Python Pandas库教程
文章目录
- 前言
- 1 Pandas数据结构
-
- 1.1 Series
-
- 1.1.1 Series数据操作
- 1.1.2 Series数据分析
- 1.2 DataFrame
-
- 1.2.1 生成DataFrame
- 1.2.2 数据访问
- 1.2.3 数据修改
- 1.2.4 缺失值处理
- 1.2.5 Pandas的三板斧
- 1.2.6 处理时间序列
- 1.2.7 数据离散化
- 1.2.8 交叉表
- 2 实例分析
前言
Python有了NumPy的Pandas,用Python处理数据就像使用Exel或SQL一样简单方便。Pandas是基于NumPy的Python 库,它被广泛用于快速分析数据,以及数据清洗和准备等工作。可以把 Pandas 看作是 Python版的Excel或Table。Pandas 有两种数据结构:Series和DataFrame,Pandas经过几个版本的更新,目前已经成为数据清洗、处理和分析的不二选择。
1 Pandas数据结构
Pandas主要采用Series和DataFrame两种数据结构。Series是一种类似一维数据的数据结构,由数据(values)及索引(indexs)组成,而DataFrame是一个表格型的数据结构,它有一组序列,每列的数据可以为不同类型(NumPy数据组中数据要求为相同类型),它既有行索引,也有列索引。
# 导入相关模块
import numpy as np
import pandas as pd
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
c = np.array(['a', 'b', 'c', 'd'])
# 转成 DataFrame 结构
df = pd.DataFrame({'a' : a, 'b' : b, 'c' : c, 'c' : c})
df
1.1 Series
Series是一维带标签的数组,数组里可以放任意的数据(整数,浮点数,字符串, Python Object)。Series的标签索引(它位置索引自然保留)使用起来比 ndarray 方便多了,且定位也更精确,不会产生歧义其基本的创建函数是:
- 其中index是一个列表,用来作为数据的标签。
- data的类型可以是Python字典、ndarray对象、一个标量值,如3等。
1.1.1 Series数据操作
(1) 创建Series
s = pd.Series([1, 3, 6, -1, 2, 8])
s

(2) Series 索引
s.values #显示s1的所有值 out : array([ 1, 3, 6, -1, 2, 8], dtype=int64)
s.index #显示s1的索引(位置索引或标签索引) out : RangeIndex(start=0, stop=6, step=1)
s1 = pd.Series([1, 3, 6, -1, 2, 8], index=['a', 'b', 'c', 'd', 'e', 'f']) #定义标签索引
s1

(3) 数据访问
# 访问Series中数据的两种方法
import pandas as pd
s1 = pd.Series([ 75, 90, 61],index=['张三', '李四', '陈五'])
print(s1[0]) #通过元素储存位置访问
print(s1['张三']) #通过指定索引访问
# 结果均为 75
(4) 数据修改
可以直接通过赋值的方法修改Series中的对应值。
# 修改Series中的值
import pandas as pd
s1 = pd.Series([ 75, 90, 61],index=['张三', '李四', '陈五'])
s1['张三'] = 60 #通过指定索引访问
s1[1] = 60 #通过元素储存位置访问
print(s1)

(5) 算术运算
Pandas会根据索引index索引对相应数据进行计算。如代码所示,可以直接对Series结构进行加减乘除运算符,当出现index不匹配的情况时会输出NaN。
import pandas as pd
sr1 = pd.Series([1, 2, 3, 4],['a','b','c','d'])
sr2 = pd.Series([1, 5, 8, 9],['a','c','e','f'])
sr2 - sr1

1.1.2 Series数据分析
(1) 切片操作
数据切片的概念源于Numpy数组,Series对象使用类似NumPy中ndarray的数据访问方法实现切片操作。
#Series的切片操作
import pandas as pd
s1 = pd.Series([ 75, 90, 61, 59],index=['a', 'b', 'c', 'd'])
s1[1:3]

(2) 数据缺失处理
Pandas工具包提供了相应处理方法可以轻松实现缺失数据的处理,如下表:

# Series填充缺失值
import pandas as pd
import numpy as np
s1 = pd.Series([ 75, 90, np.NaN, 59],index=['a', 'b', 'c', 'd'])
# 查看缺失值
s1.isnull()
# a False
# b False
# c True
# d False
# 删除缺失值
s1.dropna()
# a 75.0
# b 90.0
# d 59.0
# 填充缺失值
s1.fillna(0)
# a 75.0
# b 90.0
# c 0.0
# d 59.0
(3) 统计分析
Pandas数据分析库提供了强大的数据统计功能,因此通过Series可以非常方便进行数据统计分析。下面是一些常用的Series描述性统计方法。

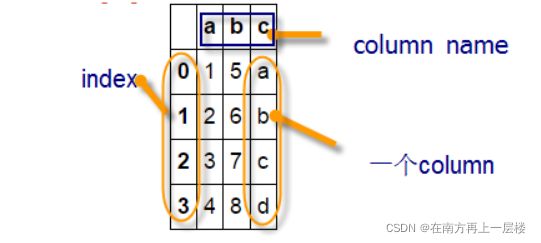
1.2 DataFrame
DataFrame除了索引有位置索引也有标签索引,而且其数据组织方式与MySQL的表极为相似,除了形式相似,很多操作也类似,这就给操作DataFrame带来极大方便。这些是DataFrame特色的一小部分,它还有比数据库表更强大的功能,如强大统计、可视化等等。
DataFrame有几个要素:index、columns、values等,columns就像数据库表的列表,index是索引,values就是值。DataFrame的基本格式是:
- 其中 index是行标签, columns是列标签、
- data可以是由一维 numpy数组,list, Series构成的字典、二维 numpy数组、一个 Series、另外的 DataFrame对象
####自动生成一个3行4列的DataFrame,并定义其索引(如果不指定,缺省为整数索引)####及列名
df = pd.DataFrame(np.arange(12).reshape((3,4)), columns=['a1', 'a2', 'a3', 'a4'], index=['a', 'b', 'c'])
df
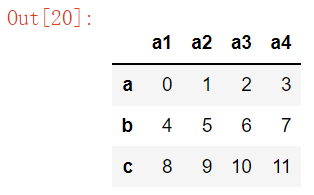
获取一些 DataFrame 结构的属性
df.index #显示索引(有标签索引则显示标签索引,否则显示位置索引)
df.columns ##显示列名
df.values ##显示值
1.2.1 生成DataFrame
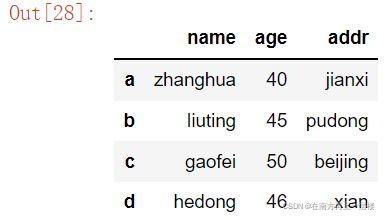
生成DataFrame有很多,比较常用的有导入等长列表、字典、numpy数组、数据文件等。
data={'name' : ['zhanghua', 'liuting', 'gaofei', 'hedong'], 'age':[40, 45, 50, 46], 'addr': ['jianxi', 'pudong', 'beijing', 'xian']}
df = pd.DataFrame(data)
#改变列的次序
df = pd.DataFrame(data, columns=['name', 'age', 'addr'], index=['a', 'b', 'c', 'd'])
df
1.2.2 数据访问
(1) 使用obj[]来获取列或行
df[['name']] #选取某一列
df[['name', 'age']] ##选择多列
df['a' : 'c'] ##选择行,包括首位行
df[1 : 3] ##选择行(利用位置索引),不包括尾行
df[df['age'] > 40] ###使用过滤条件
(2) 使用obj.loc[] 或obj.iloc[]获取行或列数据。
- loc通过行标签获取行数据,iloc通过行号获取行数据
- loc 在index的标签上进行索引,范围包括start和end.
- iloc 在index的位置上进行索引,不包括end.
import pandas as pd
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
index = ['a', 'b', 'c']
columns=['c1', 'c2', 'c3']
df = pd.DataFrame(data = data, index = index, columns = columns)
###########loc的使用############
df.loc[['a','b']] #通过行标签获取行数据
df.loc[['a'],['c1','c3']] #通过行标签、列名称获取行列数据
df.loc[['a','b'],['c1','c3']] #通过行标签、列名称获取行列数据
#########iloc的使用###############
df.iloc[1] #通过行号获取行数据
df.iloc[0:2] #通过行号获取行数据,不包括索引2的值
df.iloc[1:,1] ##通过行号、列行获取行、列数据
df.iloc[1:,[1,2]] ##通过行号、列行获取行、列数据
df.iloc[1:,1:3] ##通过行号、列行获取行、列数据
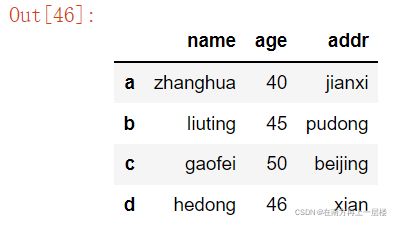
1.2.3 数据修改
我们可以像操作数据库表一样操作DataFrame,删除数据、插入数据、修改字段名、索引名、修改数据等,以下通过一些实例来说明。
data={'name' : ['zhanghua', 'liuting', 'gaofei', 'hedong'], 'age':[40, 45, 50, 46], 'addr': ['jianxi', 'pudong', 'beijing', 'xian']}
df = pd.DataFrame(data, index = ['a', 'b', 'c', 'd'])
df
data={'name' : ['zhanghua', 'liuting', 'gaofei', 'hedong'], 'age':[40, 45, 50, 46], 'addr': ['jianxi', 'pudong', 'beijing', 'xian']}
df = pd.DataFrame(data, index = ['a', 'b', 'c', 'd'])
df.drop('d', axis = 0)###删除行,如果欲删除列,使axis=1即可
df ###从副本中删除,原数据没有被删除
df.drop('addr', axis = 1) ###删除第addr列
# ###添加一行,注意需要ignore_index=True,否则会报错
df.append({'name' : 'wangkuan', 'age' : 38, 'addr' : 'henan'}, ignore_index = True)
df ###原数据未变
# ###添加一行,并创建一个新DataFrame
df = df.append({'name' : 'wangkuan', 'age' : 38, 'addr' : 'henan'}, ignore_index = True)
df.index=['a','b','c','d','e'] ###修改d4的索引
df
df.loc['e', 'age'] = 39 ###修改索引为e列名为age的值
df
1.2.4 缺失值处理
与Series数据结构一样Pandas提供了3种方法用于处理数据集中的缺失值。

(1) dropna
dropna默认丢弃任何含有缺失值的行,因此如果需要丢弃任何含有缺失的列,只需传入axis=1即可。
data = {'one' : [1, 2, np.nan, 3], 'two' : [4, 5, 6, 7], 'three' : [8, 9, 10, 11]}
df = pd.DataFrame(data, index = ['a', 'b', 'c', 'e'])
df.dropna(axis = 1)

(2) fillna
data = {'one' : [1, 2, np.nan, 3], 'two' : [4, 5, 6, 7], 'three' : [8, 9, 10, 11]}
df = pd.DataFrame(data, index = ['a', 'b', 'c', 'd'])
# 直接替换缺失值
df.fillna(0)
# 使用字典方式且使用缺失值那列的平均数替换
trans = {'one' : df['one'].mean()}
df.fillna(trans, inplace = True)
df

1.2.5 Pandas的三板斧
我们知道数据库中有很多函数可用作用于表中元素,DataFrame也可将函数(内置或自定义)应用到各列或行上,而且非常方便和简洁,具体可用通过DataFrame的apply、applymap和map来实现,其中apply、map对数据集中的每列或每行的逐元操作,applymap对dataframe的每个元素进行操作,这些函数是数据处理的强大工具。
df = DataFrame(np.arange(12).reshape(3, 4), columns = ['a1', 'a2', 'a3', 'a4'], index = ['a', 'b', 'c'])
df
df.apply(lambda x : x.max() - x.min(), axis = 0) ###列级处理,每列的最大值减去最小值
df.apply(lambda x : x * 2) ###每个元素乘2
df.iloc[1].map(lambda x : x * 2) ###d第二行的每个元素乘2

1.2.6 处理时间序列
pandas最基本的时间序列类型就是以时间戳(时间点)(通常以python字符串或datetime对象表示)为索引的Series
dates = ['2022-02-05', '2022-02-06', '2022-02-07', '2022-02-08', '2022-02-09']
ts = pd.Series(np.random.randn(5), index = pd.to_datetime(dates))
ts

索引为日期的DataFrame数据的索引、选取以及子集构造
ts.index
#传入可以被解析成日期的字符串
ts['2022-02-05']
#传入年或年月
ts['2022-02']
#时间范围进行切片
ts['2022-02-07': '2022-02-09']

1.2.7 数据离散化
如何离散化连续性数据?在一般开发语言中,可以通过控制语句来实现,但如果分类较多时,这种方法不但繁琐,效率也比较低。在Pandas中现成方法,如cut或qcut等。
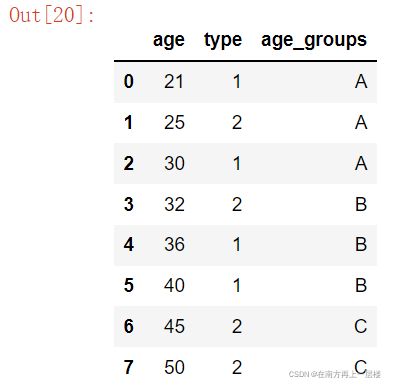
df = DataFrame({'age' : [21, 25, 30, 32, 36, 40, 45, 50], 'type' : ['1', '2', '1', '2', '1', '1', '2', '2']}, columns = ['age', 'type'])
df
###现在需要对age字段进行离散化, 划分为(20,30],(30,40],(40,50].
level = [20, 30, 40, 50] ###划分为(20,30],(30,40],(40,50]
groups = ['A', 'B', 'C']
df['age_groups'] = pd.cut(df['age'], level, labels = groups) ###增加新的列age_groups
df1 = df[df.columns]
df1
1.2.8 交叉表
我们平常看到的数据格式大多像数据库中的表,如购买图书的基本信息:
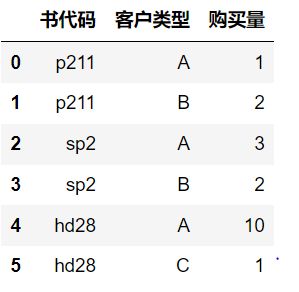
这样的数据比较规范,比较适合于一般的统计分析。但如果我们想查看客户购买各种书的统计信息,就需要把以上数据转换为如下格式:
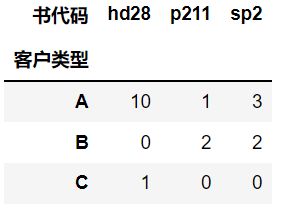
不难发现要想转换成交叉表只需将信息表的行和列进行旋转即可得到
df=DataFrame({'书代码' : ['p211', 'p211', 'sp2', 'sp2', 'hd28', 'hd28'], '客户类型' : ['A', 'B', 'A', 'B', 'A', 'C'], '购买量' : [1, 2, 3, 2, 10, 1]}, columns = ['书代码', '客户类型', '购买量'])
###转换后,出现一些NaN值或空值,我们可以把NaN修改为0
df1 = pd.pivot_table(df, values = '购买量', index = '客户类型', columns = '书代码', fill_value = 0)
df1
2 实例分析
(1) 把csv数据导入pandas
from pandas import DataFrame
import numpy as np
import pandas as pd
path = 'pandas-data/stud_score.csv'
data = pd.read_csv(path, encoding = 'gbk') #要修改编码方式,否则中文不能正常显示
#其他参数:
###header=None 表示无标题,此时缺省列名为整数;如果设为0,表示第0行为标题
###names,encoding,skiprows等,skiprows较为常用,用来删除第一行
#读取excel文件,可用 read_excel
df = DataFrame(data)
df.head() ###显示前5行
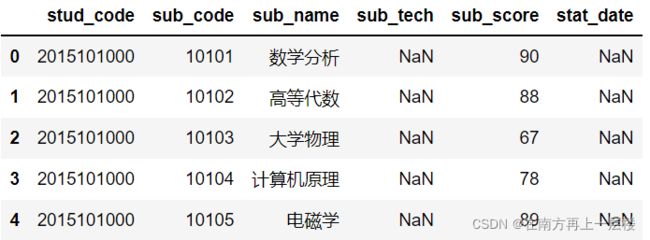
(2) 查看df的统计信息
df.count() #统计非NaN行数
df.info() #查看数据的缺失情况
df.describe() ##各列的数据情况
df['sub_score'].std() ##求学生成绩的标准差
df['sub_score'].var() ##求学生成绩的方差
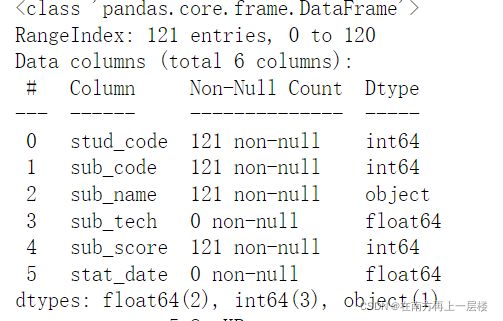
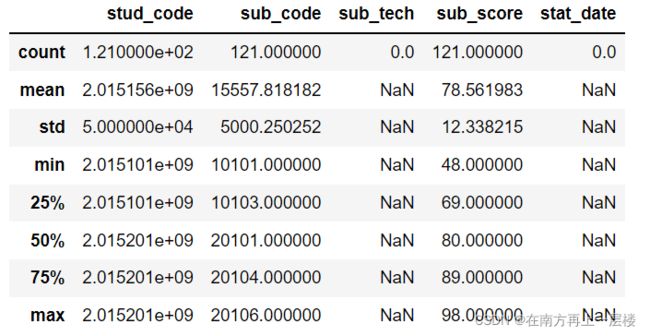
(3) 选择部分列
因为在现实数据中,常常存在着大量冗余数据,本次的例子中第四列就是冗余的,因此这里选择学生代码、课程代码、课程名称、程程成绩,注册日期列。
#根据列的索引来选择
df.iloc[ : , [0, 1, 2, 4, 5]]
#或根据列名称来选择
df = df.loc[ : ,['stud_code', 'sub_code', 'sub_name', 'sub_score', 'stat_date']]
(4) 补充缺省值
a.用指定值补充NaN值,这里要求把stat_date的缺省值(NaN)改为’2022-2-8’
df1 = df.fillna({'stat_date' : '2022-2-8'})
df1.head()
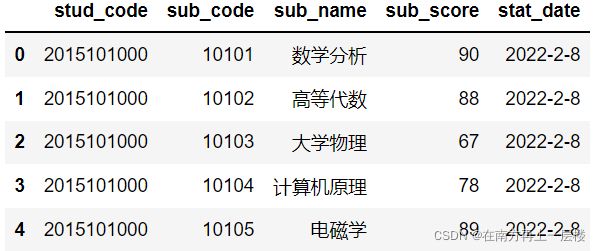
b. 可视化前五名学生的成绩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas import DataFrame
from matplotlib.font_manager import FontProperties
%matplotlib
df2 = df1.loc[ : , ['sub_name', 'sub_score']].head(5)
#设置字体类型及大小
font = FontProperties(fname = r"c:\windows\fonts\simkai.ttf", size=14)
#设置画布大小
plt.figure(figsize = (10,6))
x = np.arange(5)
y = np.array(df2['sub_score'])
xticks = list(df2['sub_name'])
#画柱状图,两柱之间相差距离为0.35
plt.bar(x, y, align = 'center', width = 0.35, color = 'b', alpha = 0.8)
#设置横纵坐标标签及主题
plt.xticks(x, xticks, fontproperties = font)
plt.xlabel('课程类别', fontproperties = font)
plt.ylabel('成绩', fontproperties = font)
plt.title('不同课程的成绩', fontproperties = font)
#设置数字标签
for a, b in zip(x, y):
plt.text(a, b + 0.05, f'{b : 0.1f}', ha = 'center', va = 'bottom', fontsize = 14)
plt.ylim(0, 100)
plt.show()
