iOS面试题:腾讯一面以及参考思路:
1.使用了第三方库, 有看他们是怎么实现的吗?
例:SD、YY、AFN、MJ等!
<1>.SD为例:
1.入口 setImageWithURL:placeholderImage:options:
会先把 placeholderImage 显示,然后 SDWebImageManager 根据 URL 开始处理图片。
2.进入 SDWebImageManagerdownloadWithURL:delegate:options:userInfo:,
交给 SDImageCache 从缓存查找图片是否已经下载 queryDiskCacheForKey:delegate:userInfo:.
3.先从内存图片缓存查找是否有图片,
如果内存中已经有图片缓存,SDImageCacheDelegate 回调 imageCache:didFindImage:forKey:userInfo: 到 SDWebImageManager。
4.SDWebImageManagerDelegate 回调 webImageManager:didFinishWithImage:
到 UIImageView+WebCache 等前端展示图片。
5.如果内存缓存中没有,生成 NSInvocationOperation
添加到队列开始从硬盘查找图片是否已经缓存。
6.根据 URLKey 在硬盘缓存目录下尝试读取图片文件。
这一步是在 NSOperation 进行的操作,所以回主线程进行结果回调 notifyDelegate:。
7.如果上一操作从硬盘读取到了图片,将图片添加到内存缓存中
(如果空闲内存过小,会先清空内存缓存)。
SDImageCacheDelegate 回调 imageCache:didFindImage:forKey:userInfo:。
进而回调展示图片。
8.如果从硬盘缓存目录读取不到图片,
说明所有缓存都不存在该图片,需要下载图片,
回调 imageCache:didNotFindImageForKey:userInfo:。
9.共享或重新生成一个下载器 SDWebImageDownloader 开始下载图片。
10.图片下载由 NSURLConnection 来做,
实现相关 delegate 来判断图片下载中、下载完成和下载失败。
11.connection:didReceiveData: 中
利用 ImageIO 做了按图片下载进度加载效果。
12.connectionDidFinishLoading: 数据下载完成后交给 SDWebImageDecoder 做图片解码处理。
13.图片解码处理在一个 NSOperationQueue 完成,
不会拖慢主线程 UI。如果有需要对下载的图片进行二次处理,
最好也在这里完成,效率会好很多。
14.在主线程 notifyDelegateOnMainThreadWithInfo:
宣告解码完成,
imageDecoder:didFinishDecodingImage:userInfo:
回调给 SDWebImageDownloader。
15.imageDownloader:didFinishWithImage:
回调给 SDWebImageManager 告知图片下载完成。
16.通知所有的 downloadDelegates 下载完成,
回调给需要的地方展示图片。
17.将图片保存到 SDImageCache 中,
内存缓存和硬盘缓存同时保存。
写文件到硬盘也在以单独 NSInvocationOperation 完成,
避免拖慢主线程。
18.SDImageCache 在初始化的时候会注册一些消息通知,
在内存警告或退到后台的时候清理内存图片缓存,
应用结束的时候清理过期图片。
19.SDWI 也提供了 UIButton+WebCache 和
MKAnnotationView+WebCache,方便使用。
20.SDWebImagePrefetcher 可以预先下载图片,
方便后续使用。
2.强连通分量了解嘛?
概念:
有向图强连通分量:在有向图G中,如果两个顶点vi,vj间(vi>vj)有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点强连通(strongly
connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量(strongly
connected components)。
定义:
有向图强连通分量:
在有向图G中,如果两个顶点间至少存在一条路径,称两个顶点强连通(strongly connected)。
如果有向图G的每两个顶点都强连通,则称G是一个强连通图。
非强连通图有向图的极大强连通子图,成为强连通分量(strongly connected components)。
下图中,子图{1,2,3,4}为一个强连通分量,因为顶点1,2,3,4两两可达,{5},{6}也分别是两个强连通分量。
直接根据定义,用双向遍历取交际的方法求强连通分量,时间复杂度为O(N^2+M)。更好的方法是Kosaraju算法或者Tarjan算法。
两者的时间复杂度都是O(N+M)。本文介绍的是Tarjan算法。
算法原理:(Tarjan)
need-to-insert-img
Tarjan算法是基于对图深度优先搜索的算法,每个强连通分量为搜索树中的一颗子树。
搜索时,把当前搜索树中未处理的节点加入一个堆栈,回溯时可以盘对栈顶到栈中的节点是否为一个强连通分量。
定义DFN(u)为节点u搜索的次序编号(时间戳)。Low(u)为u或者u的子树能够追溯到的最早的栈中的节点的次序号。
由定义可以得出:
Low(u)= Min { DFN(u), Low(v)} ((u,v)为树枝边,u为v的父节点DFN(v),(u,v)为指向栈中节点的后向边(非横叉边))
当DFN(u)=Low(u)时,以u为根的搜索子树上所有节点是一个强连通分量。
3.遇到tableView卡顿嘛?会造成卡顿的原因大致有哪些?
可能造成tableView卡顿的原因有:
1.最常用的就是cell的重用, 注册重用标识符
如果不重用cell时,每当一个cell显示到屏幕上时,就会重新创建一个新的cell;
如果有很多数据的时候,就会堆积很多cell。
如果重用cell,为cell创建一个ID,每当需要显示cell 的时候,都会先去缓冲池中寻找可循环利用的cell,如果没有再重新创建cell
2.避免cell的重新布局
cell的布局填充等操作 比较耗时,一般创建时就布局好
如可以将cell单独放到一个自定义类,初始化时就布局好
3.提前计算并缓存cell的属性及内容
当我们创建cell的数据源方法时,编译器并不是先创建cell 再定cell的高度
而是先根据内容一次确定每一个cell的高度,高度确定后,再创建要显示的cell,滚动时,每当cell进入凭虚都会计算高度,提前估算高度告诉编译器,编译器知道高度后,紧接着就会创建cell,这时再调用高度的具体计算方法,这样可以方式浪费时间去计算显示以外的cell
4.减少cell中控件的数量
尽量使cell得布局大致相同,不同风格的cell可以使用不用的重用标识符,初始化时添加控件,
不适用的可以先隐藏
5.不要使用ClearColor,无背景色,透明度也不要设置为0
渲染耗时比较长
6.使用局部更新
如果只是更新某组的话,使用reloadSection进行局部更新
7.加载网络数据,下载图片,使用异步加载,并缓存
8.少使用addView 给cell动态添加view
9.按需加载cell,cell滚动很快时,只加载范围内的cell
10.不要实现无用的代理方法,tableView只遵守两个协议
11.缓存行高:estimatedHeightForRow不能和HeightForRow里面的layoutIfNeed同时存在,这两者同时存在才会出现“窜动”的bug。所以我的建议是:只要是固定行高就写预估行高来减少行高调用次数提升性能。如果是动态行高就不要写预估方法了,用一个行高的缓存字典来减少代码的调用次数即可
12.不要做多余的绘制工作。在实现drawRect:的时候,它的rect参数就是需要绘制的区域,这个区域之外的不需要进行绘制。例如上例中,就可以用CGRectIntersectsRect、CGRectIntersection或CGRectContainsRect判断是否需要绘制image和text,然后再调用绘制方法。
13.预渲染图像。当新的图像出现时,仍然会有短暂的停顿现象。解决的办法就是在bitmap context里先将其画一遍,导出成UIImage对象,然后再绘制到屏幕;
14.使用正确的数据结构来存储数据。
4.M、V、C相互通讯规则你知道的有哪些?
MVC 是一种设计思想,一种框架模式,是一种把应用中所有类组织起来的策略,它把你的程序分为三块,分别是:
M(Model):实际上考虑的是“什么”问题,你的程序本质上是什么,独立于 UI 工作。是程序中用于处理应用程序逻辑的部分,通常负责存取数据。
C(Controller):控制你 Model 如何呈现在屏幕上,当它需要数据的时候就告诉 Model,你帮我获取某某数据;当它需要 UI 展示和更新的时候就告诉 View,你帮我生成一个 UI 显示某某数据,是 Model 和 View 沟通的桥梁。
V(View):Controller 的手下,是 Controller 要使用的类,用于构建视图,通常是根据 Model 来创建视图的。
要了解 MVC 如何工作,首先需要了解这三个模块间如何通信。
MVC通信规则
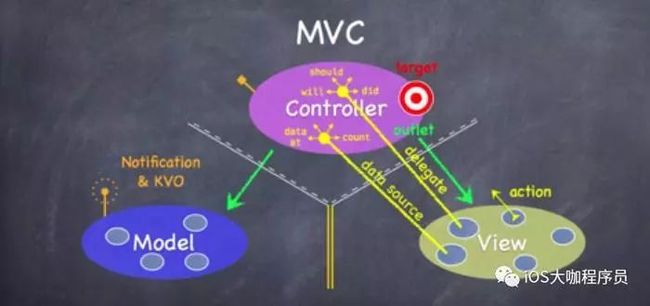
Controller to Model
可以直接单向通信。Controller 需要将 Model 呈现给用户,因此需要知道模型的一切,还需要有同 Model 完全通信的能力,并且能任意使用 Model 的公共 API。
Controller to View
可以直接单向通信。Controller 通过 View 来布局用户界面。
Model to View
永远不要直接通信。Model 是独立于 UI 的,并不需要和 View 直接通信,View 通过 Controller 获取 Model 数据。
View to Controller
View 不能对 Controller 知道的太多,因此要通过间接的方式通信。
Target
action。首先 Controller 会给自己留一个 target,再把配套的 action 交给 View 作为联系方式。那么 View
接收到某些变化时,View 就会发送 action 给 target 从而达到通知的目的。这里 View 只需要发送
action,并不需要知道 Controller 如何去执行方法。
代理。有时候 View 没有足够的逻辑去判断用户操作是否符合规范,他会把判断这些问题的权力委托给其他对象,他只需获得答案就行了,并不会管是谁给的答案。
DataSoure。View 没有拥有他们所显示数据的权力,View 只能向 Controller 请求数据进行显示,Controller 则获取 Model 的数据整理排版后提供给 View。
Model 访问 Controller
同样的 Model 是独立于 UI 存在的,因此无法直接与 Controller 通信,但是当 Model 本身信息发生了改变的时候,会通过下面的方式进行间接通信。
Notification & KVO一种类似电台的方法,Model 信息改变时会广播消息给感兴趣的人 ,只要 Controller 接收到了这个广播的时候就会主动联系 Model,获取新的数据并提供给 View。
从上面的简单介绍中我们来简单概括一下 MVC 模式的优点。
1.低耦合性
2.有利于开发分工
3.有利于组件重用
4.可维护性
5.NStimer准吗?谈谈你的看法?如果不准该怎样实现一个精确的NSTimer?
1.不准
2.不准的原因如下:
1、NSTimer加在main runloop中,模式是NSDefaultRunLoopMode,main负责所有主线程事件,例如UI界面的操作,复杂的运算,这样在同一个runloop中timer就会产生阻塞。
2、模式的改变。主线程的 RunLoop 里有两个预置的 Mode:kCFRunLoopDefaultMode 和 UITrackingRunLoopMode。
当你创建一个 Timer 并加到 DefaultMode 时,Timer 会得到重复回调,但此时滑动一个ScrollView时,RunLoop 会将 mode 切换为 TrackingRunLoopMode,这时 Timer 就不会被回调,并且也不会影响到滑动操作。所以就会影响到NSTimer不准的情况。
PS:DefaultMode 是 App 平时所处的状态,rackingRunLoopMode 是追踪 ScrollView 滑动时的状态。
方法一:
1、在主线程中进行NSTimer操作,但是将NSTimer实例加到main runloop的特定mode(模式)中。避免被复杂运算操作或者UI界面刷新所干扰。
self.timer = [NSTimer timerWithTimeInterval:1 target:self selector:@selector(showTime) userInfo:nil repeats:YES];
[[NSRunLoop currentRunLoop] addTimer:self.timer forMode:NSRunLoopCommonModes];
2、在子线程中进行NSTimer的操作,再在主线程中修改UI界面显示操作结果;
- (void)timerMethod2 {
NSThread *thread = [[NSThread alloc] initWithTarget:self selector:@selector(newThread) object:nil];
[thread start];
}
- (void)newThread
{
@autoreleasepool
{
[NSTimer scheduledTimerWithTimeInterval:1.0 target:self selector:@selector(showTime) userInfo:nil repeats:YES];
[[NSRunLoop currentRunLoop] run];
}
}
总结:
一开始的时候系统就为我们将主线程的main runloop隐式的启动了。
在创建线程的时候,可以主动获取当前线程的runloop。每个子线程对应一个runloop
方法二:
使用示例
使用mach内核级的函数可以使用mach_absolute_time()获取到CPU的tickcount的计数值,可以通过”mach_timebase_info”函数获取到纳秒级的精确度 。然后使用mach_wait_until(uint64_t deadline)函数,直到指定的时间之后,就可以执行指定任务了。
关于数据结构mach_timebase_info的定义如下:
struct mach_timebase_info {uint32_t numer;uint32_t denom;};
#include
#include
static const uint64_t NANOS_PER_USEC = 1000ULL;
static const uint64_t NANOS_PER_MILLISEC = 1000ULL * NANOS_PER_USEC;
static const uint64_t NANOS_PER_SEC = 1000ULL * NANOS_PER_MILLISEC;
static mach_timebase_info_data_t timebase_info;
static uint64_t nanos_to_abs(uint64_t nanos) {
return nanos * timebase_info.denom / timebase_info.numer;
}
void example_mach_wait_until(int seconds)
{
mach_timebase_info(&timebase_info);
uint64_t time_to_wait = nanos_to_abs(seconds * NANOS_PER_SEC);
uint64_t now = mach_absolute_time();
mach_wait_until(now + time_to_wait);
}
方法三:直接使用GCD替代!
下次面试题,再见!
iOS面试题:腾讯二面以及参考思路
1.编译过程做了哪些事情?
1.C++,Objective C都是编译语言。编译语言在执行的时候,必须先通过编译器生成机器码,机器码可以直接在CPU上执行,所以执行效率较高。
iOS开发目前的常用语言是:Objective和Swift。二者都是编译语言,换句话说都是需要编译才能执行的。二者的编译都是依赖于Clang + LLVM. OC和Swift因为原理上大同小异,知道一个即可!
iOS编译
不管是OC还是Swift,都是采用Clang作为编译器前端,LLVM(Low level vritual machine)作为编译器后端。所以简单的编译过程如图
编译器前端
编译器前端的任务是进行:语法分析,语义分析,生成中间代码(intermediate representation )。在这个过程中,会进行类型检查,如果发现错误或者警告会标注出来在哪一行。
编译器后端
编译器后端会进行机器无关的代码优化,生成机器语言,并且进行机器相关的代码优化。iOS的编译过程,后端的处理如下
LVVM优化器会进行BitCode的生成,链接期优化等等
LLVM机器码生成器会针对不同的架构,比如arm64等生成不同的机器码。
执行一次XCode build的流程
当你在XCode中,选择build的时候(快捷键command+B),会执行如下过程
编译信息写入辅助文件,创建编译后的文件架构(name.app)
处理文件打包信息,例如在debug环境下
执行CocoaPod编译前脚本
例如对于使用CocoaPod的工程会执行CheckPods Manifest.lock
编译各个.m文件,使用CompileC和clang命令。
编译各个.m文件,使用CompileC和clang命令。
1.CompileC ClassName.o ClassName.m normal x86_64 objective-c com.apple.compilers.llvm.clang.1_0.compiler
2.export LANG=en_US.US-ASCII
3.export PATH="..."
4.clang-x objective-c -arch x86_64 -fmessage-length=0 -fobjc-arc...
-Wno-missing-field-initializers ... -DDEBUG=1 ... -isysroot
iPhoneSimulator10.1.sdk -fasm-blocks ... -I 上文提到的文件 -F 所需要的Framework-iquote 所需要的Framework ... -c ClassName.c -o ClassName.o
通过这个编译的命令,我们可以看到
2.字典大致实现原理;
一:字典原理
NSDictionary(字典)是使用hash表来实现key和value之间的映射和存储的
方法:- (void)setObject:(id)anObject forKey:(id)aKey;
Objective-C中的字典NSDictionary底层其实是一个哈希表
二:哈希原理
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
哈希概念:哈希表的本质是一个数组,数组中每一个元素称为一个箱子(bin),箱子中存放的是键值对。
三:哈希存储过程
1.根据 key 计算出它的哈希值 h。
2.假设箱子的个数为 n,那么这个键值对应该放在第 (h % n) 个箱子中。
3.如果该箱子中已经有了键值对,就使用开放寻址法或者拉链法解决冲突。
在使用拉链法解决哈希冲突时,每个箱子其实是一个链表,属于同一个箱子的所有键值对都会排列在链表中。
哈希表还有一个重要的属性:负载因子(load factor),它用来衡量哈希表的空/满程度,一定程度上也可以体现查询的效率,计算公式为:
负载因子 = 总键值对数 / 箱子个数
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
哈希表在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变,这个过程也称为重哈希(rehash)。
哈希表的扩容并不总是能够有效解决负载因子过大的问题。假设所有 key 的哈希值都一样,那么即使扩容以后他们的位置也不会变化。虽然负载因子会降低,但实际存储在每个箱子中的链表长度并不发生改变,因此也就不能提高哈希表的查询性能。
基于以上总结,细心的朋友可能会发现哈希表的两个问题:
1.如果哈希表中本来箱子就比较多,扩容时需要重新哈希并移动数据,性能影响较大。
2.如果哈希函数设计不合理,哈希表在极端情况下会变成线性表,性能极低。
3.block和函数指针的理解;
相似点:
函数指针和Block都可以实现回调的操作,声明上也很相似,实现上都可以看成是一个代码片段。
函数指针类型和Block类型都可以作为变量和函数参数的类型。(typedef定义别名之后,这个别名就是一个类型)
不同点:
函数指针只能指向预先定义好的函数代码块(可以是其他文件里面定义,通过函数参数动态传入的),函数地址是在编译链接时就已经确定好的。
Block本质是Objective-C对象,是NSObject的子类,可以接收消息。
函数里面只能访问全局变量,而Block代码块不光能访问全局变量,还拥有当前栈内存和堆内存变量的可读性(当然通过__block访问指示符修饰的局部变量还可以在block代码块里面进行修改)。
从内存的角度看,函数指针只不过是指向代码区的一段可执行代码,而block实际上是程序运行过程中在栈内存动态创建的对象,可以向其发送copy消息将block对象拷贝到堆内存,以延长其生命周期。
4.一般开始做一个项目,你的架构是如何思考的?
参考文章一
参考文章二
5.你了解的UIKit结构?
