原料
windows10+python3.5+pycharm
安装tensorflow
利用Tensorflow训练搭建自己的物体训练模型,万里长征第一步,先安装tensorflow。
tensorflow分为cpu版和gpu版,gpu版的运行速度是cpu的50倍,但是gpu版的坑太多,要安装许多开发套件,对windows的支持不够友好;更为致命的是,它需要Nvida的中高端显卡,我的电脑系统是windows10,显卡是入门级显卡,开始我还想挣扎一下,安装个gpu版,大概试了一个晚上,到底是没有成功,识时务者为俊杰,那就安装cpu版的吧。
pip insatll tensorflow
假如没有报错,做个测试,运行以下代码
import tensorflow as tf
#指定一个常数张量
first_blood = tf.constant('double kill')
#创建一个会话,方便查看结果
sess = tf.Session()
print(str(sess.run(first_blood)))
运行结果如下
E:\python\python.exe "E:/pycharm src/TF/__init__.py"
2018-12-01 23:33:25.181550: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
double kill
Process finished with exit code 0
如果出现警告:
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
翻译过来的大致意思是:
你的CPU支持AVX扩展,但是你安装的TensorFlow版本无法编译使用
此时需要在第一行代码前加上两行代码:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
# 指定一个常数张量
first_blood = tf.constant('double kill')
# 创建一个会话,方便查看结果
sess = tf.Session()
print(str(sess.run(first_blood)))
下载Tensorflow object detection API
如果有git的话,右键git bash,使用命令下载:
git clone https://github.com/tensorflow/models.git
或者直接打开网站:
https://github.com/tensorflow/models
点击绿色按钮->downlaod zip
下载好之后,把文件解压,注意解压路径不要包含中文,比如我的解压后的路径是:
C:\Users\lenovo\Desktop\note\gitclone\models
如果下载速度很慢,可以参考:https://blog.csdn.net/ygdxt/article/details/82825013
下载并配置protoc
在https://github.com/google/protobuf/releases中选择windows版本:

只有win32,也就是windows32位的,64位是兼容32位的。
下载好之后,解压,把bin目录下的protoc.exe复制到..\models\research文件夹下。
接着就是配置protoc了,在打开cmd下切换到..\models\research目录,
执行命令protoc object_detection\protos\*.proto --python_out=.
如果报以下的错(其实很大可能性会报错,无论是不是在管理员模式下):
object_detection\protos*.proto: No such file or directory
则需要对指令做修改,指令protoc object_detection\protos\*.proto --python_out=.中的*.proto表示是对research目录下的所有后缀名为proto的文件做操作,那干脆我们把指令中的*.proto这部分改成所有后缀名为proto的文件,每执行一次,就会生成一个.py文件,由于文件太多,我已经把指令写成脚本:
import os
path_url = os.path.join(os.getcwd(),r"object_detection\protos")
print("proto path:",path_url)
for file in os.listdir(path_url):
cmd = "protoc object_detection\protos\{} --python_out=."
if file.endswith(".proto"):
command = cmd.format(file)
print("excuting command:",command)
os.popen(command)
在..\research目录下新建一个文件excuter.py,把以上代码复制进去,保存运行,稍等一会儿就可以看到..\research\object_detection\protos目录下生成了许多.py文件,说明protoc配置成功。
models环境变量配置
配置环境变量
依次打开:我的电脑--->高级系统设置--->环境变量,新建一个系统变量:

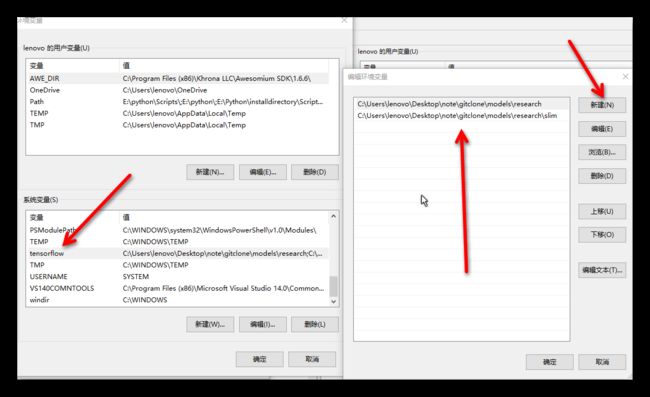
系统变量名只要不和已有的重复,符合命令规范,没有其他要求,我这里是
tensorflow
系统变量名下有两个值,..\research和..\research\slim的绝对路径。
测试
在..\research下打开cmd,运行以下命令,
python object_detection/builders/model_builder_test.py
如果出现错误:
报错原因是你的models路径太长,python无法找指定模块,
解决办法是在你的python安装路径下新建一个tensorflow_model.pth文件
(比如我的是E:\python\Lib\site-packages)
把写到环境变量里的那两个路径复制到该文件中。
再运行命令python object_detection/builders/model_builder_test.py
说明配置成功
利用tensorflow自带模型测试
测试的图片是在
C:\Users\lenovo\Desktop\note\gitclone\models\research\object_detection\test_images
我们看到这里有现成的两张图片,当然也可以换成自己的。
测试的脚本是
C:\Users\lenovo\Desktop\note\gitclone\models\research\object_detection\object_detection_tutorial.ipynb
这是一个需要用jupyter notebook打开的文件,不过好像在jupyter notebook运行会有许多毛病
我已经把这个ipynb文件改写成py文件,并修复了一些未知问题,文件内容如下:
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from distutils.version import StrictVersion
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from distutils.version import StrictVersion
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
from utils import label_map_util
from utils import visualization_utils as vis_util
# What model to download.
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
output_num = 1
output_img_dic = r'\output_images'
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
print(1,image_np)
plt.imshow(image_np)
plt.show()
global output_num
global output_img_dic
if not os.path.exists(output_img_dic):
os.mkdir(output_img_dic)
output_img_path = os.path.join(output_img_dic,str(output_num)+".png")
plt.savefig(output_img_path)
运行上述代码需要安装
matplotlib库,直接pip install matplotlib安装失败的可以去官网安装与python版本对应的whl文件。安装matplotlib.whl时需要先出pycharm。
同时由于需要下载模型文件,需要在网络好的情况下进行测试。否则就会报HTTP ERROR错误
运行效果图
