JavaScript — DOM的增删改查、节点、事件、文档的加载
目录
一、DOM
二、节点
三、事件
四、文档的加载
五、DOM查询
1.获取元素节点
2.获取元素节点的子节点
3.获取父节点和兄弟节点
4. 其他DOM查询的方法
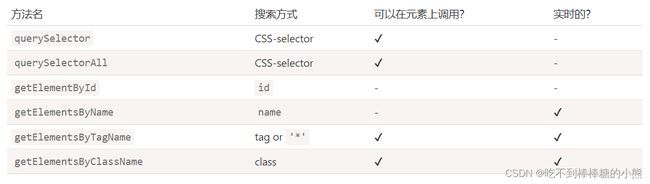
常用搜索方法总结:
5.matches()与closest()
六、DOM的增删改
创建新节点的方法
插入和移除节点的方法
七、DocumentFragment
一、DOM
DOM,全称Document Object Model 文档对象模型。
JS中通过DOM来对HTML文档进行操作。只要理解了DOM就可以随心所欲的操作WEB页面。
- 文档——文档表示的就是整个的HTML网页文档
- 对象——对象表示将网页中的每一个部分都转换为了一个对象
- 模型——使用模型来表示对象之间的关系,这样方便我们获取对象
当网页被加载时,浏览器会创建页面的文档对象模型。
HTML DOM 模型被结构化为对象树:
对象的HTML DOM树如下:
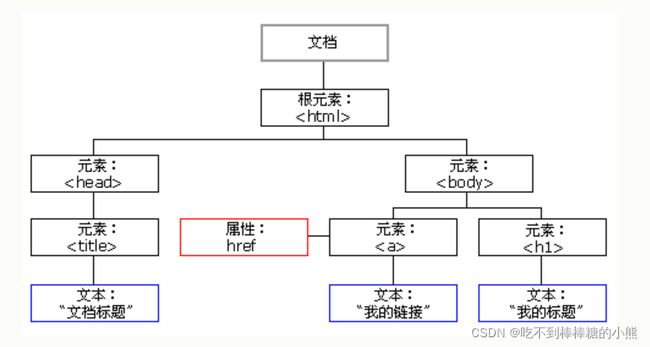
HTML DOM 是 HTML 的标准对象模型和编程接口。它定义了:
- 作为对象的 HTML 元素
- 所有 HTML 元素的属性
- 访问所有 HTML 元素的方法
- 所有 HTML 元素的事件
二、节点
节点Node,是构成我们网页的最基本的组成部分,网页中的每一个部分都可以称为是一个节点。
比如:html标签、属性、文本、注释、整个文档等都是一个节点。
虽然都是节点,但是实际上它们的具体类型是不同的。
常用节点分为四类
- 文档节点——整个HTML节点
- 元素节点——HTML文档中的HTML标签
- 属性节点——元素的属性
- 文本节点——HTML标签中的文本内容

节点的类型不同,属性和方法也都不尽相同。
节点的属性如下图所示:

浏览器已经为我们提供文档节点对象,这个对象是window属性,可以在页面中直接使用,文档节点代表的是整个网页
三、事件
事件,就是文档或浏览器窗口中发生的一些特定的交互瞬间。
JavaScript与HTML之间的交互是通过事件实现的。
对于Web应用来说,有下面这些代表性的事件:点击某个元素、将鼠标移动至某个元素上方、按下键盘上某个键等等。
方法一:可以在事件对应的属性中设置一些JS代码,这样当事件被触发时,这些代码将会执行,这种写法称为结构与行为耦合,不方便维护,不推荐使用:
方法二:还可以为按钮的对应事件绑定处理函数的形式来响应事件,这样当事件被触发时,其对应的函数会被调用:
四、文档的加载
浏览器在加载一个页面时,是按照自上向下的顺序加载的,读取到一行就运行一行,如果将script标签写到页面的上边,在代码执行时,页面还没有加载,页面可以加载DOM对象也没有加载,会导致无法获取到DOM对象
将JS代码编制写到页面的下面就是为了可以在页面加载完毕以后再执行JS代码
如果要将代码写到页面上边,可以使用onload事件,onload事件会在整个页面加载完成后才会被触发。
为window绑定一个onload事件,该事件对应的响应函数将会在页面加载完成后执行,这样就可以确保代码执行时所有的DOM对象都已经加载完毕。
举个例子:
Document
五、DOM查询
1.获取元素节点
通过document对象调用
- getElementById() 通过id属性获取一个元素节点对象(id属性是唯一的)
- getElementsByTagName() 通过标签名获取一组元素节点对象(标签名可以有多个,最终获取到的是一个数组)
- getElementsByName() 通过name属性获取一组元素节点对象(name属性可以有多个,最终获取到的是一个数组)
innerHTML用于获取元素内部的HTML代码的
对于自结束标签,这个属性没有意义
如果需要读取元素节点属性,直接使用 元素.属性名
例子:元素.id 元素.name 元素.value
注意:class属性不能采取这种方式,读取class属性时需要使用 元素.className
2.获取元素节点的子节点
通过具体的元素节点调用
- getElementsByTagName() 方法,返回当前节点的指定标签名后代节点
- childNodes 属性,表示当前节点的所有子节点,该属性会获取包括文本节点在内的所有节点
- firstChild 属性,表示当前节点的第一个子节点(包括空白文本节点)
- lastChild 属性,表示当前节点的最后一个子节点
3.获取父节点和兄弟节点
通过具体的节点调用
- parentNode 属性,表示当前节点的父节点
- previousSibling 属性,表示当前节点的前一个兄弟节点(也可能获取到空白节点)
- nextSibling 属性,表示当前节点的后一个兄弟节点
innerText
该属性可以获取到元素内部的文本内容
它和innerHTML类似,不同的是它会自动将html去除
4. 其他DOM查询的方法
body标签中的内容如下:
hhhhhhhhhhhhh
获取body标签
let body = document.getElementsByTagName("body")[0]在document中有一个body属性,它保存的是body的引用
let body = document.body;document.documentElement保存的是html根标签
let html = document.documentElementdocument.all代表页面中的所有元素
let all = document.all
for(let i=0; i根据元素的class属性值查询一组元素节点对象
let box1 = document.getElementsByClassName("box1")获取class为box1中的所有的div
document.querySelector()
需要一个选择器的字符串作为参数,可以根据一个CSS选择器来查询一个元素节点对象
使用该方法总会返回唯一的一个元素,如果满足条件的元素有多个,那么它只会返回第一个
let div = document.querySelector(".box1 div")document.querySelectAll()
该方法和document.querySelector()用法类似,不同的是它会将符合条件的元素封装在一个数组
即使符合条件的元素只有一个,它也会返回数组
let divs = document.querySelectorAll(".box1")
常用搜索方法总结:
5.matches()与closest()
elem.matches(css) 不会查找任何内容,它只会检查 elem 是否与给定的 CSS 选择器匹配。它返回 true 或 false
元素的祖先(ancestor)是:父级,父级的父级,它的父级等。祖先们一起组成了从元素到顶端的父级链。
elem.closest(css) 方法会查找与 CSS 选择器匹配的最近的祖先。elem自己也会被搜索。
换句话说,方法 closest 在元素中得到了提升,并检查每个父级。如果它与选择器匹配,则停止搜索并返回该祖先。
所有的
"getElementsBy*"方法都会返回一个 实时的(live) 集合。这样的集合始终反映的是文档的当前状态,并且在文档发生更改时会“自动更新”。在下面的例子中,有两个脚本。
- 第一个创建了对
1。- 第二个脚本在浏览器再遇到一个
2。相反,
querySelectorAll返回的是一个 静态的 集合。就像元素的固定数组。如果我们使用它,那么两个脚本都会输出
1:六、DOM的增删改
创建新节点的方法
document.createElement(tag)— 用给定的标签创建一个元素节点,
document.createTextNode(value)— 创建一个文本节点(很少使用),
elem.cloneNode(deep)— 克隆元素,如果deep==true则与其后代一起克隆。插入和移除节点的方法
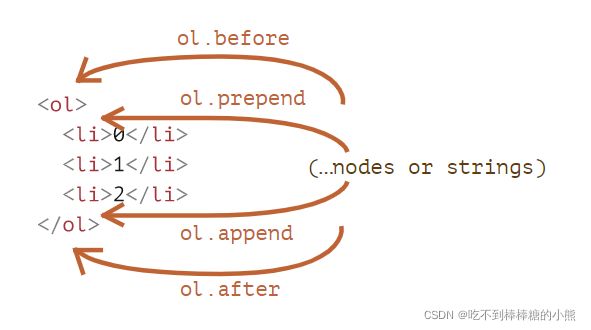
node.append(...nodes or strings)— 在node末尾插入,
node.prepend(...nodes or strings)— 在node开头插入,
node.before(...nodes or strings)— 在node之前插入,
node.after(...nodes or strings)— 在node之后插入,
node.replaceWith(...nodes or strings)— 替换node。
node.remove()— 移除node。文本字符串被“作为文本”插入。
下面这张图直观的表示出了插入节点的位置:
elem.insertAdjacentHTML/Text/Element为此,我们可以使用另一个非常通用的方法:
elem.insertAdjacentHTML(where, html)。该方法的第一个参数是代码字(code word),指定相对于
elem的插入位置。必须为以下之一:
"beforebegin"— 将html插入到elem前插入,"afterbegin"— 将html插入到elem开头,"beforeend"— 将html插入到elem末尾,"afterend"— 将html插入到elem后。第二个参数是 HTML 字符串,该字符串会被“作为 HTML” 插入。
我们很容易就会注意到这张图片和上一张图片的相似之处。插入点实际上是相同的,但此方法插入的是 HTML。
这个方法有两个兄弟:
elem.insertAdjacentText(where, text)— 语法一样,但是将text字符串“作为文本”插入而不是作为 HTML,elem.insertAdjacentElement(where, elem)— 语法一样,但是插入的是一个元素。它们的存在主要是为了使语法“统一”。实际上,大多数时候只使用
insertAdjacentHTML。因为对于元素和文本,我们有append/prepend/before/after方法 — 它们也可以用于插入节点/文本片段,但写起来更短。七、DocumentFragment
DocumentFragment是一个特殊的 DOM 节点,用作来传递节点列表的包装器(wrapper)。我们可以向其附加其他节点,但是当我们将其插入某个位置时,则会插入其内容。
例如,下面这段代码中的
getListContent会生成带有列表项的片段,然后将其插入到中:
请注意,在最后一行
(*)我们附加了DocumentFragment,但是它和ul“融为一体(blends in)”了,所以最终的文档结构应该是:
- 1
- 2
- 3