Java面试相关知识点
这篇笔记主要用来记录一个大牛的java相关知识点
一、计算机网络
网络上的知识,基本上以理论为主
1. OSI七层协议
物理层:用于信号传输,进行数模转换/模数转换,基本数据是:比特,网卡在这一层工作
数据链路层:定义格式化数据进行传输和为物理介质的控制,提供数据校验,基础数据是:帧,交换机在这一层工作
网络层:将网络地址翻译成物理地址并且决定传输的路径,基本数据是:数据包,路由器在这里工作(TCP/IP协议就在此层)
传输层:解决数据传输的稳定性,必要时将数据分割(TCP/UDP协议就工作在此层)
会话层:解决不同操作系统的通讯语法的问题
应用层:(HTTP协议就工作在此层)
2. TCP/IP协议族的四层协议
OSI七层协议知识一个概念性的框架,TCP/IP协议族是OSI七层模型的实现,但是它并没有完全按照OSI七层模型进行实现。
3. TCP和三次握手
IP协议是无链接的通讯协议,但是IP协议没有控制包的顺序和可靠性,因此需要上层的TCP协议进行控制。
TCP将上层的数据报文分割成适当大小的包交给网络层进行发送,为了保证顺序和可靠,TCP会对每个包进行编号,并且需要接收方发送ACK进行确认来确保不会丢包
3.1 TCP报文头
3.2 三次握手
相关的标识位如下:
- ACK:缺人需要表示1:确认有效 0:不含确认信息
- SYN:同步需要 SYN=1且ACK=0表示没有捎带确认的信息 SYN=1且ACK=1表示会稍带确认上一条数据
- FIN:结束标志
握手过程:
- C端发出SYN包(seq = x)请求建立链接,进入SYN-SENT状态
- S端收到刚刚的SYN包,发出确认包(ack = x+1),并且自己也发出一个SYN包(seq = y),请求确认,进入SYN-REVD状态
- C端收到S端的确认包和SYN包,再发送一个确认包(ack = y+1),这是进入ESTAB-LISHED状态,S端收到后也进入ESTAB-LISHED状态,开始传输数据
注意:第二次握手时S端收到首次发送C端的SYN包,发送确认包和自己的SYN包时如果S端没有收到ACK确认时,S端会不断重试,linux默认情况下会等待63秒
4.四次挥手

- 挥手过程
- C端发送FIN包(seq = u)请求关闭链接,进入FIN-WAIT1状态
- S端收到FIN包,并且发送确认包(ack = u+1),进入CLOSE-WAIT状态,C端收到后进入FIN-WAIT2状态,等待S端发送最后的数据
- S端完成最后数据的发送后,发送FIN包(seq = w),并且再次确认(ack = u+1),发送后S端进入LAST-ACL状态
- C端收到S端发送的FIN包后,发送确认包(ack = w+1),自己进入TIME-WAIT状态,经过两个延迟时间后正式关闭链接,S端收到后也会直接关闭链接
- 为啥需要有TIME-WAIT状态
- 保证S端收到最后发送的ACK包,并且保证不会和后面的链接混淆
- 频繁出现大量CLOST-WAIT的原因
- 在客户端应用层关闭Socket后,服务器忙于读写没有进一步发送第二个FIN包导致大量CLOST-WAIT积压
5.UDP和TCP的区别
5.1 UDP的特点
- UDP时非链接的,不支持错误重传,华东窗口等,只会尽可能快的传入网络中
- 不用维护链接状态,可以同时想多个客户端传输一样的信息
- UDP不保证可靠,保证速度
- UDP时面向报文的,不具备有序性,所有的事情会交给上层应用处理
6. TCP的滑动窗口
TCP的滑动窗口是为了解决TCP的流浪控制和乱序重排的问题,未来研究这个问题,我们先知道下面这两个概念
RTT:发出需要确认的包到收到确认包到时间
RTO:重传时间间隔(确认包的超时时间)
6.1 滑动窗口过程

每次收到接受放确认的连续包后,窗口会进行滑动,框入更多的未发送数据
7. HTTP协议
主要特点:
- 支持客户/服务器模式
- 简单快速,只要发送请求方法和路径即可
- 无链接的,传输完数据就会断开链接
- 无状态的,两次链接的状体对方不可感知
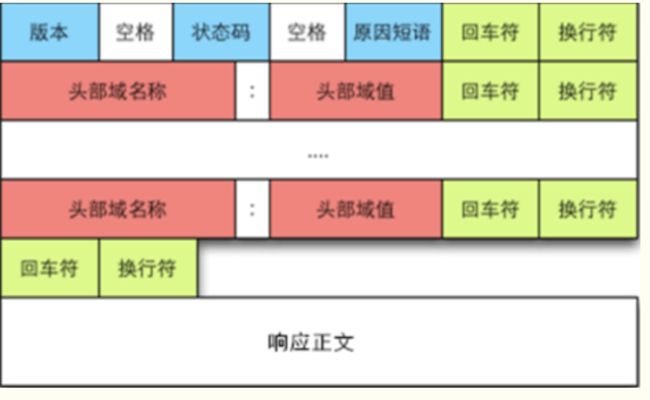
7.1 HTTP请求/响应结构
- 请求报文结构如下
- 响应报文结构如下
7.2 Cookie和Session
- Cookie:服务器要求客户端保存的信息
- Session:根据客户端发送的session-id来在服务器中检索session信息
- 使用cookie保存session-id
- 使用url参数保存session-id
7.3 HTTPS
加入ssl层,加入安全套接层,提供安全和数据完整性的协议,通过身份验证和数据加加密的完整性
- 加密的方式
- 对称加密:加密和解密使用同一个密钥,性能较高
- 非对称加密:加密使用公钥,解密使用私钥
- 哈希算法
- 数字签名:证明某个消息是某人发送的,没有被篡改的
- HTTPS流程
- 浏览器发送支持的加密算法发送服务器
- 服务器选择一套浏览器支持的算法,发送相关证书给浏览器
- 浏览器验证证书合法性,并且使用证书中的公钥加密传输用的对称加密对称加密的密码,发给服务器
- 服务器使用私钥解密浏览器发送的对称加密密码
二、 数据库
1. 数据库设计和模块划分
如果我没来设计数据库,需要这样几部分
- 存储模块:将数据存入磁盘
- 存储管理:将物理数据组织和表述
- 优化存储效能?一次性读取多行减少IO次数
- 缓存机制
- SQL接信息模块
- 日志管理:管理操作日志
- 用户权限模块
- 异常容灾难机制
- 索引模块
- 锁模块
2. 索引模块
为什么要使用索引?
相当于字典的目录,通过索引可以大幅提升查询速度
2.1 索引的数据结构
-
二叉查找树
二叉树.png二叉查找树:对于树中的任意节点,比左子树的值大,比右子树的值小��
平衡二叉树:根结点的左右子树高度相差不超过1
查找效率:O(logn),但是最多两个孩子的设定会大大增加树的深度,增加查找次数
-
B树
3阶段B树B树可以通过策略保证新增节点不会变成线性的(B树节点的分裂,合并)
-
B+数(MySQL使用这种数据结构作为索引)
B+树B+树的数据全部存储在叶子结点上,非叶子结点只用于索引,叶子结点的链表结构也便于做数据统计和全盘扫描
-
Hash结构
相当于Java的HashMap的索引方式,只需要O(1)的时间
但是无法排序、范围操作,可能同一个哈希插入太多值造成效率不如哈希
2.2. 密集索引和稀疏索引的区别
密集索引:每一个搜索码都对应一个搜索值(只能有一个,相当于组件,相当于叶子结点保存了所有的信息)
-
稀疏索引:只为了索引某些相才建立的索引(叶子结点里只保存了数据的存储地址)
在MySQL的MyISAM引擎里所有的索引都是稀疏索引
MySQL的InnoDB引擎的索引有且仅有一个密集索引(主键 ==> 第一个唯一非空索引 ==> 生成隐藏的索引 )
因此在使用InnoDB的稀疏索引时会先找到对应的密集索引,再通过密集索引找到数据(两次索引)
2.3 SQL衍生问题
-
如何优化慢SQL
-
根据慢日志定位问题:修改mysql中的变量来开启慢日志(下面的操作在my.ini更改后就会永久保存)
shwo variables like 'query' #找到和查询有关的全局变量 set global show_query_log = no #开启慢日志 set global long_query_time = 1 #设置慢查询时间为1秒 show status like '%slow_queries' #查看慢sql个数 -
利用
explan来分析select查询,用法就是在select前面加上explan就好了关注出现的
type字段,如果是“index”或者"all"就表明查询是通过全表扫描完成的,需要优化-
关注
extar字段[图片上传失败...(image-52b86-1584189158882)]
修改SQL让其尽量使用索引或者添加索引
-
-
联合索引最左原则
最左匹配原则:A、B字段组成联合索引,当
where A = xxx和where A = xxx and B = xxx时,会使用这个联合索引,但是当where B = XXX时,就不会使用这个索引了-
原因:联合索引建立时,会先对第一个字段进行排序,在这个顺序的基础上再对第二个字段进行陪许,因此第二个字段是局部有序的
最左匹配
-
索引是越多越好吗
索引并不是越多越好。索引也需要维护并且占用空间。
3. 锁模块
3.1 MyISAM和InnoDB锁的区别
MyISAM默认表级锁,不支持行级锁
-
InnoDB默认行级锁:在使用索引时使用行级锁,不使用索引时使用表锁
两种引擎适合的场景:
MyISAM:频繁执行全表count、查询操作较多(只有表锁,效率低),写的操作较少、不需要事务
InnoBD:增删改查都很频繁的系统、稳定性要求较高
3.2 锁的分类
- 锁的粒度划分:表级锁,行级锁,页级锁
- 锁的级别划分:读锁 = 共享锁,可以反复加上 写锁=独占锁,只能加上一次,且不能和读锁共存
- 加锁的方式划分:自动锁,显式锁
- 按操作划分:DML锁:对数据进行加锁 DDL锁:对表结构枷锁
- 使用方式划分:悲观锁:先取锁,再访问,乐观锁:只有提交更新时才会检测是否冲突
3.3 数据库事务的四大特性
- A:原子性:对于事务中的操作,要么全执行,要么全不执行(回滚)
- C:一致性:数据库中的数据在事务执行前后应保存一致
- I:隔离性:多个事务的并发执行不会相互影响(隔离等级)
- D:持久性:事务一旦提交,对系统的修改应该永久保存
3.4 事务并发访问产生的问题和隔离级别
-
事务并发访问可能引起的问题
-
丢失修改:一个事务的更新覆盖了另一个事务的更新(在任何隔离级别(读未提交)下都可以防止)
丢失修改 脏读:读取到还未提交的事务修改的数据(可以在读已提交级别防止,该级别不允许读未提交的数据)
不可重复读:事务A多次读取同一个数据,事务B在A读取时作出更新并提交导致A在多次读取时内容不一致(可以在可重复读级别防止,该级别确保别的事物的提交不会更改本次事务查询的结果)
幻读:事务A多次读取若干行,事务B进行插入或者删除操作导致事务A多次读取的数据的数量不一致(可在Serializable级别防止,这个级别会让事务串行提交)
事务隔离级别越高,事务的并发度越低,因此需要根据需求来确定隔离级别
在MySQL的InnoDB中如何在可重复读中避免了幻读的?
MySQL中存在两种读取数据的方式:当前读和快照读
- 当前读:selete ... lock in share mode、delete、update、insert操作都为当前读,当前读会获取数据的最新版本
- 快照读:不加锁的读selete为快照读,在“可重复读”的隔离级别下,读到的不是数据的最新版本。在“可重复读”的级别下,快照读读出的都是第一次执行这条语句的数据。
-
4. SQL关键语法
假设我们的表结构如下
4.1 Group By
根据查询结果进行分组查询,对每个组的数据进行聚合运算。
例子:查询所有同学的学号,姓名,选课数,和每个同学成绩的总和
selete s.student_id,stu.name,count(s.coures_id),sum(s.score)
form score s,student stu
where s.student_id = stu.student_id
greop by student_id
4.2 Having
通常于Group By一起使用,给Group By 添加限定条件
例子: 查询所有平均分大于60分的同学的学号,姓名,选课数,和每个同学的平均成绩
selete s.student_id, stu.name, count(s.coures_id), avg(s.score)
form score s,student stu
where s.student_id = stu.student_id
greop by student_id
having avg(s.score) > 60
例子:查询使用没有学全所有课程的学号和姓名
selete s.student_id, stu.name
from score s, student stu
where s.student_id = stu.student_id
group by s.student_id
having count(*) < (
select count(*) from course
)
三、Redis
- Redis快的原因
- Redis是完全基于内存的
- 数据结构简单
- 采用单线程和IO多路复用,不存在上下文切换问题
1 IO多路复用模型
- Select系统调用:可以监控多个IO的文件描述符,只用一个线程就可以完成多个IO的操作
2 Redis数据类型
- String:最基础的数据模型,是包括二进制的
- Hash:String元素组成的字典,可以方便的存入POJO
- List:String元素组成的队列,有序可重复
- Set:String元素组成的集合,无序不重复,集合可以交集并集的操作
3 相关问题
3.1 如何从redis中查询固定前缀的简直对
使用keys指令:keys会一次性获取所有参数,数据过大时可能会使服务器卡顿
-
使用Scan命令,相当于给返回数据分页,每次查询可以从上次结束的地方继续查询,但是可能会获取到重复的问题,而且给的的count并不会完全符合
scan [开始行] match [匹配模式] count [个数]
3.2 实现分布式锁
- 使用
SETNT [key] [value]来设置一个值,设置成功返回1,失败返回0且不会被更改,再使用EXPIRE [key] [seconds]来设置过期时间「这种模式并没有原执性,使用set [key] [value] ex [seconds]来保证原子性」
3.3 避免同一时间大量的key过期
过期时间需要添加随机值
3.4 redis做一步队列(消息队列)
用list数据的pop操作和push的操作
- 使用
BLPOP [key] [超时时间]来达到监听的效果 - 使用pub/sub主题订阅者模式做消息订阅的效果,用
publish [topic] [msg]来发布消息,用subscribe [topic]来接受相关的消息,甚至不用创建频道。但是这个状态是无状态的,不保证送达,如果有更高的需求,就要使用专业的消息队列了
4 Redis持久化方式
4.1 RDB持久化
会在固定的间隔保存一次整个数据库的全量数据。使用save指令在主线程中进行RDB备份,使用bgsave指令使用fork的子线程完成备份
4.2 AOF持久化
相当于备份操作日志,每一个和写入有关的操作会被记录到一个文件中
四、Java相关知识点
1. ClassLoader
1.1 类从编译到执行的过程
- 编译器把.java文件编译成.class字节码文件
- ClassLoader将直接码读入内存中,转换为JVM中的Class对象
- JVM再使用Class对象将其实例化为对应的对象
1.2 ClassLoader
在JVM中,所有的类对象都是由ClassLoader进行加载的,主要功能是从class文件中的二进制数据流加载类对象,是Java的核心组件
-
ClassLoader的种类
BootStrapClassLoader:是java的核心库,是C++编写的
ExtClassLoader:Java编写的,用于加载扩展库
APPClassLoader:Java编写,加载classpath下相关的文件
-
自己定义的ClassLoader:用于定制化加载,只要传入的二进制流,就可以进行类的加载(从压缩包获取,从网络中获取等等)
package com.libi.classloader; /** * @author :Libi * @version :1.0 * @date :2020-03-05 20:56 */ public class MyClassLoader extends ClassLoader { private String path; private String classLoaderName; public MyClassLoader(String path, String classLoaderName) { this.path = path; this.classLoaderName = classLoaderName; } @Override protected Class findClass(String name) throws ClassNotFoundException { byte[] b = loadClassData(name); return defineClass(name, b, 0, b.length); } //从文件中读出class数据流,我这边不想写了 private byte[] loadClassData(String name) { return null; } //如何通过自定义的ClassLoader进行类的加载 public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException { //创建ClassLoader MyClassLoader myClassLoader = new MyClassLoader("path", "name"); //生成类对象 Class c = myClassLoader.loadClass("name"); //生成实例 Object o = c.newInstance(); } }
-
ClassLoader的双亲委派机制
双亲委派机制ClassLoader中,加载类的部分源码如下
protected Class loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // 首先检查这个类是否被加载 Class c = findLoadedClass(name); if (c == null) { //如果没有被加载那么委托它的父加载器,父加载器为空则委托Bootstrap加载器 long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // 如果父加载器仍然没有找到,就自己找 long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } } -
为什么要使用双亲委派机制?
避免一个类被加载多次,节约内存
1.3 类装载方式
类装改过程如下

- 隐试加载:new(顺带获取实例)
- 显示加载:
- ClassLoader.loadClass:还没有完成链接,只完成加载
- Class.forName:已经完成初始化
2. JVM内存模型
2.1 内存模型划分的区域
从线程的角度分类
- 程序计数器:相当于行号指示器,是线程独立的
- Java虚拟机栈:相当单个线程于虚拟机执行的调用栈,每个栈帧包括局部变量表,关键数,方法出口等信息
- 本地方法栈:调用本地方法是就会使用到本地方法栈
- 元空间(类似之前的永久代,元空间使用本地内存,但是永久代使用的是java管理的内存)
- 字符串常量池存(现在代队内存中)在永久代中可能出现性能问题
- 简化GC的操作
- 永久代的大小指定不再成为问题
- Java堆
2.2 JVM常见问题
- JVM性能调优参数
- -Xss:每个线程虚拟机栈的大小
- -Xms:堆的初始大小
- -Xmx:堆的最大大小
- 内存分配策略
- 静态存储:编译时就可以确定的空间需求
- 栈式存储:编译时未知,但是但是允许开始前夕可以确定
- 堆式存储:运行时都无法确定使用的内存大小,完全动态分配
3. Java垃圾回收机制
3.1 判定为垃圾的算法
当一个java对象没有被任何对象引用时就会判定为垃圾
-
引用计数法
- 任何对象里有引用计数器,当引用计数为0时,就会判定为垃圾
- 优点:速度很快,不会影响程序、缺点:无法辨别循环引用的情况
-
可达性分析
-
通过对象的引用链来判断是否可以从GC Root进行查找
- GC Root:虚拟机栈、方法区的常量和静态引用的对象
- JNI引用的对象
- 活跃的线程对象
可读性分析
-
3.2 垃圾回收算法
-
标记清除算法
- 标记:扫描整个GC root,对存活的对象进行标记。清除:对整个堆进行扫描,清除不可达对象
标记清除- 缺点:可能产生大量碎片空间导致无法利用
-
复制算法
-
把整个堆空间分为对象面和空闲面,每次在创建对象在对象面,进行GC时把可用的对象复制到另一边
复制算法 解决的空间的碎片化问题,且适用于存活率较低的情况。但是会浪费50的空间,若存活率较高,则会产生大量复制操作,浪费时间。
-
-
标记整理算法
- 标记:扫描整个GC root,对存活的对象进行标记。整理:移动存活的对象,移动到前端,再清除后面的所有的空间
标记整理 - 避免了空间的碎片,适用于存活率高的场景
- 标记:扫描整个GC root,对存活的对象进行标记。整理:移动存活的对象,移动到前端,再清除后面的所有的空间
3.3 分代收集算法
对内存进行分类,不同的空间使用不同的手机算法
-
新生代的划分
- Eden区:新创建的对象出生的区域
- 两个Survivor区
GC会先去清理Eden区域,把存活的对象放入Survivor区域,Survivor区域使用复制算法进行手机。当Survivor区域的对象连续存活一定时间后,将会进度老年代。
当较大的对象会直接进入老年代
-
进入老年代的情况
- 在Survivor区域存活次数超过一定数字时
- Survivor区域装不下时
- 新生成的大对象
-
GC的分类
Minor GC:用于新生代的GC
Full GC: 用于老年代的GC,通常也会对新生代进行GC
出发FullGC的条件
- 老年代空间不足
- 永久代空间不足
- 预计下次MinorGC需要晋升到老年代的大小大于老年代的平均空间
- 调用System.gc()
3.4 新生代的垃圾收集器
-
相关概念
- Stop-the-World:JVM在执行GC时会停掉除了GC线程意外的所有线程
- Safepoint:分析引用关系不会发生变化的时间点,只有程序执行到safepoint,gc才会停掉工作线程。如:循环跳转,方法调用等时间点
Serial收集器:单线程收集器,必须停掉所有线程
- ParNew收集器:多线程收集的Serial
- Parallel Scavengel收集器:面向吞吐量的GC,会尽可能后台完成任务
- 吞吐量 = 运行时间/运行时间+GC停下来的时间
3.5 老年代收集器
- Serial Old收集器:单线程标记整理

- Parallel Old收集器:多线程的标记整理
-
CMS收集器:可以后台运行一部分工作,使用标记清除算法
CMS
- G1收集器
- 是并行和并发的收集器
- 可以分代收集
3.6 相关问题
-
Java的finalize()方法有什么用
这个方法会在将要被收集前调用,作用是让其有机会再次和GC Root链接(给其重生的机会)
-
Java的强引用,弱引用,弱引用,虚引用
- 强引用:宁可抛出OOM也不会释放掉还在被强引用的对象
- 软引用:当内存不足时,即使对象还在被弱引用,这个对象也会被回收,用于高速缓存,可用于引用队列
- 弱引用:每次GC都会被回收,但是因为GC线程优先级低,所以也不会被很快回收,可以配合引用队列
- 虚引用:对GC来说和没有引用是一样的,用于跟踪对象的生命周期,必须配合引用队列
4. Java并发编程
4.1 java线程相关
-
进程和线程的区别
进程是资源分配的最小单位,线程是cpu调度的最小单位。线程并没有被看作独立应用,只有独立的堆栈和局部变量,没有独立的地址空间
线程和进程 -
如何给run()方法传递参数
- 构造函数传参
- 成员变量传参
- 回调函数传参
-
如何处理线程的返回值
- 主线程等待:使用
Thread.join()的方法阻塞当前线程 - 通过Callable接口实现:
- 通过
FutureTask类,传入Callable接口的实例,调用call()方法和get()方法,就可以获取到返回值 - 通过线程池的
submit()方法传入神经Callable接口的实例,通过返回的Future实例进行获得返回值
- 通过
- 主线程等待:使用
-
线程的状态
- 新建(new):创建后还没有启动的状态
- 运行(Runnable):线程正在运行或者等待cup时间
- 等待(Waiting):无限期等待,这个线程正在等待被唤醒
- 有限等待(Time Waiting):一定时间后会被系统自动唤醒
- 阻塞(Blocked):等改获取锁或者等待io
- 结束(Terminated):已经终止的线程,线程已经执行完成,不能再次运行
线程的状态 -
sleep()和wait()方法- wait方法用于让出锁(调用成为锁的对象的wait方法),可以让其他等待资源的线程获得锁
- sleep方法只会让出cpu,锁的状态不会改变
-
notify()和notifyAll()-
notifyAll会唤醒全部等待这个锁的线程,而notify只会唤醒一个 - 这两个方法都不会释放自己的锁
-
-
Thread.yiele()方法当前线程愿意让出cpu使用权,但是是否让出还是取决于调度器
-
如何中断线程
- 已经被废弃的
stop()方法,这个方法会暴力地停下线程,导致后续清理的问题 - 调用
interrupt()方法,希望线程结束。- 如果这时线程处在阻塞、等待的状态,那么就会马上抛出
InterruptedException异常 - 如果线程处于正常活动的状态,也只会把它的中断标志设置为true,线程仍会继续运行,至于要如何中断,需要自己实现
- 如果这时线程处在阻塞、等待的状态,那么就会马上抛出
- 已经被废弃的
4.2 java中的锁
-
synchronized的底层对锁的优化
-
自适应自旋锁
- 自旋:大部分情况下,线程只需要很短的时间就可以获取锁,这时进行线程状态切开销较大。因此通过让线程自行忙循环等待锁是否
- 自适应自旋:自旋尝试的次数不再固定,由上一个获取到锁的自旋次数和现在拥有者的状态来决定。如果上一次线程是通过自旋获取到锁的,而且线程正在运行中,jvm就会认为自旋获取到锁的几率很大,就会增加自旋尝试次数
锁消除:JIT编译时,会对上下文扫描,消除没有竞争的锁,避免不必要的开销
-
锁粗化:如果对一个对象频繁进行加锁,也会消耗不少的资源,这时就会进行锁的粗化,扩大锁的范围
锁的状态:无锁 ==> 偏向锁 ==> 轻量级锁 ===> (自旋锁?) ===> 重量级锁
偏向锁:大多数情况总是一个线程获得了锁,因此一个线程获得锁后,锁就变成了偏向模式,该线程下一次获取锁事,不需要再做任何同步的操作就会获得锁。但是对于锁竞争比较激烈的场合并不适用
轻量级锁:当第二个线程开始争夺锁后,锁的模式就升级成的轻量级模式。如果线程是交替执行同步快的时候,轻量级锁就会启动
重量级锁:当有锁不再是两个线程交替执行而是开始等待时,锁就会变成重量级锁
-
-
synchronized和ReentrantLock(重入锁)的区别
- ReentrantLock是JUC包下的锁类,实现了多种实用的方法,基于AQS实现的
- ReentrantLock一定要显示的释放锁,不然会导致该线程一直持有锁
- ReentrantLock有比synchronized实现了更多的功能
- 实现公平锁(给锁的顺序倾向于给等待时间最长的线程,比非公平锁性能降低)
- 可以设置获取锁的超时时间
- 判断是否有线程或特定线程是否在尝试获取该锁
- 判断是否可以获得该锁
- ReentrantLock的
newCondition()方法获取的对象有awit()和singal()方法实现等待和通知操作 - synchronized使用的是操作对象头中的MarkWord,ReentrantLock使用的是Unsafe类下的
park()方法
4.3 JMM如何解决可见性的问题
-
Java内存模型(JMM):只是一个规范,它规定了程序中的变量访问内存的方式
image.png- 所有的变量都存储在主内存中,所有的内存都可以共享访问。
- 线程对变量的操作只能在工作内存中执行,线程把要操作的数据拷贝到自己的工作内存中,运行完成后再写回主内存,不会直接操作主内存
-
多线程共享内存可能会导致数据一致性的问题,因此JMM会对一些操作进行优化
指令重排序:如果两个操作无法通过happens-before原则推导出来,才可以进行重排序
-
happens-before原则:A操作如果需要对B操作可见,则A,B存在happens-before原则。happens-before原则具体如下图
image.png如果两个操作不满足上述任何一个规则,那么这两个操作就没有执行顺序上的保障,JVM会对这两个操作进行重排序。反之,如果A happens-before B,那么A的操作在B上就是可见的
-
volatile关键字:
- 保障被其修饰的共享变量在所有线程中是可见的,对这个变量的任何改动都会立即反应到共享内存中
- 禁止指令的重排序
- 并不能保障操作的原子性,因此不能完全保障并发安全
-
volatile如何保障立即可见
- 被volatie修饰的变量被改变时,JMM会立即刷新到主内存中
- 每读一个volatile变量,JMM会对对应的工作内存置为无效,线程只能从主内存中读取
-
volatile如何保障禁止重排序
- 插入内存屏障
4.4 乐观锁和CAS操作
- JUC包下提供了atomic包提供了很多原子性的数据类型和引用
- 缺点:
- 如果循环时间太长,开销很大
- 只能保障一个变量的原子性操作
- ABA的问题
4.5 Java线程池
利用Executors提供的线程池可以满足不同场景的需求

-
使用线程池的原因
- 减少创建线程的消耗,复用线程
- 统一管理,调优和监控
-
JUC的有关线程池的接口
-
Executor:只有
executor()的方法,只是用于和任务提交和执行细节解耦public interface Executor { void execute(Runnable command); } -
ExecutorService:扩展了Executer,提供了管理器和生命周期的方法
public interface ExecutorService extends Executor { void shutdown(); ListshutdownNow(); boolean isShutdown(); boolean isTerminated(); boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; //后面的代码略过 } ScheduledExecutorService:扩展ExecutorService,增加了Future和定时任务
-
-
ThreadPoolExecutor线程池
线程池- 线程池相关的参数
- corePoolSize:核心线程数,长期驻留的线程数量
- maximumPoolSize:线程可以创建的最大线程数量
- woreQueue:当核心线程满了之后任务等待的队列。我们使用不同的队列,就会有不同的排列机制
- keepAliveTime:当核心线程以外的线程闲置以后可以存活的时间
- ThreadFactory:用于创建线程
- handler:任务的拒绝策略
- AbortPolicy:直接抛出异常
- CallerRunsPolicy:使用调用者的线程执行任务
- DiscardOldestPolicy:丢弃阻塞队列中最前的任务并且执行本任务
- DiscardPOlicy:直接丢弃任务
- 可也以自己实现RejectedExecutionHandler接口来自定义handler
- 线程池中对任务的处理:
- 如果当前线程数小于核心线程数,则创建一个线程执行(即使其他线程空闲)
- 如果当前任务大于核心线程数,则封装后进入等待队列
- 如果等待队列已满,则创建临时线程执行任务
- 若当前线程数大于最大线程数,且阻塞队列已经满了,则通过handler定义的策略处理任务
- 线程池的运行状态
- Running:正在运行,线程池可以提交新的任务
- Shutdown:正在停止,线程池不再接受新的任务,但是还会处理队列中的任务,调用线程池的
shutdown()方法会使线程池进入这个状态 - Stop:完全停止,线程池不再接受新的任务,也不处理队列中的任务,线程池中的线程会被中断,调用线程池的
shutdownNow()方法或者shutdown状态的线程池执行完剩余任务会使线程池进入和这个状态 - Tydying:所有的任务都已经终止了
- Terminated:
- 线程池相关的参数