阅读路线:
- 项目背景
- 项目目的
- 数据来源
- 代码展示
一、项目背景
公司于1994年2月由双胞胎兄弟杰森汀和马修汀共同创立。公司在1994年8月推出telnet服务。公司在1994年9月成为一家零售CD网站。
二、项目目的:
利用python对销售数据进行分析,根据复购率、回购率、高额消费用户等指标及模型,获取高价值客户,从而进行有针对性的客户管理和维护。
三、数据来源
数据源于CDNow网站的用户购买明细
(数据:https://pan.baidu.com/s/1Mr1VyfgTOUyraKe_6z0Orw)
四、代码展示
(1)基本描述
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
columns = ['user_id', 'order_dt', 'order_products', 'order_amount']
# 命名列名为用户id, 购买日期, 购买数量, 购买金额
df = pd.read_table('CDNOW_master.txt', names = columns, sep='\s+')
df.head()
# 简单看下数据前五行

df.info()
# 观察数据的属性

可以观察到无缺失值,同时也发现了日期没有正确识别,等下我再处理。
df.describe()
#数据基本信息
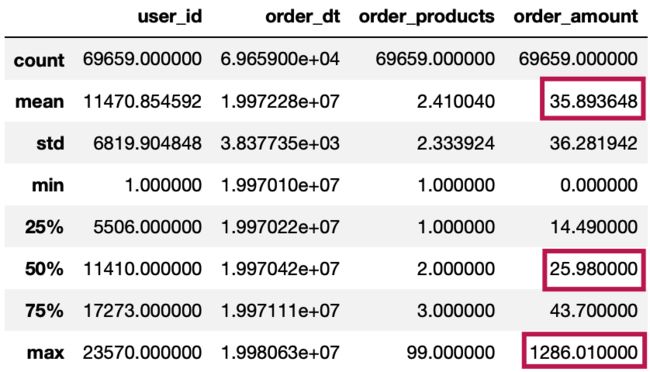
可以观察到大部分订单只消费了少量少量商品2.4件。
同时可以看到,用户的消费金额比较稳定,平均消费了35元,中位数为25元,最大值为1286元,明显受到了极值干扰,有些右偏分布。
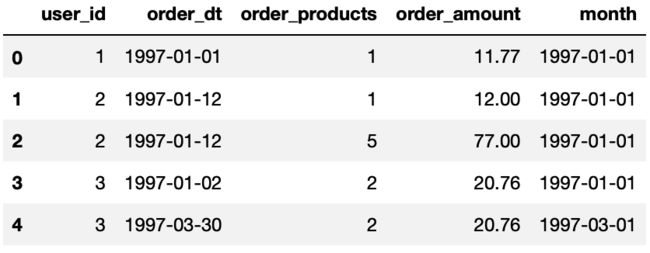
接着我来处理刚刚没有正确识别的日期列,以及加一列新的月份,方便之后按月来分析。
df['order_dt'] = pd.to_datetime(df.order_dt, format='%Y%m%d')
df['month']=df.order_dt.values.astype('datetime64[M]')
df.head()
(2)按月进行用户消费趋势分析
grouped_month = df.groupby('month')
order_month_amount = grouped_month.order_amount.sum()
order_month_amount.head()
# 按月进行分组,并对消费金额进行求和

from matplotlib.font_manager import FontProperties
font = FontProperties(fname='/Users/quincy/Library/Fonts/simhei.ttf')
ax = order_month_amount.plot()
ax.set_xlabel('月份', fontproperties=font)
ax.set_ylabel('消费金额', fontproperties=font)
ax.set_title('不同月份的用户消费金额', fontproperties = font)
plt.show()

消费金额在前三个月逐步达到顶峰,后续消费额较为稳定,有下降趋势。
ax = grouped_month.user_id.count().plot()
ax.set_xlabel('月份', fontproperties = font)
ax.set_ylabel('订单数' , fontproperties=font)
ax.set_title('不同月份的订单数', fontproperties=font)
plt.show()

前三个月消费订单数在10000笔左右,后续月份平均消费订单数在2500笔左右。
由图片可知,无论是消费金额或者订单数都呈现大致相同的趋势,前三个月高,后续月份降低且趋于稳定。由于无法确定源数据从何而来,只能暂且假定前三个月有促销活动。
(3)用户个体消费行为分析
#以用户id为分组聚集
grouped_user = df.groupby('user_id')
grouped_user.sum().describe()

用户平均购买了7张cd, 但是中位数只有3,标准差较大波动较大,说明小部分用户买了大量cd,拉高了平均值
用户平均消费106元,中位数只有43,同样有极值干扰
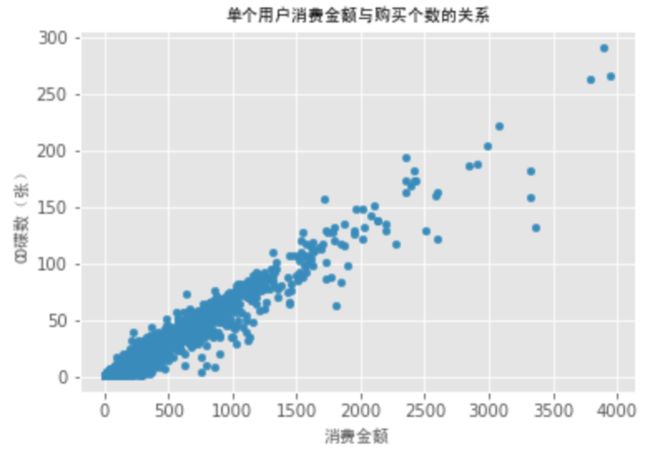
ax = grouped_user.sum().query('order_amount <= 4000').plot.scatter(x='order_amount', y='order_products')
ax.set_xlabel('消费金额',font_properties = font)
ax.set_ylabel('CD碟数(张)', font_properties = font)
ax.set_title('单个用户消费金额与购买个数的关系', font_properties=font)
plt.show()
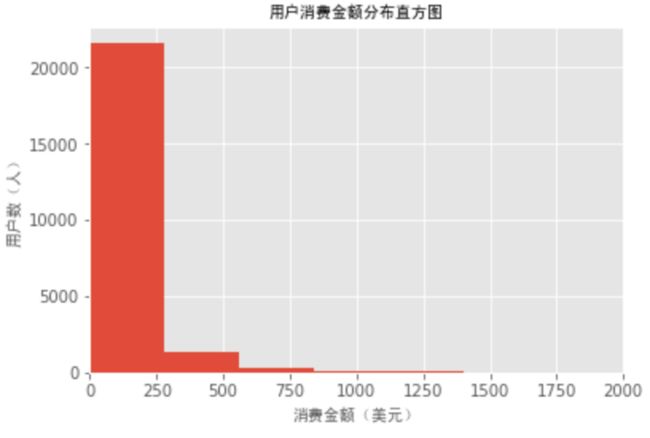
ax = grouped_user.sum().order_amount.plot.hist(bins=50)
ax.set_xlabel('消费金额(美元)', font_properties = font)
ax.set_ylabel('用户数(人)', font_properties = font)
ax.set_xlim(0,2000)
ax.set_title('用户消费金额分布直方图', font_properties = font)
plt.show()
ax = grouped_user.sum().order_products.plot.hist(bins=50)
ax.set_xlabel('CD碟数(张))', font_properties = font)
ax.set_ylabel('用户数(人)', font_properties = font)
ax.set_xlim(0,150)
ax.set_title('用户购买碟数分布直方图', font_properties = font)
plt.show()

可以从直方图观察到,绝大部分呈现集中趋势。大部分用户消费能力不高。购买张数在20张以内,金额在250美金以内。
user_cumsum = grouped_user.sum().sort_values('order_amount').apply(lambda x: x.cumsum()/ x.sum())
ax = user_cumsum.reset_index().order_amount.plot()
ax.set_title('总消费占比', font_properties = font)
ax.set_xlabel('消费金额', font_properties = font)
ax.set_ylabel('比例', font_properties = font)
plt.show()
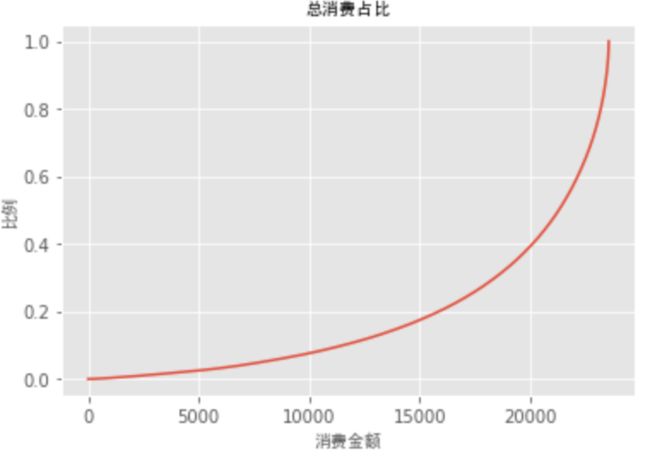
按用户消费金额进行升序排列,50%的用户只有15%的消费额度。排名前5000的用户贡献了60%的消费额。 只要维护好这前5000个用户,就能效果很好。
(4) 复购率和回购率分析
#创建数据透视表,对每个用户每个月订单数统计
pivoted_counts = df.pivot_table(index='user_id',
columns='month',
values='order_dt',
aggfunc='count').fillna(0)
pivoted_counts.head()
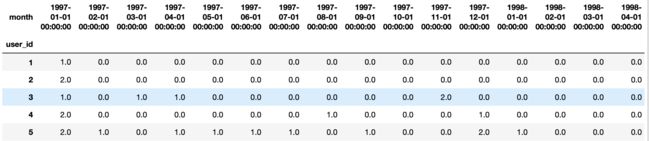
# 把购买两次及以上的转化为1,购买1次为0,方便之后分析
purchase_r = pivoted_counts.applymap(lambda x: 1 if x>1 else np.NaN if x==0 else 0)
purchase_r.head()

复购率:复购率的定义是在某时间窗口内消费两次及以上的用户在总消费用户中占比。这里的时间窗口是月,如果一个用户在同一天下了两笔订单,这里也将他算作复购用户。
ax = (purchase_r.sum() / purchase_r.count()).plot(figsize=(10,4))
ax.set_xlabel('时间(月)', font_properties = font)
ax.set_ylabel('百分比(%)', font_properties = font)
ax.set_title('每月用户复购率图', font_properties = font)
plt.show()

由图可知,前三个月由于大量新客户涌入,新用户只购买了一次,导致复购率较低。三个月后,复购率趋于稳定,在20%左右。
回购率:回购率是某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。
#回购率只需考虑一段时间内是否购买过,所以购买过转化为1,无则为0
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
df_purchase.head()

#定义函数,每个月都要跟后面一个月对比下,本月有消费且下月也有消费,则本月记为1,下月没有消费则为0,本月没有消费则为NaN,由于最后个月没有下月数据,规定全为NaN
def purchase_back(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] ==1:
status.append(1)
if data[i+1] ==0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status)
purchase_b = df_purchase.apply(purchase_back, axis=1)
# 中间发现列名出现了问题,重新调整下列名
purchase_b.columns = df_purchase.columns
purchase_b.head()

ax = (purchase_b.sum() / purchase_b.count()).plot()
ax.set_xlabel('时间(月)', font_properties = font)
ax.set_ylabel('百分比(%)', font_properties = font)
ax.set_title('十八个月内用户回购率图', font_properties = font)
plt.show()

由图可知,用户的回购率大于复购率,约在30%左右上下波动,可能有营销淡旺季导致。但这部分的回购用户消费行为大致稳定,与之前的每月复购用户有一定重合,属于优质客户。
(5) 用户分层
我们按照用户的消费行为,简单划分成几个维度:未注册用户、新用户、活跃用户、不活跃用户、回流用户。
未注册用户(unreg)
新用户(new):新用户的定义是第一次消费的用户。
活跃用户(active):即连续两个时间窗口都消费过的用户。
不活跃用户(unactive):不活跃用户则是时间窗口内没有消费过的活跃用户,即一二月份都消费过,三月份没消费过。
回流用户(return):回流用户是在上一个窗口中没有消费,而在当前时间窗口内有过消费。
def active_status(data):
status = []
for i in range(18):
#若本月没有消费
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 若本月有消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series(status)
purchase_status = df_purchase.apply(active_status, axis=1)
purchase_status.head()

#去掉未注册用户unreg,统计下每个月不同层级用户人数
purchase_status_ct = purchase_status.replace('unreg', np.NaN).apply(lambda x: pd.value_counts(x))
purchase_status_ct

#把数据转置并把填充空值为0,看上去更为直观
purchase_status_ct.fillna(0).T

ax = purchase_status_ct.fillna(0).T.plot.area(figsize = (12,6))
ax.set_xlabel('时间(月)', font_properties = font)
ax.set_ylabel('用户数(人)', font_properties = font)
ax.set_title('每月各类用户类型占比面积图', font_properties = font)
ax.legend(loc='upper left')
plt.show()
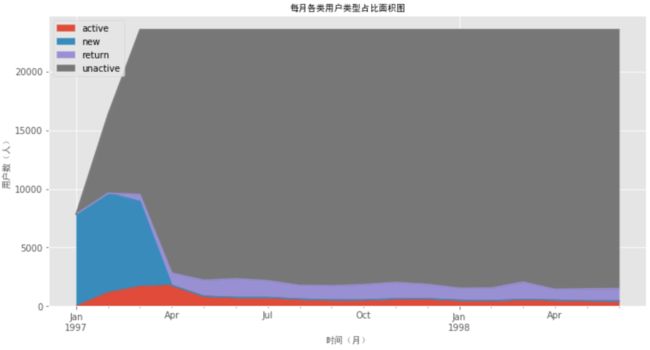
由图可知,黑色的不活跃用户占据大部分,与我们图表结果相符。红色代表的活跃用户非常稳定,属于核心用户。与紫色的回流用户相加,大致是当月的消费用户人数。
(6)用户生命周期
定义第一次消费至最后一次消费为整个用户生命。我们需要找出每个用户的第一次消费和最后次消费
user_purchase = df[['user_id','order_products','order_amount','order_dt']]
order_date_min=user_purchase.groupby('user_id').order_dt.min()
order_date_max=user_purchase.groupby('user_id').order_dt.max()
life_time = (order_date_max-order_date_min).reset_index()
life_time.describe()
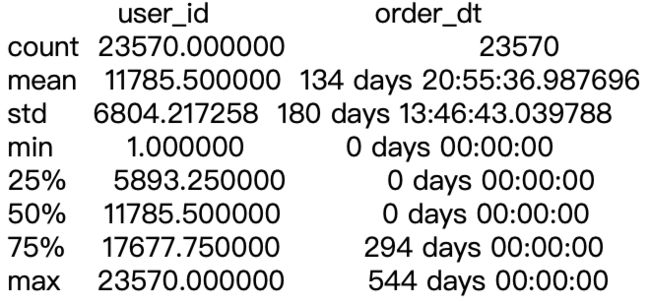
可以观察到,用户平均生命周期为134天,中位数为0。至少存在一般的用户只消费过一次,也就是低质量的客户。最大是544天,也就是数据集的总天数,说明从开始到最后都有消费意愿的高质量客户。
#二次消费以上客户的生命周期直方图
life_time['life_time'] = life_time.order_dt/np.timedelta64(1,'D')
ax=life_time[life_time > 0].life_time.plot.hist(bins =100,figsize = (12,6))
ax.set_xlabel('天数(天)', font_properties = font)
ax.set_ylabel('人数(人)', font_properties = font)
ax.set_title('二次消费以上用户的生命周期直方图', font_properties = font)
plt.show()

由图可观察到直方图呈双峰结构,部分质量较差的客户,虽然消费了两次,但仍然无法持续。若想提高用户转化率,应该在首次消费30天内尽量去引导。少部分用户集中在50-300天这个区间,属于普通型的生命周期。高质量用户的生命周期集中在400天以后,属于高忠诚客户,应尽量维护好这批客户。
(7)平均购买周期
order_diff = grouped_user.apply(lambda x: x.order_dt - x.order_dt.shift())
order_diff.describe()

ax = (order_diff / np.timedelta64(1, 'D')).hist(bins=20)
ax.set_xlabel('时间跨度(天)', font_properties = font)
ax.set_ylabel('人数(人)', font_properties = font)
ax.set_title('用户平均购买周期直方图', font_properties = font)
plt.show()

如图,典型的长尾分布,大部分用户的消费间隔确实比较短。不妨将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。