一文带你深入了解Java泛型
文章目录
- JAVA为什么引入泛型
- JAVA泛型
-
- Java泛型不是真正的泛型
- Java泛型使用擦除机制的原因
- Java泛型的使用
-
- Java泛型类
- Java泛型接口
- Java泛型方法
-
- 注意事项
- Java泛型通配符
-
- 上界通配符
- 下界通配符
- 无界通配符
- Java泛型总结
- 结语
本文收录专栏《深入理解Java虚拟机》.
JAVA为什么引入泛型
⭐️泛型思想早在c++语言的模板中就开始生根发芽,在Java语言处于还没有出现泛型的版本时,只能通过Object是所有类型的父类和类型强制转换两个特点的配合来实现类型泛化。
⭐️在哈希表的存取中,JDK1.5之前使用HashMap的get()方法,返回值就只有一个Object对象,由于Java语言里面所有的类型都继承于Java.lang.Object,所以Object转型成任何对象都是有可能的。
⭐️但是也因为有无限的可能性,就只有程序员和运行期的虚拟机才知道这个Object到底是个什么类型的对象。在编译期间,编译器无法检查这个Object的强制转型是否成功,如果仅仅依赖程序员去保障这项操作的正确性,许多ClassCastException(类型转换错误)的风险就会转嫁到程序运行期间,造成一系列的错误。
class A{ private Object object; public Object getObject() { return object; } public void setObject(Object object) { this.object = object; } } class B{ public String bTalk(){ return "this is B"; } } class C{ public String cTalk(){ return "this is C"; } } 当我们创建了如上三个类后 public static void main(String[] args) { A a = new A(); a.setObject(new B()); B b = (B)a.getObject(); a.setObject(new C()); C c = (C)a.getObject(); }

可以看到虽然程序一切运行正确,但前提是我们一路强转。
可实际用在工程中呢?这段程序存在两个较大的问题:
①程序强制转换太多很容易强制转换出错,导致程序运行异常。
②即使强制转换出错了,在编译期也检查不出来, 只能在程序运行的时候抛出异常。
⭐️因此,Java引 入了泛型,使类型转换在编译期就能被检查出来,从而减少程序的错误:
class A<T>{ private T object;//object只是一个名称,可以随便取啥 public T getObject() { return object; } public void setObject(T object) { this.object = object; } } 当我们引入泛型后 A<B> a = new A(); a.setObject(new B()); B b = a.getObject(); /*a.setObject(new C());//编译出错,类型不对 C c = a.getObject();*/ 没有人为的去强制转换,而且对于本身错误的代码直接给出错误提示

JAVA泛型
Java泛型不是真正的泛型
⭐️泛型技术在c#和Java之中的使用方式看似相同,但实现上却有着根本性的分歧,c#里面泛型无论在程序源码中、编译后的中间语言中或是运行期的语言中,都是切实存在的,List< Integer > 和List< String >就是两个不同的类型,他们在系统运行期生成,有自己的虚方法表和类型数据,这种实现称为类型膨胀,基于这种方法实现的泛型称为真实泛型。
⭐️而Java语言的泛型则不一样,它只在程序中存在,在编译后的字节码文件中,就已经被替换为原来的原生类型了,如List< String >被替换成了List。并且在相应的地方插入了强制类型转换的代码。(如若不了解此,可参考上一篇我写的文章:擦除机制)。因此,对于运行期的ArrayList< String > 与 ArrayList< Integer > 就是同一个类。Java语言中实现泛型的方法称为类型擦除,因此Java的泛型是一个伪泛型。
Java泛型使用擦除机制的原因
⭐️Java泛型实现是通过擦除机制实现的,那么Java为什么要用擦除机制来实现泛型,而不是用类似c#的类型膨胀法呢?
⭐️用这种方法其实是有历史原因的,当年java1.0出来的时候并没有泛型,现在要在加上泛型,最大的问题当然是兼容性,不能影响到以前没有泛型的java代码;
⭐️ 所以java的先贤们就想出了这样一种办法,在编译器限定了你编写容器类时就填入特定的类型,如果不填就警告,如果放入和取出不同类型就报错,不让编译,用一个角括号“<>”来填写特定类型,非常简单。它归结起来有者几个特点:1️⃣ 兼容于 Java 语言。Java 泛型是 Java 的超集。每个 Java 程序在 java 加入泛型之后 都仍合法而且不会影响程序的含义;
2️⃣兼容于 Java 虚拟机(JVM)。Java 泛型 被编译为 JVM 码。JVM 不需為了它而有任何改变。因此传统 Java 所能执行之处,Java 泛型都能执行;
3️⃣兼容现在的程序。既有的程序库都能够和 Java 泛型共同运作,即使是编译后的 .class。有时候我们也可以将某个原程序库翻新,加入新的带有泛型的程序,而不需更动其源码。Java collections framework 就是这样被翻新而加入泛型的。
4️⃣高效(efficiency)。泛型相关资讯只在编译期(而非执行期)才被维护着。这意味编译后的 Java 泛型 程式码在目的和效率上几乎完全和传统的 Java代码一致;
Java泛型的使用
Java泛型类
泛型类的基本写法:
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
.....
}
一个泛型类:
class A<T>{
private T object;object只是一个名称,可以随便取啥,类型由外部类型决定
public T getObject() {
return object;
}
public A(T object) {//泛型构造方法
this.object = object;
}
}
当我们要使用这个类时,可以这样做:
A< Integer > a = new A(123);//传入的实参(123)要与泛型的类型参数(Integer)相同。
⭐️但是定义的泛型类,就一定要传入泛型类型参数吗?并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。
A a1 = new A(123);
A a2 = new A("hello world");
A a3 = new A("1.0);
A a4 = new A(false);
这些代码都能通过编译,但是这时这个泛型的处境会很尴尬,你在泛型类中使用泛型方法或成员变量定义的类型可以为任意类型,那么取出来时又需要强制转换,与没使用泛型时一模一样。
 ⭐️强调:泛型的类型参数只能是类类型,不能是基本类型。
⭐️强调:泛型的类型参数只能是类类型,不能是基本类型。
Java泛型接口
⭐️泛型接口与泛型类的使用方法几乎一致,只不过泛型类使用class,接口使用interface。
//定义一个泛型接口
interface A<T> {
public T next();
}
//当实现泛型接口的类未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
//即:class B implements A
class B<T> implements A<T> {
public T next(){
return null;
}
}
//当实现泛型接口的类传入泛型实参时:所有使用泛型的地方都要替换成传入的实参类型
public class B implements A<String> {
@Override
public String next() {
return null;
}
}
Java泛型方法
Java中泛型类的定义非常简单,但泛型方法就比较复杂了。
静态方法尤其适合泛型化,Collections中的所有"算法"例如(binarySearch和sort)都泛型化了。
⭐️泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
//泛型方法示例
public static <T> void get(T t)
//注意< T > 是写在返回类型的前面哦,并且public 与 返回值中间非常重要
//可以理解为声明此方法为泛型方法。
//只有声明了的方法才是泛型方法,
一个泛型方法
public static <T> void get(T t){
System.out.println(t.getClass().getName());
}
使用泛型方法:
get("123");
get(123);
get(1.0);
get('c');
结果

注意事项
public class A<T> {
private T key;
public static <T> void get(T t){
System.out.println(t.getClass().getName());
}
一个泛型类中,虽然一个方法使用了泛型,但它不一定是泛型方法
public T getKey(){//这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类已经声明过的泛型。
return key;
}
这个方法显然是有问题的,在编译器会给我们提示这样的错误信息"cannot reslove symbol E"
因为在类的声明中并未声明泛型E(public<E> E),所以在使用E做形参和返回值类型时,编译器会无法识别。
public E setKey(E key){
this.key = key;
}
这也不是一个泛型方法,因为'E'没有声明,编译器不知道这个类型
public <T> T showKey(A<E> key){
……
}
值得注意的是,这里的 E 是泛型方法中声明的一个类型,这种E可以是任意类型,
可以与类类型相同也可以不同
由于泛型方法在声明的时候会声明泛型<E>,因此即使在泛型类中并未声明泛型,
编译器也能够正确识别泛型方法中识别的泛型。
public static <E> void get(E e){
System.out.println(e.getClass().getName());
}
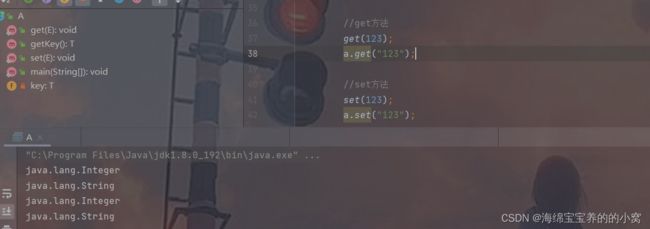
A<String>a = new A<>();
//get方法,都可通过并且运行成功
get(123);
a.get("123");
这里的E也可与类类型相同也可不同
public static <E> void set(E e){
System.out.println(e.getClass().getName());
}
A<String>a = new A<>();
//set方法
set(123);
a.set("123");
}
运行结果
Java泛型通配符
泛型的通配符非常重要,在泛型方法和泛型类中使用颇多。
⭐️类型通配符一般是使用?代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参 。
⭐️再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
当我们创建了三个类后:
class Fruit {
public String whatIs() {
return "Fruit";
}
}
class Apple extends Fruit {
@Override
public String whatIs() {
return "Apple";
}
}
class Orange extends Fruit {
@Override
public String whatIs() {
return "Orange";
}
}
public class Test {
public static void main(String[] args) {
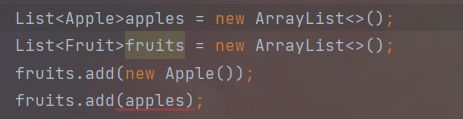
List<Apple>apples = new ArrayList<>();
//Listfruits = apples;//编译错误
Apple[] arrayApples = new Apple[10];
Fruit[] arrayFruits = arrayApples;
arrayFruits[0] = new Orange();//运行错误
}
}
我们先声明了一个Apple的List apples,然后我们准备将apples赋值给一个Fruit的List fruits。但是编译器不让,给出一个报错。这是为什么呢?
⭐️
因为参数化类型是不可变的(invariant)。换句话说,对于任何两个截然不同的类型Type1和Type2而言。List< Type >既不是List< Type2 >的子类型,也不是它的超类型。虽然List< String >
不是List< Object >的子类型,这与直觉相悖。但是实际上很有意义,你可以将任意对象放入List< Object > 中,却只能将字符串放进List< String >中。例子中fruit就只能将fruit的子类对象放入List< fruit >。
作为对比,我们拿一个在Java中和List非常相近的数据结构-array做了同样的操作,一个apple的数组赋值给一个fruit的数组完全没有问题。

其实直观上来讲也很合理,一堆苹果不也就是一堆水果嘛,将其赋于一个更大的概念没什么错。
而橘子不也是水果嘛,那么加入fruit中也没错。
⭐️你也可能会认为这意味着泛型是有缺陷的,但恰恰相反,实际上数组才是有缺陷的。
这句代码看起来也没什么问题。但是运行一下呢?报错了 。

现在知道为什么List不让将一个Apple的List赋值给一个Fruit的List了吧,因为它怕你往里面放橘子。并且比数组更糟糕的是,由于类型擦除的原因,它根本就不知道它里面应该放点什么。用数组的时候,往arrayApples里面放个Orange,系统还会报个异常出来。如果是往apple的List里面放个orange,系统可是不会报异常的哦。所以为了杜绝这种情况的发生。泛型干脆就不让这样相互赋值。
⭐️其实数组和泛型都不能将Apple加入Fruit中,但是利用数组,你会在运行时才发现错误,而泛型,你会在编译时就发现错误。我们当然是希望在编译时发现错误啦。
⭐️但是再怎么不允许,也总归要考虑到实际情况嘛,总有那么一两次,有些情况下就是要将一个小的概念赋值给一个大的概念啊 。而Java也是考虑到了这种情况:
上界通配符
public class Test {
public static void main(String[] args) {
List<Apple>apples = new ArrayList<>();
Apple apple = new Apple();
apples.add(apple);
List<? extends Fruit> fruits = apples;
Fruit fruit = fruits.get(0);
//fruits.add(new Apple());//编译报错
//fruits.add(new Orange());//编译报错
System.out.println(fruit);
System.out.println(fruits.contains(apple));
System.out.println(fruits.indexOf(new Orange()));
}
}
⭐️我们使用 List fruits = apples,称为泛型的上边界,即所有的fruit的子类都可以往里放。
但是我们发现当fruit使用add方法时,编译出错了:
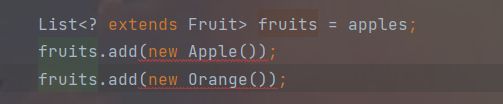
不能往fruit里面放东西了!!!
为啥呢?
⭐️联想一下上面数组的例子你心里还能没点数么。刚刚就是因为往apples里面放了不该放的东西导致错误。这次List能再这种赋值的情况下,阻止往fruits里面加东西也纯属正常,因为你根本就不知道当初付给fruits的List具体是什么,也许是apples,也许是oranges,还也许是watermelon呢。
⭐️既然运行的时候Java已经不知道你往里面放什么是安全的了,那干脆就不让你往里面add了。那是fruits所有的方法都不能调了嘛?并是,get,contains,indexOf三个方法调起来确实没什么问题啊。

那是编译期能检测到我们那个方法是要修改存储内容的?然后把这部分方法屏蔽掉了不让用?其实并不是,我们来看下ArrayList的源码是怎么写着四个方法的:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
我们可以清除的看到add方法时 E类型的,其他三个是object或其他类型的,当一个泛型的参数类型被声明为? extends Fruit以后,他对应所有使用到参数类型的方法的参数也都会变成? extends Fruit, 这个时候add方法也表示很无奈啊,你只说了是Fruit的一个子类型,我怎么知道具体应该是哪个类型啊?所以就直接会编译失败。

从这里我们可以得出来一个结论。 如果不想让声明为上界通配符的类执行的方法,大可以将其参数设置成为参数类型E,但是如果想被执行的方法,参数类型就要是Object类型的了 。
下界通配符
还是以上面的代码,再添加一个Apple的子类redApple。
class redApple extends Apple {
@Override
public String whatIs() {
return "redApple";
}
}
List<Fruit> fruits = new ArrayList<Fruit>();
List<? super Apple> appleSupers=fruits;
System.out.println(appleSupers.add(new redApple()));
Object object = appleSupers.get(0);
System.out.println(object);
? super Apple表示一个Apple的父类(具体是哪种不知道,只要是他的父类就OK),也就是说,add的方法对象类型是? super Apple,代表List持有的对象最少是Apple类型的,那我们向其中添加一个Apple的子类,是不会破坏List持有对象的原则的。但要注意不能是Apple子类的子类。接着我们往外取数据,啊哦!又出事了,我们从List里面拿出来的东西变成了Object类型的啦。
为啥?因为我们刚看了get的返回值是E类型的,对应到appleSupers对象上,就是? super Apple类型的。具体类型它也不太清楚,反正就是大于Apple的类型。那Java就只能把他当其左边界Object来处理啦!
总结:上界不能往里存,只能往外取,下界不影响往里存,但往外取只能放在Object对象里。
再举个 带大家感受下:
class A<Number>{
private T object;//object只是一个名称,可以随便取啥,类型由外部类型决定
public T getObject() {
return object;
}
public A(T object) {//泛型构造方法
this.object = object;
}
}
public void showKeyValue1(A <? extends Number> obj){
sout("泛型测试","key value is " + obj.getKey());
}
A<String> A1 = new A<String>("11111");
A<Integer> A2 = new A<Integer>(2222);
A<Float> A3 = new A<Float>(2.4f);
A<Double> A4 = new A<Double>(2.56);
//这一行代码编译器会提示错误,因为String类型并不是Number类型的子类
//showKeyValue1(A1);
showKeyValue1(A2);
showKeyValue1(A3);
showKeyValue1(A4);
如果我们把泛型类的定义也改一下:
public class A<T extends Number>{
private T key;
public A(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}
//那么这一行代码也会报错,因为String不是Number的子类
A<String> A1 = new A<String>("11111");
无界通配符
无界通配符集合了上界下界通配符的优点,同时他们的缺点也几种到了一起。不论什么样参数类型的泛型类都可以付给带有无界通配符的泛型类(上下界通配符的优点)。但是!赋值就赋值了,你可千万别想再通过它调用泛型类中参数值是泛型参数的方法(上界通配符的缺点),也别想从它这里拿到某个具体类型了,所有以参数类型为返回值的方法都将返回Object(下界通配符的缺点)。下面还是以一个例子为例:
List<Fruit> fruits = new ArrayList<Fruit>();
List<?> appleSupers=fruits;
//appleSupers.add(new redApple());//编译报错
Object object = appleSupers.get(0);

Java泛型总结
⭐️Java的泛型是由类型擦除机制实现的,其实它就只工作在程序的编译期间,保证编译期间类型检查正确,以及再生成字节码的时候自动加上类型转换的逻辑。
结语
⭐️如果本文对你有帮助的话,请不要吝啬一个小小的三连哦(点赞、收藏、评论).