splunk 日志分析软件 简介
目录
Splunk总体介绍
简介
Splunk是什么
Splunk做什么
Splunk如何做
应用场景
日志管理
为机器数据建立索引
搜索、关联、调查
钻取分析
监控&告警
报表和仪表盘
IT运维监控
IT运维监控视图
丰富的App和插件
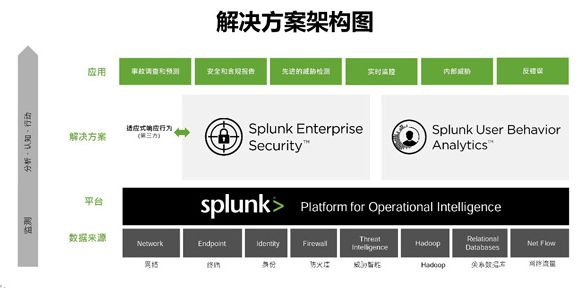
安全和欺诈
安全神经中心
安全挑战
高级威胁检测
内部威胁
合规
欺诈与盗窃
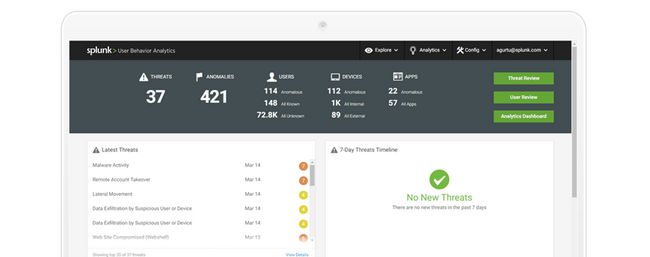
用户行为分析
数据从哪儿来
数据源类型
文件和目录
网络事件
Windows数据源
其他数据源
数据提取
数据如何分析
强大的SPL语言
可视化及报告
可视化的类型
表格
图表
单值卡片
仪表
地图
数据钻取
钻取的动作类型
钻取的行为
编辑钻取
共享
Splunk App体系
Splunk App应用
Splunk Add-on附加组件
Splunk二次开发
Splunk Web 框架
各种开发方式对比
Splunk机器学习
介绍
机器学习和分析命令
示例展示
助手
扩展的 SPL 命令
算法
分类算法
回归算法
特征提取Feature Extraction
异常检测Anomaly Detectors
聚类算法Clustering Algorithms
预处理Preprocessing
时间序列分析Time Series Analysis
工具算法Utility Algorithms
示例展示
预测数值字段
预测分类字段
检测数字异常值
检测分类异常值
时间序列预测分析
对数据类事件进行聚簇
性能
查询类型如何影响性能
Splunk部署
支持的操作系统
Unix/Linux类
Windows类
支持的浏览器
硬件建议
中小规模数据环境
大规模的数据环境和分布式部署
Splunk容量规划
磁盘容量
Splunk案例
GE通用
基本信息
用户场景
Splunk产品版本对比
Splunk许可模式
Splunk总体介绍
简介
Splunk 是一款顶级的日志分析软件,如果你经常用 grep、awk、sed、sort、uniq、tail、head 来分析日志,那么你需要 Splunk。能处理常规的日志格式,比如 apache、squid、系统日志、mail.log 这些。对所有日志先进行 index,然后可以交叉查询,支持复杂的查询语句。然后通过直观的方式表现出来。日志可以通过文件方式传倒 Splunk 服务器,也可以通过网络实时传输过去。或者是分布式的日志收集。总之支持多种日志收集方法。
这个软件分为免费版本和专业版本。
Splunk是什么
Splunk是一个分析计算机系统产生的机器数据,并在广泛的场景中提供数据收集、分析、可视化分布式的数据计算平台。
- Splunk 是一个数据引擎。
- 针对所有IT系统和基础设施数据, 提供数据搜索、报表和可视化展现。
- Splunk是软件 – 5分钟就可以下载和安装。
- 可以运行在各种主流的操作系统平台。
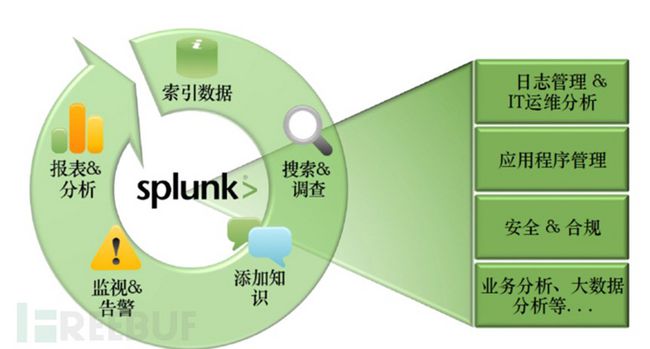
Splunk做什么
Splunk如何做
应用场景
日志管理
为机器数据建立索引
建立索引并存储任意机器数据,无论格式或位置-网络和端点安全日志、恶意软件分析信息、配置、传感器数据、网络上的在线数据、更改事件、API 数据和消息队列,甚至自定义应用程序中的多行日志。不需要预定义方案,几乎可对任何来源、格式或位置的数据建立索引。
搜索、关联、调查
具有专利的Splunk 搜索处理语言 (SPL™) ,直观且功能强大。自动将您的各类数据格式,提供 140 多种命令,可以统计搜索、计算指标、甚至在滚动时间窗内查找特定条件。放大和缩小的时间线以自动揭示趋势、峰值和蕴含的模式,并且可以以钻取深入细节。
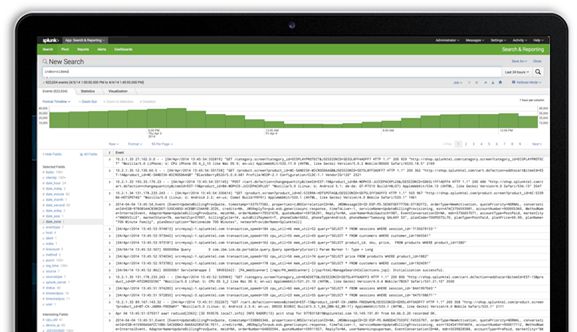
钻取分析
通过使用即时搜索和时间线控制深入分析前后的所有数据,快速显示趋势峰值和异常。只需轻点鼠标,就可利用 Splunk 的独特字段提取功能找到任何数据字段内的任何值,以跟踪事件序列和快速实现"大海捞针"。无论是否正在调查一个安全警报,分析业务中断的根源,或调查潜在数据泄露,都会在几秒钟到几分钟而不是几小时或几天内得到答案。
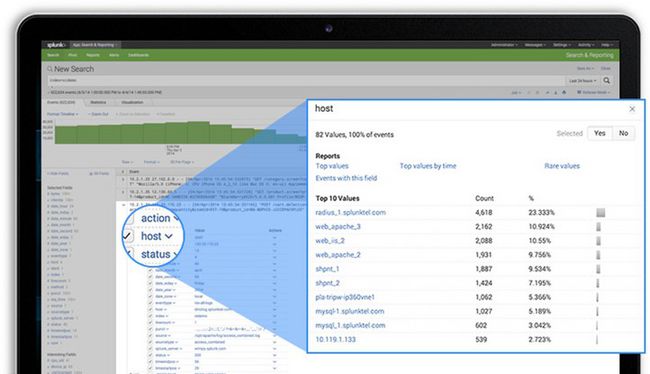
监控&告警
将搜索转化为实时告警,通过电子邮件或 RSS 自动触发通知,执行修复操作,向系统管理控制台发送 SNMP 陷阱或在服务台生成故障票据。告警可基于各种阈值、基于趋势的条件和其他复杂标准而触发。在出现告警时获得其他信息,协助运维人员更快进行根本原因分析并找到问题的解决方案。

报表和仪表盘
使用同一界面搜索实时和历史数据。使用熟悉的搜索命令来定义、限制或扩大搜索范围,并跨越多种数据源进行关联以发现新的现象。关联基于时间的数据、外部数据、位置、子搜索或连接跨越多种数据源。搜索帮助提供键入提示建议和上下文帮助,方便使用搜索处理语言 (SPL™) 的所有高级特性。
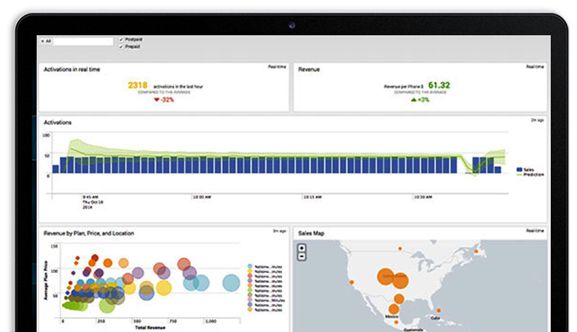
IT运维监控
IT运维监控视图
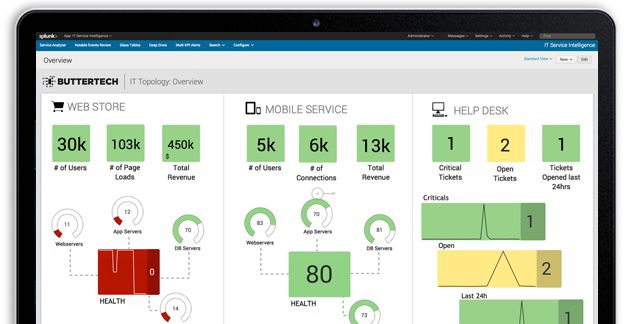
丰富的App和插件
Splunk提供了丰富的开箱即用的App和插件(Splunk可以看做是一个安卓生态),从业务层到IT层全面监控。Splunk积累了1000多个不同场景的App和插件,涵盖了主流的IT软硬件厂商,能够可视化、采集数据,大部分情况下,从Splunk市场下载App即可满足多种多样的需求。
并且提供了方便的界面,能够让使用者可以自己创建新的App和插件。
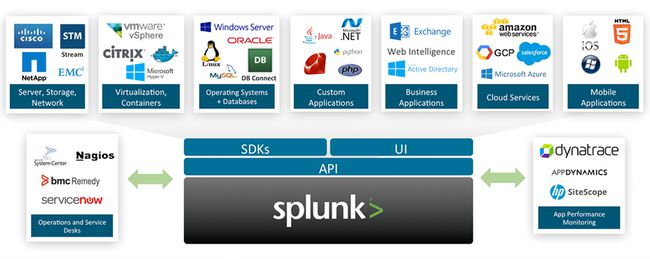
安全和欺诈
安全神经中心
Splunk 整合多个 IT 领域,以启用协作并实施最佳实践,以与数据交互并调用操作,从而应对现代网络威胁挑战。鉴于 Splunk 用作神经中心,团队可以优化人员、流程和技术。安全团队可以利用数据统计、可视化、行为和探索分析,从而有助于见解、决策和运营。

安全挑战
-
高级威胁检测
使用任何时间段内任何数据的任何字段查找关系,继而跟踪杀伤链的各个阶段。
-
内部威胁
使用 Splunk,以在偷盗、滥用或损坏机密数据前检测恶意员工和其他内部威胁。
-
合规性
提供更高水平的自动化,并连续监测合规性和监管规定。
-
欺诈与盗窃行为
通过实时或历史数据搜索和生成数据透视表,以研究和检测欺诈或盗窃行为并查明滥用行为。
-
用户行为分析
通过利用数据科学和机器学习的解决方案,检测网络攻击和内部威胁。
-
适应响应倡议
由Splunk 引导的适应响应方案会连接最佳安全供应商社区,以改善网络检测战略。
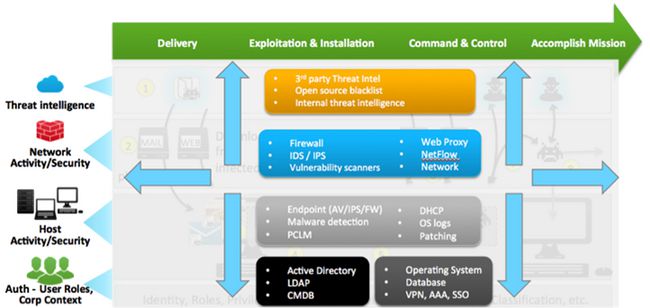
高级威胁检测
杀伤链方法论
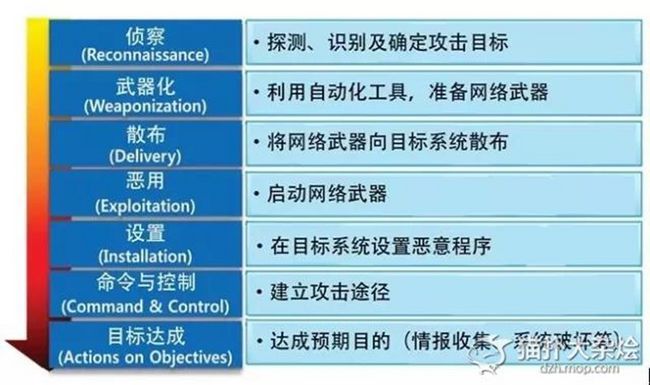
图.杀伤链方法论
网络杀伤链由攻击流程与防御概念构成。如图1所示,攻击流程分为侦察、武器化、散布、恶用、设置、命令与控制、目标达成等七个阶段3。
-
侦察阶段。侦察阶段是攻击者为达成目标,进行探测、识别及确定攻击对象(目标)的过程。在这个阶段,可通过网络收集企业/机关网站、报道资料、招标公告、职员的社会关系网(socialmedia networks)、学会成员目录等各种与目标相关的情报。
-
武器化阶段。武器化阶段是指通过侦察阶段确定目标后,准备网络武器的阶段。网络武器可由攻击者直接制造,也可利用自动化工具来制造。
-
散布阶段。散布阶段是指将制造完成的网络武器向目标散布的阶段。据洛克希德·马丁公司网络安全保障小组称,自2004年至2010年间,使用最为频繁的散布手段有邮件附件、网站、USB(Universal Serial Bus)等。
-
恶用阶段。恶用阶段是指网络武器散布到目标系统后,启动恶意代码的阶段。在大部分的情况下,往往会利用应用程序或操作系统的漏洞及缺陷。
-
设置阶段。设置阶段是指攻击者在目标系统设置特洛伊木马、后门等,一定期限内在目标系统营造活动环境的阶段。
-
命令与控制阶段。这一阶段是指攻击者建立目标系统攻击路径的阶段。在大部分情况下,智能型网络攻击并非是单纯的自动攻击,而是在攻击者的直接参与下实施的。一旦攻击路径确立后,攻击者将能够自由接近目标系统。
-
目标达成阶段。这一阶段是指攻击者达到预期目标的阶段。攻击目标呈现多样化,具体来讲有侦察、敏感情报收集、破坏数据的完整性4、摧毁系统等。
通过筛查与杀伤链的不同阶段关联的恶意软件分析解决方案、电子邮件和网络解决方案的日志,Splunk 软件能帮您发现遭入侵系统的指标和隐藏在您机器数据中的重要关系。
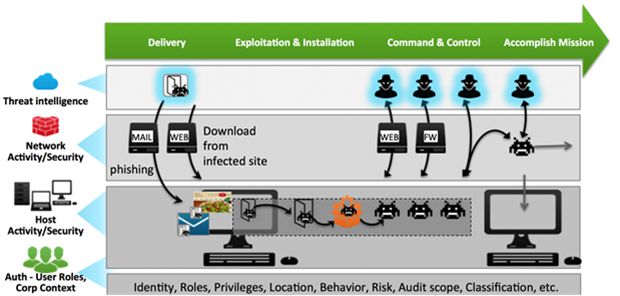
确定影响和范围
通过使用任意字段值将事件链接在一起以重新构建攻击序列来发现跨不同安全技术的相关事件,包括威胁情报、网络安全(例如电子邮件和网关)、防火墙、终端安全和终端威胁检测和响应解决方案。
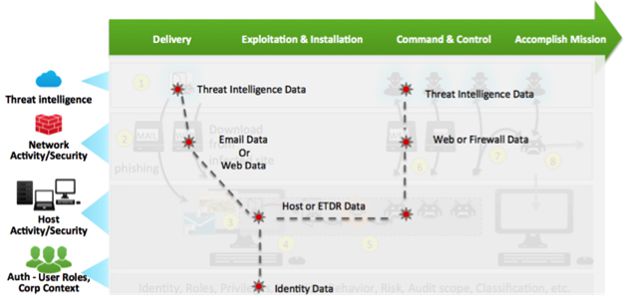
端到端的可视化
Splunk 软件允许不同的安全团队协作、应对和防御高级威胁。团队可以向上、向下和在其中查看安全和 IT 技术栈,以及回顾过去来发现、分析和应对与遭入侵主机和高级威胁相关的活动。团队成员可以在任何活动或条件上快速创建实时关联搜索,这样可将情报整合回系统以进行持续监测。
内部威胁
内部威胁来自现有或以前的员工,承包商或有权访问公司网络的合作伙伴,故意或意外渗透,误用或破坏敏感数据。 由于这些内部人员已经在组织内部,所以他们经常使用合法凭据和权限来访问和下载敏感资料,从而避开传统安全产品的检测。
Splunk可以帮助您以下列方式检测并击败内部威胁:
- 当用户操作或模式被认为是内部人员不适当地获取敏感数据或通过网络或端点进行渗透时报警。
- 当异常值偏离正常行为的基准时的警报,因为这些异常值可能是内部威胁
- 一旦明确确定内部威胁,就启动自动缓解补充其他安全技术,
- 为其他的安全解决方案提供补充,以对用户内部行为的全面了解,或可能被内部人员规避
- 通过搜索数周或数月的历史事件数据快速调查内部人员活动,以快速确定用户行为的范围,意图和严重性
- 通过利用数据科学和机器学习的现成的用户行为分析解决方案来检测网络攻击
合规
将其作为单一平台来自动遵循广泛的政府和工业规范、管理框架和内部要求,包括 PCI、HIPAA、FISMA、GLBA、NERC、SOX、EU Data Directive、ISO、COBIT 和 20 个关键的安全控制。 Splunk 能让客户创建关联规则和报告来确定对于敏感数据或关键雇员的威胁,并自动展示合规性或确定关于技术控制的非合规区域。
- 遵循 SIEM 或集中式收集/日志、持续监控和保留安全事件的要求
- 快速搜索过去几天、几周或几个月的大量的安全事件和机器数据以加快事件调查或满足审计师的特殊要求
- 创建报告和仪表板来显示遵循任何所需技术控制的状态
- 通过关联规则、异常检测或风险评分启用实时、已知和未知威胁检测
欺诈与盗窃
欺诈、盗窃和滥用的检测和防御是对于大数据的挑战,尤其是业务移入在线领域时。内部或外部的欺诈模式经常依赖于大量的由业务应用和系统产生的非结构化机器数据和日志文件。
Splunk® 软件允许组织核查这种机器数据来满足广泛的反欺诈、反盗窃和反滥用的团队需要,包括:
- 欺诈检测 - 在欺诈发生的时候,实时关联搜索或异常检测能确定欺诈并告警,这样在达到不利影响的最低限度前,组织可以采取行动以防止欺诈
- 欺诈调查 - 快速搜索和透视大量的当前或历史计算机数据来研究可能的欺诈和了解可能的欺诈行为的"主体、内容、位置、何时间以及方式"
- 欺诈分析和报告 - 轻易进行对于广泛的内部用户的欺诈风险的分析、测量和管理
- 增强现有的反欺诈工具 - 对于来自独立工具的事件数据进行索引来为单个交易创建汇总的欺诈评分
- 创建综合的报告和仪表板来在单一虚拟管理平台上查看企业范围的欺诈风险
用户行为分析
Splunk 用户行为分析 (UBA) 是一种以机器学习为支持的解决方案,提供您需要的答案,以查找用户、端点设备和应用程序的未知威胁和异常行为。它不仅关注外部攻击,而且侧重于内部威胁。它的机器学习算法产生具有风险评级的可操作结果,并提供证据表明增强安全运营中心 (SOC) 分析师现有技术以加快行动。此外,它为安全分析师和威胁寻找员提供视觉枢纽点,以便主动调查异常行为。
Splunk 用户行为分析软件:
- 使用以行为为中心的专用和可配置的机器学习框架,利用无监督的算法来增强检测足迹
- 通过将数百个异常自动拼接为单一威胁,增强 SOC 分析师用户和实体行为分析 (UEBA) 功能
- 通过在攻击的多个阶段可视化威胁来提供增强的上下文
- 支持与 Splunk Enterprise 进行双向集成,以进行数据采集和关联,并使用 Splunk 企业安全 (ES) 进行事件范围界定、调查和自动响应
用户行为分析的主要功能
- 大数据基础(Hadoop、Spark 和 GraphDB)
使用大数据基础构建,Splunk UBA 可水平扩展,每天处理数十亿事件,并支持分析数十万个组织实体。
- 无人监督的机器学习
专门构建的无人监督的机器学习算法产生较少的误报提供广泛的覆盖并产生高度可信的结果,这有助于事件响应和寻找威胁。
- 多维行为基线
历史和实时数据有助于创建行为基线,例如,概率后缀树、计数多个时间序列和更多 - 这有助于识别异常值并提供组织度量的可见性。
- 自定义威胁生成
定制底层机器学习框架,以拼接感兴趣的异常,并通过细粒度控制来解决定制用例。
- 用户监控和观察列表
使用自定义小部件或即时观察列表监视用户及其活动,以便快速方便地访问。
- 异常抑制与评分
通过应用自定义分数确定检测到的异常的优先级,并抑制触发的异常,以获得更高的保真度威胁。
- Splunk Enterprise 和 Splunk 企业安全的双向整合
与 Splunk Enterprise 无缝集成以进行数据采集,将异常和威胁实时传输到 Splunk 企业安全,通过高保真警报帮助组织获得对其安全状态的视觉洞察并自动响应。
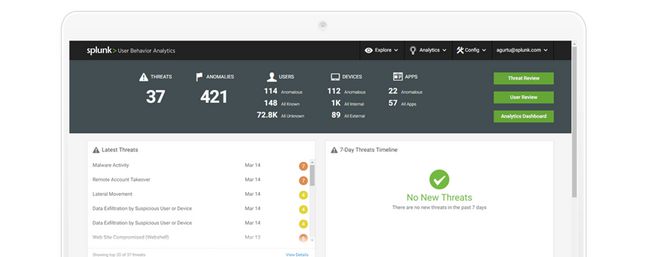
安全仪表板
安全仪表板可在组织中找到高级别摘要可视化威胁和异常以及异常用户、设备和应用程序的统计信息。






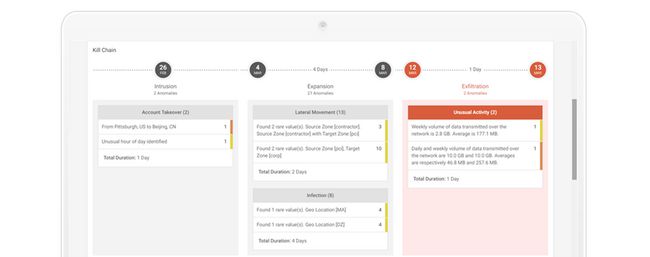
杀伤链视图
杀伤链视图通过攻击持续时间、涉及的实体、在杀伤链的入侵阶段、扩展阶段和渗透阶段观察到的异常分类等细节,对攻击进行可视化探索。
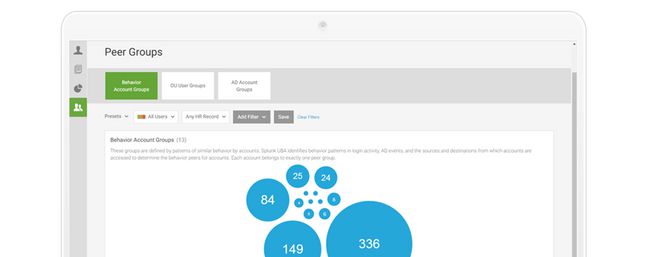
对等组
对等组分析可视化使用行为分析计算的动态对等组视图、Active Directory 和组织结构突出显示类似的用户和异常值。
开箱即用的分析
开箱即用的分析可显示跨多个实体计算的聚合和基线的仪表板,并可显示实体级别的详细细目。
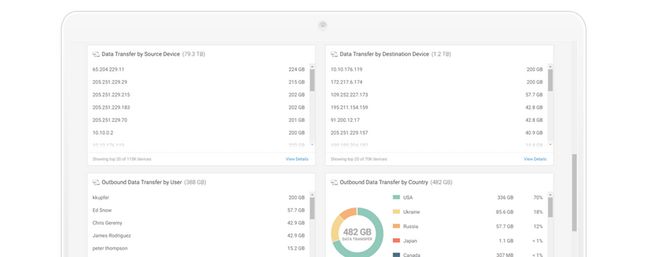
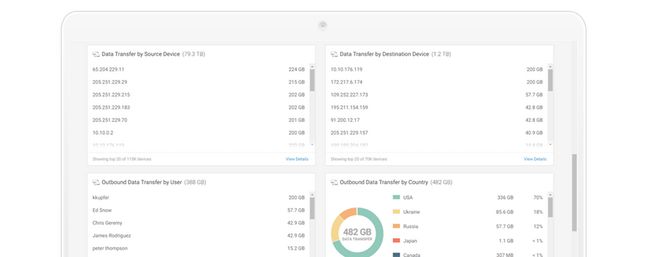
用户风险评分和监控
用户风险评分和监控监控用户并通过多个风险评分(如内部风险百分比、外部风险百分比、异常数量、威胁数量)和整体用户评分进行过滤。
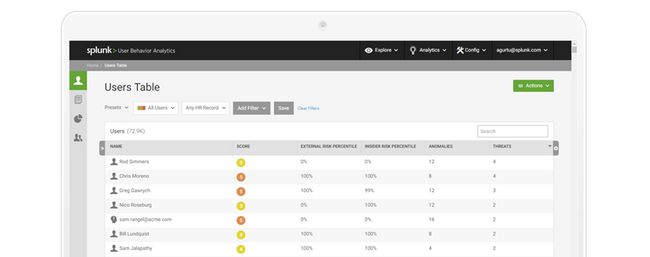
异常类别
异常类别超过 45 个异常类别可以开箱即用 - 包括异常网络活动、可疑数据移动、异常活动时间等 - 每个都可以自定义得分优先级,并抑制有效的狩猎和威胁生成。所有异常均通过机器学习算法触发。
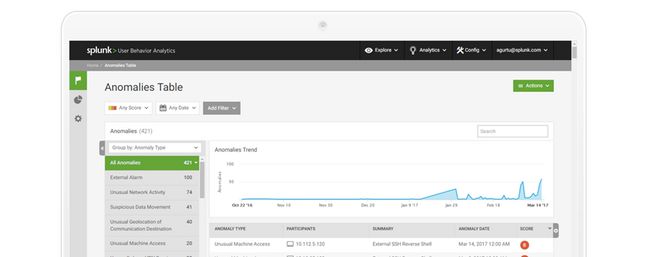
威胁类别
类别威胁超过 20 种威胁类别可以开箱即用 - 包括数据泄露、横向移动、受影响帐户、可疑行为和其他 - 可以自定义得分优先级。客户可以通过指导机器学习框架应拼接哪些异常以及如何拼接来编写自己的用例(威胁)所有威胁均通过机器学习算法触发。
集成事件可视化
集成事件可视化通过 UBA 资产和身份协会观察 ES 中的威胁行为者的活动,查看 UBA 产生的异常和威胁以及资产调查员中的其他 Swimlane 指标, 参考具有额外详细信息的专用 UBA 仪表板。
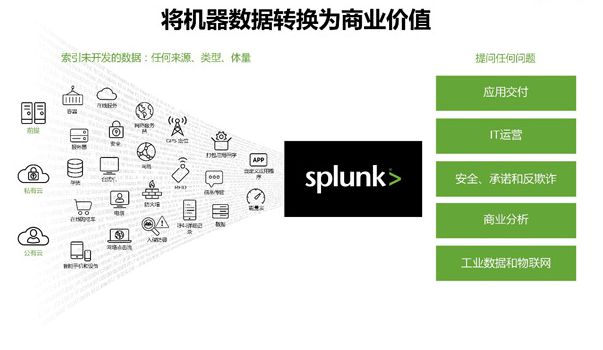
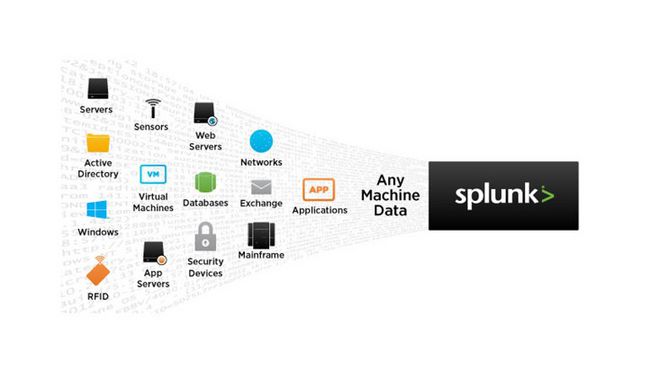
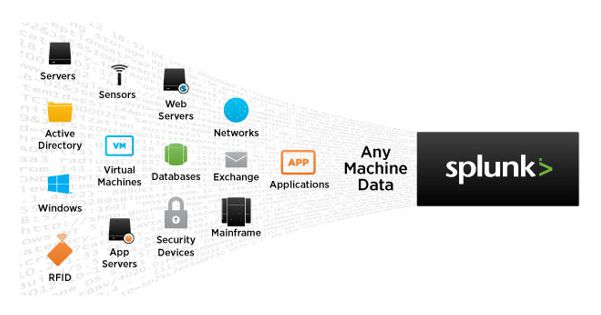
数据从哪儿来
Splunk索引数据不考虑格式或位置 — 日志、点击流、传感器、网络流量、网页服务器、客户应用、管理程序、社交媒体以及云服务。由于该结构和方案仅适用于搜索时间,可以不受限制地分析数据。
数据示例
| 数据类型 |
位置 |
它可以告诉您什么 |
| 应用日志 |
本地日志文件、log4j、log4net、Weblogic、WebSphere、JBoss、.NET、PHP |
用户活动、欺诈检测、应用性能 |
| 业务流程日志 |
业务流程管理日志 |
跨渠道客户活动、购买、帐户变更以及问题报表 |
| 呼叫详细信息记录 |
呼叫详细信息记录 (CDR)、计费数据记录、事件数据记录均由电信和网络交换机所记录。 |
计费、收入保证、客户保证、合作伙伴结算,营销智能 |
| 点击流数据 |
Web 服务器、路由器、代理服务器和广告服务器 |
可用性分析、数字市场营销和一般调查 |
| 配置文件 |
系统配置文件 |
如何设置基础设施、调试故障、后门攻击、"定时炸弹"病毒 |
| 数据库审计日志 |
数据库日志文件、审计表 |
如何根据时间修改数据库数据以及如何确定修改人 |
| 文件系统审计日志 |
敏感数据存储在共享文件系统中 |
监测并审计敏感数据读取权限 |
| 管理并记录 API |
通过 OPSEC Log Export API (OPSEC LEA) 和其他 VMware 和 Citrix 供应商特定 API 的 Checkpoint 防火墙 |
管理数据和日志事件 |
| 消息队列 |
JMS、RabbitMQ 和 AquaLogic |
调试复杂应用中的问题,并作为记录应用架构基础 |
| 操作系统度量、状态和诊断命令 |
通过命令行实用程序(例如 Unix 和 Linux 上的 ps 与 iostat 以及 Windows 上的性能监视器)显示的 CPU、内存利用率和状态信息 |
故障排除、分析趋势以发现潜在问题并调查安全事件 |
| 数据包/流量数据 |
tcpdump 和 tcpflow 可生成 pcap 或流量数据以及其他有用的数据包级和会话级信息 |
性能降级、超时、瓶颈或可疑活动可表明网络被入侵或者受到远程攻击 |
| SCADA 数据 |
监视控制与数据采集 (SCADA) |
识别 SCADA 基础结构中的趋势、模式和异常情况,并用于实现客户价值 |
| 传感器数据 |
传感器设备可以根据监测环境条件生成数据,例如气温、声音、压力、功率以及水位 |
水位监测、机器健康状态监测和智能家居监测 |
| Syslog |
路由器、交换机和网络设备上的 Syslog |
故障排除、分析、安全审计 |
| Web 访问日志 |
Web 访问日志会报告 Web 服务器处理的每个请求 |
Web 市场营销分析报表 |
| Web 代理日志 |
Web 代理记录用户通过代理发出的每个 Web 请求 |
监测并调查服务条款以及数据泄露事件 |
| Windows 事件 |
Windows 应用、安全和系统事件日志 |
使用业务关键应用、安全信息和使用模式检测问题。 |
| 线上数据 |
DNS 查找和记录,协议级信息,包括标头、内容以及流记录 |
主动监测应用性能和可用性、最终客户体验、事件调查、网络、威胁检测、监控和合规性 |
数据源类型
-
文件和目录Files and directories
-
网络事件Network events
-
Windows数据源Windows sources
-
其他数据源Other sources
文件和目录
很多数据是直接从文件和目录中提取的。可以使用 文件和目录监视器 来从文件和目录中提取数据。
参照 从文件和目录中获取数据。
网络事件
Splunk可以索引从网络端口收到的数据,例如从TCP端口收到的syslog-ng或者应用程序发来的数据。同样,UDP也是可以的,但是如果可能的话,尽量使用TCP协议。
Splunk也可以接收和索引远程设备的SNMP事件。
从网络端口接收数据参照 从TCP和UDP端口接收数据。
接收SNMP数据参照 发送SNMP事件到Splunk。
Windows数据源
Splunk Enterprise Windows版可以收集不同种类的Windows数据:
-
Windows 事件日志数据
-
Windows 注册表数据Registry data
-
WMI数据
-
Active Directory活动目录数据
-
Performance 性能监视器数据
在非Windows版本的Splunk上索引和搜索Windows数据,必须使用Windows版的Splunk收集数据。参考 如何监控远程Windows数据的考虑要点。更详细的参考 监视 Windows数据 。
其他数据源
Splunk也支持其他类型的数据源,例如:
-
性能度量
从基础设施、安全系统和应用系统获取性能度量信息。Get metrics data from from your technology infrastructure, security systems, and business applications.
-
先入先出 (FIFO) 队列
-
脚本输入
-
从API、其他远程数据结构和消息队列获取数据.
-
模块化输入
在Splunk框架上自定义一个输入采集.
-
Http事件收集器
Http事件收集器,使用Http或者https协议从数据源收集数据。
数据提取
待续。。。
数据如何分析
强大的SPL语言
SPL是Splunk Search Language的简称,是Splunk的专利分析语言,但不仅仅是一种搜索语言,是非关系数据分析的事实标准。SPL 提供 140 多种命令,可让搜索、关联、分析和可视化任何数据 — 一种可在 5 个重要领域概括的强大语言。

待续。。。
可视化及报告
在针对任意业务、运营和安全需求的自定义仪表板和报表中查看趋势和特性。使用图表叠加、平移和缩放控制深入分析。预测性可视化允许您预测高点和低点,计划系统资源并预测工作量。也可以为任意人员自定义仪表板和报表,以 PDF 形式分享或将其嵌入其他应用中。
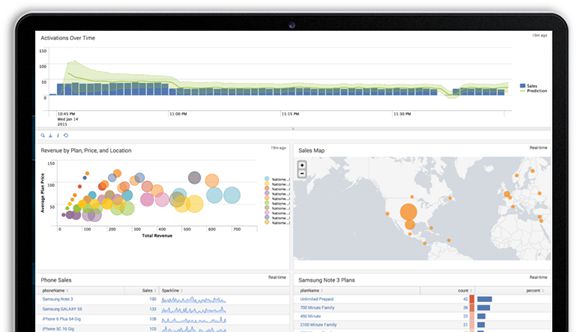
可视化的类型
表格
图表
| 图表类型 |
说明 |
| 饼图
|
单个维度 |
| 柱状图
|
表示数据集中的一个或者多个维度。每一组数据代表了一种值。 |
| 线图和区域图
|
线图用来展示在数据在时间上的变化趋势 区域图展示统计数据在时间上的变化趋势 |
| 散点和气泡图
|
表示数据集中的多个维度。数据点的大小、分布情况表达了模式和关系。 |





单值卡片
单值看片用来重点显示一条数据,以及围绕着此数据的相关数据。单值可以是任何想要呈现的数据,例如受欢迎的柠檬水的销售情况。

上图中显示了货币单位和通过颜色强调数据,右上角的箭头显示了变化趋势(当前是增长)。下边的曲线显示了随着时间数据的变化趋势。
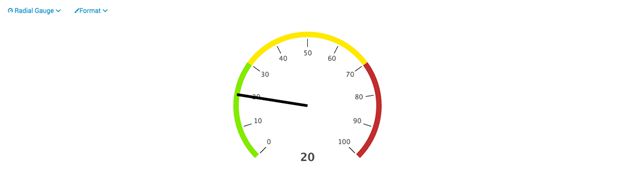
仪表
使用仪表可以显示数据的变化范围以及当前数据所在的位置,有圆形仪表、空白仪表、标记仪表三种。
圆形仪表
空白仪表
标记仪表
标记仪表使用颜色来标记不同的数据范围段。
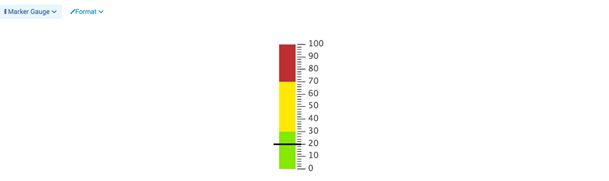
地图
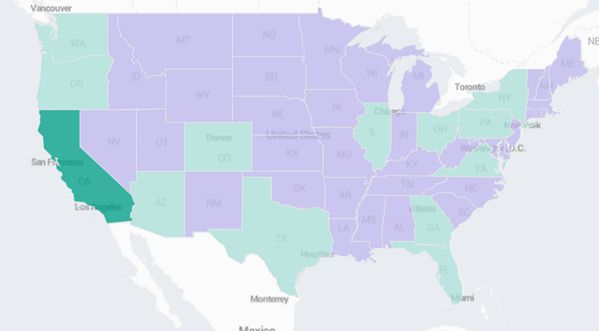
地图用来在地理维度上展现数据,有地区分布图和
地区分布图
地区分布图通过颜色在地图的区域上显示不同的数据,例如通过颜色来表示各个区域的销量情况。
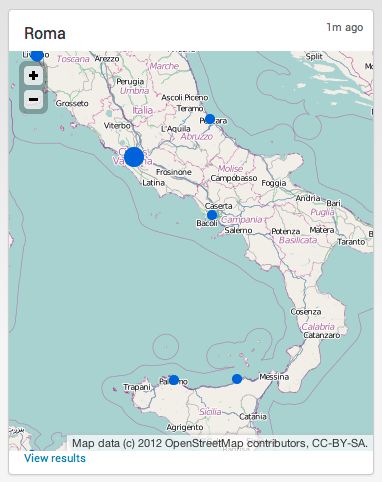
城市群地图
城市群地图,在像百度地图这样的图形上,显示不同的地域的数据情况,例如不同城市的销量情况,用圆圈的大小表示销量。
数据钻取
当使用者在Dashboard上用户的点击数据点、表格行或单元,或者其他可视化元素的某些位置,有时候需要根据点击的内容深入下去,从宏观到细节。此时就需要钻取这种交互的方式。
每一个可视化都可以配置单独的数据钻取,
钻取的动作类型
链接到一个目标位置
Dashboard或表单的点击或者其他行为链接到外部目标。 外部目标可以是一个二次搜索,另一个Dashbaord或表单或网站。
在当前的Dashboard中触发交互
钻取还可以在同一个仪表板或表单中触发上下文更改。 例如,您可以根据点击的值显示或隐藏内容。
钻取的行为
| 动作 |
类型 |
行为和配置 |
| 链接到一个搜索 |
链接到一个目标位置 |
在浏览器中打开一个搜索页面,辅助搜索会自动根据点击的数据展现搜索结果。而且也可以自定义搜索。 |
| 链接到另一个Dashboard或表单 |
链接到一个目标位置 |
在浏览器中打开目标Dashboard或者表单。使用Token传递变量,根据Token中传递的变量值显示内容。 |
| 链接到一个 URL |
链接到一个目标位置 |
在浏览器中打开一个新的外部页面,在URL中附加Token中的值作为参数。 |
| 在当前的Dashboard或表单中管理Token值 |
在当前的Dashboard中触发交互 |
当用户在Dashboard或表单中点击的时候,根据点击的值设置、取消设置、或者过滤内容。 与链接到一个目标位置想法,此种交互行为发生在当前的Dashbard中。例如使用depends 或 rejects控制面板的显示和隐藏。 |
编辑钻取
如下图所示,点击编辑,然后点击编辑钻取,可进入钻取的编辑界面。
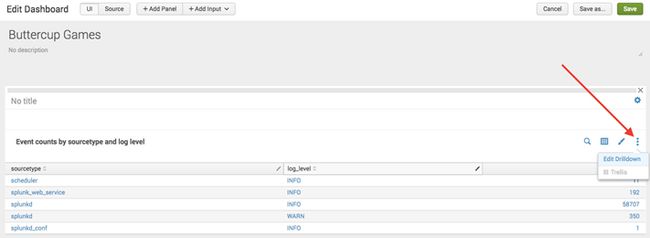
共享
Dashboard可以生成PDF或者在界面中共享给别人。
Splunk App体系
Splunk与其它类似解决方案有一个非常大的区别的地方是提供了一个名为SplunkBase的App市场,如果我们把Splunk视为Android系统,那么SplunkBase就是谷歌市场。
在SplunkBase中提供了1000多个App,这些App基本都是面向某一个应用场景开发出来的功能,包括了可视化、数据采集、处理等各个方面。非常方便的安装之后即可使用,极大的扩展了Splunk的能力,而且这些App大部分是免费的。
如下图所示,Splunk提供了6大类的App
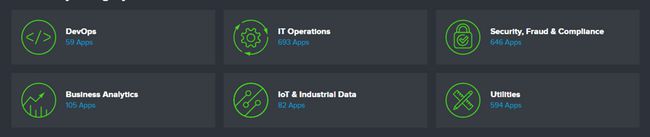
Splunk App应用
App用来做可视化呈现、分析和响应行为,为许多常见应用场景提供了解决方案。 它们通过预配置的仪表板,报告,数据输入和保存的搜索来提供对数据和系统的专业洞察。
如下图左侧的Apps列表中,所有的都是App。
Splunk App示例
- Splunk App for Microsoft Exchange,此App从Microsoft Exchange及其底层基础架构的各个方面收集性能指标,日志文件和PowerShell数据。
- Splunk Enterprise Security,此App帮助安全专家,通过分析大量活动数据来查找威胁。
- Splunk App for VMware,该应用程序提供了对IT健康的实时准确的视图,主动识别性能和容量瓶颈。
- Splunk App for NetApp Data ONTAP, 此应用程序可以可视化所有NetApp Data ONTAP存储系统的配置,日志和性能。
- S.o.S-Splunk on Splunk ,此应用程序帮助分析和解决Splunk自身的问题。
Splunk Add-on附加组件
附加组件是可扩展和自定义Splunk的特定功能的小型可重用组件,非常像一个Splunk App应用,但是专用于一个功能,例如将特定系统的数据导入和到处Splunk Enterprise。 附加组件可以包括自定义配置,脚本,数据输入,自定义报告或视图的任何组合,以及可以改变Splunk Enterprise的外观和风格的主题。 单个附件可用于多个应用程序,套件或解决方案。
技术Add-on是专门的附加组件,帮助从Splunk环境中的特定来源收集,转换和归档数据Feed。 技术附件通常包括:
- 知识管理组件,如字段提取,转换和查找,使数据易于使用。
- 将数据归一化到公共信息模型的知识映射组件,如事件类型和标签。
- 用于从源收集数据的配置和/或工具。
Splunk二次开发
Splunk Web 框架
Splunk Web框架是Splunk用户想要使用表,图表,表单搜索和其他功能创建自定义信息中心和Splunk应用程序的应用程序框架。 Splunk提供了不同的开发工具,从易于使用的拖拽式编辑器界面到JavaScript开发人员的框架模型。
架构
Splunk Web框架提供了一组基于Splunkd(即Splunk服务器核心)构建的功能。 可以构建在Splunk Web中运行的App以及诸如Splunk Search之类的App,但是也可以构建与Splunk进行交互但在自己的Web服务器上运行的自定义App。
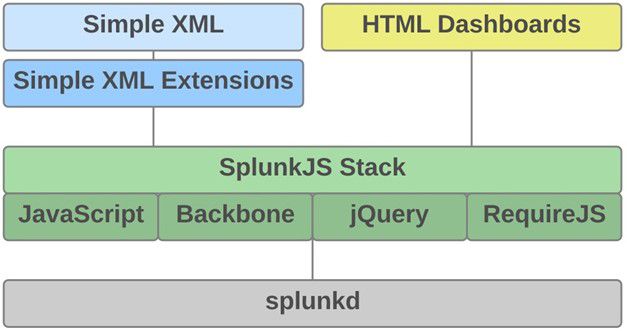
Simple XML层的工具
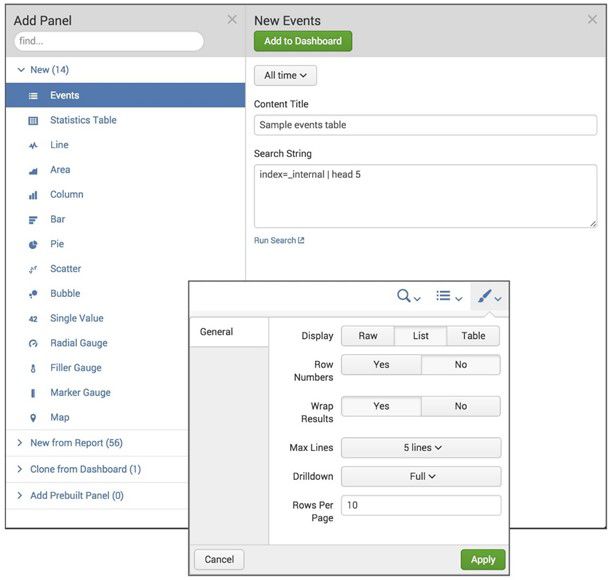
Dashboard编辑器
Dashboard编辑器是一个WYSIWYG(开源的基于html的富文本编辑器)点击和拖动界面,允许您在Splunk Web中构建Dashbaord。 可以添加具有表和图表等视图的Panel,以及窗体控件,如下拉列表,复选框和单选按钮。 Dashboard编辑器还提供编辑工具,可让修改Panel,视图和表单。
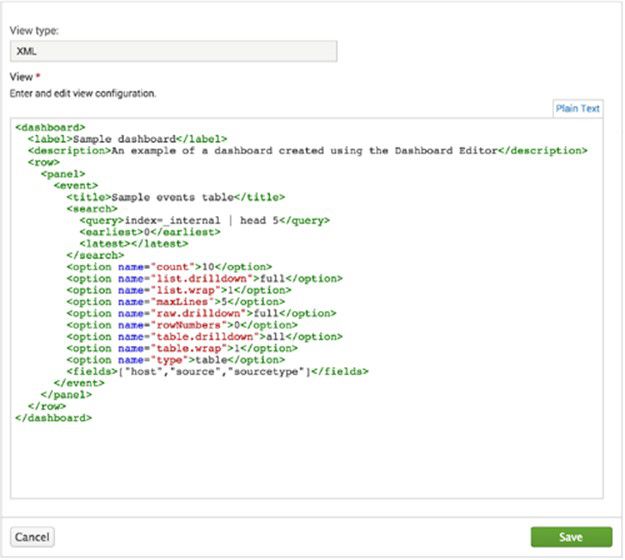
Simple XML
Splunk的可扩展标记语言Simple XML,是使用Dashboard编辑器创建的Dashboard的基础源代码。 尽管可以使用Dashboard Editor中可以使用最常用的功能特性,但在Simple XML代码中才能使用一些高级功能特性。要编辑Simple XML,可以在Splunk Enterprise中使用源代码编辑器,如果可以访问Splunk Enterprise安装中的源文件,则可以使用自己的文本编辑器。
Simple XML 扩展 和HTML Dashboard
Simple XML扩展和HTML Dashboard适用于具有不同专业水平的Web开发人员,开发人员可以在熟悉的Web开环境中进一步自定义Dashboard和App。 每一层访问SplunkJS技术栈,SplunkJs技术栈是一个JavaScript和JavaScript库的Web栈,并且包含用于搜索管理器和可视化的预定义组件。
Simple XML扩展
- 使用扩展来修改使用Dashboard编辑器或使用简单XML创建的Dashboard的外观和行为。 扩展是添加到App的CSS和JavaScript文件,然后从Dashboard的Simple XML代码中引用。
-
为了完全控制App的外观和行为,可以将任何仪表板从Simple XML转换为HTML,然后使用最熟悉的开发工具来使用CSS,HTML和JavaScript代码来构建丰富的交互式体验:
- 修改页面布局和UI的各个方面。
- 添加自定义逻辑,交互和向下钻取行为。
- 与Splunk搜索进行互动并操纵Splunk数据。
- 创建自定义可视化和可重用组件。添加第三方可视化。
- 使用Splunk Dashboard样式,使App具有相同的Splunk外观,包括Splunk chrome和导航栏。
- 如果无权访问Splunk Enterprise安装中的源文件,则可以使用Splunk Enterprise中的源代码编辑器编辑HTML。
- SplunkJS 技术栈类库
通过将SplunkJS技术栈类库添加到自己的网站,将Splunk集成到自己的Web服务器上运行的Web应用程序重,可以使用所有Splunk Web Framework组件来交互和查看Splunk数据。
各种开发方式对比
以下是Splunk中进行App开发的可用方式以及对比说明:
|
|
Dashboard 编辑器 |
Simple XML 代码 |
Simple XML 扩展 |
HTML Dashboard |
SplunkJS 技术栈类库 |
| 场景 |
创建和修改Dashboard |
为现有Dashboard添加高级功能特性 |
为Dashbaord添加自定义的样式和操作逻辑 |
使用自定义的布局和可视化创建交互式的Dashboard |
将Splunk组件嵌入到自己开发的Web应用中 |
| 技能 |
无 |
XML |
• CSS |
• CSS |
• CSS |
| 优点 |
• 拖拽式的可视化编辑界面 • 支持生成PDF特性 |
•拖拽式的可视化编辑界面 •支持PDF生成特性 • 更多的布局选项(相对Dashboard编辑器) • 更多的功能特性(相对于Dashboard编辑器) |
• 拖拽式的可视化编辑界面 • 支持生成PDF特性 • 完全的定制化 • 可使用第三方类库 |
• 完全的定制化 • 可以使用第三方类库 |
• 完全的定制化 • 可以使用第三方类库 • 运行在Splunk Web服务之外 |
| 缺点 |
• 受限的布局 • 使用部分功能特性 |
• 受限的布局 • 使用部分功能特性 |
无 |
• 没有拖拽式编辑界面 • 没有PDF生成特性 |
•没有拖拽式的可视化编辑界面 • 没有PDF生成特性 |
| 参考 |
Dashboard编辑器参考 |
Simple XML编辑参考 |
使用Simple XML 扩展编辑Dashboard参考 |
将Simple XML dashboards转换为HTML |
在Web应用中使用SplunkJS技术栈 |
Splunk机器学习
介绍
机器学习和分析命令
Splunk 平台提供 20 多个机器学习命令,其可以直接使用数据进行检测、告警或分析。outlier、predict、cluster 和 correlate 命令使用固定的算法,而 anomalydetection 等其他命令则允许在若干算法中选择最符合要求的命令。
希望灵活性更高?借助 Splunk 机器学习工具箱,可以获取附加命令和开源算法,为任何使用示例创建自定义模块。
示例展示
简要了解模块创建的互动式示例,其均为 IT、安全、物联网和业务分析的常见使用示例,且排布条理分明。示例包括预测磁盘故障,查找响应时间的异常值,预测 VPN 使用情况和因特网流量。
助手
助手帮助先选择算法,然后引导进行模块创建,测试和部署常见目标,例如预测数值,数字或类别字段,检测数字或类别异常值。
扩展的 SPL 命令
使用机器学习 SPL 命令,例如适应、应用和允许,直接构建、测试和实施模块,使用来自 Splunk Python 科学计算附加设备的开源 Python 算法。
算法
Splunk 机器学习工具包里内置了27种算法,同时也可以使用Python的其他开源的机器学习算法。
分类算法
- 决策树
- 逻辑回归
- 随机森林
- SVM向量机
- BernoulliNB
- GaussianNB
- SGDClassifier
- GradientBoostingClassifier
回归算法
- DecisionTreeRegressor
- KernelRidge
- LinearRegression
- RandomForestRegressor
- Lasso
LASSO是由1996年Robert Tibshirani首次提出,全称Least absolute shrinkage and selection operator。该方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
- ElasticNet
ElasticNet 是一种使用L1和L2先验作为正则化矩阵的线性回归模型.这种组合用于只有很少的权重非零的稀疏模型,比如:class:Lasso, 但是又能保持:class:Ridge 的正则化属性.我们可以使用 l1_ratio 参数来调节L1和L2的凸组合(一类特殊的线性组合)。
当多个特征和另一个特征相关的时候弹性网络非常有用。Lasso 倾向于随机选择其中一个,而弹性网络更倾向于选择两个.
在实践中,Lasso 和 Ridge 之间权衡的一个优势是它允许在循环过程(Under rotate)中继承 Ridge 的稳定性.
- Ridge
- SGDRegressor
- GradientBoostingRegressor
特征提取Feature Extraction
- FieldSelector
- TFIDF
- PCA
- KernelPCA
异常检测Anomaly Detectors
- OneClassSVM
聚类算法Clustering Algorithms
- KMeans
- DBSCAN
- Birch
- SpectralClustering
预处理Preprocessing
- StandardScaler
时间序列分析Time Series Analysis
- ARIMA
工具算法Utility Algorithms
- Autocorrelation Function
- Partial Autocorrelation Function
示例展示
预测数值字段
算法: 线性回归
| 示例 |
数据集 |
说明 |
| 预测服务器电源消耗 |
服务器电力数据(server_power.csv) |
基于服务器的如CPU使用率、内存实务等预测服务器的电力消耗。 |
| 预测VPN的使用率 |
应用的统计数据(apps.csv) |
预测雇员的VPN使用情况,基于应用的使用频率。 |
| 预测房子价值中位数 |
房屋数据 (housing.csv) |
根据房子相关的数据预测房子的价值中位数 |
| 预测电厂的能源输出 |
电厂的湿度 (power_plant.csv) |
根据其他数据变量(如环境温度和湿度)预测发电厂的功率输出。 |
预测分类字段
算法: 逻辑回归
| 示例 |
数据集 |
说明 |
| 预测磁盘故障 |
磁盘故障 (disk_failures.csv) |
根据磁盘的多种指标预测磁盘是否将会出现故障 |
| 预测是否存在恶意软件 |
防火墙流量 (firewall_traffic.csv) |
根据防火墙上的各种流量指标,预测防火墙是否会受到恶意软件的影响,还是有漏洞。 |
| 预测电信客户流失 |
流失数据(churn.csv) |
预测客户是否会因为客户的使用模式改变供应商 |
| 预测糖尿病 |
糖尿病数据 (diabetes.csv) |
|
| 预测车辆制造和模型 |
车辆跟踪数据 (track_day.csv) |
根据实时指标预测车辆的类型 |
检测数字异常值
算法: Distribution statistics
| 示例 |
数据集 |
说明 |
| 检测服务器响应时间中的异常值 |
服务器响应时间数据S (hostperf.csv) |
检测服务器响应时间中的异常值 |
| 检测登录次数中的异常值 |
雇员登录数据 (logins.csv) |
预测按小时登录的次数,并识别实际登录次数与预测明显不同的数据。 |
| 检测超市采购中的异常值 |
超市采购数据集 (supermarket.csv) |
检测超市中的采购数量的异常值。 |
| 检测电厂湿度异常值 Detect Outliers in Power Plant Humidity |
电厂湿度数据集 Power plant humidity (power_plant.csv) |
检测电厂湿度异常值 Detects outliers in humidity of a power plant. |
检测分类异常值
算法: Probabilistic measures
| 示例 |
数据集 |
说明 |
| 检测磁盘故障中的异常值 |
磁盘故障数据集 (disk_failures.csv) |
检测磁盘故障数据中的分类异常值。 |
| 检测比特币交易中的异常值 |
比特币交易数据集(bitcoin_transactions.csv) |
检测可能反映异常活动的比特币交易中的异常值。 |
| 检测超市采购中的异常值 |
超市采购数据集(supermarket.csv) |
检测超时整个交易中的异常值 |
| 检测抵押合约中的异常值 |
纽约抵押合约数据集 (mortgage_loan_ny.csv) |
检测纽约抵押合约中的异常值 |
| 检测糖尿病患者记录中的异常值 |
糖尿病数据集(diabetic.csv) |
检测糖尿病患者记录中的异常值 |
| 检测移动电话活动中的异常值 |
电话使用情况数据(phone_usage.csv) |
检测来自不同手机的呼入,呼出或错过的呼叫数量的异常值。 |
时间序列预测分析
算法: State-space Method using Kalman Filter
| 示例 |
数据集 |
说明 |
| 预测Internet流量 |
Internet流量数据集 (internet_traffic.csv) |
根据提供的几个完整的互联网流量历史周期数据,预测互联网使用的峰值和非高峰时间。 |
| 预测雇员的登录次数 |
雇员登录数据 (logins.csv) |
预测每个小时的登录次数 |
| 预测月度销售量 |
纪念品商店的销售数据 (souvenir_sales.csv) |
预测纪念品商店的月销售纪录。 |
| 预测蓝牙设备的数量 |
蓝牙设备数据 (bluetooth.csv) |
预测新加坡国立大学校园内最繁忙的演讲厅内接入点的蓝牙联络人数。 |
| 使用ARIMA预测汇率TWI |
汇率TWI数据 (exchange.csv) |
预测货币的交易加权指数 |
对数据类事件进行聚簇
算法: K-means, DBSCAN, Spectral Clustering, BIRCH
| 示例 |
数据集 |
说明 |
| 根据SMART指标进行磁盘聚簇 |
磁盘故障数据disk_failures.csv |
根据磁盘的自我监控指标进行聚簇 |
| 根据应用的使用对行为进行聚簇 |
应用使用数据app_usage.csv |
根据用户使用业务应用(例如Webmail或VPN)的频率,对雇员行为进行聚簇 |
| 根据属性对社区进行聚簇 |
房屋数据housing.csv |
基于属性,例如犯罪率、房屋中位数,对社区进行聚簇 |
| 根据车载指标,对车辆进行聚簇 |
车载指标数据track_day.csv |
根据车载的指标,例如引擎温度和G值,对赛道上的车辆进行聚簇。 |
| 聚簇发电厂的运行状况 |
电厂数据power_plant.csv |
基于诸如温度和真空的环境测量来聚簇发电厂的运行状况。 |
性能
查询类型如何影响性能
| 查询类型 |
说明 |
参考索引器的吞吐 |
性能影响 |
| 密集 |
返回指定时间段内的符合条件的结果,如果返回的结果超过了数据集的10%或者更多。密集型查询通常会优先消耗CPU,因为需要从压缩的数据中提取原始数据。例如:使用空搜索而不是通配符,或者搜索任何index。 样例:
|
每秒最高50000个匹配事件 |
CPU密集型 |
| 稀疏 |
返回指定时间段内的符合条件的结果,如果返回的结果超过了数据集的0.01%到1%。返回的数据量少于密集型查询。 |
每秒最高5000个匹配事件 |
CPU密集型 |
| 超级稀疏 |
从每个index的分桶中返回的符合查询条件的数量很少。超级稀疏型查询是I/O密集型,因为索引器必须遍历index的所有分桶来查询。如果索引中存储了大量的数据,有很多的分桶,超级稀疏查询可能会花费很长的时间执行。 |
最高2秒钟/分桶 |
I/O密集型 |
| 罕见 Rare |
类似于超级稀疏搜索,但是使用了boom-filter,有助于过滤与搜索请求不匹配的索引桶。 罕见的搜索结果可以比超稀疏搜索快20到100倍。 |
从10个分桶/秒到50个分桶/秒 |
I/O密集型 |
Splunk部署
支持的操作系统
Unix/Linux类
| 操作系统 |
架构 |
企业版 |
免费版 |
试用版 |
通用转发器 |
| Solaris 10,11 |
x86 (64-bit) |
X |
|||
| SPARC |
X |
||||
| Linux, 内核版本2.6 及更高 |
x86 (64-bit) |
X |
X |
X |
X |
| Linux, 内核版本3.x 及更高 |
x86 (64-bit) |
X |
X |
X |
X |
| PowerLinux, 内核版本2.6 及更高 (包含Big Endian 和Little Endian 版) |
PowerPC |
D |
|||
| zLinux, 内核版本2.6 及更高版本 |
s390x |
X |
|||
| FreeBSD 9 |
x86 (64-bit) |
D |
|||
| FreeBSD 10 ,11 |
x86 (64-bit) |
X |
|||
| Mac OS X 10.11 ,macOS 10.12 , 10.13 |
Intel |
X |
X |
X |
|
| AIX 7.1 ,7.2 |
PowerPC |
X |
|||
| ARM Linux |
ARM |
A |
A: 该平台可以安装Splunk的软件,但是没有官方支持。
D: 支持该平台和架构,但是在未来的版本中可能会不再支持。详细请查阅发布说明中的 Deprecated Features。
Windows类
| 操作系统 |
架构 |
企业版 |
免费版 |
试用版 |
通用转发器 |
| Windows Server 2008 R2 |
x86 (64-bit) |
D |
|||
| Windows Server 2012, Server 2012 R2, Server 2016 |
x86 (64-bit) |
X |
X |
X |
X |
| Windows 8 |
x86 (64-bit) |
D |
|||
| x86 (32-bit) |
N |
||||
| Windows 8.1 和10 |
x86 (64-bit) |
X |
X |
X |
|
| x86 (32-bit) |
*** |
*** |
X |
D: 支持该平台和架构,但是在未来的版本中可能会不再支持。详细请查阅发布说明中的 Deprecated Features .
N: 新版本Splunk不支持该平台和架构。如果需要此平台和体系结构的支持,则必须下载较早版本的Splunk软件。
***: Splunk支持但是不建议安装在此平台和架构上。
支持的浏览器
-
Firefox 最新版
-
Internet Explorer 11 (不支持兼容模式)
-
Safari 最新版
-
谷歌浏览器最新版
-
国产浏览器
360浏览器、腾讯浏览器、搜狗浏览器(使用极速模式)
硬件建议
中小规模数据环境
适用于中小规模的环境,单个实例推荐配置如下:
| 平台 |
建议硬件配置 |
| 非Windows平台 |
2x 6核, 2+ GHz CPU, 12GB 内存, 冗余磁盘阵列 (RAID) 0 或 1+0, 64位操作系统 |
| Windows平台 |
2x6核, 2+ GHz CPU, 12GB 内存, RAID 0 或 1+0, 64位系统 |
大规模的数据环境和分布式部署
稍后待续
Splunk容量规划
磁盘容量
(每天平均索引的数据大小) x ( 存储周期 ) x 1/2
例如每天平均的索引的数据大小为5GB,存储周期是90天,所需要的存储空间大约为5 x 90 x 1/2 = 225GB
Splunk案例
GE通用
基本信息
- 每天 1TB数据(每个月100 billion 安全事件)
- 基础设施分布在全球的10个数据中心
- 3个Splunk Search Head, 20 个Splunk Indexer, 6000个forwarder
- 90天的日志保存期
- 300个活跃Splunk用户
- 日志来自50万台工作站、服务器和网络设备
用户场景
安全运维
- 客户端分发、版本跟踪和升级
- 恶意软件爆发跟踪
- 漏洞识别和修复
- 补丁部署跟踪
- 策略分析
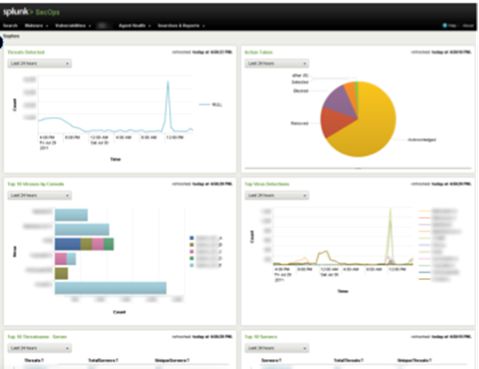
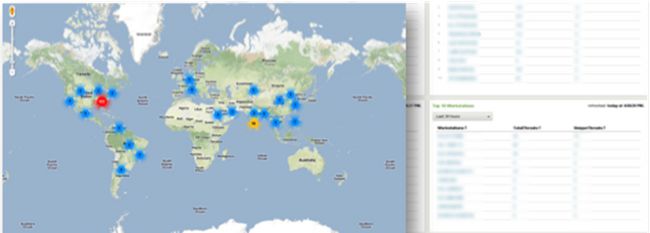
特权用户访问 (Highly Privileged Access/HPA)
- 针对全球特权用户的访问,集中记录、报表和告警
- 帮助符合监管 要求,强制合规行为
- 针对各种操作系统、数据库、文件和应用程序的安全事件提供报表
- 提供PDF仪表板分发、实时告警、自定义报表控制面板,与工单系统整合集成
有针对的安全报表展现
- 对高级别主机提供报表和告警设置
- 定制Splunk内部apps应用
- 漏洞、安全事故和客户单监控状况报表
- 实时恶意代码景观
- 可钻取的仪表板
Splunk产品版本对比
| 特性 |
Splunk Enterprise 企业版 |
Splunk Light轻量版 |
Splunk Free免费版 |
| 每天最大索引数据量 |
无限制 |
20GB |
500MB |
| 最多用户数 |
无限制 |
20 |
1 |
| 通用数据收集和索引 |
支持 |
支持 |
支持 |
| 指标存储 |
支持 |
支持 |
支持 |
| 数据收集插件 |
支持 |
支持 |
支持 |
| 监控和告警 |
支持 |
支持 |
不支持 |
| Dashbaord和报告 |
支持 |
支持 |
支持 |
| 查询和分析 |
支持 |
支持 |
支持 |
| 自动数据完善 |
支持 |
支持 |
支持 |
| 异常检测 |
支持 |
支持 |
支持 |
| 表,数据模型和透视图 |
支持 |
不支持 |
不支持 |
| Splunkbase Apps |
支持 |
仅AWS App |
支持 |
| Splunk高级解决方案 |
支持 |
不支持 |
不支持 |
| 高可用性 |
支持 |
不支持 |
不支持 |
| 灾难恢复 |
支持 |
不支持 |
不支持 |
| 集群 |
支持 |
不支持 |
不支持 |
| 分布式搜索 |
支持 |
不支持 |
不支持 |
| 性能加速 |
支持 |
不支持 |
不支持 |
| 访问控制 |
细粒度和可定制 |
Admin和用户级 |
Admin用户 |
| 单点登录/LDAP |
支持 |
不支持 |
不支持 |
| 开发环境 |
完全的API和SDK |
无 |
无 |
| 支持 |
企业全球 |
标准 |
社区 |
Splunk许可模式
Splunk按照索引的数据量计算产品的价格,分为按年授权和永久授权。
按年授权产品价格 = 授权每天索引数据量(GB)* 每GB价格
永久授权产品价格 = 授权每天索引数据量(GB)* 每GB价格
注意:随着授权每天索引数据量的增加,每GB价格持续下降。