1 为什么需要Graphs
Graphs(图)是用于描述和分析具有关系/互动的实体的通用语言

因为图论以及Graph充斥在我们学习和生活的方方面面:
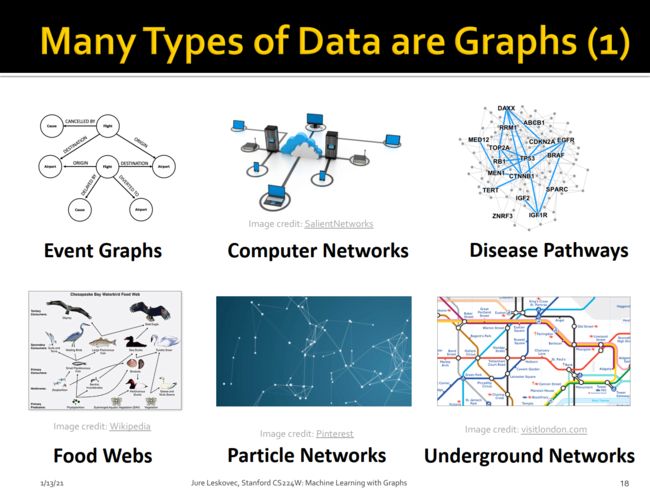
Event Graphs:事件图谱,比如我们常见的飞机航班图,从登机到我们安全抵达目的地,其中航班飞机与乘客之间发生了许多事情。
Computer Networks:计算机网络拓扑图,在万维网中人们通过各种形式正在冲浪,云服务器、中转机、个人电脑组成了一个非常庞大的网络图
疾病传播图:我们以近期北京顺义新冠病例传播为例,此次顺义区局部聚集性疫情为单一传播链,初步判断疫情感染来源为12月28日报告新增的1例境外输入无症状感染者。
Food Webs:食物链,一个基于知识图谱创建动物app的例子为一款由腾讯联合WWF打造、名为「神秘雪豹在哪里」的微信小程序。而且上线2天,便有超过10万人在使用。打开「神秘雪豹在哪里」小程序,点击图片上雪豹的不同部位,便可查看相应的知识点,如雪豹的分布区域、身体结构、成长阶段、生存环境等。「同域物种生物链图谱」则展示了雪豹相关生物链上每一个物种的简介https://www.jiqizhixin.com/articles/2020-10-29-6
Particle Networks:人们所认识的宇宙世界是由原子和其他基本粒子组成,原子则是由原子核与电子组成,原子核是由质子和中子构成,而质子和中子是夸克和胶子构成的。随着实验和理论的发展,科学家形成了描述宇宙构成和相互作用的“标准模型”。
Underground Networks:地图线路图
- Social Networks:社交网络
- Economic Networks:金融贸易网络
- Citation Networks:科技文献相互引用网络图
- Internet:互联网
- Networks of Neurons:脑神经网络
下面我们人工组建构造的衍生知识网络:
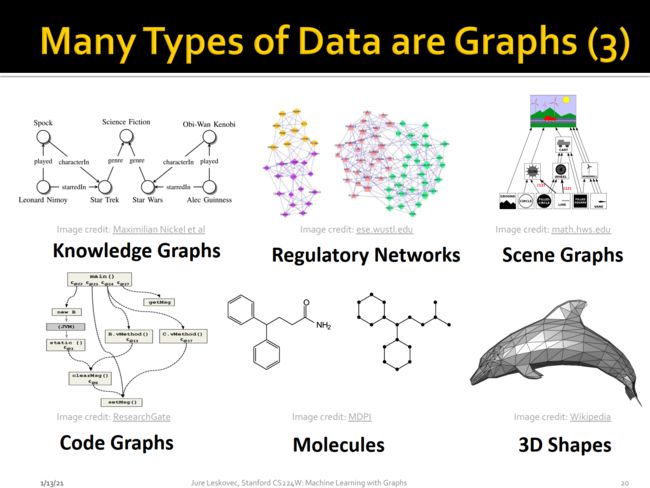
从上面一些例子我们可以看出,Graph的概念存在于这个世界的每个地方,我们每个人都或多或少地在Graph扮演某个角色或者正在利用Graph带来的便利,目前随着图神经网络的崛起,Graph的潜在价值将会越来越大
2 Networks和Graphs
Networks通常认为是自然状态下的图:
- 社交网络:全球71人组成了一个庞大社会群体
- 信息交互与传递:电子设备,手机,电话以及电子金融交易
- 生物医学:基因/蛋白质控制和管理我们身体的机能
- 大脑:我们的想法来源于数十亿神经元的相互联系
Graphs(作为一种信息表示或者知识表示) - 信息/知识:由人类加工后的各种信息或者知识
- 软件:软件有各个组件构成图
- 相似性网络:连接着相似的数据点
- 相关性结构:分子,基因图谱, 3D结构图,粒子
很多时候network和graph界限比较模糊,我们暂且可以认为Networks是自然状态下的图,而Graph是经过加工或者复杂结构组成的。
3 基于Graphs的机器学习

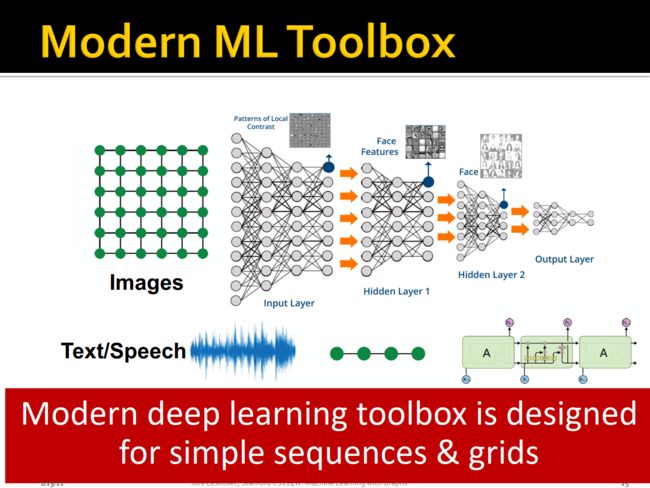
当前主流的深度学习模型主要是为简单的序列数据或者格式化数据来设计的,如下图所示常见有图像数据、文本或者语音数据等。
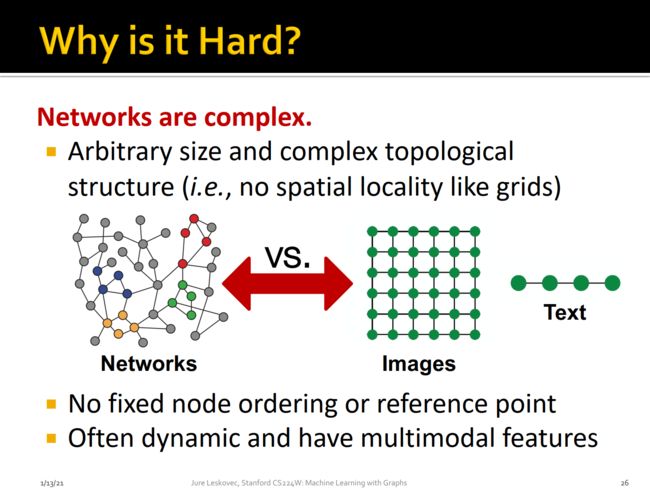
但是基于网络或者图的机器学习是相对困难的:
- 图是没有固定的大小,并且是一个复杂的拓扑结构
- 节点之前没有固定的引用顺序
-
图时常是动态更新的并且具有多模态异构的特征
所以我们如何开发或者探索出一种神经网络使Graph更加广泛地的应用?
Graphs正在成为深度学习新的研究领域

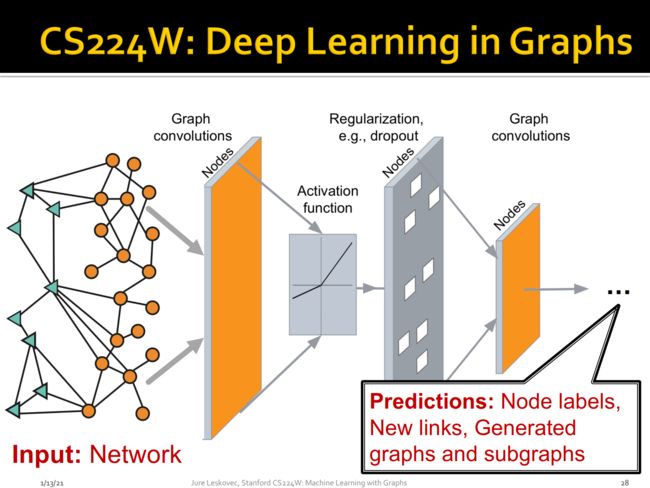
我们以GCN为例来解释深度学习在图学习的作用机制,由节点以及节点之前的边组成Graphs作为神经网络的输入,通过图卷积神经网络以及几激活函数得到图的表示,最后通过正则化比如dropout来约束模型,最后通过输出层得到相应任务的输出,比如可以用来预测节点的标签、新的关系以及子图发现。
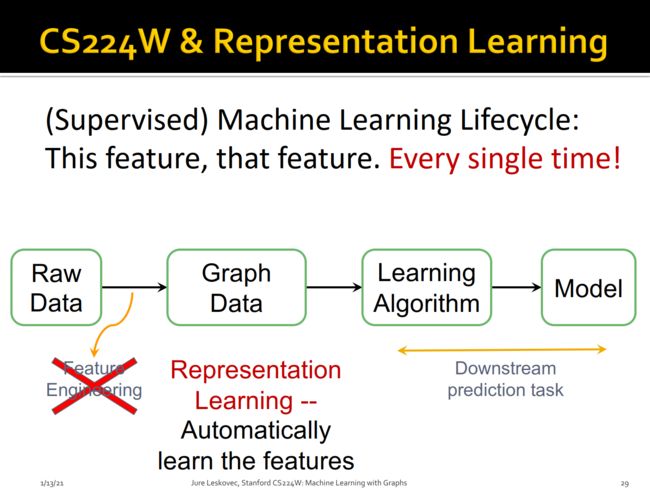
(有监督)机器学习生存周期基本上是构建特征工程->基于模型做特征学习以及学习新的特征表示->最后基于特征进行预测,而现在基于Graph的机器学习不需要枯燥的特征工程了,而是输入到网络进行自动表示学习,然后用于下游任务。
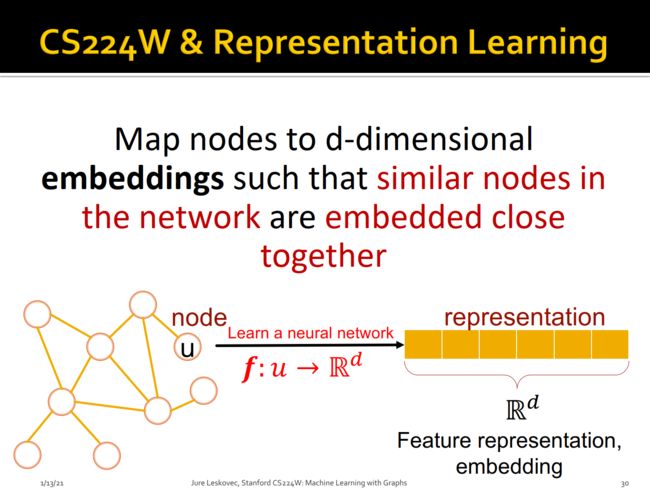
通过Graph的表示学习,我们可以将网络映射到d维的嵌入空间,理想情况下,在这个d维的向量空间中网络中的相似节点相似性越大,差异距离越小。
下面举出来了几种常见的图表示学习方法:
- 传统方法:Graphlets,Graph Kernels
- Node Embedding:DeepWalk,Node2Vec
- GNN:GCN,GraphSAGE,GAT,GNNS
- 知识图谱以及嵌入:TransE,BetaE
- 图生成网络
-
生物医药、科学研究以及工业界的应用
之后我们会慢慢介绍以上几种方法,大家在此节先导致了解下

4 Graphs ML的应用实例
我们前面也提到过基于Graphs的机器学习可以做哪些任务:
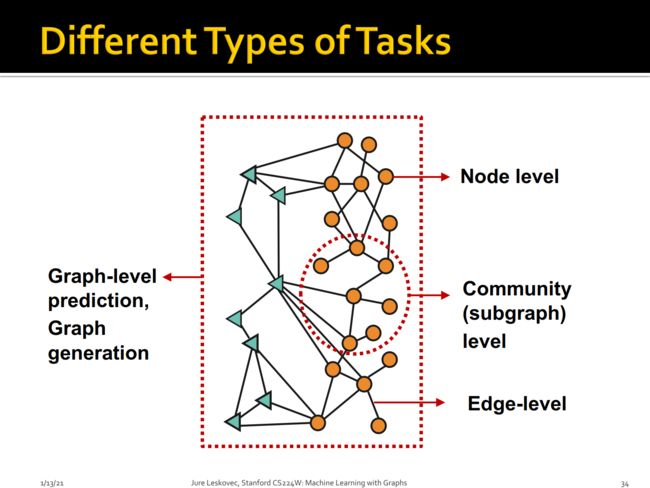
- Graph级别的预测,比如预测Graph的类型以及图的生成,比如预测整个分子团的属性
- 节点级别的任务:这个也是较常见的,比如节点标签预测、节点学习等,判断节点是用户或者商品
- 社区级别:发现新的子图,构建新的节点社区或者簇,常见的方式是图聚类
- 边级别的预测:预测两个节点之间是否存在新的关系
-
其他任务:图生成-比如新的药物结构图发现;图演化

4.1 Node级别的Graph机器学习实例
- 震惊科学界!DeepMind AI破解「蛋白质折叠」难题,攻克生物学50年巨大挑战
白质折叠(英语:Protein folding)是蛋白质获得其功能性结构和构象的物理过程。通过这一物理过程,蛋白质从无规则卷曲折叠成特定的功能性三维结构
原文链接:https://www.leiphone.com/news/202012/lklVFjHWl2C7xUFh.html
DeepMind在官方博客中称:AlphaFold的最新版本,在通过氨基酸序列精确预测蛋白质折叠结构方面,已经获得权威蛋白质结构预测评估机构(Critical Assessment of protein Structure Prediction,CASP)的认可。
此消息一出,立刻登上了Nature杂志封面,标题直接评论为:“它将改变一切!”。
同一时间,谷歌CEO兼首席执行官桑达尔·皮查伊 (Sundar Pichai)、斯坦福教授李飞飞、马斯克等众多科技大佬也在第一时间转推祝贺!
那么这场惊动科技圈、生物学界和科学界的重大突破,到底是一项怎样的研究?
AlphaFold背后的AI机制
折叠的蛋白质可以看作是一个“空间图形”,其中残基是节点和边紧密连接在一起。
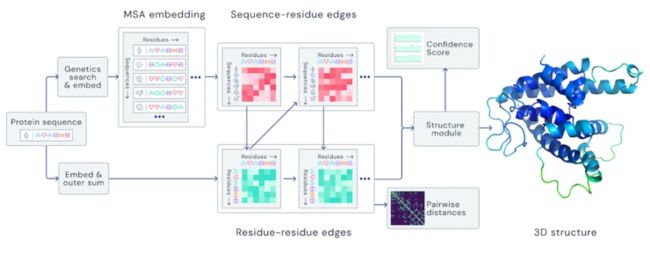
该图代表了AlphaFold系统的神经网络模型体系结构。该模型对蛋白质序列和氨基酸残基进行操作——在两种表示之间传递迭代信息以生成结构。
这一过程对于理解蛋白质内部的物理相互作用以及它们的进化史很重要。
对于AlphaFold的最新版本,研究人员创建了一个基于注意力机制的神经网络系统,经过端到端的训练来试图解释这个图的结构,同时对它所构建的隐式图进行推理。它通过使用多重序列对齐 (MSA) 和氨基酸残基对的表示来精化这个图形结构。
通过迭代这个过程,系统可以对蛋白质的基本物理结构做出准确的预测,并能够在几天的时间内确定高度精确的结构。此外,AlphaFold 还可以使用内部置信度来预测每个预测的蛋白质结构的哪些部分是可靠的。
AlphaFold系统所使用的数据,来自包括约170,000个蛋白质结构,以及未知结构的蛋白质序列的大型数据库。在训练时,它使用了大约128个 TPU v3内核 (大致相当于100-200个GPU) ,并仅运行了数周。这在当今机器学习中使用的大多数最先进的大型模型的上下文中是相对较小的计算量。
4.2 Edge级别的Graph机器学习实例
-
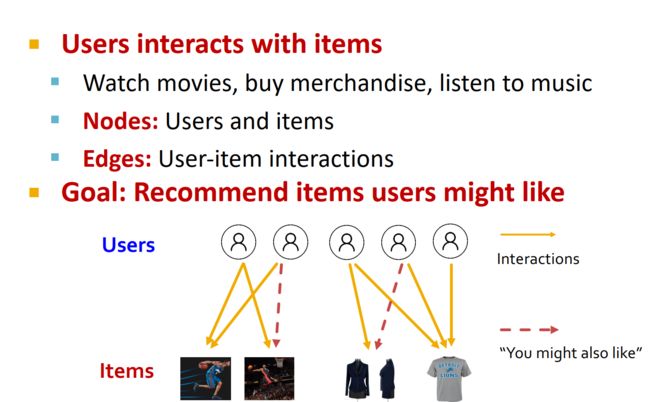
基于社交网络的推荐系统
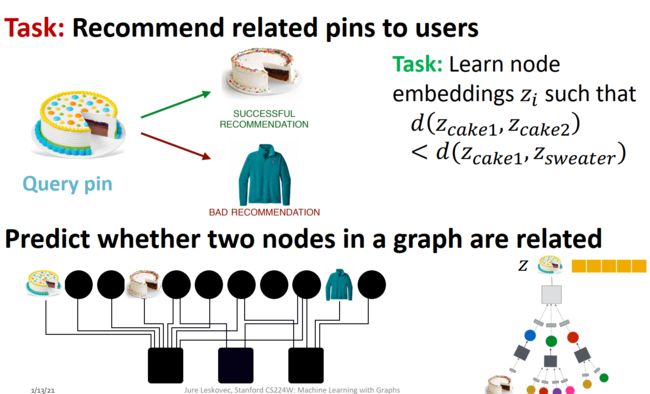
基于商品节点表示推荐相似商品
- 药物的副作用预测
很多病人同时吃多种药物来治疗复杂的或者并发症,研究调查发现: - 在70-79岁之间病人有46%的 人会摄入超过5种药物
- 很多病人会同时摄入20多种药物来治疗心脏病,抑郁症,失眠等症状;
任务:假设有一对药物,然后预测两者之间的不良副作用
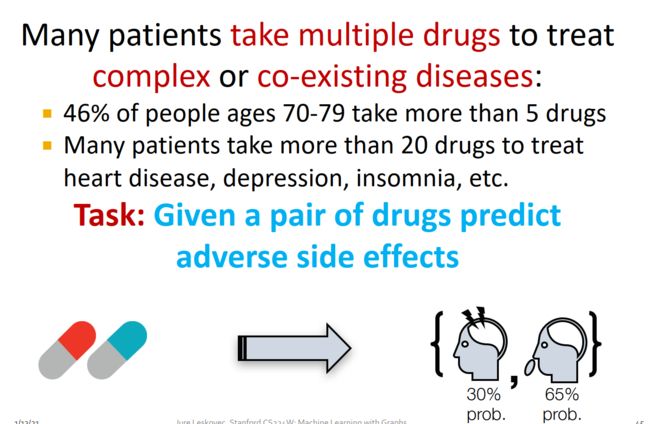
例如:辛伐他汀(Simvastatin)和环丙沙星(Ciprofloxacin)合在一起时分解肌肉组织的可能性有多大
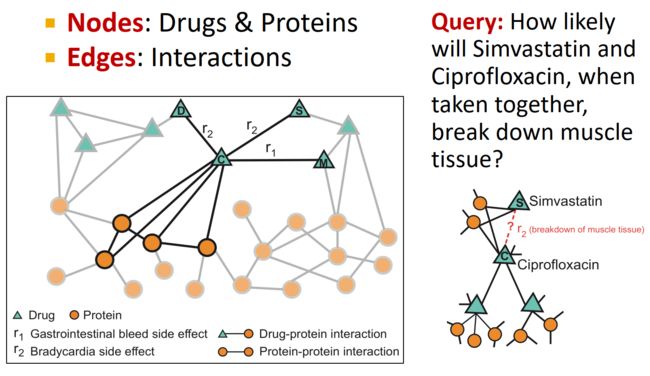
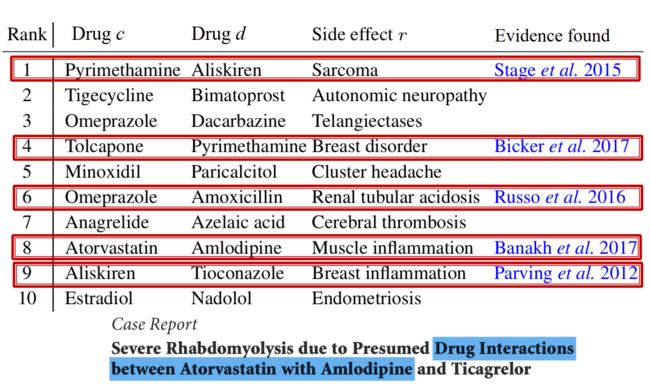
通过实验结果可以发现:
阿托伐他汀与氨氯地平和替卡格雷的药物相互作用可能导致严重的横纹肌溶解
4.3 Subgraph级别的Graph机器学习实例
- 交通预测
随着图网络的发展,其在非欧氏数据上的应用被进一步开发,而交通预测就是图网络的一个主要应用领域。交通预测指的是根据历史交通数据和交通网络的拓扑结构来预测未来的交通状况,包括但不限于速度、流量、拥堵等。交通流量预测是其他上层任务如路径规划的基础,是工业界非常关心的任务。
原文:https://blog.csdn.net/zhouchen1998/article/details/110136808
class ChebConv(nn.Module):
def __init__(self, in_c, out_c, K, bias=True, normalize=True):
"""
ChebNet conv
:param in_c: input channels
:param out_c: output channels
:param K: the order of Chebyshev Polynomial
:param bias: if use bias
:param normalize: if use norm
"""
super(ChebConv, self).__init__()
self.normalize = normalize
self.weight = nn.Parameter(torch.Tensor(K + 1, 1, in_c, out_c)) # [K+1, 1, in_c, out_c]
init.xavier_normal_(self.weight)
if bias:
self.bias = nn.Parameter(torch.Tensor(1, 1, out_c))
init.zeros_(self.bias)
else:
self.register_parameter("bias", None)
self.K = K + 1
def forward(self, inputs, graph):
"""
:param inputs: he input data, [B, N, C]
:param graph: the graph structure, [N, N]
:return: convolution result, [B, N, D]
"""
L = ChebConv.get_laplacian(graph, self.normalize) # [N, N]
mul_L = self.cheb_polynomial(L).unsqueeze(1) # [K, 1, N, N]
result = torch.matmul(mul_L, inputs) # [K, B, N, C]
result = torch.matmul(result, self.weight) # [K, B, N, D]
result = torch.sum(result, dim=0) + self.bias # [B, N, D]
return result
def cheb_polynomial(self, laplacian):
"""
Compute the Chebyshev Polynomial, according to the graph laplacian
:param laplacian: the multi order Chebyshev laplacian, [K, N, N]
:return:
"""
N = laplacian.size(0) # [N, N]
multi_order_laplacian = torch.zeros([self.K, N, N], device=laplacian.device, dtype=torch.float) # [K, N, N]
multi_order_laplacian[0] = torch.eye(N, device=laplacian.device, dtype=torch.float)
if self.K == 1:
return multi_order_laplacian
else:
multi_order_laplacian[1] = laplacian
if self.K == 2:
return multi_order_laplacian
else:
for k in range(2, self.K):
multi_order_laplacian[k] = 2 * torch.mm(laplacian, multi_order_laplacian[k - 1]) - \
multi_order_laplacian[k - 2]
return multi_order_laplacian
@staticmethod
def get_laplacian(graph, normalize):
"""
compute the laplacian of the graph
:param graph: the graph structure without self loop, [N, N]
:param normalize: whether to used the normalized laplacian
:return:
"""
if normalize:
D = torch.diag(torch.sum(graph, dim=-1) ** (-1 / 2))
L = torch.eye(graph.size(0), device=graph.device, dtype=graph.dtype) - torch.mm(torch.mm(D, graph), D)
else:
D = torch.diag(torch.sum(graph, dim=-1))
L = D - graph
return L
class ChebNet(nn.Module):
def __init__(self, in_c, hid_c, out_c, K):
"""
:param in_c: int, number of input channels.
:param hid_c: int, number of hidden channels.
:param out_c: int, number of output channels.
:param K:
"""
super(ChebNet, self).__init__()
self.conv1 = ChebConv(in_c=in_c, out_c=hid_c, K=K)
self.conv2 = ChebConv(in_c=hid_c, out_c=out_c, K=K)
self.act = nn.ReLU()
def forward(self, data, device):
graph_data = data["graph"].to(device)[0] # [N, N]
flow_x = data["flow_x"].to(device) # [B, N, H, D]
B, N = flow_x.size(0), flow_x.size(1)
flow_x = flow_x.view(B, N, -1) # [B, N, H*D]
output_1 = self.act(self.conv1(flow_x, graph_data))
output_2 = self.act(self.conv2(output_1, graph_data))
return output_2.unsqueeze(2)
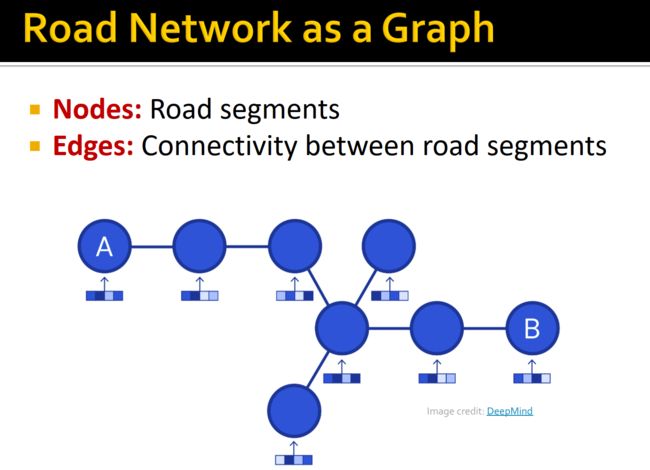
其中图构成了网络
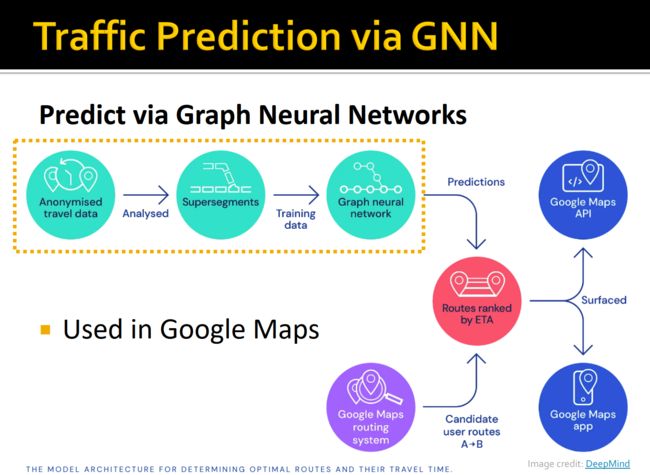
扩展阅读: 两篇图神经网络交通预测 |A3T-GCN:用于交通预测的注意力时间图卷积网络 https://zhuanlan.zhihu.com/p/162815713
4.4 Graph级别的机器学习任务
- 药物发现
1)基于自回归流模型的分子图生成模型—— GraphAF
GraphAF是一种新颖的分子图生成模型,不仅在数据密度估计上具有高度的模型灵活性,而且支持训练高效的并行计算。采取迭代采样,在生成过程中加入有效性检测以保证生成的化学分子真实、有效。
2)可以预测分子逆合成路线的模型——G2Gs
G2Gs是第一个基于图且不依赖于反应模版的逆合成预测方法,在接近或达到最先进方法表现的情况下,避免了反应模版和昂贵的子图同构,且具有更好的可扩展性。

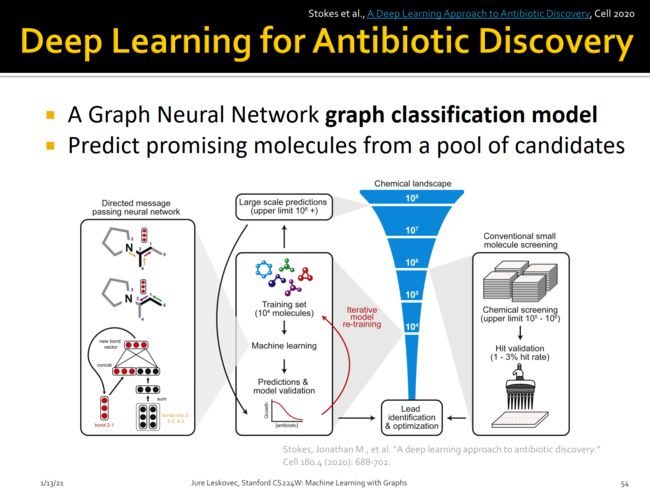
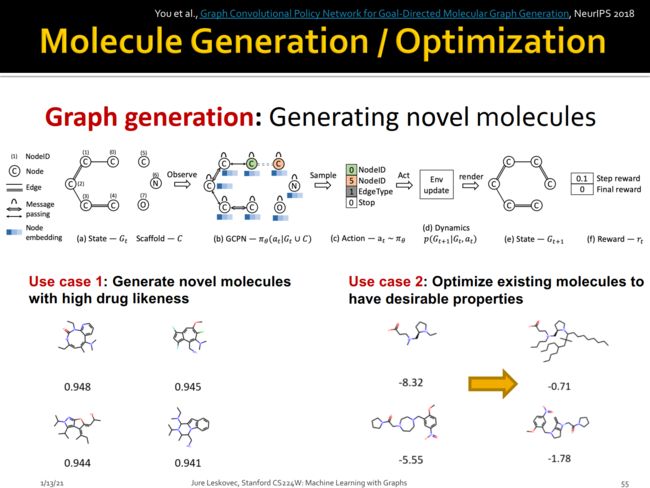
扩展阅读:
AI+医疗:图表示学习在新药发现中的妙用 https://www.aminer.cn/research_report/5f5974b71f22880f6e944ca4
特别评述 | 人工智能助力药物研发:可解释性深度神经网络分子表征模型
http://www.phirda.com/artilce_20712.html?cId=3
Survey | 基于图卷积网络的药物发现方法 https://www.jiqizhixin.com/articles/2019-09-04-13