hello大家好,我是你们的可爱丸,不知道你们有没有遇到过这种情况:
自己喜欢的小说竟然只能看不能下载???
作为一个python学习者,这种情况当然不能忍,那么今天我就教大家用python写一个小说爬虫,轻轻松松的把全网小说都下载到你的电脑里。
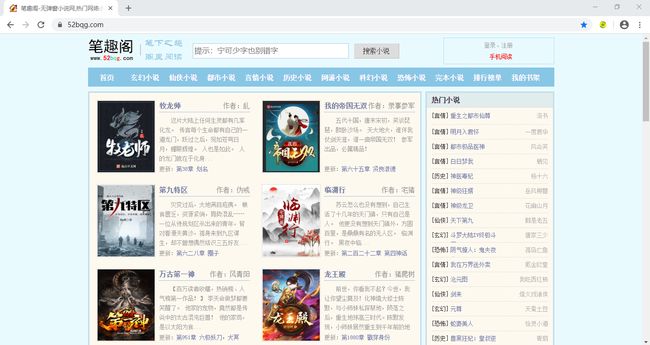
本次案例我选取的是小说网站是:笔趣阁,首页地址为:https://www.52bqg.com/
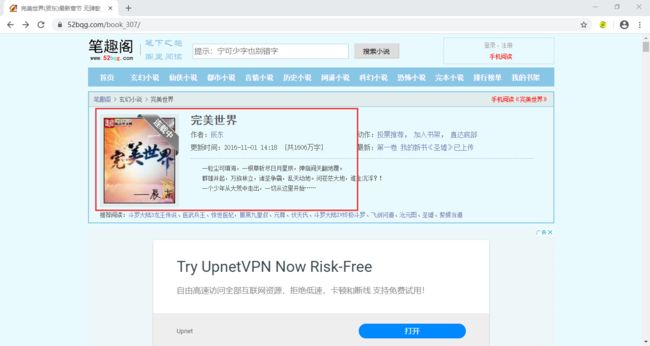
因为该小说网站上每一本小说的内容都很多,所以今天我就教大家设计针对单本小说的爬虫。在本案例中,我选取的是以下这本还在连载的小说,网页地址为:https://www.52bqg.com/book_307/
在正式开始讲解之前我先给大家讲解一下我的设计思路:
1、确定想要爬取的小说及入口url
2、在入口url通过解析获取小说所有章节名称及各章节href
3、通过字符串拼接得到所有章节详情页的地址
4、爬取每章具体内容的文本
5、将每章小说以章节名称命名并保存为txt文件
注意:现在各大网站都有反爬机制,所以我们要对我们的爬虫进行伪装,让它模仿浏览器访问,这样网站就检测不到访问他的是爬虫程序啦。所以我们要给爬虫设置请求头,将网页的User-Agent复制到代码里
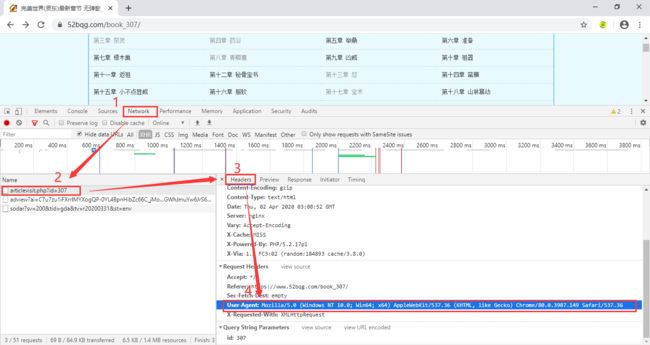
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
刚才我们已经确定了想要爬的小说以及入口url,那怎么获取小说的章节名称和href呢?方法是:点击鼠标右键,选择检查,然后选择左上角的小箭头,再把鼠标移动到我们想要获取的内容的位置,就能找到他们的代码啦!
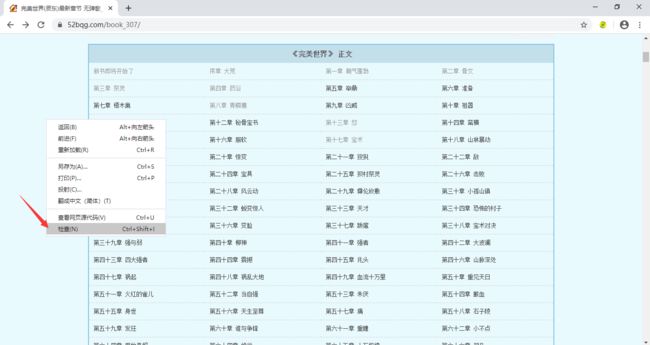
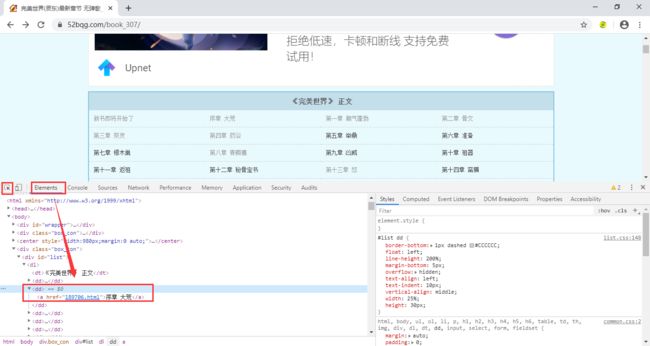
这里我们通过xpath的方式获取需要的内容 ,如果你对xpath不熟悉的话,那我们还可以通过如下的一个小妙招轻松获取xpath路径。
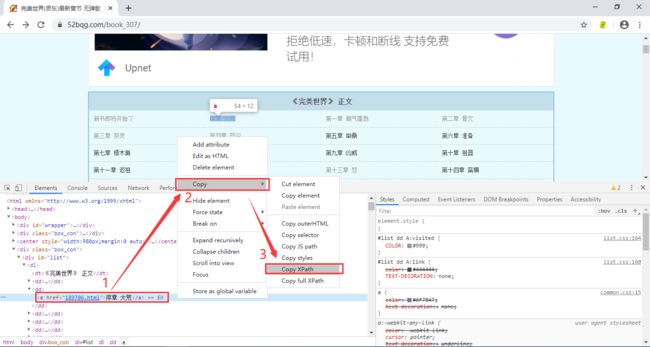
注意:dd[3]代表的是获取第三个dd标签的内容,如果你想获取所有章节名称,那把[3]去掉即可,即:
//*[@id="list"]/dl/dd[3]/a
变为:
//*[@id="list"]/dl/dd/a
代码如下:
#设置爬取小说的函数功能
def get_text(url):
response = requests.get(url, headers=headers)
#最常用的编码方式是utf-8以及gbk,出现乱码可以先尝试这两种
response.encoding = 'gbk'
selector = etree.HTML(response.text)
#获取到所有章节的标题
title = selector.xpath('//*[@id="list"]/dl/dd/a/text()')
#获取每章小说具体内容的链接
hrefs = selector.xpath('//*[@id="list"]/dl/dd/a/@href')
接下来我们来想一想如何获取到每一章的内容链接呢?首先我们可以观察一下每一章的链接有什么规律:
第一章:https://www.52bqg.com/book_307/189710.html
第二章:https://www.52bqg.com/book_307/189713.html
第三章:https://www.52bqg.com/book_307/189716.html
第四章:https://www.52bqg.com/book_307/189720.html
第五章:https://www.52bqg.com/book_307/189723.html
我们可以观察到,每章的链接地址前面有一部分都是相同的,而最后一个/后的内容都是每一章名称a标签的href属性的内容,因此我们可以通过字符串的拼接来找到具体章节地址
urls = []
for href in hrefs:
#把url和href拼接得到每一章具体内容的url并存在urls列表里
urls.append(url+href)
然后我们可以再次通过审查元素的方法,找到章节内容的xpath路径,获取每一章的内容
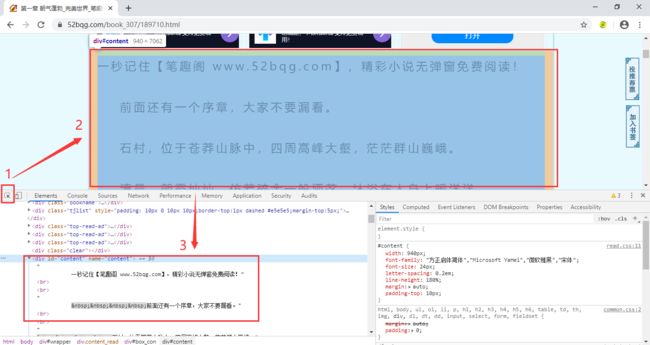
for i in range(len(urls)):
#传入每一章内容具体链接的url
response = requests.get(urls[i], headers=headers)
response.encoding = 'gbk'
selector = etree.HTML(response.text)
#获取每一章具体的内容
contents = selector.xpath('//*[@id="content"]/text()')
#保存小说章节名称及章节内容
最后我们再设计一下保存文章的代码,并使这个爬虫能帮助我们在没有对应文件夹的情况下自动创建文件夹保存小说文件。
自动生成小说文件夹:
import os
#自动创建保存小说的文件夹
# os.chdir()方法用于改变当前工作目录指定的文件夹
if not os.path.exists(os.getcwd()+"/xiaoshuo"):
print("小说文件夹不存在,帮你自动创建好了")
print("==================================")
os.mkdir("xiaoshuo")
#把当前路径改为到xiaoshuo文件夹处
os.chdir(os.getcwd()+"/xiaoshuo")
else:
print("小说文件夹存在")
os.chdir(os.getcwd()+"/xiaoshuo")
print("==================================")
保存为txt文件:
with open(title[i]+".txt", "w", encoding='utf-8') as f:
for content in contents:
content = content.replace("\n","")
#将每一章的内容写入对应章节的txt文件里
f.write(content)
print(str(title[i])+"下载成功!")
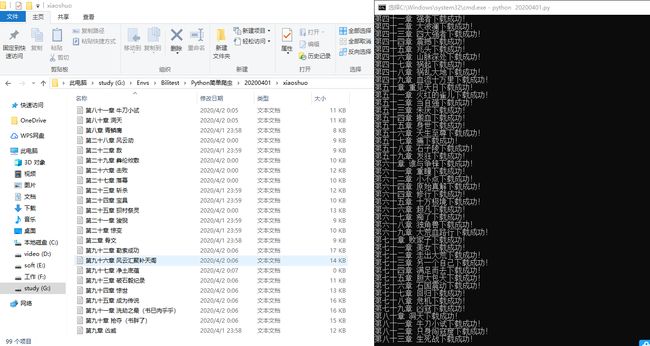
代码运行效果:
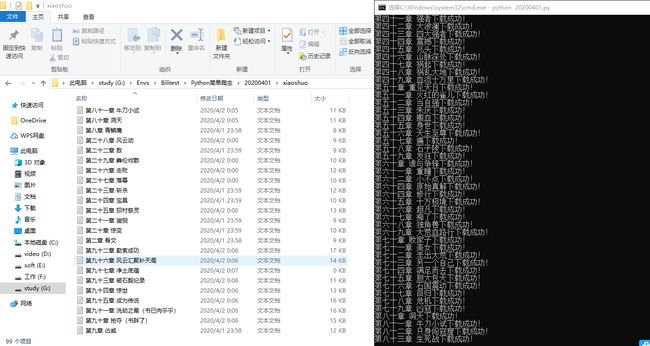
完整代码:
#导入需要用到的模块
import requests
from lxml import etree
import os
#自动创建保存小说的文件夹
# os.chdir()方法用于改变当前工作目录指定的文件夹
if not os.path.exists(os.getcwd()+"/xiaoshuo"):
print("小说文件夹不存在,帮你自动创建好了")
print("==================================")
os.mkdir("xiaoshuo")
#把当前路径改为到xiaoshuo文件夹处
os.chdir(os.getcwd()+"/xiaoshuo")
else:
print("小说文件夹存在")
os.chdir(os.getcwd()+"/xiaoshuo")
print("==================================")
#设置请求头
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
#设置想要爬取的小说链接
url = 'https://www.52bqg.com/book_307/'
#设置爬取小说的函数功能
def get_text(url):
response = requests.get(url, headers=headers)
#最常用的编码方式是utf-8以及gbk,出现乱码可以先尝试这两种
response.encoding = 'gbk'
selector = etree.HTML(response.text)
#获取到所有章节的标题
title = selector.xpath('//*[@id="list"]/dl/dd/a/text()')
#获取每章小说具体内容的链接
hrefs = selector.xpath('//*[@id="list"]/dl/dd/a/@href')
urls = []
for href in hrefs:
#把url和href拼接得到每一章具体内容的url并存在urls列表里
urls.append(url+href)
for i in range(len(urls)):
#传入每一章内容具体链接的url
response = requests.get(urls[i], headers=headers)
response.encoding = 'gbk'
selector = etree.HTML(response.text)
#获取每一章具体的内容
contents = selector.xpath('//*[@id="content"]/text()')
#保存小说章节名称及章节内容
with open(title[i]+".txt", "w", encoding='utf-8') as f:
for content in contents:
content = content.replace("\n","")
#将每一章的内容写入对应章节的txt文件里
f.write(content)
print(str(title[i])+"下载成功!")
if __name__ == '__main__':
get_text(url)
今天的小说爬虫案例就分享到这里啦,喜欢的朋友们记得给我点赞关注支持我哦,我将持续和大家分享python学习经验 O(∩_∩)O~
