最近项目使用Redis缓存很多实时的数据,很多还是HashMap形式的,比较吃资源,查询还比较频繁,单机版的Redis性能上有点跟不上。节点上数据量一大就容易影响使用redis的模块的平稳运行,所以我们决定再加两台服务器,搭建三节点的Redis服务器。
网上看了下,Redis集群安装有点麻烦,实在不是太想尝试。于是我们思考了一种比较简单的办法,直接采用分布式系统中负载均衡用作负载均衡地一致性hash来控制读写的服务器。这样三台服务器之间是完全独立的(不过这个搞法肯定不如集群版稳定)。
什么是一致性Hash
一致性哈希算法常用于负载均衡中要求资源被均匀的分布到所有节点上,并且对资源的请求能快速路由到对应的节点上。它相对hash%N来说,可扩展性较好。hash%N方式当增加服务器时,会造成大量数据检索无效。
一致性hash特性
单调性(Monotonicity),单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时候,应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其它服务器上去。 这个通过上面新增服务器ip5可以证明,新增ip5后,原来被ip1处理的user6现在还是被ip1处理,原来被ip1处理的user5现在被新增的ip5处理。
分散性(Spread):分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来他看到的部分服务器会形成一个完整的hash环。如果多个客户端都把部分服务器作为一个完整hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。好的哈希算法应尽量避免尽量降低分散性。 一致性hash具有很低的分散性
平衡性(Balance):平衡性也就是说负载均衡,是指客户端hash后的请求应该能够分散到不同的服务器上去。一致性hash可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同
两种实现
不使用虚拟节点
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Set;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHashingWithoutVirtualNode {
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
/**
* key表示服务器的hash值,value表示服务器的名称
*/
private static SortedMap sortedMap =
new TreeMap();
/**
* 程序初始化,将所有的服务器放入sortedMap中
*/
static
{
for (int i = 0; i < servers.length; i++)
{
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println();
}
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
*/
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node)
{
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map
SortedMap subMap =
sortedMap.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i=null;
String virtualNode = null;
if(subMap==null||subMap.size()==0){
i=sortedMap.firstKey();
virtualNode=sortedMap.get(i);
}else{
i = subMap.firstKey();
virtualNode= subMap.get(i);
}
return virtualNode;
}
public static void main(String[] args)
{
HashMap map=new HashMap();
List id = new ArrayList();
for(int i=0;i<1000000;i++){
String str ;
if(i%4==0) str = "VD";
else if(i%4==1) str = "EM";
else if(i%4==2) str = "LP";
else str = "VB";
id.add(str+"_"+i);
//id.add("adasfdsafdsgfdsagdsafdsafdsaf"+i);
}
for (int i = 0; i < id.size(); i++) {
String aString =getServer(id.get(i));
Integer aInteger = map.get(aString);
if(aInteger==null){
map.put(aString,1);
}else{
map.put(aString, aInteger+1);
}
System.out.println("id:"+id.get(i)+"被分配到节点: "+aString+"上");
}
Set set= map.keySet();
for(String a:set){
System.out.println("节点【"+a+"】分配到元素个数为==>"+map.get(a));
}
}
}
测试结果:1000000个请求
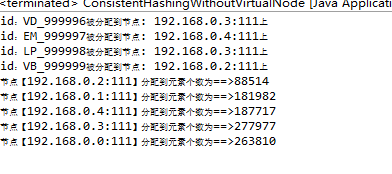
可以看出来,不使用虚拟节点的一致性hash虽然保证了每台服务器都可以接收到一定量的请求,但是不保证大致的平衡,出现了一定的数据倾斜问题。
使用虚拟节点
采用虚拟节点可以把每台服务器映射成多个虚拟节点,这样服务器hash环俩俩之间的距离就变小了,当我们映射到某一个最近的虚拟节点时,我们就将这个请求交给虚拟节点对应的真实节点去处理。这样的话,对于我们这种真实节点比较少的情况,就可以提供更加细粒度的hash映射,有效地减少数据清洗问题。
下面是测试代码:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHashingWithVirtualNode {
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
/**
* 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好
*/
private static List realNodes = new LinkedList();
/**
* 虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称
*/
private static SortedMap virtualNodes =
new TreeMap();
/**
* 虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应5个虚拟节点
*/
private static final int VIRTUAL_NODES = 1000;
/**
*
* @Title: buildVirtualNodes
* @Description: 建立虚拟节点
* @param
* @return void
* @throws
*/
public void buildVirtualNodes(){
synchronized(virtualNodes) {
for (int i = 0; i < servers.length; i++)
realNodes.add(servers[i]);
// 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高
for (String str : realNodes)
{
for (int i = 0; i < VIRTUAL_NODES; i++)
{
String virtualNodeName = str + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
}
}
static
{
// 先把原始的服务器添加到真实结点列表中
for (int i = 0; i < servers.length; i++)
realNodes.add(servers[i]);
// 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高
for (String str : realNodes)
{
for (int i = 0; i < VIRTUAL_NODES; i++)
{
String virtualNodeName = str + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
System.out.println();
}
/**
* 使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
*/
private static int getHash(String str)
{
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node)
{
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map
SortedMap subMap =
virtualNodes.tailMap(hash);
Integer i=null;
String virtualNode = null;
if(subMap==null||subMap.size()==0){
i=virtualNodes.firstKey();
virtualNode=virtualNodes.get(i);
}else{
i = subMap.firstKey();
virtualNode= subMap.get(i);
}
// 第一个Key就是顺时针过去离node最近的那个结点
// 返回对应的虚拟节点名称,这里字符串稍微截取一下
return virtualNode.substring(0, virtualNode.indexOf("&&"));
}
public static void main(String[] args)
{
HashMap map=new HashMap();
List id = new ArrayList();
for(int i=0;i<1000000;i++){
String str ;
if(i%4==0) str = "VD";
else if(i%4==1) str = "EM";
else if(i%4==2) str = "LP";
else str = "VB";
id.add(str+"_"+i);
//id.add("adasfdsafdsgfdsagdsafdsafdsaf"+i);
}
for (int i = 0; i < id.size(); i++) {
String aString =getServer(id.get(i));
Integer aInteger = map.get(aString);
if(aInteger==null){
map.put(aString,1);
}else{
map.put(aString, aInteger+1);
}
System.out.println("id:"+id.get(i)+"被分配到节点: "+aString+"上");
}
Set set= map.keySet();
for(String a:set){
System.out.println("节点【"+a+"】分配到元素个数为==>"+map.get(a));
}
}
}
测试结果:1000000
每个真实节点构造1000个虚拟节点

可以看出,这样加入虚拟节点后,各个节点的数据变得均衡了。但是虚拟节点添加过多会占用大量内存,如果不是过分强调负载均衡,不宜设置过大。
接下来就是修改原来的redis的代码。让jedis能够找到对应的服务器去读写数据。这一步我们需要写一个类继承Jedis类,重写这些读写操作
public class MyJedis extends Jedis{
private static HashMap jedisMap = new HashMap();
public MyJedis(){
SortedMap realNodes = ConsistentHashingWithVirtualNode.virtualNodes;
for (Entry entry : realNodes.entrySet()) {
String ip = entry.getKey();
jedisMap.put(ip, JedisPoolUtils.getJedisByIP(ip));
}
}
/*根据key去获取相应的ip,并根据ip来获取相应的jedis*/
public Jedis getJedis(String key){
String jedisIP = ConsistentHashingWithVirtualNode.getServer(key);
return jedisMap.get("jedisIP");
}
/*重写hashMap的set方法*/
@Override
public String hmset(String key, Map hash) {
// TODO Auto-generated method stub
Jedis jedis = this.getJedis(key);//根据key去获取jedis连接
return jedis.hmset(key, hash);用该key去操作
}
/*此处不累赘......*/
}