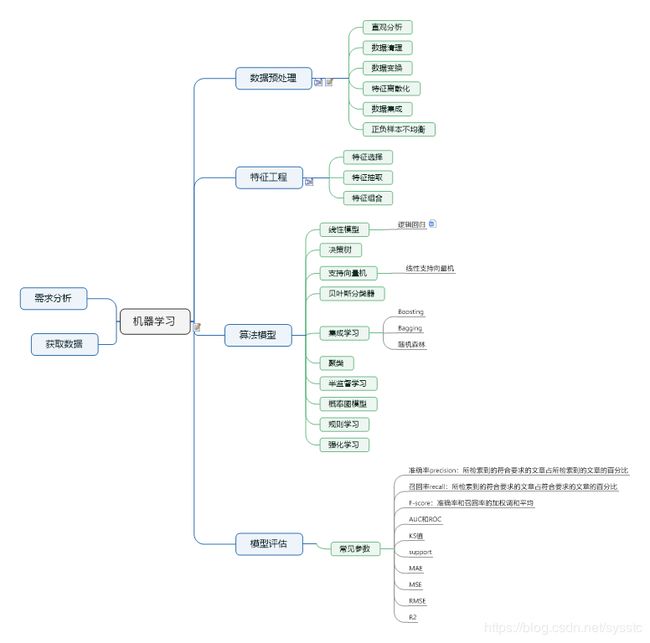
需求分析与数据获取
- 在需求分析与数据获取中,我们往往要考虑以下几个方面:
- 确定模型目标
- 根据目标得到所需的相关因素?
- 特征的定义方式(比如,一周用户心情,是要取平均值还是方差呢)?
- 这些特征该是连续的还是离散的呢?
- 离散特征应该如何划分比较合理?
对于数据获取中,分析合适的特征划分方式是非常重要的,更多情况下,趋向划分为离散特征,因为在机器学习中,用于处理离散特征的效果远比处理连续特征的效果更好。
数据预处理
数据预处理大致分为6个部分:
- 直观分析
直观分析即通过作图的方式,分析特征的分布情况:最大值,最小值,局部峰值,置信区间,过零点,拐点,异常点等等。 - 数据清理
数据清理即处理一些不符常规的数据。常见的数据清理方法有:去重、错误纠正、格式标准化、异常值处理。其中,异常值处理又分为:缺失值填充,噪声数据处理,删除利群点等。 - 数据变换
数据变换即将数据变换为更有利于模型处理的数据。常见的数据变换有:特征二值化,特征归一化,连续特征变化,特征哑编码(如常见的one-hot编码)。 - 特征离散化
特征离散化即将连续特征离散到一个个区间,特征离散化能降低过拟合的风险,使模型更加稳定。常见的特征离散化方式有:无监督方法,有监督方法,基于独立性的离散化,基于精确度的离散化。其中,无监督方法又分为分箱法,直观划分法,基于聚类分析的离散化等,无监督方法易于实现,但同时它也可能会把属于同一类别的不同实例分到不同箱里。有监督方法分为1R离散化,基于卡方的离散化,基于熵增益的离散化,基于Gini增益的离散化等。 - 数据集成
- 正负样本均衡
常见的用于正负样本均衡的方法有欠采样,过抽样,算法调整,其中算法调整又分为权重调整和集成学习。
未处理特征通常存在几种常见问题:
| 问题 | 处理方法 |
|---|---|
| 信息冗余(例如,学习成绩特征,如果目标是是否及格,那么则只需要将其进行二值化就好,不需要知道具体的分数) | 二值化 |
| 定性特征不能直接使用 | 定性特征哑编码 |
| 存在缺失值 | 缺失值填充 |
| 信息利用率低 | 数据变换 |
| 不属于同一量纲(特征规格不一样) | 无纲量化 |
特征工程
特征过程的目的是为了获得更好的训练数据。数据与特征决定了机器学习的上限,而模型和算法则是逼近这个上限。特征工程又分为特征抽取、特征选择和特征组合。
- 特征抽取主要是通过属性之间的关系,如组合不同的属性得到新的属性,这样就改变了原来的特征空间。
- 特征选择是从特征集合中挑选出一组最具统计意义的特征子集,从而达到降低维度的效果
- 特征组合通常是“基本特征+组合特征”兼顾了全局和个性化,对于线性学习器,特征组合可以很好地扩展大量数据,对于大规模数据集使用特征组合是学习高度复杂模型的一种有效策略。
算法模型
常用的算法模型有:逻辑回归、决策树、支持向量机、贝叶斯分类器、聚类算法、半监督学习、集成学习(Boosting、Bagging、随机森林)、概率图模型、规则学习、强化学习等。
模型评估
进行模型评估的常见参数有:准确率、召回率、F-score、AUC、ROC、KS、support、MAE、MSE、RMSE、R2等。
机器学习知识点笔记参考:
机器学习主要知识点整理_二三TP的博客-CSDN博客_机器学习知识点总结
机器学习——笔记整理(原理、python代码)——反反复复,出精活!_珞沫的博客-CSDN博客
1.机器学习面试知识点总结(更新中...)_Meggie的博客-CSDN博客
2.机器学习面试知识点整理_朱滕威的博客-CSDN博客
-
常用机器学习算法汇总比较(上)
-
常用机器学习算法汇总比较(中)
-
常用机器学习算法汇总比较(完)
机器学习入门系列(1)--机器学习概览