机器学习笔记1(主要内容可视化)
机器学习笔记1(主要内容可视化)
(只是学习笔记,里面的批注都是我当时的总结,不一定准确,如果广大网友愿意批评指出,那真是再好不过,谢谢你们!)
重要概念:离网率(Churn)是指放弃目前所使用网络(移动、联通、网通等业务产品)的用户数量占该网络全部用户数量的比例,也可以说是客户流失率。
(一)单变量可视化
1.直方图:关键词“柱”“高斯分布”
hist()
features = [‘Total day minutes’, ‘Total intl calls’]
df[features].hist(figsize=(10, 4)),10和4表示图的宽和高
2.密度图
plot():
df[features].plot(kind=‘density’, subplots=True, layout=(1, 2),
sharex=False, figsize=(10, 4), legend=False, title=features)
总结:displot()可以同时显示直方图和密度图
3.箱型图和提琴型图
箱型图:sns.boxplot(x=‘Total intl calls’, data=df)
提琴形图:_, axes = plt.subplots(1, 2, sharey=True, figsize=(6, 4))
sns.boxplot(data=df[‘Total intl calls’], ax=axes[0])
**sns.violinplot(**data=df[‘Total intl calls’], ax=axes[1])
4.频率表(value_counts() )和countplot()
频率表的图形化表示是条形图
plt.subplot(nrows, ncols, index, **kwargs)位置是由三个整型数值构成,第一个代表行数,第二个代表列数,第三个代表索引位置。举个列子:plt.subplot(2, 3, 5) 和 plt.subplot(235) 是一样一样的。需要注意的是所有的数字不能超过10。
条形图和直方图的区别如下:
直方图适合查看数值变量的分布,而条形图用于查看类别特征。
直方图的 X 轴是数值;条形图的 X 轴可能是任何类型,如数字、字符串、布尔值。
直方图的 X 轴是一个笛卡尔坐标轴;条形图的顺序则没有事先定义!
数据描述
除图形工具外,还可以使用 DataFrame 的 describe() 方法来获取分布的精确数值统计。
类别特征和二元特征
df[features].describe()
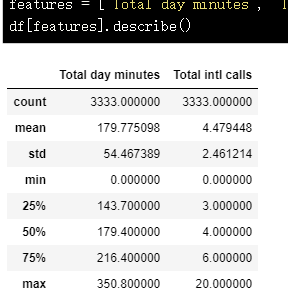

类别特征和二元特征
类别特征(categorical features take)反映了样本的某个定性属性,它具有固定数目的值,每个值将一个观测数据分配到相应的组,这些组称为类别(category)。如果类别变量的值具有顺序,称为有序(ordinal)类别变量。
自己的理解(不一定准确):一个属性具有多个值,根据这多个值可以划分不同组,而这些不同的组就叫类别
频率表
df[‘Churn’].value_counts()
copy
copy
上表显示,该数据集的 Churn 有 2850 个属于 False(Churn0),有 483 个属于 True(Churn1)

(二)多变量可视化
相关矩阵
多变量(multivariate)图形可以在单张图像中查看两个以上变量的联系
DataFrame.corr(method = ‘pearson’,min_periods = 1)[资源]
计算列的成对相关,不包括NA /空值。
numerical = list(set(df.columns) -
set([‘State’, ‘International plan’, ‘Voice mail plan’,
‘Area code’, ‘Churn’, ‘Customer service calls’]))#丢弃非数值变量
corr_matrix = df[numerical].corr()#计算相关性
sns.heatmap(corr_matrix)#绘制色彩编码
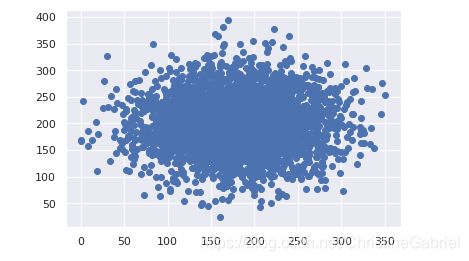
散点图
通过 matplotlib 库的 scatter() 方法可以绘制散点图。
plt.scatter(df[‘Total day minutes’], df[‘Total night minutes’])
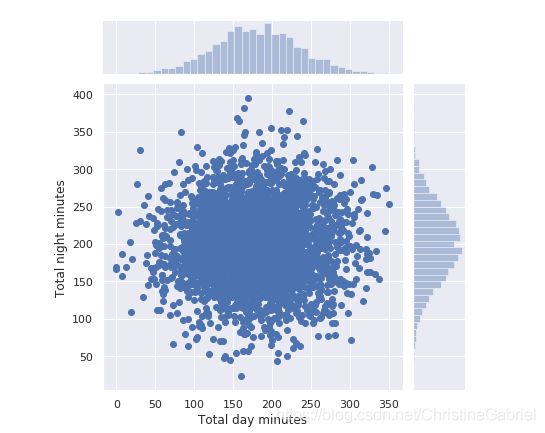
seaborn 库的 jointplot() 方法在绘制散点图的同时会绘制两张直方图,某些情形下它们可能会更有用。
sns.jointplot(x=‘Total day minutes’, y=‘Total night minutes’,
data=df, kind=‘scatter’)
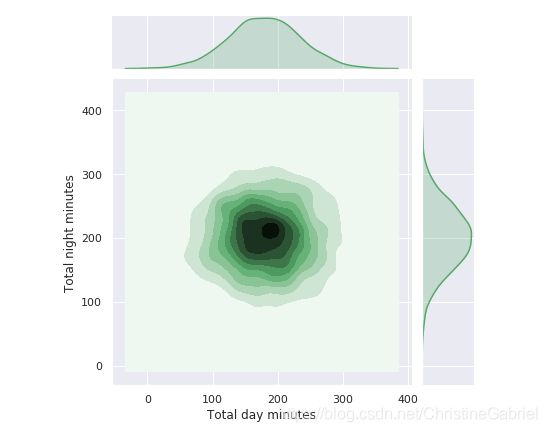
jointplot() 方法还可以绘制平滑过的散点直方图。
sns.jointplot(‘Total day minutes’, ‘Total night minutes’, data=df,
kind=“kde”, color=“g”)
散点图矩阵
在某些情形下,我们可能想要绘制如下所示的散点图矩阵(scatterplot matrix)。它的对角线包含变量的分布,并且每对变量的散点图填充了矩阵的其余部分。
数量和类别
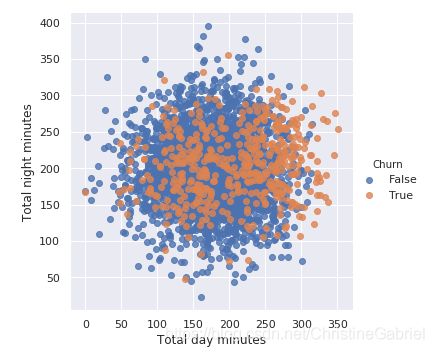
让我们看看输入变量和目标变量 Churn 的关系。使用 lmplot() 方法的 hue 参数来指定感兴趣的类别特征。
sns.lmplot(‘Total day minutes’, ‘Total night minutes’,
data=df, hue=‘Churn’, fit_reg=False)
numerical.append(‘Customer service calls’)
seaborn.lmplot用来拟合数据集的条件子集之间的回归模型
catplot(): 用分类型数据(categorical data)绘图
当想要一次性分析两个类别维度下的数量变量时
catplot()
sns.catplot(x=‘Churn’, y=‘Total day minutes’, col=‘Customer service calls’,
data=df[df[‘Customer service calls’] < 8], kind=“box”,
col_wrap=4, height=3, aspect=.8)
用参数 col_wrap, 指定每排展示的个数.
col参数, 指定某一切面来考察数据
aspect :每个面的纵横比,因此Aspect*height给出了每个面的宽度(以英寸为单位)。
类别与类别
变量 Customer service calls 客服呼叫数 的重复值很多,因此,既可以看成数值变量,也可以看成有序类别变量。现在我们感兴趣的是这一有序特征和目标变量 Churn 离网率 之间的关系。
使用 countplot() 方法查看客服呼叫数的分布,这次传入 hue=Churn 参数,以便在图形中加入类别维度。
批注:其实就是观察Churn和customer service calls 的关系。Churn可以看作是图例
sns.countplot(x=‘Customer service calls’, hue=‘Churn’, data=df)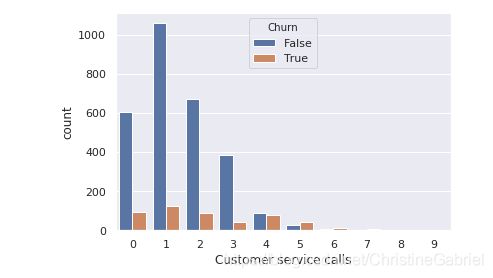
subplot()子图
交叉表
通过它可以查看某一列或某一行以了解某个变量在另一变量的作用下的分布情况。
pd.crosstab(df[‘State’], df[‘Churn’])

而我们在最一开始的五行实例表中只能看到州名,离网率的true/false情况,而使用交叉表**crosstab()**可以具体看到每个州对于Churn的true/false的人数分布情况

表显示,State 州 有 51 个不同的值,并且每个州只有 3 到 17 个客户抛弃了运营商。通过 groupby() 方法计算每个州的离网率,由高到低排列。
df.groupby([‘State’])[‘Churn’].agg(
[np.mean]).sort_values(by=‘mean’, ascending=False).T
*分析一下这行代码:
agg():*不管是身高和还是平均值 我们都是进行列操作的 即我们是从上至下加起来的 而不是从左到右。为了计算简便 我们引入了agg函数。groupby函数是基于行操作的 而agg是基于列操作的
sort_values()函数:DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)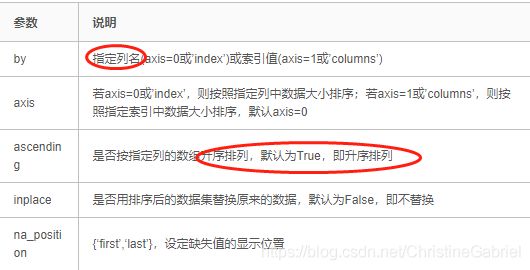
.T:转置:把行变成列,反之亦然
全局数据集可视化:一次性显示所有特征
降维:
主成分分析:
t-SNE:一个实例
引入:
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
去除 State 州 和 Churn 离网率 变量按列删除)
然后用 pandas.Series.map() 方法将二元特征的「Yes」/「No」转换成数值:
X = df.drop([‘Churn’, ‘State’], axis=1)
X[‘International plan’] = X[‘International plan’].map({‘Yes’: 1, ‘No’: 0})
X[‘Voice mail plan’] = X[‘Voice mail plan’].map({‘Yes’: 1, ‘No’: 0})
axis=0代表往跨行(baidown),而axis=1代表跨列
使用 StandardScaler() 方法来完成归一化数据
归一化:每个变量中减去均值,然后除以标准差:scaler = StandardScaler()
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
*transform函数是一定可以替换为fit_transform函数的,fit_transform函数不能替换为transform函数!这俩函数的运行结果是一样的。**fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式。即tranform()的作用是通过找中心和缩放等实现标准化。
现在可以构建 t-SNE 表示了:
tsne = TSNE(random_state=17)
tsne_repr = tsne.fit_transform(X_scaled)
**random_state=17:这是一个随机数
之所以会这样,是因为模型的构建、数据集的生成、数据集的拆分都是一个随机的过程
然后以图形的方式可视化。固定random_state后,每次构建的模型是相同的、生成的数据集是相同的、每次的拆分结果也是相同的。random_state 相当于 random.seed,也就是随机种子,这个值你可以设置成任意整数(17,18,100…都无所谓),它
**
plt.scatter(tsne_repr[:, 0], tsne_repr[:, 1], alpha=.5)

这里的下,x,y也就是上面代码的tsne_repr[:, 0], tsne_repr[:, 1]。要求x,y形如数组
StandardScaler----计算训练集的平均值和标准差,以便测试数据集使用相同的变换
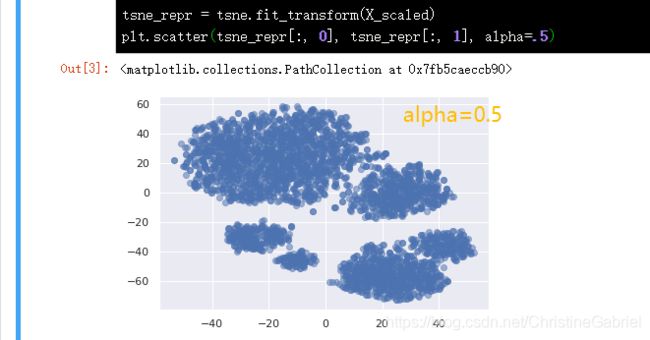

alpha=1明显更“重”
**补充一点关于切片的总结:**以列表a=[0,1,2,3,4,5,6,7,8,9]为例。**切片操作基本表达式:object[start_index:end_index:step]参数解释:**左闭右开,步长为负意为从右到左,步长为正意为从左到右。把起点终点投影到数轴上,看是否和步长方向一致,一致可以输出,不一致什么都不输出。
plt.scatter(tsne_repr[:, 0], tsne_repr[:, 1],
c=df[‘Churn’].map({False: ‘blue’, True: ‘orange’}), alpha=.5)
根据离网情况给 t-SNE 表示加上色彩(蓝色表示忠实用户,黄色表示不忠实用户),形成离网情况散点图。
_, axes = plt.subplots(1, 2, sharey=True, figsize=(12, 5))
for i, name in enumerate([‘International plan’, ‘Voice mail plan’]):
axes[i].scatter(tsne_repr[:, 0], tsne_repr[:, 1],
c=df[name].map({‘Yes’: ‘orange’, ‘No’: ‘blue’}), alpha=.5)
axes[i].set_title(name)
fig, ax = plt.subplots(figsize = (a, b))解析 与 plt.subplot()函数解析fig, ax = plt.subplots(figsize = (a, b))解析 与 plt.subplot()函数解析区别
[有关subplots()的介绍]:(https://blog.csdn.net/Leeoo_lyq/article/details/103146591?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control)
可以看到,离网客户集中在低维特征空间的一小部分区域。为了更好地理解这一图像,可以使用剩下的两个二元特征,即 International plan 国际套餐 和 Voice mail plan 语音邮件套餐 给图像着色,蓝色代表二元特征的值为 Yes,黄色代表二元特征的值为 No。
_, axes = plt.subplots(1, 2, sharey=True, figsize=(12, 5))
for i, name in enumerate([‘International plan’, ‘Voice mail plan’]):
axes[i].scatter(tsne_repr[:, 0], tsne_repr[:, 1],
c=df[name].map({‘Yes’: ‘orange’, ‘No’: ‘blue’}), alpha=.5)
axes[i].set_title(name)
t-SNE 的缺陷。
计算复杂度高。如果你有大量样本,你应该使用 Multicore-TSNE。
随机数种子的不同会导致图形大不相同,这给解释带来了困难。通常而言,你不应该基于这些图像做出任何决定性的结论,因为它可能和单纯的猜测差不多。当然,t-SNE 图像中的某些发现可能会启发一个想法,这个想法可以通过更全面深入的研究得到确认。