VGGNet网络详解与模型搭建
文章目录
-
- 1 模型介绍
- 2 模型结构
- 3 模型特性
- 4 Pytorch模型搭建代码
1 模型介绍
VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以7.32%的错误率赢得了2014年ILSVRC分类任务的亚军(冠军由GoogLeNet以6.65%的错误率夺得)和25.32%的错误率夺得定位任务(Localization)的第一名(GoogLeNet错误率为26.44%),网络名称VGGNet取自该小组名缩写。VGG网络原论文《Very Deep Convolutional Networks For Large-Scale Image Recognition》发表于ICLR-2015,VGGNet所提出的 3 × 3 3\times3 3×3卷积核的思想为后来许多模型所沿用。
2 模型结构
在原论文中,作者尝试了不同深度的配置(11层,13层,16层,19层),是否使用LRN(Local Response Normalization)以及卷积核1x1与卷积核3x3的差异,VGGNet尝试使用了6种不同的模型结构,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数(VGG11-LRN表示在第一层中采用了LRN的VGG11,VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为 1 × 1 1\times1 1×1,相应的VGG16-3表示卷积核尺寸为 3 × 3 3\times3 3×3)。下表是从原论文中截取的几种VGG模型的配置表,VGGNet网络模型结构非常工整,其卷积层全部都采用了大小为3x3,步距为1,padding为1的卷积操作(即same卷积,经过卷积后不会改变特征矩阵的高和宽);最大池化下采样层全部都是池化核大小为2,步距为2的池化操作,每次通过最大池化下采样后特征矩阵的高和宽都会缩减为原来的一半。

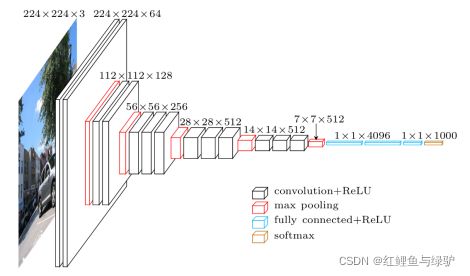
我们通常使用的VGG模型是表格中的VGG16(D)配置,根据表格中的配置信息以及上文所讲的卷积层和池化层的详细参数,可以搭建如下图所示的feature map大小的变化图。在VGG模型中,卷积操作不会改变feature map的大小,池化操作会使feature map大小减小为原来的一半。
3 模型特性
(1)通过堆叠多个3x3的卷积核来替代大尺度卷积核
论文中提到,可以通过堆叠两层 3 × 3 3\times 3 3×3的卷积核替代一层 5 × 5 5\times 5 5×5的卷积核,堆叠三层 3 × 3 3\times3 3×3的卷积核替代一层 7 × 7 7\times7 7×7的卷积核。这样的连接方式使得网络参数量更小(见下例),而且多层的激活函数令网络对特征的学习能力更强。
-
如果使用一层卷积核大小为7的卷积所需参数(第一个C代表输入特征矩阵的channel,第二个C代表卷积核的个数也就是输出特征矩阵的深度): 7 × 7 × C × C = 49 C 2 7\times 7\times C\times C=49C^2 7×7×C×C=49C2
-
如果使用三层卷积核大小为3的卷积所需参数: 3 × 3 × C × C + 3 × 3 × C × C + 3 × 3 × C × C = 27 C 2 3\times 3\times C\times C + 3\times 3\times C\times C + 3\times 3\times C\times C=27C^2 3×3×C×C+3×3×C×C+3×3×C×C=27C2
经过对比明显使用3层大小为3x3的卷积核比使用一层7x7的卷积核参数更少
(2)整个网络都使用了同样大小的卷积核尺寸 3 × 3 3\times3 3×3和最大池化尺寸 2 × 2 2\times2 2×2,模型十分工整。
(3)VGGNet在训练时有一个小技巧,先训练浅层的的简单网络VGG11,再复用VGG11的权重来初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。
4 Pytorch模型搭建代码
注:由于LRN层对训练结果影响不大,故代码中去除了LRN层
import torch
import torch.nn as nn
class VGG(nn.Module):
def __init__(self, features, num_classes=1000):
super().__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
def forward(self, inputs):
x = self.features(inputs) # [N, 3, 224, 224] --> [N, 512, 7, 7]
x = torch.flatten(x, start_dim=1) # [N, 512, 7, 7] --> [N, 512 * 7 * 7]
outputs = self.classifier(x) # [N, 512 * 7 * 7] --> [N, num_classes]
return outputs
# VGGNet的配置文件,数字表示卷积层输出的feature map大小,'M'表示最大池化下采样
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
def make_features(cfg: list):
"""根据cfgs配置制作vgg的特征提取层"""
layers = []
in_channels = 3
for v in cfg:
if v == "M":
maxpool2d = nn.MaxPool2d(kernel_size=2, stride=2)
layers.append(maxpool2d)
else:
conv2d = nn.Conv2d(in_channels=in_channels, out_channels=v, kernel_size=3, padding=1)
layers.append(conv2d)
in_channels = v
return nn.Sequential(*layers)
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: {} not in config dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(features=make_features(cfg), **kwargs)
return model