
本文对数据库Mysql做了一些介绍,望对你有所帮助。
(1)使用了brew进行安装
brew install mysql
/usr/bin/mysqladmin -u root password "111111"//对初始密码修改。
(2)文件所属位置
/usr/share/mysq/下是安装目录
/var/lib/mysql/下是mysql数据库、错误日志和socket文件
/usr/bin/文件下存储着mysql的各种命令
/etc/init.d/ 可用来启动和停止mysql服务
/etc/my.cnf是mysql的配置文件
netstat -tanp | grep mysql 查看端口号(3306)
(3)初始登录退出操作
登录mysql : mysql -u root -p 密码
启动/关闭/重新启动 service mysqld start/stop/restart
(4)数据库的增删改查
create database shujuku;//创建数据库
show databases;//显示数据库列表
drop database shujuku;// 删除数据库
use shujuku;//选择要使用的数据库
create table stud(name varchar(20) , age int ,score float);//创建表
show tables;//显示表
drop table stud;删除表
alter table stud rename to studinfo;修改表名
alter table stud add address char(40);//向表中增加字段
alter table stud modify address char(10);//修改字段的数据类型
alter table stud drop address;//删除字段
desc stud;//查看表中有哪些字段
insert into stud values(‘zhang san’,20,98.6),(‘xiao ming’,19,60);//插入数据
select *from stud where age >= 20 and score < 60;//查询信息
delete from stud where name = ‘zhang san’;//删除信息
update stud set age = 25 where name = ‘xiao ming’;//更新信息
2、数据库中的视图
视图:它是一种虚拟的表,是从数据库中一个或多个表中导出来的表。使用视图查询数据时,数据库会从原来的表中取出对应的数据。
创建视图:


a、在单表上创建视图(这里列举了一个例子)
create view department_view1(name,function,location)
as select d_name,function,address
from department;
b、在多表上创建视图(这里列举了一个例子)
create algorithm = merge view
worker_view1(name,deparment,sex,age,address)
as select name,deparment.d_name,sex,2009-birthday,address
from worker,deparment
where worker.d_id = deparment.d_id
with local check option;
查看视图
DESCRIBE worker_view1;(缩写:DESC worker_view1)//查看视图的定义
show table status like worker_view1;//查看视图基本信息
3、使用正则表达式查询信息

Example:
select * from info where name REGEXP ‘^l’;//从info 表的name 字段中查询以字母‘l’开头的记录
select * from info where name REGEXP ‘c$’;//从info 表的name 字段中查询以字母‘c’结尾的记录
select * from info where name REGEXP ‘^l..y$’;//从info 表的name 字段中查询以字母‘l’开头,以字母y结尾,中间两个任意字符的记录
select * from info where name REGEXP ‘a*c’;//从info 表的name 字段中查询字母‘c’之前出现过0个或多个‘a’的记录
select * from info where name REGEXP ‘a+c’;//从info 表的name 字段中查询字母‘c’之前出现过至少一个‘a’的记录)
4、mysql性能优化
目的:为了使mysql数据库运行速度更快、占用的磁盘空间更小。
数据库管理员可以使用如下语句查询mysql数据库的性能:
show status like 'value';

(1)查询优化:
explain select * from student \G //分析select 语句的执行情况

上述字段的含义如下:

使用索引,创建索引,如:
create index index_name on student(name);//在name字段上建立一个名为index_name 的索引
(2)优化数据库结构:
a、将字段很多的表分解成为一个表

b、增加中间表
有时候需要经常查询两个表中的几个字段,如果经常进行链表查询,会降低mysql的查询速度,因此可将这几个字段抽取出来单独建立一个表,然后从两个表中将数据导入进来。
c、增加冗余字段

d、优化插入记录的速度
1>禁用索引

2>禁用唯一性检查

3>优化insert语句

e、分析表、检查表和优化表
分析表的作用是检查关键字的分布---->


检查表的作用是检查表是否存在错误---->

优化表的主要作用是消除删除或者更新造成的空间浪费--->


5、数据库中的触发器
触发器是由insert、update、delete 等事件来触发某种特定操作,满足触发器的触发条件时,数据库系统就会执行触发器中定义的程序语句,这样做可以保证某些操作之间的一致性。
创建触发器:
有一个执行语句的触发器:

有多个执行语句的触发器:

6、数据库复制原理

分三步:
(1)主服务器把数据更新记录到二进制日志中;
(2)从服务器把主服务器的二进制日志拷贝到自己的中继日志中;
(3)从服务器重做中继日志的时间,把更新应用到自己的数据库上;
注:从服务器有两个线程:一个是I/O线程,负责读取主服务器的二进制日志,并将其拷贝到自己的中继日志中;另一个是SQL 线程,负责复制执行中继日志。
7、数据库中事务的概念
事务:作为单个逻辑工作单元执行的一系列操作。
事务满足4个特性:
(1)原子性(Atomic):事务要么全部执行,要么全都不执行,不可能只处理一个子集。
(2)一致性(Consistent):事务在完成时,必须确保所有的数据都处于一致状态。
(3)隔离性(Insulation):由并发事务所做的修改必须与其他任何并发事务所做的修改隔离,通过“锁”实现。通常有四种隔离级别:read uncommited(读取未提交的内容,也称为脏读),read committed(读取提交内容,支持不可重复读),repeatable read(可重读,这是MySQL 的默认事务隔离级别,会导致幻读,即当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行),serializable(可串行化,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题)
(4)持久性(Duration):事务完成之后,它对于系统的影响是持久的,既使出现致命的系统故障。
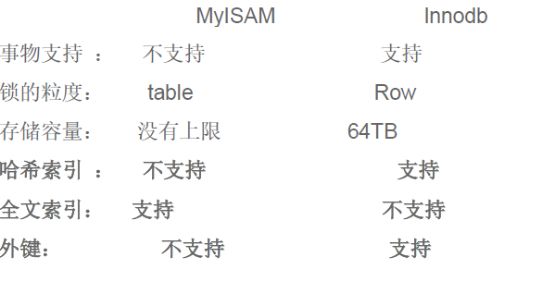
8、myisam与innodb、Memory的差别
(1)MyISAM引擎
MyISAM引擎是MySQL默认的存储引擎,MyISAM不支持事务和行级锁,所以MyISAM引擎速度很快,性能优秀。MyISAM可以对整张表加锁,支持并发插入,支持全文索引。
//如果你不需要事务支持,通常我们建表时都选用MyISAM存储引擎,像新闻表之类都没有必要支持事务。
(2)InnoDB引擎
InnoDB是专为事务设计的存储引擎,支持事务,支持外键,拥有高并发处理能力。但是,InnoDB在创建索引和加载数据时,比MyISAM慢。
//涉及到货币操作一般都需要支持事务,什么都能错,钱不能出错。
(3)Memory引擎(采用哈希索引)
内存表,Memory引擎将数据存储在内存中,表结构不是存储在内存中的,查询时不需要执行磁盘I/O操作,所以要比MyISAM和InnoDB快很多倍,但是数据库断电或是重启后,表中的数据将会丢失,表结构不会丢失.
//如果你需要将SESSION数据存在数据库中,那么使用Memory引擎是个不错的选择。
9、数据库范式的概念
1NF:第一范式。如果关系模式R的所有属性的值域中每一个值都是不可再分解的值,则称R属于第一范式模式。
2NF:第二范式。如果关系模式R是第一范式,并且R中每一个非主属性完全函数依赖于R的某个候选键,则称R为第二范式。
3NF:第三范式。如果关系模式R是第二范式,并且R中每一个非主属性都不传递依赖于R的候选键,则称R为第三范式。
BCNF:BC范式,如果关系模式R是第一范式,且且每个属性都不传递依赖于R的候选键,则称R为BCNF的模式。
4NF:第四范式。把同一表内的多对多关系删除。
10、数据库中索引的深入理解
索引是一种数据结构。
InnoDB存储引擎支持的几种常见索引:
B+树索引:并不能找到一个给定健值的具体行,B+树索引只能找到被查找数据行所在的页,然后从数据库将页读入内存,在内存中查找。B+树索引可以分为聚集索引和辅助索引。
(1)聚集索引

这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键。按照表的主键构建一颗B+树。键值的逻辑顺序决定了表中对应行(记录集)在逻辑地址上是连续的,注意:很多书上说是在物理地址上连续,其实是指逻辑地址连续。
聚集索引查询速度快,叶子节点的数据就是用户需要查询的数据。聚集索引对于那些经常要搜索范围值的列特别有效。
(2)辅助索引

叶节点的data域存放的是数据记录的地址,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录(MYISAM采用此种索引方式)
注:不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
Myisam 和InnoDB索引的区别:
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。
11、数据库中倒排表的概念
对包含有大量数据对象的数据表或文件进行搜索时,最常用的是针对对象的主关键码建立索引。主关键码可以唯一地标识该对象。用主关键码建立的索引叫做主索引。主索引的每个索引项给出对象的关键码和对象在表或文件中的存放地址。
但在实际应用中有时需要针对其它属性进行搜索。
因此,除主关键码外,可以把一些经常搜索的属性设定为次关键码,并针对每一个作为次关键码的属性,建立次索引。在次索引中,列出该属性的所有取值,并对每一个取值建立有序链表,把所有具有相同属性值的对象按存放地址递增的顺序或按主关键码递增的顺序链接在一起。次索引的索引项由次关键码、链表长度和链表本身等三部分组成。
如下图是一个关于主索引和次索引的例子:

倒排表或倒排文件是一种次索引的实现。在次索引中记录对象存放位置的指针可以用主关键码表示,可以通过搜索次索引确定该对象的主关键码,再通过搜索主索引确定对象的存放地址。在倒排表中各个属性链表的长度大小不一,管理起来比较困难。为此引入单元式倒排表。
在单元式倒排表中,索引项中不存放对象的存储地址,存放该对象所在硬件区域的标识。
硬件区域可以是磁盘柱面、磁道或一个页块,以一次 I / O 操作能存取的存储空间作为硬件区域为最好。为使索引空间最小,在索引中标识这个硬件区域时可以使用一个能转换成地址的二进制数,整个次索引形成一个(二进制数的) 位矩阵。
12、mysql中的varchar与char
(1)varchar与char的区别
char是固定长度的,而varchar需要增加一个长度标识,处理的时候需要多一次运算,所以相对来说char比varchar更快。
(2)varchar(50)中50的含义
最多存放50个字节
(3)int(20)中20的含义
20代表整型的最大显示宽度,整数的最大范围是255
13、innodb 有多少种日志
错误日志:记录出错信息,也记录一些警告信息或者正确的信息
慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL 语句都记录到慢查询的日志文件中。
二进制日志:记录对数据库执行更改的所有操作
查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
14、存储过程
是用户定义的一系列SQL语句的集合,涉及特定表或其他对象的任务,用户可以调用存储过程。
15、SQL注入式攻击:攻击者将SQL命令插入到web表单的输入域或页面请求的查询字符串中,欺骗服务器执行恶意的SQL命令。在某些表单中,用户输入的内容直接用来构造(或者影响)动态SQL命令,或作为存储过程的输入参数,这类表单特别容易受到SQL注入式攻击。
防范SQL注入式攻击:
思想-->在利用表单输入的内容构造SQL命令之前,把所有输入的内容过滤一番。过滤输入内容的方式有以下几中:
一、替换单引号,把所有单独出现的单引号改成两个单引号,防止攻击者修改SQL命令的含义。
二、对于用来执行查询的数据库账户,限制其权限。用不同的用户执行查询、插入、更新、删除操作。
三、用存储过程来执行所有的查询。SQL参数的传递方式将防止攻击者利用单引号和连字符实施攻击。此外,它使得数据库权限可以被限制到只允许特定的存储过程执行,所有的用户输入必须遵从被调用存储过程的安全上下文。
四、检查用户输入的合法性,确信输入的内容只包含合法的数据。数据检查应当在客户端和服务器端都执行。
五、将用户登录名称、密码等数据加密保存。
六、检查提取数据的查询所返回的记录数量。如果程序只要求返回一个记录,但实际返回的记录却超过一行,那就当做出错处理。
16、查询:
Order by默认的查询结果是按升序排列的。加DESC是按降序排列的。
Group by将查询结果按某个字段或多个字段进行分组查询,字段中值相等的为一组:
(1)Group by与Group_Concat()函数一起使用,每个分组中的字段值都会显示出来。
eg:select sex,GROUP_CONCAT(name) from employee GROUP BY sex;
(2)Group by与集合函数一起使用,可以通过集合函数计算分组中的总记录、最大值、最小值。
eg:select sex,COUNT(sex) from employee GROUP BY sex;
(3)Group by与HAVING一起使用,可以限制输出的结果,只有满足条件表达式的结果才会显示。
eg:select sex,COUNT(sex) from employee GROUP BY sex HAVING COUNT(sex)>=3;
(4)Group by与WITH ROLLUP一起使用,将会在所有记录的最后加上一条记录,这条记录是上面所有记录的总和。
使用SQL语句建立一张临时表:
create table #Temp(字段1 类型,字段2 类型);
------end--------