python 机器学习介绍
此文章暂停更新,更多关于python机器学习的内容转至《机器学习》西瓜书 算法代码 python实现
这篇文章就用来介绍了。
目录
- 如何学?
- 常见算法分类
- 已在其他笔记中记过的算法及其补充
-
- kNN
- 决策树算法
-
- 构建流程
-
-
- 一、准备工作
-
- 信息熵
- 二、选择特征
-
- 信息增益
- 选择特征
- 三、创建分支
- 四、是否终止
- 五、结果生成
-
- ID3 系列算法和其他算法
- Apriori 算法
-
- 构建流程
- 半监督学习介绍
- 集成学习介绍
-
- AdaBoost
- 随机森林(RandomForest)
- 其他机器学习介绍
- 机器学习的基本概念
-
- 机器学习方法流程
- 一些概念
- 机器学习方法三要素
-
- 策略
-
- 常用损失函数
- 风险
- 模型评估与选择
-
- 一些概念
- 评估方法
- 性能度量
- 模型检验
-
- 比较检验
- 假设检验
-
- 步骤
- 偏差与方差
-
- 偏差、方差与噪声
- 泛化误差组成推导
- 回归分析
-
- 建立回归模型
- 回归模型的优缺点
- 一元线性回归
如何学?
- 学会原理
- 会用工具(例如 python 机器学习库)
- 能自己实现算法
- 会优化,能根据需求定制算法
常见算法分类
- 有监督学习
- 分类算法
- 基于统计的:贝叶斯分类(NB 朴素贝叶斯)
- 基于规则的:DT(决策树)
- 基于神经网络的:神经网络算法
- 基于距离的:kNN(k最邻近)
- SVM(支持向量机)
- …
- 回归算法
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression)
- 岭回归(Ridge Regression)
- 拉索回归(LASSO Regression)
- …
- 分类算法
- 无监督学习
- 聚类
- 层次聚类
- 划分聚类(k-Means)
- 基于密度的聚类 (DBSCAN)
- EM(最大期望)
- 降维(PCA,PLS 偏最小二乘回归,MDS 多维尺度分析)
- …
- 关联规则学习
- Apriori
- Eclat
- …
- 聚类
- 半监督学习
- 半监督分类
- 半监督回归
- 半监督聚类
- 半监督降维
- …
- 集成学习
- Bagging
- Boosting
- Stacking
- …
- 深度学习
- 受限玻尔兹曼机 RBM(Restricted Boltzmann Machine)
- 深度信念网络 DBN(Deep Belief Networks)
- 卷积网络(Convolutional Network)
- 栈式自编码(Stacked Auto-encoders)
- …
- 强化学习/增强学习
- Q-Learning
- 时间差学习(Temporal Difference Learning)
- …
- 迁移学习
- …
已在其他笔记中记过的算法及其补充
这些算法因为已经在我其他笔记中提到了,就不重新写了,只做补充:
kNN,k-Means,DBSCAN
分类算法常用评估指标
- 精确率(Precision):被分为正例的示例中实际为正例的比例
- 召回率(recall):所有正例中被分对的比例,衡量了分类器对正例的识别能力
- 综合评价指标:F1-Score: 2 ∗ P ∗ R P + R \frac{2*P*R}{P+R} P+R2∗P∗R
- ROC 曲线
kNN
优点:
- 原理简单,容易理解,容易实现
- 聚类结果容易解释
- 聚类结果相对较好
缺点:
- 分类个数 k 需要事先指定,且指定的 k 值不同,聚类结果相差较大
- 初始的 k 个类簇中心对最终结果有影响,选择不同,结果可能会不同
- 能识别的类簇仅为球状,非球状的聚类效果很差
- 样本点较多时,计算量较大
- 对异常值敏感,对离散值需要特殊处理
决策树算法
决策树,即根据样本的特征,构建一棵树,每个分支都代表某个特征的不同取值,叶子结点即为类别。
例如,现在要将已知性别、年龄、经济状况的一组人,判断其是否能成为目标客户,可构建如下决策树:
注:这部分在 阿里云大学-人工智能学习路线-机器学习概览即常用算法-课时9 中讲得特别好
构建流程
构建流程指如何用已知样本生成决策树。生成决策树后如何去应用是简单的。
一、准备工作
- 明确自变量和因变量
- 自变量
- 因变量
- 确定信息度量的方式
- 熵
- 基尼系数
- 确定终止条件
- 纯度
- 记录条数
- 循环次数
信息熵
描述混乱程度的度量,取值范围0~1,值越大越混乱
H ( U ) = E [ − log p i ] = − ∑ i = 1 n p i log 2 p i H(U) = E[-\log p_i] =- \sum_{i=1}^{n}{p_i\log_2{p_i}} H(U)=E[−logpi]=−i=1∑npilog2pi
二、选择特征
得到当前待处理子集,计算所有信息特征度量,得到当前最佳分类特征
信息增益
- 信息增益指从一个状态到另一个状态信息的变化(信息度量的差)
- 信息增益一定是增加的
- 信息增益越大,对确定性贡献越大
见下例,信息度量方式为熵:
| 名称 | 颜色 | 味道 | 是否是水果 |
|---|---|---|---|
| 西红柿 | 红色 | 不甜 | 否 |
| 黄瓜 | 绿色 | 不甜 | 否 |
| 苹果 | 红色 | 甜 | 是 |
| 提子 | 红色 | 甜 | 是 |
不考虑特征值,直接估计是否为水果的熵:
E = − 2 4 ∗ log 2 ( 2 4 ) − 2 4 ∗ log 2 ( 2 4 ) = 1 E = -\frac{2}{4}*\log_2{(\frac{2}{4})}-\frac{2}{4}*\log_2{(\frac{2}{4})}=1 E=−42∗log2(42)−42∗log2(42)=1
考虑以颜色为参考信息,估计是否为水果的熵:
E = − 3 4 ∗ ( − 2 3 ∗ log 2 ( 2 3 ) − 1 3 ∗ log 2 ( 1 3 ) ) + 1 4 ∗ ( − 1 ∗ log 2 1 ) = 0.689 E = -\frac{3}{4}*(-\frac{2}{3}*\log_2{(\frac{2}{3})} -\frac{1}{3}*\log_2{(\frac{1}{3})})+\frac{1}{4}*( -1*\log_2{1})=0.689 E=−43∗(−32∗log2(32)−31∗log2(31))+41∗(−1∗log21)=0.689
考虑以味道为参考信息,估计是否为水果的熵:
E = 2 4 ∗ ( − 1 ∗ log 2 1 ) + 2 4 ∗ ( − 1 ∗ log 2 1 ) = 0 E = \frac{2}{4}*( -1*\log_2{1})+\frac{2}{4}*( -1*\log_2{1})=0 E=42∗(−1∗log21)+42∗(−1∗log21)=0
可计算出,颜色和味道的信息增益分别为:
颜 色 : 1 − 0.689 = 0.311 颜色:1-0.689=0.311 颜色:1−0.689=0.311
味 道 : 1 − 0 = 1 味道:1-0=1 味道:1−0=1
说明味道提供的有效信息更多
选择特征
计算当前每一个特征的信息增益,选择信息增益最大的特征作为当前最佳特征
三、创建分支
根据选中特征将当前记录分成不同分支,分支个数取决于算法
例如上例中,确认味道为最佳特征,那么第一级特征选择就为味道,第一层分支就为甜和不甜两个分支。原来的记录(已知样本)分别分配给每个分支。
四、是否终止
判断是否满足终止条件,满足则退出循环,不满足则继续递归调用
例如上例中,已经确定第一层分支,针对每个分支,若已经可以判断是否是水果,则分支到此为止。若认为还不足以判断是否是水果,则在每个分支下,分别计算出新的最佳特征,得到第二层分支。
- 纯度:若当前分支下每条记录的分类结果均一致或一致性足够高,则终止
- 记录条数:若当前分支下记录条数小于某一给定值,则终止
- 循环次数:若当前分支循环次数大于某以给定值,则终止
五、结果生成
判断是否需要剪枝,需要则进行适当修剪,不需要则为最终结果
ID3 系列算法和其他算法
以上提到的用信息熵计算信息增益,根据信息增益决定树的结点的算法,叫 ID3(迭代树三代)算法。
该算法存在如下问题:
- 信息度量不合理:倾向于选择取值多的字段
- 输入类型单一:离散型
- 不做剪枝,容易过拟合
之后出现改进算法 C4.5
- 用信息增益率代替信息增益
- 能对连续属性进行离散化,对不完整数据进行处理
- 进行剪枝
之后又出现改进算法 C50
- 使用了 boosting
- 前修剪,后修剪
ID3 系列算法的核心是信息熵,且其树结构是多叉树。
还有一种算法是 CART(分类回归树),可用于分类和回归
- 核心是基尼系数(Gini)
- 分类是二叉树
- 后剪枝进行修剪
- 支持回归,可以预测连续值
Apriori 算法
关联分析是一种在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:频繁项集或者关联规则。
- 关联规则是反映事物与事物间相互的依存关系和关联性。如果两个或多个事物间存在一定的关联关系,则其中一个事物能够通过其他事物预测到。最常见的场景就是购物篮分析,通过分析顾客购物篮中不同商品之间的关系,来分析顾客的购买习惯。经典案例就是啤酒与尿布。
- 频繁项集是经常出现在一块的物品的集合。
频繁项集需要建立两个概念:支持度和置信度
- 支持度:定义为数据集中包含该项集的记录所占的比例
- 置信度:是针对一条诸如{尿布} ➞ {啤酒}的关联规则来定义的。这条规则的置信度被定义为“支持度({尿布, 啤酒})/支持度({尿布})”。即,数据集中在某些商品确定的情况下,某一商品的支持度。
构建流程
以下表数据集为例:
| 流水号 | 购买商品 |
|---|---|
| 1001 | A、C、D |
| 1002 | B、C、E |
| 1003 | A、B、C、E |
| 1004 | B、E |
- 确定最小支持度和最小置信度(例如50%,50%)
- 根据最小支持度确定 1-频繁项集 {A}: 50%,{B}: 75%,{C}: 75% ,{E}: 75%
- 在 1-频繁项集基础上生成 2-频繁项集,并根据最小支持度筛选出:
{A,C}: 50%,{B,C}: 50%,{B,E}: 75%,{C,E}: 50% - 在 2-频繁项集基础上生成 3-频繁项集,并根据最小支持度筛选出:{B,C,E}: 50%
- …
- 针对每一个频繁项集,先求出其所有真子集,其真子集到余集的规则的置信度等于该频繁项集的支持度除以真子集的支持度,筛选出所有置信度大于最小置信度的规则,即为训练最终结果。
- 设集合M、N,则规则 M -> N 的支持度为 M 的支持度,规则 M -> N 的置信度为 M∪N 的支持度除以 M 的支持度。
| 规则 | 支持度 | 置信度 |
|---|---|---|
| {A} -> {C} | 50% | 100% |
| {C} -> {A} | 75% | 66.7% |
| {B} -> {C} | 75% | 66.7% |
| {C} -> {B} | 75% | 66.7% |
| {B} -> {E} | 75% | 100% |
| {E} -> {B} | 75% | 100% |
| {C} -> {E} | 75% | 66.7% |
| {E} -> {C} | 75% | 66.7% |
| {B} -> {C,E} | 75% | 66.7% |
| {C} -> {B,E} | 75% | 66.7% |
| {E} -> {B,C} | 75% | 66.7% |
| {B,C} -> {E} | 50% | 100% |
| {B,E} -> {C} | 75% | 66.7% |
| {C,E} -> {B} | 50% | 100% |
- 若认为当前设定最小支持度、最小置信度下规则数过多或过少,则需要进行调参
半监督学习介绍
训练数据有部分被标识,部分没有被标识,这种模型首先需要学习数据的内在结构,以便合理的组织数据来进行预测。旨在避免数据和资源的浪费,解决监督学习模型泛化能力不强、无监督学习的模型不精确等问题。
- 半监督分类:在无类标签的样例帮助下训练有类标签的样本,弥补有类标签的样本不足的缺陷(因为实际中样本往往需要人工定标签)
- 半监督回归:在无输出的输入的帮助下训练有输出的输入,获得性能更好的回归器
- 半监督聚类:在有类标签的样本的信息帮助下获得比只用无类标签的阳历得到的结果更好的簇
- 半监督降维:在有类标签的样本的信息帮助下找到高维输入数据的低维结构,同时保持原始高维数据和成对约束的结构不变
半监督学习的实现方法是,先训练有类标签的样本,得到的学习机去预测无标签的样本,取其中预测结果较好的样本作为新的有类标签的样本,重新训练得到新的学习机,再去预测无标签的样本,以此类推。
集成学习介绍
针对同一数据集,训练多种学习器,来解决同一问题
- Bagging(Bootstrap aggregating)
- 有放回抽样构建多个子集(对原数据集采用 Bootstrap 抽样)
- 训练多个分类器
- 最终结果由各分类器结果投票得出
- 实现非常简单
- Boosting
- 重复使用一类学习器
- 每次训练后根据结果调整样本的比重
- 每个样本进行不同次加权后,分别训练的结果的线性组合即为最终结果
- Stacking
- 由两级组成,第一级为初级学习器,第二级为高级学习器
- 第一级学习器的输出作为第二级学习器的输入
AdaBoost
每次训练后,将结果错误的样本的权重增大,再进行训练
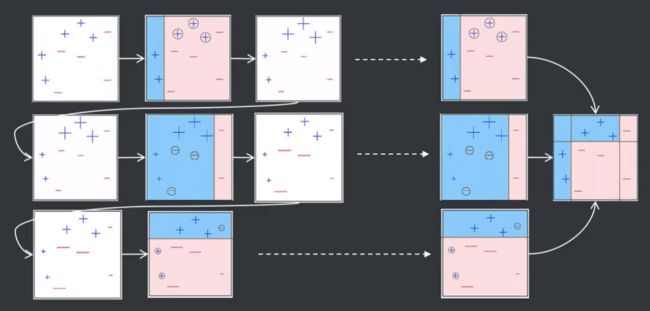
随机森林(RandomForest)
- 由许多决策树组成,树生成时采用了随机的方法
- Smart Bagging(抽样时除了对样本抽样外还对特征进行抽样)
- 生成步骤
- 随机采样,生成多个样本集
- 对每个样本集构建决策树(构建决策树时也可采用不同的算法)
- 最后使用投票模型输出结果
- 优点
- 可以处理多分类
- 很大程度上避免过拟合
- 容易实现并行
- 对数据集容错能力强
其他机器学习介绍
- 深度学习
- 源于人工神经网络的研究,含多隐藏层的多层感知器就是一种深度学习结构
- 通过组合底层特征形成更加抽象的高层标识属性类别或特征,以发现数据的分布式特征标识
- 属于机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本
- 强化学习
- 一个能感知环境的自治 agent,通过学习,选择能达到其目标的最优动作
- 本质就是解决“决策(decision making)问题,即学会自动进行决策,比如控制移动的机器人、在工厂中学习最优操作工序、学习棋类对弈等
- 迁移学习
- 把已训练好的模型参数迁移到新的环境来帮助新模型训练数据集
- 初衷是节省人工标注样本的时间
- 运用已有的知识来学习新的知识
- 核心是找到已有知识和新知识之间的相似性
机器学习的基本概念
机器学习方法流程
- 输入数据
- 特征工程
- 模型训练
- 模型部署
- 模型应用
一些概念
- 输入空间(Input Space):将输入的所有可能取值的集合
- 输出空间(Output Space):将输出的所有可能取值的集合
- 特征(Feature):即属性。每个输入实例的各个组成部分(属性)称作原始特征,基于原始特征还可以拓展出更多的衍生特征
- 特征向量(Feature Vector):由多个特征组成的集合
- 特征空间(Feature Space):特征向量存在的空间,模型定义在特征空间之上
- 假设:输入空间到输出空间的映射(不是一个特征向量到输出结果的映射,而是所有可能组成的特征向量到输出结果的映射的集合,称为一个假设)
- 假设空间(Hypothesis Space):由输入空间到输出空间的映射的集合(问题所有假设组成的空间)
- 例如:
输入空间:性别(男、女),年龄(成年、未成年)
输出空间:1,0
可以存在 16 个假设,再加上一个特殊的全空假设,这些假设的集合称为假设空间。(输出空间组合数的输入空间组合数次方个+1) - 这里假设空间和周志华老师西瓜书里的定义不同,西瓜书里定义为:假设每个输入特征可能取值个数为 n i n_i ni,假设空间大小为 ( n 1 + 1 ) ( n 2 + 1 ) . . . ( n i + 1 ) + 1 (n_1+1)(n_2+1)...(n_i+1)+1 (n1+1)(n2+1)...(ni+1)+1
- 例如:
- 归纳偏好:学习过程中对某种类型假设的偏好
- 奥卡姆剃刀:同等效果选取更简单的模型
机器学习方法三要素
- 模型
- 确定学习范围
- 输入空间到输出空间的映射关系。学习过程即为从假设空间中搜索适合当前数据的假设
- 策略
- 确定学习规则
- 从假设空间众多的假设中选择到最优的模型的学习标准或规则
- 算法
- 按规则在范围内学习
- 学习模型的具体的计算方法,通常是求解最优化问题
策略
要从假设空间中选择一个最合适的模型,需要解决以下问题:
- 评估某个模型对单个训练样本的效果
- 评估某个模型对训练集的整体效果
- 评估某个模型对包括训练集、测试集在内的所有数据的整体效果
定义几个指标用来衡量上述问题:
- 损失函数:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等
- 风险函数:经验风险、期望风险、结构风险
基本策略:
- 经验风险最小(ERM:Empirical Risk Minimization)
- 结构风险最小(SRM:Structural Risk Minimization)
损失函数(Loss Function)
- 用来衡量预测结果和真实结果之间的差距,其值越小,代表预测结果和真实结果越一致
- 通常是一个非负实值函数
- 通过各种方式缩小损失函数的过程被称作优化
- 损失函数记作 L ( Y , f ( x ) ) L(Y,f(x)) L(Y,f(x))
常用损失函数
-
0-1 损失函数
- 预测值和实际值精确相等则没有损失为0,否则意味着完全损失为1
- 实际可采用两者差小于某个阈值的方式
- 适用于理想模型
L ( Y , f ( x ) ) = { 1 , ∣ Y − f ( x ) ∣ ≥ T 0 , ∣ Y − f ( x ) ∣ < T L(Y,f(x))=\begin{cases} 1\text{, } &|Y-f(x)|\ge T \\ 0\text{, } &|Y-f(x)|\lt T \\ \end{cases} L(Y,f(x))={1, 0, ∣Y−f(x)∣≥T∣Y−f(x)∣<T
-
绝对值损失函数
- 预测结果与真实结果差的绝对值
- 简单易懂,但是计算不方便
-
平方损失函数
- 预测结果与真实结果差的平方
- 平方对于大误差的惩罚大于小误差
- 数学计算简单友好,导数为一次函数
- 适用于线性回归
-
对数损失函数(对数似然损失函数)
- 可将乘法转换为加法
- 适用于逻辑回归、交叉熵
L ( Y , P ( Y ∣ X ) ) = − log P ( Y ∣ X ) L(Y,P(Y|X))=-\log{P(Y|X)} L(Y,P(Y∣X))=−logP(Y∣X)
-
指数损失函数
- 适用于 AdaBoosting
L ( Y , f ( X ) ) = e − Y ∗ f ( x ) L(Y,f(X))=e^{-Y*f(x)} L(Y,f(X))=e−Y∗f(x)
- 适用于 AdaBoosting
-
折叶损失函数(Hinge LF)
- 对于判定边界附近的点的惩罚力度较高
- 适用于 SVM、soft margin
L ( f ( x ) ) = m a x ( 0 , 1 − f ( x ) ) L(f(x))=max\big(0,1-f(x)\big) L(f(x))=max(0,1−f(x))
风险
- 经验风险
- 损失函数度量了单个样本的预测结果,而经验风险衡量整个训练集的预测值与真实值的差异
- 将整个训练集的所有数据进行预测,求取损失函数,累加即为经验风险
- 经验风险越小说明模型对训练集的拟合程度越好
R e m p ( f ) = 1 N ∑ i = 1 N L ( Y , f ( x ) ) R_{emp}(f)=\frac{1}{N}\sum_{i=1}^{N}{L\big(Y,f(x)\big)} Remp(f)=N1i=1∑NL(Y,f(x))
- 风险函数(期望风险)
- 所有数据集(包括训练集和预测集,遵循联合分布 P ( X , Y ) P(X,Y) P(X,Y))的损失函数的期望值
- 期望风险是模型对全局(所有数据集)的效果,经验风险是模型对局部(训练集)的效果
- 期望风险往往无法计算,因为联合分布通常是未知的,经验风险可以计算
- 当训练集足够大时,经验风险可以替代期望风险
R e x p ( f ) = ∬ L ( Y , f ( x ) ) P ( x , y ) d x d y R_{exp}(f)=\iint{L\big(Y,f(x)\big)P(x,y)dxdy} Rexp(f)=∬L(Y,f(x))P(x,y)dxdy
注:在样本数量比较少的情况下,仅关注经验风险,很容易导致过拟合。
- 结构风险(Structural Risk)
- 在经验风险的基础上,增加一个正则化项(Regularizer)或者叫做惩罚项(Penalty Term):
R s r m ( f ) = 1 N ∑ i = 1 N L ( Y , f ( x ) ) + λ J ( f ) R_{srm}(f)=\frac{1}{N}\sum_{i=1}^{N}{L\big(Y,f(x)\big)}+\lambda J(f) Rsrm(f)=N1i=1∑NL(Y,f(x))+λJ(f) - 其中 λ \lambda λ 为一个大于0的系数, J ( f ) J(f) J(f) 表示模型 f ( x ) f(x) f(x) 的复杂度
- 正则化函数一般是模型复杂度的单调函数
- 正则化函数常用模型的参数向量的范数:
- 零范数(非零元素个数,结果会趋向于大多数项变为0,只保留极少数项)
- 一范数(各个元素绝对值之和,结果会趋向于让部分项变为0)
- 二范数(各个元素平方和求平方根,结果趋向于使每个项的系数接近于0,但一般不会等于0)
∥ x ∥ k = ∑ i = 1 N x i k k {\lVert x \rVert}_k=\sqrt[k]{\sum\nolimits_{i=1}^N{{x_i}^k}} ∥x∥k=k∑i=1Nxik - 迹范数
- Frobenius 范数
- 核范数
- …
- 在经验风险的基础上,增加一个正则化项(Regularizer)或者叫做惩罚项(Penalty Term):
模型评估与选择
一些概念
- 误差(Error)
- 是模型的预测输出值与真实值之间的差异
- 训练(Training)
- 通过已知样本数据进行学习,从而得到模型的过程
- 训练误差(Training Error)
- 模型作用于训练集时的误差
- 泛化(Generalize)
- 由具体的、个别的扩大为一般的,即从特殊到一般
- 对机器学习模型来讲,泛化是指模型作用于新的样本数据(非训练集)
- 泛化误差(Generalization Error)
- 模型作用于新的样本数据时的误差
- 模型容量(Model Capacity)
- 是指其拟合各种模型的能力
- 过拟合(Overfitting)
- 是指某个模型在训练集上表现良好,但是在新样本上表现差
- 欠拟合(Underfitting)
- 模型对训练集的一般性质学习较差,模型作用于训练集时表现不好
- 模型选择(Model Selection)
- 针对某个具体的任务,通常会有多种模型可供选择,对同一个模型也会有多种参数,可以通过分析、评估模型的泛化误差,选择泛化误差最小的模型
评估方法
使用测试集进行泛化测试,测试误差(Testing Error)即为泛化误差的近似。
测试集和训练集尽可能互斥。
测试集和训练集独立同分布。
- 留出法(Hold-out)
- 将已知数据集分为两个互斥的部分,其中一部分用来训练模型,另一部分用来测试模型,评估其误差,作为泛化误差的估计
- 单次留出法存在偶然性,需要重复实验评估,取平均值
- 训练、测试比例通常为 7:3、8:2 等
- 交叉验证法(Cross Validation)
- 将数据集划分为 k 个大小相似的互斥的数据子集,子集数据尽可能保证数据分布的一致性(分层采样),每次从中选取一个数据集作为测试集,其余用作训练集,可以进行 k 次训练和测试,得到平均估值。该验证方法也称作 k 折交叉验证(k-fold Cross Validation)
- 使用不同的划分,重复 p 次,称为 p 次 k 折交叉验证
- 留一法(Leave-One-Out,LOO)
- 交叉验证法的特殊情况,将数据集分为训练集和测试集,其中测试集只有一条数据,重复使每个数据都作为一次测试集,计算最终估计值
- 评估结果比较准确
- 缺点是当数据集较大时,训练次数和计算规模较大
- 自助法(Bootstrapping)
- 是一种产生样本的抽样方法,其实质是有放回的随机抽样
- 在所有数据集中进行若干次有放回的随机抽样并将抽到的数据加入训练集或测试集,直到训练集或测试集数据条数满足要求
- 无放回抽样引入了额外的偏差
- 包外估计(Out-of-Bag Estimate,OOB)
- 假设原始数据集有 n 条数据,用自助法生成大小为 n 的训练集,当 n 足够大时,计算可知道大约有36.8%的数据不在训练集里,将这部分数据用于测试
- 其他(也可以自己针对需求设计改善方法)
有以下经验用于选择评估方法
- 已知数据集数量充足时,通常采用留出法或交叉验证法
- 已知数据集较小且难以有效划分训练集和测试集时,采用自助法
- 已知数据集较小且可以有效划分训练集和测试集时,采用留一法
性能度量
- 性能度量(Performance Measure)
- 评价模型泛化能力的标准
- 对于不同模型,有不同的评价标准,不同的评价标准将导致不同的评价结果
- 模型的好坏是相对的,取决于对当前任务需求的完成情况
部分模型常用性能度量:
-
回归模型
- 均方误差(Mean Squared Error)
- 给定样例集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\} D={(x1,y1),(x2,y2),...,(xm,ym)},模型为 f f f ,其性能度量均方误差为:
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f;D)=\frac{1}{m}\sum_{i=1}^{m}{\big(f(x_i)-y_i\big)}^2 E(f;D)=m1i=1∑m(f(xi)−yi)2
-
分类算法
- 错误率:分类错误的样本占总样本数的比例
- 精度:分类正确的样本占总样本数的比例
- 查准率:预测结果为正的样本中,实际值也为正的比例
- 查全率:实际值为正的样本中,预测结果也为正的比例
- P-R曲线:查准率-查全率曲线,不同判断阈值对应查准率-查全率的曲线
- 当模型为根据概率来进行分类时可用,曲线变量为判断属于某一类的概率的阈值(概率大于这个值时,认为属于这一类)
- 混淆矩阵:将预测分类结果和实际分类结果做成矩阵的形式显示
- 行(第 k 列)代表预测类,列(第 k 行)代表实际类,设总类数为n,则混淆矩阵为 n×n 矩阵
- p行q列的元素代表实际类为q,预测类为p的样本个数
- F β - score F_\beta\text{ - score} Fβ - score: β \beta β 值的不同体现了对查准率、查全率的不同倾向,公式为:
( 1 + β 2 ) ∗ P ∗ R β 2 ∗ P + R \frac{(1+\beta^2)*P*R}{\beta^2*P+R} β2∗P+R(1+β2)∗P∗R - 受试者特征曲线(ROC)和曲线下面积(AUC):TPR-FPR曲线(真正例率-假正例率曲线)
- TPR,正例的样本被正确预测为正例的比例
- FPR,反例的样本中被错误预测为正例的比例
- 曲线原理同 P-R 曲线
- 代价曲线:不同类型的预测错误对结果影响不同而增加代价(cost),绘制 P ( + ) c o s t - c o s t n o r m {P(+)cost\text{ - }{cost}_{norm}} P(+)cost - costnorm 曲线
- …
-
聚类算法
- 外部指标(External Index):将聚类结果同某个参考模型进行比较
- Jaccard系数(Jaccard Coefficient,JC)
J C = a a + b + c JC=\frac{a}{a+b+c} JC=a+b+ca - FM指数(Fowlkes and Mallows Index,FMI)
F M I = a a + b ∗ a a + c FMI=\sqrt{\frac{a}{a+b}*\frac{a}{a+c}} FMI=a+ba∗a+ca - Rand指数(Rand Index,RI)
R I = 2 ( a + d ) m ( m − 1 ) RI=\frac{2(a+d)}{m(m-1)} RI=m(m−1)2(a+d)
- Jaccard系数(Jaccard Coefficient,JC)
- 内部指标(Internal Index):不使用参考模型直接考察聚类结果
- DB指数(Davise-Bouldin Index,DBI)
D B I = 1 k ∑ i = 1 k max j ≠ i ( a v g ( c i ) + a v g ( c j ) d c e n ( u i , u j ) ) DBI=\frac{1}{k}\sum_{i=1}^{k}\max_{j\neq i}({\frac{avg(c_i)+avg(c_j)}{d_{cen}(u_i,u_j)}}) DBI=k1i=1∑kj=imax(dcen(ui,uj)avg(ci)+avg(cj)) - Dunn指数(Dunn Index,DI)
D I = min 1 ≤ i ≤ k { min j ≠ i ( d m i n ( c i , c j ) max 1 ≤ l ≤ k d i a m ( c l ) ) } DI = \min_{1\le i\le k}\{{\min_{j\neq i}\big(\frac{d_{min}(c_i,c_j)}{\max_{1\le l \le k} diam(c_l)}\big)}\} DI=1≤i≤kmin{j=imin(max1≤l≤kdiam(cl)dmin(ci,cj))}
- DB指数(Davise-Bouldin Index,DBI)
- 外部指标(External Index):将聚类结果同某个参考模型进行比较
模型检验
比较检验
选择合适的评估方法和相应的性能度量,计算出性能度量后直接比较,但存在以下问题:
- 模型评估得到的是测试集上的性能,并非严格意义上的泛化性能,两者并不完全相同
- 测试集上的性能与样本选取关系很大,不同的划分,测试结果会不同,比较缺乏稳定性
- 很多模型本身有随机性,即使参数和数据集相同,其运行结果也存在差异
假设检验
- 统计假设检验(Hypothesis Test)
- 事先对总体的参数或者分布做一个假设,然后基于已有的样本数据去判断这个假设合不合理
- 基本思想:
- 从样本推断整体
- 通过反证法推断假设是否成立
- 小概率事件在一次试验中基本不会发生
- 不轻易拒绝原假设,只有小概率事件发生了,才能拒绝原假设
- 通过显著性水平定义小概率事件不可能发生的概率
- 全程命题只能被否定而不能被证明
(如果需要,可自学《商务与经济统计》)
步骤
- 建立假设
- 原假设(Null Hypothesis):搜集证据希望推翻的假设,记作 H 0 H_0 H0
- 备择假设(Alternative Hypothesis):搜集证据予以支持的假设,记作 H 1 H_1 H1
- 假设的形式:
- 双边检验: H 0 : μ = μ 0 , H 1 : μ ≠ μ 0 H_0:\mu =\mu_0,\text{ } H_1:\mu\neq\mu_0 H0:μ=μ0, H1:μ=μ0
- 左侧单边检验: H 0 : μ ≥ μ 0 , H 1 : μ < μ 0 H_0:\mu\ge\mu_0,\text{ } H_1:\mu\lt\mu_0 H0:μ≥μ0, H1:μ<μ0
- 右侧单边检验: H 0 : μ ≤ μ 0 , H 1 : μ > μ 0 H_0:\mu\le\mu_0,\text{ } H_1:\mu\gt\mu_0 H0:μ≤μ0, H1:μ>μ0
- 确定检验水准(显著性水平)
- 检验水准(Size of a Test):又称显著性水平(Significance Level),记作 α \alpha α,是指原假设正确,但是最终被拒绝的概率
- 对应于第一类错误:原假设为真、被拒绝,通常取0.05、0.025、0.01等
- 检验功效(Power of a Test):记作 β \beta β,是指原假设错误,但是最终被接受的概率
- 对应于第二类错误:原假设为假、被接受
- 检验水准(Size of a Test):又称显著性水平(Significance Level),记作 α \alpha α,是指原假设正确,但是最终被拒绝的概率
- 构造统计量
- 根据资料类型、研究设计方案和统计推断目的,选用适当的检验方法,并计算相应的统计量
- 常见检验方法:
- t 检验:小样本(<30),总体标准差 σ \sigma σ 未知的正态分布
- F 检验:即方差分析,检验两个正态随机变量的总体方差是否相等的一种假设检验方法
- Z 检验:大样本(>=30)平均值差异性检验,又称 u 检验
- χ 2 \chi^2 χ2 检验:即卡方检验,用于非参数检验,主要是比较两个或两个以上样本率以及两个分类变量的关联性分析
- 计算 p 值
- 用来判定假设检验结果的参数,用于和显著性水平 α \alpha α 比较
- 在原假设为真的前提下,出现目前得到的样本观察结果或更极端的结果出现的概率
- 如果 p 值很小,说明原假设为真的概率很小,p 值越小,拒绝原假设的理由越充分
- 计算过程为:假设原假设为真,由样本数据计算出统计量,根据统计量的具体分布求出 p 值
- 得到结论
- 如果 p 值小于等于显著性水平 α \alpha α ,拒绝原假设
- 统计量的值如果落在拒绝域内或临界值,则拒绝原假设,落在接受域则不能拒绝原假设
偏差与方差
偏差、方差与噪声
- 偏差(Bias)
- 描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,即在样本上,拟合的好不好
- 度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力
- 体现的是最终结果与实际结果的差异,偏差越小,和真实结果越接近
- 通常模型越复杂,偏差越小
- 当偏差较大时,会出现欠拟合
- 方差(Variance)
- 模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性
- 度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
- 体现的是整体水平波动,方差越小,结果稳定性越好
- 通常模型越简单,方差越小
- 当方差较大时,会出现过拟合
- 噪声(Noise)
- 为真实标记与数据集中的实际标记间的偏差,通常由多种因素综合影响造成,不可去除
- 表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度
由此我们可以知道,期望的模型结果要符合:低偏差、低方差
泛化误差组成推导
(这部分只要记住结论就行)
记数据集 D D D 中的测试样本 x x x 的标记为 y D y_D yD, y y y 为 x x x 的真实标记, f ( x ; D ) f(x;D) f(x;D) 为基于数据集 D D D 学习的模型 f f f 对 x x x 的预测值。
以回归算法为例,其期望预测为: f ˉ ( x ) = E D [ f ( x ; D ) ] \bar{f}(x)=E_D[f(x;D)] fˉ(x)=ED[f(x;D)]
使用样本数相同的不同训练集产生的方差为: v a r ( x ) = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] var(x)=E_D[{\big(f(x;D)-\bar{f}(x)\big)}^2] var(x)=ED[(f(x;D)−fˉ(x))2]
噪声: ε 2 = E D [ ( y D − y ) 2 ] \varepsilon^2=E_D[{(y_D-y)}^2] ε2=ED[(yD−y)2] ,回归方程的噪声的期望: E D ( y D − y ) = 0 E_D(y_D-y)=0 ED(yD−y)=0
期望输出与真实标记的偏差: b i a s 2 ( x ) = E D [ ( f ˉ ( x ) − y ) 2 ] {bias}^2(x)=E_D[{\big(\bar{f}(x)-y\big)}^2] bias2(x)=ED[(fˉ(x)−y)2]
期望泛化误差:预测值和真实值的差的平方和
E ( f ; D ) = E D [ ( f ( x ; D ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) + f ˉ ( x ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] + E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y + y − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y ) 2 ] + E D [ ( y D − y ) 2 ] + E D [ 2 ( f ˉ ( x ) − y ) ( y − y D ) ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y ) 2 ] + E D [ ( y D − y ) 2 ] = v a r ( x ) + b i a s 2 ( x ) + ε 2 \begin{aligned} E(f;D)&=E_D[{\big(f(x;D)-y_D)}^2]=E_D[{\big(f(x;D)-\bar{f}(x)+\bar{f}(x)-y_D)}^2]\\ &=E_D[{\big(f(x;D)-\bar{f}(x)\big)}^2]+E_D[{\big(\bar{f}(x)-y_D\big)}^2]+E_D[2\big(f(x;D)-\bar{f}(x)\big)\big(\bar{f}(x)-y_D\big)]\\ &=E_D[{\big(f(x;D)-\bar{f}(x)\big)}^2]+E_D[{\big(\bar{f}(x)-y_D\big)}^2]=E_D[{\big(f(x;D)-\bar{f}(x)\big)}^2]+E_D[{\big(\bar{f}(x)-y+y-y_D\big)}^2]\\ &=E_D[{\big(f(x;D)-\bar{f}(x)\big)}^2]+E_D[{\big(\bar{f}(x)-y\big)}^2]+E_D[{(y_D-y)}^2]+E_D[2\big(\bar{f}(x)-y\big)(y-y_D)]\\ &=E_D[{\big(f(x;D)-\bar{f}(x)\big)}^2]+E_D[{\big(\bar{f}(x)-y\big)}^2]+E_D[{(y_D-y)}^2]\\ &=var(x)+{bias}^2(x)+\varepsilon^2 \end{aligned} E(f;D)=ED[(f(x;D)−yD)2]=ED[(f(x;D)−fˉ(x)+fˉ(x)−yD)2]=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]+ED[2(f(x;D)−fˉ(x))(fˉ(x)−yD)]=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y+y−yD)2]=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y)2]+ED[(yD−y)2]+ED[2(fˉ(x)−y)(y−yD)]=ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y)2]+ED[(yD−y)2]=var(x)+bias2(x)+ε2
回归分析
回归是处理两个或两个以上变量之间互相依赖的定量关系的一种统计方法和技术,变量之间的关系并非确定的函数关系,通过一定的概率分布来描述
- 线性与非线性
- 线性(Linear)的严格定义是一种映射关系,其映射关系满足可加性和齐次性。通俗理解就是两个变量之间存在一次函数关系,在平面坐标系中表现为一条直线。不满足线性即为非线性(non-linear)。
- 线性回归(Linear Regression)
- 在回归分析中,自变量和因变量存在着线性关系
- 回归模型的一般形式
- y = f ( x 1 , x 2 , x 3 , . . . , x p ) + ε y=f(x_1,x_2,x_3,...,x_p)+\varepsilon y=f(x1,x2,x3,...,xp)+ε
- 线性回归模型的一般形式
- y = β 0 + β 1 x 1 + β 2 x 2 + . . . + β p x p + ε y=\beta_0+\beta_1x_1+\beta_2x_2+...+\beta_px_p+\varepsilon y=β0+β1x1+β2x2+...+βpxp+ε
- β 0 , β 1 , . . . , β p \beta_0,\beta_1,...,\beta_p β0,β1,...,βp 被称作回归系数
- 回归模型的基本假设
- 零均值:随机误差项均值为0,保证未考虑的因素对被解释变量没有系统性的影响
- 同方差:随机误差项方差相同,在给定 x x x 的情况下, ε \varepsilon ε 的条件方差为某个常数 σ 2 \sigma^2 σ2
- 无自相关:两个 ε \varepsilon ε 之间不相关: C O V ( ε i , ε j ) = 0 , i ≠ j COV(\varepsilon_i,\varepsilon_j)=0,i\ne j COV(εi,εj)=0,i=j
- 正态分布: ε \varepsilon ε 符合正态分布: ε i ∼ N ( 0 , σ 2 ) \varepsilon_i\sim N(0,\sigma^2) εi∼N(0,σ2)
- 解释变量 x 1 , x 2 , . . . , x p x_1,x_2,...,x_p x1,x2,...,xp 是非随机变量,其观测值是常数
- 解释变量之间不存在精确的线性关系
- 样本个数要多于解释变量的个数
建立回归模型
- 需求分析明确变量
- 了解相关需求,明确场景,清楚需要解释的指标(因变量),并根据相关业务知识选取与之有关的变量作为解释变量(自变量)
- 数据收集加工
- 根据上一步分析得到的解释变量,去收集相关的数据(时序数据、截面数据等),对得到的数据进行清洗、加工,并根据数据情况调整解释变量,并判断是否满足基本假设
- 确定回归模型
- 了解数据集,使用绘图工具绘制变量样本散点图或者使用其他分析工具分析变量间的关系,根据结果选择回归模型,如线性回归模型、指数形式的回归模型(柯布-道格拉斯生产函数预测工业总产值)等
- 模型参数估计
- 模型确定后,基于收集、整理的样本数据,估计模型中的相关参数。最常用的方法是最小二乘法,在不满足基本假设的情况下,还会采取岭回归、主成分回归、偏最小二乘法等
- 模型检验优化
- 参数确定后,得到模型。此时需要对模型进行统计意义上的检验,包括对回归方程的显著性检验、回归系数的显著性检验、拟合优度检验、异方差检验、多重共线性检验等。还需要结合实际场景,判断该模型是否具有实际意义
- 模型部署应用
- 模型检验通过后,可以使用模型进行相关的分析、应用,包括因素分析、控制、预测等
- 变量关系:确定几个特定变量之间是否存在相关关系,如果存在的话,找出它们之间合适的数学表达式
- 因素分析:回归模型对解释变量和被解释变量之间的关系进行了度量,从各个解释变量的系数可以发现各因素对最终结果的影响大小
- 控制:给定被解释变量的值,根据模型来控制解释变量的值
- 预测:根据回归模型,可以基于已知的一个或多个变量预测另一个变量的取值,并可以了解这个取值精确到什么程度
- …
- 模型检验通过后,可以使用模型进行相关的分析、应用,包括因素分析、控制、预测等
回归模型的优缺点
- 优点
- 模型简单,建模和应用都比较容易
- 有坚实的统计理论支撑
- 定量分析各变量之间的关系
- 模型预测结果可以通过误差分析精确了解
- 缺点
- 假设条件比较多且相对严格
- 变量选择对模型影响较大
注意:如果最后结果不好的话,往往是因为没有满足前提假设条件,在进行回归分析前,必须要先确认是否满足假设条件!